Puedes usar Enterprise Document OCR como parte de Document AI para detectar y extraer texto, y obtener información sobre el diseño de varios documentos. Con las funciones configurables, puedes adaptar el sistema para que cumpla con los requisitos específicos de procesamiento de documentos.
Descripción general
Puedes usar Enterprise Document OCR para tareas como la entrada de datos basada en algoritmos o aprendizaje automático, y para mejorar y verificar la precisión de los datos. También puedes usar Enterprise Document OCR para controlar tareas como las siguientes:
- Digitalización de texto: Extrae texto y datos de diseño de documentos para la búsqueda, las canalizaciones de procesamiento de documentos basadas en reglas o la creación de modelos personalizados.
- Uso de aplicaciones de modelos de lenguaje grandes: Usa la comprensión contextual de los LLM y las capacidades de extracción de texto y diseño del OCR para automatizar preguntas y respuestas. Obtén estadísticas a partir de los datos y optimiza los flujos de trabajo.
- Archivado: Digitaliza documentos en papel en texto legible por máquina para mejorar la accesibilidad a los documentos.
Cómo elegir el mejor OCR para tu caso de uso
| Solución | Producto | Descripción | Caso práctico |
|---|---|---|---|
| Document AI | Enterprise Document OCR | Modelo especializado para casos de uso de documentos. Las funciones avanzadas incluyen la puntuación de calidad de la imagen, sugerencias de idioma y corrección de rotación. | Se recomienda cuando se extrae texto de documentos. Los casos de uso incluyen archivos PDF, documentos escaneados como imágenes o archivos DocX de Microsoft. |
| Document AI | Complementos de OCR | Funciones premium para requisitos específicos Solo es compatible con la versión 2.0 y posteriores del OCR de documentos empresariales. | Necesitas detectar y reconocer fórmulas matemáticas, recibir información sobre el estilo de la fuente o habilitar la extracción de casillas de verificación. |
| API de Cloud Vision | Detección de textos | API de REST disponible a nivel mundial basada en el Google Cloud modelo estándar de OCR. Cuota predeterminada de 1,800 solicitudes por minuto | Casos de uso generales de extracción de texto que requieren baja latencia y alta capacidad. |
| Cloud Vision | OCR Google Distributed Cloud (obsoleto) | Aplicación de Google Cloud Marketplace que se puede implementar como contenedor en cualquier clúster de GKE con GKE Enterprise. | Para cumplir con los requisitos de residencia o cumplimiento de datos |
Detección y extracción
El OCR de documentos empresarial puede detectar bloques, párrafos, líneas, palabras y símbolos en archivos PDF e imágenes, además de corregir la inclinación de los documentos para mejorar la precisión.
Atributos de detección y extracción de diseño admitidos:
| Texto impreso | Escritura a mano | Párrafo | Bloquear | Line | Palabra | A nivel de símbolos | Número de página |
|---|---|---|---|---|---|---|---|
| Predeterminado | Predeterminado | Predeterminado | Predeterminado | Predeterminado | Predeterminado | Configurable | Predeterminado |
Las funciones configurables del OCR empresarial de documentos incluyen lo siguiente:
Extrae texto integrado o nativo de PDFs digitales: Esta función extrae texto y símbolos exactamente como aparecen en los documentos fuente, incluso en el caso de textos rotados, tamaños o estilos de fuente extremos y texto parcialmente oculto.
Corrección de rotación: Usa Enterprise Document OCR para preprocesar imágenes de documentos y corregir problemas de rotación que pueden afectar la calidad de la extracción o el procesamiento.
Puntuación de calidad de la imagen: Recibe métricas de calidad que pueden ayudar con el enrutamiento de documentos. La puntuación de calidad de la imagen te proporciona métricas de calidad a nivel de la página en ocho dimensiones, incluidas la falta de nitidez, la presencia de fuentes más pequeñas de lo habitual y el deslumbramiento.
Especificar rango de páginas: Especifica el rango de páginas de un documento de entrada para el OCR. Esto ahorra tiempo de procesamiento y de inversión en páginas innecesarias.
Detección de idiomas: Detecta los idiomas que se usan en los textos extraídos.
Sugerencias de idioma y escritura a mano: Mejora la precisión proporcionando al modelo de OCR una sugerencia de idioma o escritura a mano según las características conocidas de tu conjunto de datos.
Para obtener información sobre cómo habilitar la configuración del OCR, consulta Habilita la configuración del OCR.
Complementos de OCR
Enterprise Document OCR ofrece capacidades de análisis opcionales que se pueden habilitar en solicitudes de procesamiento individuales según sea necesario.
Las siguientes capacidades de complementos están disponibles para las versiones estable pretrained-ocr-v2.0-2023-06-02 y pretrained-ocr-v2.1-2024-08-07, y la versión candidata a lanzamiento pretrained-ocr-v2.1.1-2025-01-31.
- OCR de ecuaciones: Identifica y extrae fórmulas de documentos en formato LaTeX.
- Extracción de casillas de verificación: Detecta casillas de verificación y extrae su estado (marcado o sin marcar) en la respuesta de Enterprise Document OCR.
- Detección de estilo de fuente: Identifica las propiedades de la fuente a nivel de la palabra, incluidos el tipo, el estilo, la escritura a mano, el grosor y el color.
Para obtener información sobre cómo habilitar los complementos enumerados, consulta Habilita complementos de OCR.
Formatos de archivo compatibles
El OCR de documentos empresariales admite los formatos de archivo PDF, GIF, TIFF, JPEG, PNG, BMP y WebP. Para obtener más información, consulta Archivos compatibles.
El OCR de documentos empresariales también admite archivos DocX de hasta 15 páginas en modo síncrono y 30 páginas en modo asíncrono. Para realizar una solicitud de aumento de cuota (QIR), sigue los pasos que se indican en Solicita un ajuste de cuota. La compatibilidad con DocX está en versión preliminar privada. Para solicitar acceso, comunícate con el equipo de tu cuenta de Google.
Control de versiones avanzado
El control de versiones avanzado se encuentra en Vista previa. Las actualizaciones de los modelos subyacentes de OCR basados en IA/AA pueden generar cambios en el comportamiento del OCR. Si se requiere coherencia estricta, usa una versión del modelo inmovilizada para fijar el comportamiento en un modelo de OCR heredado durante un máximo de 18 meses. Esto garantiza el mismo resultado de la función de OCR de imágenes. Consulta la tabla sobre las versiones del procesador.
Versiones del procesador
Las siguientes versiones de procesador son compatibles con esta función. Para obtener más información, consulta Administra versiones de procesadores.
| ID de versión | Canal de versiones | Descripción |
|---|---|---|
pretrained-ocr-v1.2-2022-11-10 |
Estable | Versión inmovilizada del modelo de la versión 1.0: Archivos, configuraciones y archivos binarios del modelo de una instantánea de la versión inmovilizada en una imagen de contenedor por hasta 18 meses. |
pretrained-ocr-v2.0-2023-06-02 |
Estable | Modelo listo para producción y especializado en casos de uso de documentos. Incluye acceso a todos los complementos de OCR. |
pretrained-ocr-v2.1-2024-08-07 |
Estable | Las principales áreas de mejora de la versión 2.1 son las siguientes: mejor reconocimiento de texto impreso, detección más precisa de casillas de verificación y orden de lectura más exacto. |
pretrained-ocr-v2.1.1-2025-01-31 |
Versión candidata para lanzamiento | La versión 2.1.1 es similar a la versión 2.1 y está disponible en todas las regiones, excepto en US, EU y asia-southeast1. |
Usa Enterprise Document OCR para procesar documentos
En esta guía de inicio rápido, se presenta el OCR de documentos empresariales. En él, se muestra cómo optimizar los resultados del OCR de documentos para tu flujo de trabajo habilitando o inhabilitando cualquiera de las configuraciones de OCR disponibles.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. quality/defect_blurryquality/defect_noisyquality/defect_darkquality/defect_faintquality/defect_text_too_smallquality/defect_document_cutoffquality/defect_text_cutoffquality/defect_glare- Puede devolver detecciones de falsos positivos con documentos digitales sin defectos. Esta función se usa mejor en documentos escaneados o fotografiados.
Los defectos de reflejo son locales. Su presencia podría no dificultar la legibilidad general del documento.
- Para procesar solo la segunda y la quinta página, haz lo siguiente:
- Para procesar solo las primeras tres páginas, haz lo siguiente:
- Para procesar solo las últimas cuatro páginas, haz lo siguiente:
Se detectó una imagen
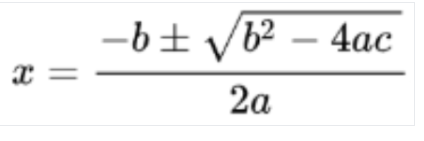
Conversión a LaTeX
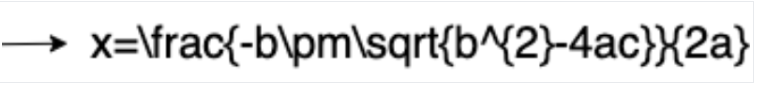
- Detección de escritura a mano
- Estilo de fuente
- Tamaño de fuente
- Tipo de fuente
- Color de fuente
- Grosor de la fuente
- El espacio entre letras
- Negrita
- Cursiva
- Subrayado
- Color del texto (RGBa)
Color de fondo (RGBa)
- La respuesta de la API de Vision AI solo completa
verticespara las solicitudes de imágenes y solo completanormalized_verticespara las solicitudes de PDF. La respuesta de Document AI y el convertidor completanverticesynormalized_vertices. - La respuesta de la API de Vision AI propaga el
detected_breaken el último símbolo de la palabra. La respuesta de la API de Document AI y el convertidor propagandetected_breaken la palabra y el último símbolo de la palabra. - La respuesta de la API de Vision AI siempre completa los campos de símbolos. De forma predeterminada, la respuesta de Document AI no propaga los campos de símbolos. Para asegurarte de que la respuesta de Document AI y el convertidor completen los campos de símbolos, configura la función
enable_symbolcomo se detalla. - LOCATION: La ubicación de tu procesador, por ejemplo:
us: Estados Unidoseu: Unión Europea
- PROJECT_ID: El ID de tu proyecto de Google Cloud .
- PROCESSOR_ID: Es el ID de tu procesador personalizado.
- PROCESSOR_VERSION: Es el identificador de la versión del procesador. Consulta Selecciona una versión del procesador para obtener más información. Por ejemplo:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- skipHumanReview: Es un valor booleano para inhabilitar la revisión manual (solo es compatible con los procesadores con interacción humana).
true- Se omite la revisión humanafalse: Habilita la revisión manual (configuración predeterminada).
- MIME_TYPE†: Una de las opciones de tipo de MIME válidas.
- IMAGE_CONTENT†: Uno de los contenidos de documentos intercalados válidos, representado como un flujo de bytes. Para las representaciones JSON, es la codificación en base64 (cadena ASCII) de los datos de la imagen binaria. Esta cadena debería ser similar a la siguiente:
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==
- FIELD_MASK: Especifica qué campos se deben incluir en el resultado de
Document. Esta es una lista separada por comas de los nombres de campos completamente calificados en formatoFieldMask.- Ejemplo:
text,entities,pages.pageNumber
- Ejemplo:
- Configuraciones de OCR
- ENABLE_NATIVE_PDF_PARSING: (Booleano) Extrae el texto incorporado de los PDFs, si está disponible.
- ENABLE_IMAGE_QUALITY_SCORES: (booleano) Habilita las puntuaciones de calidad de documentos inteligentes.
- ENABLE_SYMBOL: (booleano) Incluye información de OCR de símbolos (letras).
- DISABLE_CHARACTER_BOXES_DETECTION: (booleano) Desactiva el detector de cuadros de caracteres en el motor del OCR.
- LANGUAGE_HINTS: Lista de códigos de idioma BCP-47 que se usarán para el OCR.
- ADVANCED_OCR_OPTIONS: Es una lista de opciones avanzadas de OCR para ajustar aún más el comportamiento del OCR. Los valores válidos actuales son los siguientes:
legacy_layout: Es un algoritmo de detección de diseño basado en heurísticas que sirve como alternativa al algoritmo de detección de diseño basado en AA actual.
- Complementos de OCR Premium
- ENABLE_SELECTION_MARK_DETECTION: (booleano) Activa el detector de marcas de selección en el motor del OCR.
- COMPUTE_STYLE_INFO (booleano): Activa el modelo de identificación de fuente y devuelve la información del estilo de fuente.
- ENABLE_MATH_OCR: (booleano) Activa el modelo que puede extraer fórmulas matemáticas de LaTeX.
- INDIVIDUAL_PAGES: Es una lista de páginas individuales para procesar.
- Revisa la lista de procesadores.
- Separa documentos en fragmentos legibles con el analizador de diseño.
- Crea un clasificador personalizado.
Crea un procesador de Enterprise Document OCR
Primero, crea un procesador de Enterprise Document OCR. Para obtener más información, consulta Crea y administra procesadores.
Configuraciones de OCR
Para habilitar todas las configuraciones de OCR, establece los campos respectivos en ProcessOptions.ocrConfig en ProcessDocumentRequest o BatchProcessDocumentsRequest.
Para obtener más información, consulta Cómo enviar una solicitud de procesamiento.
Análisis de la calidad de la imagen
El análisis inteligente de la calidad del documento usa el aprendizaje automático para evaluar la calidad de un documento según la legibilidad de su contenido.
Esta evaluación de calidad se devuelve como un nivel de calidad [0, 1], en el que 1 significa calidad perfecta.
Si el nivel de calidad detectado es inferior a 0.5, también se devuelve una lista de motivos de calidad negativos (ordenados por probabilidad).
Una probabilidad mayor que 0.5 se considera una detección positiva.
Si se considera que el documento es defectuoso, la API devuelve los siguientes ocho tipos de defectos:
El análisis de calidad del documento actual tiene algunas limitaciones:
Entrada
Para habilitar esta opción, configura ProcessOptions.ocrConfig.enableImageQualityScores como true en la solicitud de procesamiento.
Esta función adicional agrega latencia a la llamada de proceso comparable con el procesamiento de OCR.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableImageQualityScores": true
}
}
}
Salida
Los resultados de la detección de defectos aparecen en Document.pages[].imageQualityScores[].
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Consulta Resultado del procesador de muestra para ver ejemplos completos del resultado.
Sugerencias de idioma
El procesador de OCR admite sugerencias de idioma que defines para mejorar el rendimiento del motor de OCR. Aplicar una sugerencia de idioma permite que el OCR se optimice para un idioma seleccionado en lugar de un idioma inferido.
Entrada
Para habilitar esta opción, establece ProcessOptions.ocrConfig.hints[].languageHints[] con una lista de códigos de idioma BCP-47.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"hints": {
"languageHints": ["en", "es"]
}
}
}
}
Consulta Resultado del procesador de muestra para ver ejemplos completos del resultado.
Detección de símbolos
Propaga los datos a nivel del símbolo (o de la letra individual) en la respuesta del documento.
Entrada
Para habilitar esta opción, configura ProcessOptions.ocrConfig.enableSymbol como true en la solicitud de procesamiento.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableSymbol": true
}
}
}
Salida
Si esta función está habilitada, se propagará el campo Document.pages[].symbols[].
Consulta Resultado del procesador de muestra para ver ejemplos completos del resultado.
Análisis de PDF integrado
Extrae el texto incorporado de los archivos PDF digitales. Cuando está habilitado, si hay texto digital, se usa automáticamente el modelo de PDF digital integrado. Si hay texto no digital, se usa automáticamente el modelo de OCR óptico. El usuario recibe ambos resultados de texto combinados.
Entrada
Para habilitar esta opción, configura ProcessOptions.ocrConfig.enableNativePdfParsing como true en la solicitud de procesamiento.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": true
}
}
}
Detección de personajes en la caja
De forma predeterminada, Enterprise Document OCR tiene habilitado un detector para mejorar la calidad de la extracción de texto de los caracteres que se encuentran dentro de un cuadro. A continuación, se muestra un ejemplo:

Si tienes problemas de calidad del OCR con los caracteres dentro de los cuadros, puedes inhabilitarlo.
Entrada
Para inhabilitar esta opción, establece ProcessOptions.ocrConfig.disableCharacterBoxesDetection en true en la solicitud de procesamiento.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"disableCharacterBoxesDetection": true
}
}
}
Diseño heredado
Si necesitas un algoritmo de detección de diseño basado en la heurística, puedes habilitar el diseño heredado, que funciona como alternativa al algoritmo de detección de diseño actual basado en AA. Esta no es la configuración recomendada. Los clientes pueden elegir el algoritmo de diseño más adecuado según el flujo de trabajo de sus documentos.
Entrada
Para habilitar esta opción, configura ProcessOptions.ocrConfig.advancedOcrOptions como ["legacy_layout"] en la solicitud de procesamiento.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"advancedOcrOptions": ["legacy_layout"]
}
}
}
Cómo especificar un rango de páginas
De forma predeterminada, el OCR extrae información de texto y diseño de todas las páginas de los documentos. Puedes seleccionar números de página o rangos de páginas específicos y extraer texto solo de esas páginas.
Existen tres formas de configurar esta opción en ProcessOptions:
{
"individualPageSelector": {"pages": [2, 5]}
}
{
"fromStart": 3
}
{
"fromEnd": 4
}
En la respuesta, cada Document.pages[].pageNumber corresponde a las mismas páginas especificadas en la solicitud.
Usos de los complementos de OCR
Estas funciones de análisis opcionales de Enterprise Document OCR se pueden habilitar en solicitudes de procesamiento individuales según sea necesario.
OCR matemático
El OCR matemático detecta, reconoce y extrae fórmulas, como ecuaciones matemáticas representadas como LaTeX, junto con las coordenadas del cuadro delimitador.
A continuación, se muestra un ejemplo de representación en LaTeX:
Entrada
Para habilitar esta opción, configura ProcessOptions.ocrConfig.premiumFeatures.enableMathOcr como true en la solicitud de procesamiento.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableMathOcr": true
}
}
}
}
Salida
El resultado del OCR de ecuaciones aparece en Document.pages[].visualElements[] con "type": "math_formula".
"visualElements": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "46"
}
]
},
"confidence": 1,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.14662756,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.8027211
},
{
"x": 0.14662756,
"y": 0.8027211
}
]
},
"orientation": "PAGE_UP"
},
"type": "math_formula"
}
]
Puedes consultar el resultado JSON completo de Document en este vínculo .
Extracción de marcas de selección
Si está habilitado, el modelo intenta extraer todas las casillas de verificación y los botones de opción del documento, junto con las coordenadas del cuadro delimitador.
Entrada
Para habilitar esta opción, configura ProcessOptions.ocrConfig.premiumFeatures.enableSelectionMarkDetection como true en la solicitud de procesamiento.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableSelectionMarkDetection": true
}
}
}
}
Salida
El resultado de la casilla de verificación aparece en Document.pages[].visualElements[] con "type": "unfilled_checkbox" o "type": "filled_checkbox".

"visualElements": [
{
"layout": {
"confidence": 0.89363575,
"boundingPoly": {
"vertices": [
{
"x": 11,
"y": 24
},
{
"x": 37,
"y": 24
},
{
"x": 37,
"y": 56
},
{
"x": 11,
"y": 56
}
],
"normalizedVertices": [
{
"x": 0.017488075,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.9032258
},
{
"x": 0.017488075,
"y": 0.9032258
}
]
}
},
"type": "unfilled_checkbox"
},
{
"layout": {
"confidence": 0.9148201,
"boundingPoly": ...
},
"type": "filled_checkbox"
}
],
Puedes consultar el resultado JSON completo de Document en este vínculo .
Detección del estilo de fuente
Con la detección de estilo de fuente habilitada, Enterprise Document OCR extrae atributos de fuente, que se pueden usar para un mejor procesamiento posterior.
A nivel del token (palabra), se detectan los siguientes atributos:
Entrada
Para habilitar esta opción, configura ProcessOptions.ocrConfig.premiumFeatures.computeStyleInfo como true en la solicitud de procesamiento.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"computeStyleInfo": true
}
}
}
}
Salida
El resultado de font-style aparece en Document.pages[].tokens[].styleInfo con el tipo StyleInfo.

"tokens": [
{
"styleInfo": {
"fontSize": 3,
"pixelFontSize": 13,
"fontType": "SANS_SERIF",
"bold": true,
"fontWeight": 564,
"textColor": {
"red": 0.16862746,
"green": 0.16862746,
"blue": 0.16862746
},
"backgroundColor": {
"red": 0.98039216,
"green": 0.9882353,
"blue": 0.99215686
}
}
},
...
]
Puedes consultar el resultado JSON completo de Document en este vínculo .
Convierte objetos de documentos al formato de la API de Vision AI
La caja de herramientas de Document AI incluye una herramienta que convierte el formato Document de la API de Document AI al formato AnnotateFileResponse de la API de Vision AI, lo que permite a los usuarios comparar las respuestas entre el procesador de OCR de documentos y la API de Vision AI. Aquí tienes un código de muestra.
Discrepancias conocidas entre la respuesta de la API de Vision AI y la respuesta y el convertidor de la API de Document AI:
Muestras de código
En las siguientes muestras de código, se muestra cómo enviar una solicitud de procesamiento que habilite los complementos y la configuración del OCR, y, luego, leer e imprimir los campos en la terminal:
REST
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
† Este contenido también se puede especificar con contenido codificado en base64 en el objeto inlineDocument.
Método HTTP y URL:
POST https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
Cuerpo JSON de la solicitud:
{
"skipHumanReview": skipHumanReview,
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"fieldMask": "FIELD_MASK",
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": ENABLE_NATIVE_PDF_PARSING,
"enableImageQualityScores": ENABLE_IMAGE_QUALITY_SCORES,
"enableSymbol": ENABLE_SYMBOL,
"disableCharacterBoxesDetection": DISABLE_CHARACTER_BOXES_DETECTION,
"hints": {
"languageHints": [
"LANGUAGE_HINTS"
]
},
"advancedOcrOptions": ["ADVANCED_OCR_OPTIONS"],
"premiumFeatures": {
"enableSelectionMarkDetection": ENABLE_SELECTION_MARK_DETECTION,
"computeStyleInfo": COMPUTE_STYLE_INFO,
"enableMathOcr": ENABLE_MATH_OCR,
}
},
"individualPageSelector" {
"pages": [INDIVIDUAL_PAGES]
}
}
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
Si la solicitud se completa de forma correcta, el servidor muestra un código de estado HTTP 200 OK y la respuesta en formato JSON. El cuerpo de la respuesta contiene una instancia de
Document.
Python
Para obtener más información, consulta la documentación de referencia de la API de Document AI Python.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.