Sie können Enterprise Document OCR als Teil von Document AI verwenden, um Text und Layoutinformationen aus verschiedenen Dokumenten zu erkennen und zu extrahieren. Mit konfigurierbaren Funktionen können Sie das System an spezifische Anforderungen an die Dokumentenverarbeitung anpassen.
Übersicht
Sie können Enterprise Document OCR für Aufgaben wie die Dateneingabe auf Grundlage von Algorithmen oder maschinellem Lernen sowie zur Verbesserung und Überprüfung der Datengenauigkeit verwenden. Sie können Enterprise Document OCR auch für Aufgaben wie die folgenden verwenden:
- Text digitalisieren:Extrahieren Sie Text- und Layoutdaten aus Dokumenten für die Suche, regelbasierte Pipelines zur Dokumentverarbeitung oder die Erstellung benutzerdefinierter Modelle.
- Anwendungen mit Large Language Models verwenden:Nutzen Sie das kontextbezogene Verständnis von LLMs und die Funktionen von OCR zum Extrahieren von Text und Layout, um Fragen und Antworten zu automatisieren. Erkenntnisse aus Daten gewinnen und Workflows optimieren
- Archivierung:Papierdokumente in maschinenlesbaren Text digitalisieren, um die Zugänglichkeit von Dokumenten zu verbessern.
Die beste OCR-Lösung für Ihren Anwendungsfall auswählen
| Lösung | Produkt | Beschreibung | Anwendungsfall |
|---|---|---|---|
| Document AI | Enterprise Document OCR | Spezialisiertes Modell für Dokumentanwendungsfälle. Zu den erweiterten Funktionen gehören der Bildqualitätsfaktor, Sprachhinweise und die Korrektur der Drehung. | Empfohlen, wenn Text aus Dokumenten extrahiert wird. Anwendungsfälle sind unter anderem PDFs, gescannte Dokumente als Bilder oder Microsoft DocX-Dateien. |
| Document AI | OCR-Add-ons | Premium-Funktionen für spezifische Anforderungen Nur mit Enterprise Document OCR Version 2.0 und höher kompatibel. | Sie müssen mathematische Formeln erkennen und identifizieren, Informationen zum Schriftstil erhalten oder die Extraktion von Kästchen aktivieren. |
| Cloud Vision API | Texterkennung | Global verfügbare REST API basierend auf dem Google Cloud Standard-OCR-Modell. Standardkontingent von 1.800 Anfragen pro Minute. | Allgemeine Anwendungsfälle für die Textextraktion, die eine niedrige Latenz und hohe Kapazität erfordern. |
| Cloud Vision | OCR Google Distributed Cloud (nicht mehr unterstützt) | Google Cloud Marketplace-Anwendung, die als Container in jedem GKE-Cluster bereitgestellt werden kann, der GKE Enterprise verwendet. | Um Anforderungen an den Datenstandort oder Compliance-Anforderungen zu erfüllen. |
Erkennung und Extraktion
Mit Enterprise Document OCR können Blöcke, Absätze, Zeilen, Wörter und Symbole aus PDFs und Bildern erkannt und Dokumente für eine bessere Genauigkeit begradigt werden.
Unterstützte Attribute für Layout-Erkennung und ‑Extraktion:
| Gedruckter Text | Handschrift | Absatz | Blockieren | Linie | Wortmarke | Symbol-Ebene | Seitenzahl |
|---|---|---|---|---|---|---|---|
| Standard | Standard | Standard | Standard | Standard | Standard | Konfigurierbar | Standard |
Zu den konfigurierbaren Enterprise Document OCR-Funktionen gehören:
Eingebetteten oder nativen Text aus digitalen PDFs extrahieren:Mit dieser Funktion wird Text und werden Symbole genau so extrahiert, wie sie in den Quelldokumenten angezeigt werden. Das gilt auch für gedrehten Text, extreme Schriftgrößen oder ‑stile und teilweise verborgenen Text.
Korrektur der Rotation:Mit Enterprise Document OCR können Sie Dokumentbilder vorverarbeiten, um Rotationsprobleme zu beheben, die sich auf die Qualität der Extraktion oder die Verarbeitung auswirken können.
Bewertung der Bildqualität:Sie erhalten Qualitätsmesswerte, die beim Weiterleiten von Dokumenten helfen können. Der Bildqualitätsfaktor liefert Ihnen Qualitätsmesswerte auf Seitenebene in acht Dimensionen, darunter Unschärfe, das Vorhandensein von ungewöhnlich kleinen Schriftarten und Blendung.
Seitenbereich angeben:Gibt den Bereich der Seiten in einem Eingabedokument für die OCR an. So werden Ausgaben und Verarbeitungszeit für unnötige Seiten gespart.
Spracherkennung:Erkennt die Sprachen, die in den extrahierten Texten verwendet werden.
Sprach- und Handschrifthinweise:Sie können die Genauigkeit verbessern, indem Sie dem OCR-Modell einen Sprach- oder Handschrifthinweis basierend auf den bekannten Merkmalen Ihres Datasets geben.
Informationen zum Aktivieren von OCR-Konfigurationen finden Sie unter OCR-Konfigurationen aktivieren.
OCR-Add-ons
Enterprise Document OCR bietet optionale Analysefunktionen, die bei Bedarf für einzelne Verarbeitungsanfragen aktiviert werden können.
Die folgenden Add-on-Funktionen sind für die stabilen Versionen pretrained-ocr-v2.0-2023-06-02 und pretrained-ocr-v2.1-2024-08-07 sowie für die Release-Kandidaten-Version pretrained-ocr-v2.1.1-2025-01-31 verfügbar.
- Math OCR: Formeln in Dokumenten im LaTeX-Format erkennen und extrahieren.
- Extrahieren von Kästchen: Erkennen von Kästchen und Extrahieren ihres Status (markiert/nicht markiert) in der Enterprise Document OCR-Antwort.
- Erkennung des Schriftstils: Identifizieren Sie Schriftart, Schriftstil, Handschrift, Stärke und Farbe auf Wortebene.
Informationen zum Aktivieren der aufgeführten Add-ons finden Sie unter OCR-Add-ons aktivieren.
Unterstützte Dateiformate
Enterprise Document OCR unterstützt die Dateiformate PDF, GIF, TIFF, JPEG, PNG, BMP und WebP. Weitere Informationen finden Sie unter Unterstützte Dateien.
Enterprise Document OCR unterstützt auch DocX-Dateien mit bis zu 15 Seiten bei synchronen und 30 Seiten bei asynchronen Anfragen. Folgen Sie der Anleitung unter Kontingentanpassung anfordern, um eine Anfrage zur Kontingenterhöhung zu stellen. Die Unterstützung von DocX ist in der privaten Vorschau verfügbar. Wenden Sie sich an Ihr Google-Kontoteam, um Zugriff zu erhalten.
Erweiterte Versionsverwaltung
Die erweiterte Versionsverwaltung befindet sich in der Vorschau. Durch Upgrades der zugrunde liegenden KI-/ML-OCR-Modelle kann sich das OCR-Verhalten ändern. Wenn strikte Konsistenz erforderlich ist, verwenden Sie eine eingefrorene Modellversion, um das Verhalten für bis zu 18 Monate an ein altes OCR-Modell zu binden. So wird sichergestellt, dass das Ergebnis der OCR-Funktion für dasselbe Bild gleich ist. Tabelle mit Prozessorversionen
Prozessorversionen
Die folgenden Prozessorversionen sind mit dieser Funktion kompatibel. Weitere Informationen finden Sie unter Prozessorversionen verwalten.
| Versions-ID | Release-Version | Beschreibung |
|---|---|---|
pretrained-ocr-v1.2-2022-11-10 |
Stabil | Eingefrorene Modellversion 1.0: Modelldateien, Konfigurationen und Binärdateien einer Versionsmomentaufnahme, die bis zu 18 Monate lang in einem Container-Image eingefroren sind. |
pretrained-ocr-v2.0-2023-06-02 |
Stabil | Produktionsreifes Modell, das auf Dokumentanwendungsfälle spezialisiert ist. Beinhaltet den Zugriff auf alle OCR-Add-ons. |
pretrained-ocr-v2.1-2024-08-07 |
Stabil | Die wichtigsten Verbesserungen in Version 2.1 sind: bessere Erkennung von gedrucktem Text, genauere Erkennung von Kästchen und eine präzisere Lesereihenfolge. |
pretrained-ocr-v2.1.1-2025-01-31 |
Releasekandidat | v2.1.1 ähnelt V2.1 und ist in allen Regionen verfügbar, mit Ausnahme von US, EU und asia-southeast1. |
Dokumente mit Enterprise Document OCR verarbeiten
In dieser Kurzanleitung wird Enterprise Document OCR vorgestellt. Hier erfahren Sie, wie Sie die OCR-Ergebnisse für Dokumente für Ihren Workflow optimieren, indem Sie eine der verfügbaren OCR-Konfigurationen aktivieren oder deaktivieren.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. quality/defect_blurryquality/defect_noisyquality/defect_darkquality/defect_faintquality/defect_text_too_smallquality/defect_document_cutoffquality/defect_text_cutoffquality/defect_glare- Es kann zu falsch-positiven Erkennungen bei digitalen Dokumenten ohne Mängel kommen. Die Funktion eignet sich am besten für gescannte oder fotografierte Dokumente.
Blendungsfehler sind lokal. Sie beeinträchtigen möglicherweise nicht die allgemeine Lesbarkeit des Dokuments.
- So verarbeiten Sie nur die zweite und fünfte Seite:
- So verarbeiten Sie nur die ersten drei Seiten:
- So verarbeiten Sie nur die letzten vier Seiten:
Bild erkannt
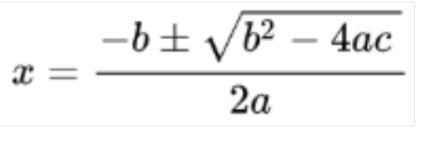
Konvertierung in LaTeX
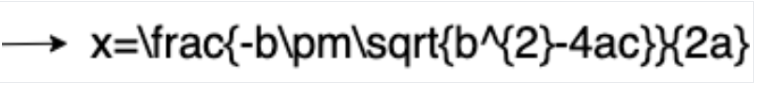
- Handschrifterkennung
- Schriftstil
- Schriftgröße
- Schriftart
- Schriftfarbe
- Schriftstärke
- Zeichenabstand
- Fett
- Kursiv
- Unterstreichen
- Textfarbe (RGBa)
Hintergrundfarbe (RGBa)
- In der Vision AI API-Antwort wird nur
verticesfür Bildanfragen und nurnormalized_verticesfür PDF-Anfragen ausgefüllt. Die Document AI-Antwort und der Converter füllen sowohlverticesals auchnormalized_verticesaus. - Die Vision AI API-Antwort füllt das
detected_breakim letzten Symbol des Wortes aus. In der Document AI API-Antwort und im Konverter wirddetected_breakim Wort und im letzten Symbol des Wortes eingefügt. - In der Vision AI API-Antwort werden immer Symbolfelder ausgefüllt. Standardmäßig werden Symbolfelder in der Document AI-Antwort nicht ausgefüllt. Damit die Felder für Symbole in der Document AI-Antwort und im Converter ausgefüllt werden, legen Sie die Funktion
enable_symbolauf „detailed“ (detailliert) fest. - LOCATION: Der Standort Ihres Prozessors, z. B.
us– USAeu– Europäische Union
- PROJECT_ID: Ihre Google Cloud -Projekt-ID
- PROCESSOR_ID: Die ID Ihres benutzerdefinierten Prozessors.
- PROCESSOR_VERSION: die Kennung der Prozessorversion. Weitere Informationen finden Sie unter Prozessorversion auswählen. Beispiel:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- skipHumanReview: Ein boolescher Wert zum Deaktivieren der manuellen Überprüfung (wird nur von Human-in-the-Loop-Prozessoren unterstützt).
true– Manuelle Überprüfung wird übersprungenfalse: Aktiviert die manuelle Überprüfung (Standard).
- MIME_TYPE†: Eine der gültigen Optionen für den MIME-Typ.
- IMAGE_CONTENT†: Einer der gültigen Inline-Dokumentinhalte, dargestellt als Bytestream. Für JSON-Darstellungen die Base64-Codierung (ASCII-String) Ihrer Binärbilddaten. Dieser String sollte in etwa so aussehen:
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==
- FIELD_MASK: Gibt an, welche Felder in die
Document-Ausgabe aufgenommen werden sollen. Dies ist eine durch Kommas getrennte Liste vollständig qualifizierter Feldnamen im FormatFieldMask.- Beispiel:
text,entities,pages.pageNumber
- Beispiel:
- OCR-Konfigurationen
- ENABLE_NATIVE_PDF_PARSING: (Boolesch) Extrahiert eingebetteten Text aus PDFs, sofern verfügbar.
- ENABLE_IMAGE_QUALITY_SCORES: (boolesch) Aktiviert intelligente Dokumentqualitätswerte.
- ENABLE_SYMBOL: (boolesch) Schließt OCR-Informationen für Symbole (Buchstaben) ein.
- DISABLE_CHARACTER_BOXES_DETECTION: (Boolesch) Deaktivieren Sie die Erkennung von Zeichenkästen in der OCR-Engine.
- LANGUAGE_HINTS: Liste der BCP-47-Sprachcodes, die für die OCR verwendet werden sollen.
- ADVANCED_OCR_OPTIONS: Eine Liste mit erweiterten OCR-Optionen, mit denen das OCR-Verhalten weiter optimiert werden kann. Aktuell gültige Werte:
legacy_layout: Ein heuristischer Algorithmus zur Layout-Erkennung, der als Alternative zum aktuellen ML-basierten Algorithmus zur Layout-Erkennung dient.
- Premium-OCR-Add-ons
- ENABLE_SELECTION_MARK_DETECTION: (Boolesch) Aktivieren Sie die Erkennung von Auswahlmarkierungen in der OCR-Engine.
- COMPUTE_STYLE_INFO (boolesch): Aktivieren Sie das Modell zur Schriftarterkennung, um Informationen zur Schriftart zurückzugeben.
- ENABLE_MATH_OCR: (Boolesch) Aktivieren Sie das Modell, das mathematische Formeln aus LaTeX extrahieren kann.
- INDIVIDUAL_PAGES: Eine Liste der einzelnen Seiten, die verarbeitet werden sollen.
- Sehen Sie sich die Liste der Prozessoren an.
- Mit dem Layout-Parser können Sie Dokumente in lesbare Blöcke unterteilen.
- Erstellen Sie einen benutzerdefinierten Klassifikator.
Enterprise Document OCR-Prozessor erstellen
Erstellen Sie zuerst einen Enterprise Document OCR-Prozessor. Weitere Informationen finden Sie unter Prozessoren erstellen und verwalten.
OCR-Konfigurationen
Alle OCR-Konfigurationen können aktiviert werden, indem die entsprechenden Felder in ProcessOptions.ocrConfig in ProcessDocumentRequest oder BatchProcessDocumentsRequest festgelegt werden.
Weitere Informationen finden Sie unter Verarbeitungsanfrage senden.
Analyse der Bildqualität
Bei der intelligenten Analyse der Dokumentqualität wird maschinelles Lernen eingesetzt, um die Qualität eines Dokuments anhand der Lesbarkeit des Inhalts zu bewerten.
Diese Qualitätsbewertung wird als Qualitätsfaktor [0, 1] zurückgegeben, wobei 1 für perfekte Qualität steht.
Wenn der erkannte Qualitätsfaktor niedriger als 0.5 ist, wird auch eine Liste mit Gründen für die niedrige Qualität zurückgegeben, die nach Wahrscheinlichkeit sortiert ist.
Eine Wahrscheinlichkeit über 0.5 gilt als positiver Fund.
Wenn das Dokument als fehlerhaft eingestuft wird, gibt die API die folgenden acht Dokumentfehlertypen zurück:
Die aktuelle Analyse der Dokumentqualität unterliegt einigen Einschränkungen:
Eingabe
Aktivieren Sie diese Option, indem Sie ProcessOptions.ocrConfig.enableImageQualityScores in der Verarbeitungsanfrage auf true setzen.
Diese zusätzliche Funktion erhöht die Latenz des Prozessaufrufs im Vergleich zur OCR-Verarbeitung.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableImageQualityScores": true
}
}
}
Ausgabe
Die Ergebnisse der Fehlererkennung werden in Document.pages[].imageQualityScores[] angezeigt.
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Vollständige Beispiele für die Ausgabe finden Sie unter Beispiel für Prozessorausgabe.
Sprachhinweise
Der OCR-Prozessor unterstützt Sprachhinweise, die Sie definieren können, um die Leistung der OCR-Engine zu verbessern. Wenn Sie einen Sprachhinweis anwenden, kann die OCR für eine ausgewählte Sprache anstelle einer abgeleiteten Sprache optimiert werden.
Eingabe
Aktivieren Sie die Funktion, indem Sie ProcessOptions.ocrConfig.hints[].languageHints[] mit einer Liste von BCP-47-Sprachcodes festlegen.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"hints": {
"languageHints": ["en", "es"]
}
}
}
}
Vollständige Beispiele für die Ausgabe finden Sie unter Beispiel für Prozessorausgabe.
Symbolerkennung
Daten auf Symbolebene (oder auf Ebene einzelner Buchstaben) in die Dokumentantwort einfügen.
Eingabe
Aktivieren Sie diese Option, indem Sie ProcessOptions.ocrConfig.enableSymbol in der Verarbeitungsanfrage auf true setzen.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableSymbol": true
}
}
}
Ausgabe
Wenn diese Funktion aktiviert ist, wird das Feld Document.pages[].symbols[] ausgefüllt.
Vollständige Beispiele für die Ausgabe finden Sie unter Beispiel für Prozessorausgabe.
Integriertes Parsen von PDFs
Eingebetteten Text aus digitalen PDF-Dateien extrahieren Wenn diese Option aktiviert ist und digitaler Text vorhanden ist, wird automatisch das integrierte digitale PDF-Modell verwendet. Wenn nicht digitaler Text vorhanden ist, wird automatisch das optische OCR-Modell verwendet. Der Nutzer erhält beide Textergebnisse zusammengefasst.
Eingabe
Aktivieren Sie diese Option, indem Sie ProcessOptions.ocrConfig.enableNativePdfParsing in der Verarbeitungsanfrage auf true setzen.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": true
}
}
}
Erkennung von Figuren in einem Rechteck
Standardmäßig ist in Enterprise Document OCR ein Detektor aktiviert, um die Qualität der Textextraktion von Zeichen in einem Feld zu verbessern. Hier ein Beispiel:

Wenn Sie Probleme mit der OCR-Qualität bei Zeichen in Kästen haben, können Sie die Funktion deaktivieren.
Eingabe
Deaktivieren Sie die Funktion, indem Sie ProcessOptions.ocrConfig.disableCharacterBoxesDetection in der Verarbeitungsanfrage auf true setzen.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"disableCharacterBoxesDetection": true
}
}
}
Altes Layout
Wenn Sie einen heuristischen Algorithmus zur Layout-Erkennung benötigen, können Sie das Legacy-Layout aktivieren. Es dient als Alternative zum aktuellen ML-basierten Algorithmus zur Layout-Erkennung. Dies ist nicht die empfohlene Konfiguration. Kunden können den Layoutalgorithmus auswählen, der am besten zu ihrem Dokumentworkflow passt.
Eingabe
Aktivieren Sie diese Option, indem Sie ProcessOptions.ocrConfig.advancedOcrOptions in der Verarbeitungsanfrage auf ["legacy_layout"] setzen.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"advancedOcrOptions": ["legacy_layout"]
}
}
}
Seitenbereich angeben
Standardmäßig werden mit OCR Text- und Layoutinformationen von allen Seiten der Dokumente extrahiert. Sie können bestimmte Seitenzahlen oder Seitenbereiche auswählen und nur Text von diesen Seiten extrahieren.
Es gibt drei Möglichkeiten, dies in ProcessOptions zu konfigurieren:
{
"individualPageSelector": {"pages": [2, 5]}
}
{
"fromStart": 3
}
{
"fromEnd": 4
}
In der Antwort entspricht jedes Document.pages[].pageNumber den Seiten, die in der Anfrage angegeben sind.
Verwendung von OCR-Add-ons
Diese optionalen Analysefunktionen für Enterprise Document OCR können bei Bedarf für einzelne Verarbeitungsanfragen aktiviert werden.
Mathematik-OCR
Mit der mathematischen OCR werden Formeln wie mathematische Gleichungen, die als LaTeX dargestellt werden, zusammen mit den Koordinaten des Begrenzungsrahmens erkannt, erkannt und extrahiert.
Hier ein Beispiel für die LaTeX-Darstellung:
Eingabe
Aktivieren Sie diese Option, indem Sie ProcessOptions.ocrConfig.premiumFeatures.enableMathOcr in der Verarbeitungsanfrage auf true setzen.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableMathOcr": true
}
}
}
}
Ausgabe
Die Math OCR-Ausgabe wird in Document.pages[].visualElements[] mit "type": "math_formula" angezeigt.
"visualElements": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "46"
}
]
},
"confidence": 1,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.14662756,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.8027211
},
{
"x": 0.14662756,
"y": 0.8027211
}
]
},
"orientation": "PAGE_UP"
},
"type": "math_formula"
}
]
Die vollständige Document-JSON-Ausgabe finden Sie unter diesem Link .
Extraktion von Auswahlmarkierungen
Falls aktiviert, versucht das Modell, alle Kästchen und Optionsfelder im Dokument zusammen mit den Koordinaten des Begrenzungsrahmens zu extrahieren.
Eingabe
Aktivieren Sie diese Option, indem Sie ProcessOptions.ocrConfig.premiumFeatures.enableSelectionMarkDetection in der Verarbeitungsanfrage auf true setzen.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableSelectionMarkDetection": true
}
}
}
}
Ausgabe
Die Checkbox-Ausgabe wird in Document.pages[].visualElements[] mit "type": "unfilled_checkbox" oder "type": "filled_checkbox" angezeigt.

"visualElements": [
{
"layout": {
"confidence": 0.89363575,
"boundingPoly": {
"vertices": [
{
"x": 11,
"y": 24
},
{
"x": 37,
"y": 24
},
{
"x": 37,
"y": 56
},
{
"x": 11,
"y": 56
}
],
"normalizedVertices": [
{
"x": 0.017488075,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.9032258
},
{
"x": 0.017488075,
"y": 0.9032258
}
]
}
},
"type": "unfilled_checkbox"
},
{
"layout": {
"confidence": 0.9148201,
"boundingPoly": ...
},
"type": "filled_checkbox"
}
],
Die vollständige Document-JSON-Ausgabe finden Sie unter diesem Link .
Erkennung des Schriftstils
Wenn die Schriftartenerkennung aktiviert ist, extrahiert Enterprise Document OCR Schriftartattribute, die für eine bessere Nachbearbeitung verwendet werden können.
Auf Token-Ebene (Wortebene) werden die folgenden Attribute erkannt:
Eingabe
Aktivieren Sie diese Option, indem Sie ProcessOptions.ocrConfig.premiumFeatures.computeStyleInfo in der Verarbeitungsanfrage auf true setzen.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"computeStyleInfo": true
}
}
}
}
Ausgabe
Die Ausgabe für „font-style“ wird in Document.pages[].tokens[].styleInfo mit dem Typ StyleInfo angezeigt.

"tokens": [
{
"styleInfo": {
"fontSize": 3,
"pixelFontSize": 13,
"fontType": "SANS_SERIF",
"bold": true,
"fontWeight": 564,
"textColor": {
"red": 0.16862746,
"green": 0.16862746,
"blue": 0.16862746
},
"backgroundColor": {
"red": 0.98039216,
"green": 0.9882353,
"blue": 0.99215686
}
}
},
...
]
Die vollständige Document-JSON-Ausgabe finden Sie unter diesem Link .
Dokumentobjekte in das Vision AI API-Format konvertieren
Die Document AI Toolbox enthält ein Tool, mit dem das Document-Format der Document AI API in das AnnotateFileResponse-Format der Vision AI API konvertiert werden kann. So können Nutzer die Antworten des Dokument-OCR-Prozessors und der Vision AI API vergleichen. Beispielcode
Bekannte Abweichungen zwischen der Vision AI API-Antwort und der Document AI API-Antwort und dem Converter:
Codebeispiele
Die folgenden Codebeispiele zeigen, wie Sie eine Verarbeitungsanfrage senden, die OCR-Konfigurationen und ‑Add-ons aktiviert, und dann die Felder lesen und im Terminal ausgeben:
REST
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
† Diese Inhalte können auch mit base64-codierten Inhalten im inlineDocument-Objekt angegeben werden.
HTTP-Methode und URL:
POST https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
JSON-Text der Anfrage:
{
"skipHumanReview": skipHumanReview,
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"fieldMask": "FIELD_MASK",
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": ENABLE_NATIVE_PDF_PARSING,
"enableImageQualityScores": ENABLE_IMAGE_QUALITY_SCORES,
"enableSymbol": ENABLE_SYMBOL,
"disableCharacterBoxesDetection": DISABLE_CHARACTER_BOXES_DETECTION,
"hints": {
"languageHints": [
"LANGUAGE_HINTS"
]
},
"advancedOcrOptions": ["ADVANCED_OCR_OPTIONS"],
"premiumFeatures": {
"enableSelectionMarkDetection": ENABLE_SELECTION_MARK_DETECTION,
"computeStyleInfo": COMPUTE_STYLE_INFO,
"enableMathOcr": ENABLE_MATH_OCR,
}
},
"individualPageSelector" {
"pages": [INDIVIDUAL_PAGES]
}
}
}
Wenn Sie die Anfrage senden möchten, wählen Sie eine der folgenden Optionen aus:
curl
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
Wenn die Anfrage erfolgreich ist, gibt der Server den HTTP-Statuscode 200 OK und die Antwort im JSON-Format zurück. Der Antworttext enthält eine Instanz von Document.
Python
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Python API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.