Memberi label dokumen
Set data berlabel dokumen diperlukan untuk melatih, melatih ulang, atau mengevaluasi versi pemroses.
Halaman ini menjelaskan cara menerapkan label dari skema pemroses ke dokumen yang diimpor dalam set data Anda.
Halaman ini mengasumsikan bahwa Anda telah membuat pemroses yang mendukung pelatihan, pelatihan ulang, atau evaluasi. Jika prosesor Anda didukung, Anda akan melihat tab Train di konsol Google Cloud . Panduan ini juga mengasumsikan bahwa Anda telah membuat set data, mengimpor dokumen, dan menentukan skema prosesor.
Menamai kolom untuk ekstraksi AI generatif
Cara penamaan kolom memengaruhi akurasi ekstraksi kolom menggunakan AI generatif. Kami merekomendasikan praktik terbaik berikut saat memberi nama kolom:
Beri nama kolom dengan bahasa yang sama yang digunakan untuk mendeskripsikannya dalam dokumen: Misalnya, jika dokumen memiliki kolom yang dideskripsikan sebagai
Employer Address, maka beri nama kolom tersebutemployer_address. Jangan gunakan singkatan sepertiemplr_addr.Spasi saat ini tidak didukung dalam nama kolom: Daripada menggunakan spasi, gunakan
_. Misalnya:First Nameakan diberi namafirst_name.Ulangi nama untuk meningkatkan akurasi: Document AI memiliki batasan yang tidak memungkinkan perubahan nama kolom. Untuk menguji nama yang berbeda, gunakan alat penggantian nama entitas untuk memperbarui nama entitas lama dengan nama yang lebih baru dalam set data, impor set data, aktifkan entitas baru di pemroses, dan nonaktifkan atau hapus kolom yang ada.
Pemelajaran zero-shot dan few-shot
Model dengan Gemini memiliki pembelajaran zero-shot dan few-shot, yang dapat membuat model berperforma tinggi dengan sedikit atau tanpa data pelatihan.
Zero-shot learning adalah contoh machine learning di mana model terlatih tanpa pelatihan ulang apa pun belajar mengenali dan mengklasifikasikan kelas dan entity yang belum pernah ditemuinya sebelumnya selama pengujian.
Pembelajaran sedikit contoh (few-shot learning) adalah teknik di mana model belajar mengenali dan mengklasifikasikan class dan entitas baru hanya dengan beberapa contoh pelatihan per class. Model ini memanfaatkan pengetahuan dari model terlatih pada set data besar yang diberi label dengan baik untuk meningkatkan performa pada tugas few-shot.
Pembelajaran sedikit data menjadi lebih efektif jika set data pelatihan rapi dan diberi label dengan cermat. Biasanya, ini berarti harus ada minimal 10 contoh pengujian dan 10 contoh pelatihan yang tersedia agar model dapat mempelajarinya.
Opsi pemberian label
Berikut opsi untuk memberi label pada dokumen:
Manual: memberi label pada dokumen Anda secara manual di konsol Google Cloud
Pelabelan otomatis: menggunakan versi pemroses yang ada untuk membuat label
Mengimpor dokumen yang telah diberi label sebelumnya: menghemat waktu jika Anda sudah memiliki dokumen yang diberi label
Memberi label secara manual di konsol Google Cloud
Di tab Latih, pilih dokumen untuk membuka alat pelabelan.
Dari daftar label skema di sisi kiri alat pelabelan, pilih simbol 'Tambahkan' untuk memilih alat Kotak pembatas guna menandai entitas dalam dokumen dan menetapkannya ke label.
Pada screenshot berikut, kolom EMPL_SSN EMPLR_ID_NUMBER, EMPLR_NAME_ADDRESS,
FEDERAL_INCOME_TAX_WH, SS_TAX_WH, SS_WAGES, dan WAGES_TIPS_OTHER_COMP
dalam dokumen telah diberi label.
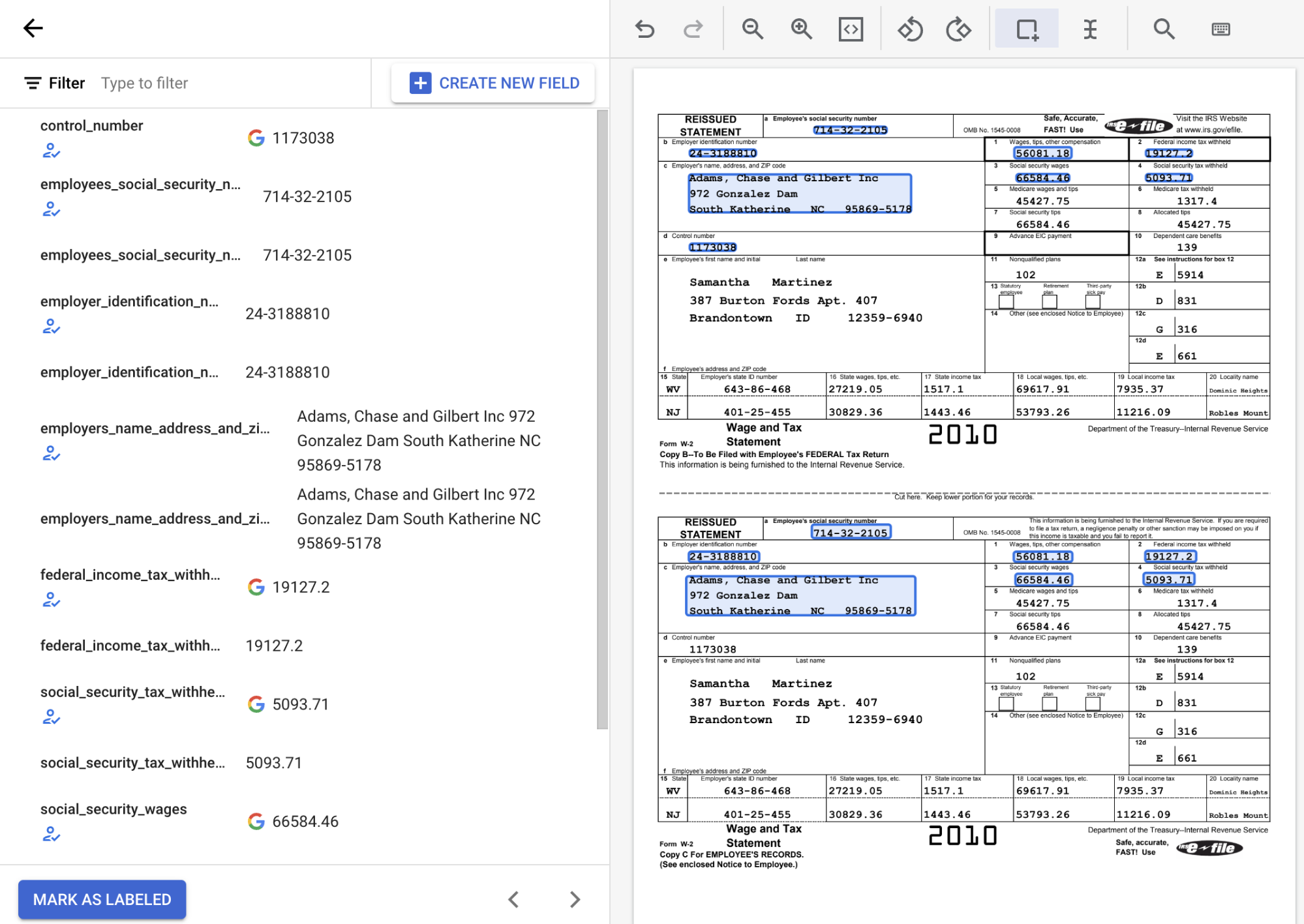
Saat Anda memilih entitas kotak centang dengan alat Kotak pembatas, pilih kotak centang itu sendiri, dan bukan teks terkait. Pastikan entitas kotak centang yang ditampilkan di sebelah kiri dipilih atau tidak dipilih agar sesuai dengan yang ada di dokumen.

Saat memberi label pada entity induk-turunan, jangan beri label pada entity induk. Entitas induk hanyalah penampung entitas turunan. Hanya beri label pada entitas turunan. Entitas induk diperbarui secara otomatis.
Saat memberi label pada entity turunan, beri label pada entity turunan pertama, lalu kaitkan entity turunan terkait dengan baris tersebut. Anda akan melihatnya di entitas anak kedua saat pertama kali memberi label pada entitas tersebut. Misalnya, dengan invoice, jika Anda memberi label description, invoice tersebut akan terlihat seperti entity lainnya. Namun, jika Anda melabeli jumlah berikutnya, Anda akan diminta untuk memilih induk.
Ulangi langkah ini untuk setiap item baris dengan memilih Entitas Induk Baru untuk setiap item baris baru.
Entitas induk-turunan didukung untuk tabel dengan hingga tiga lapisan penyusunan bertingkat. Model dasar mendukung tiga tingkat kolom (kakek/nenek, orang tua, anak), sehingga entitas anak dapat memiliki satu tingkat turunan. Untuk mempelajari lebih lanjut penyusunan bertingkat, lihat Penyusunan bertingkat tiga tingkat.
Tabel cepat
Saat memberi label pada tabel, memberi label pada setiap baris berulang kali bisa merepotkan. Ada alat yang sangat praktis yang dapat mereplikasi struktur entity baris. Perhatikan bahwa fitur ini hanya berfungsi pada baris yang disusun secara horizontal.
- Pertama, beri label pada baris pertama seperti biasa.
Kemudian, tahan kursor di atas entity induk yang merepresentasikan baris. Pilih Tambahkan baris lainnya. Baris tersebut menjadi template untuk membuat lebih banyak baris.
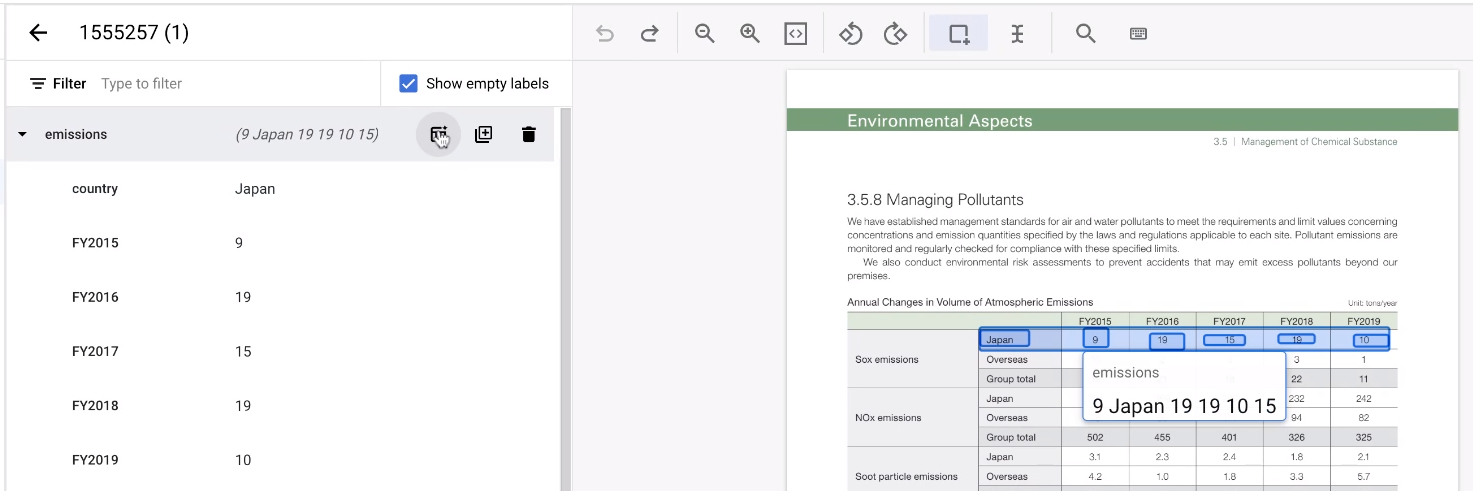
Pilih area tabel lainnya.
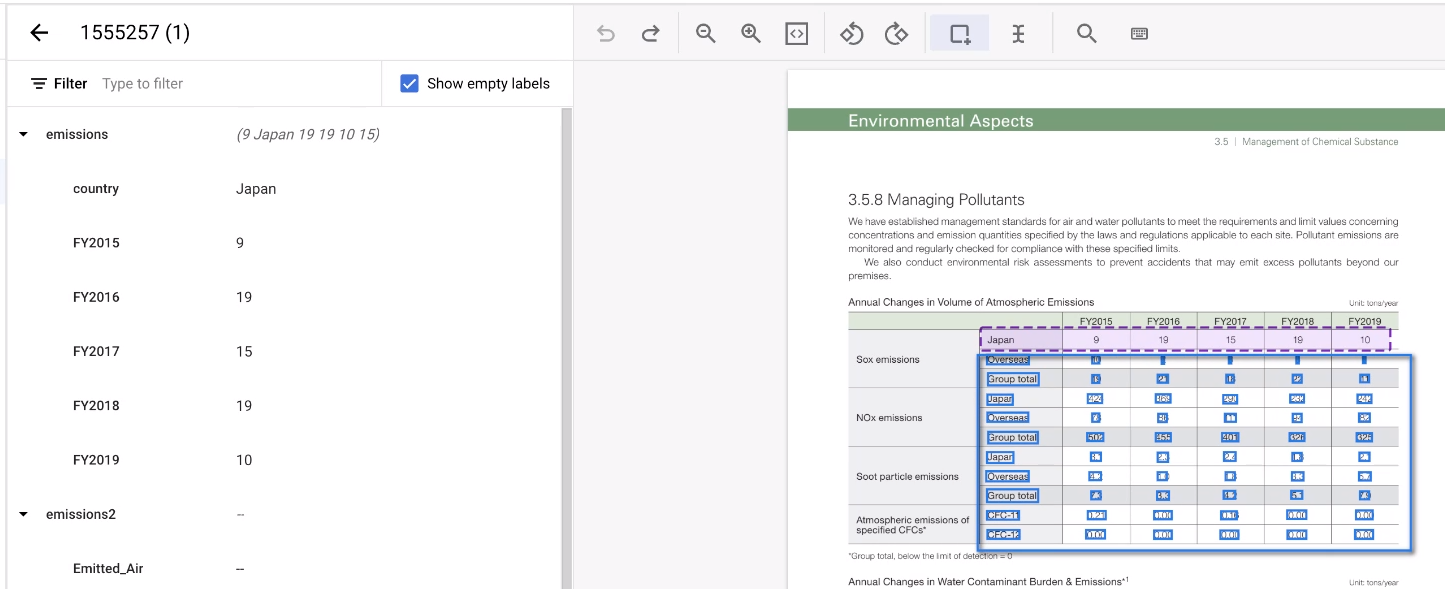
Alat ini menebak anotasi, dan biasanya berhasil. Untuk tabel yang tidak dapat ditangani, beri anotasi secara manual.
Menggunakan pintasan keyboard di konsol
Untuk melihat pintasan keyboard yang tersedia, pilih menu di kanan atas konsol pelabelan. Daftar pintasan keyboard akan ditampilkan, seperti yang ditunjukkan dalam tabel berikut.
| Tindakan | Pintasan |
|---|---|
| Perbesar | Alt + = (Option + = di macOS) |
| Perkecil | Alt + - (Option + - di macOS) |
| Zoom agar sesuai | Alt + 0 (Option + 0 di macOS) |
| Scroll untuk memperbesar/memperkecil | Alt + Scroll (Option + Scroll di macOS) |
| Menggeser | Scroll |
| Geser terbalik | Shift + Scroll |
| Tarik untuk menggeser | Spasi + Tarik mouse |
| Urungkan | Ctrl + Z (Control + Z di macOS) |
| Ulangi | Ctrl + Shift + Z (Control + +Shift + Z di macOS) |
Pelabelan otomatis
Jika tersedia, Anda dapat menggunakan versi prosesor yang ada untuk mulai memberi label.
Pemberian label otomatis dapat dimulai selama impor. Semua dokumen diberi anotasi menggunakan versi pemroses yang ditentukan.
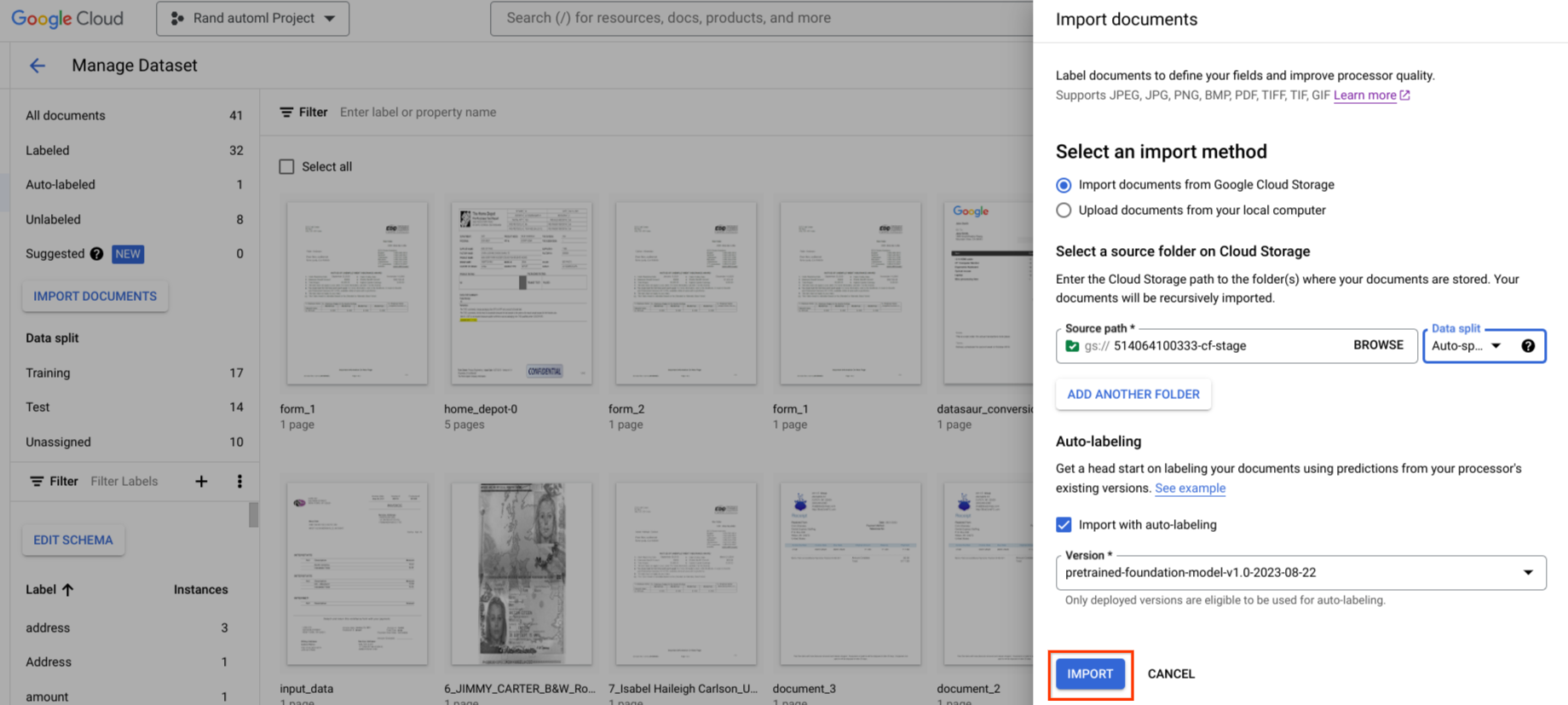
Pelabelan otomatis dapat dimulai setelah pengimporan untuk dokumen dalam kategori tidak berlabel atau berlabel otomatis. Semua dokumen yang dipilih diberi anotasi menggunakan versi pemroses yang ditentukan.
Anda tidak dapat melatih atau melatih ulang dokumen berlabel otomatis, atau menggunakannya dalam set pengujian, tanpa menandainya sebagai berlabel. Tinjau dan koreksi secara manual anotasi yang diberi label otomatis, lalu pilih Tandai sebagai Berlabel untuk menyimpan koreksi. Kemudian, Anda dapat menetapkan dokumen sesuai kebutuhan.
Mengimpor dokumen yang telah diberi label
Anda dapat mengimpor file JSON Document. Jika entity dalam dokumen cocok dengan label dalam skema
pemroses, entity akan dikonversi menjadi instance label oleh pengimpor. Ada beberapa cara untuk mendapatkan file Dokumen JSON:
Mengekspor set data dari pemroses lain. Lihat Mengekspor set data.
Mengirim permintaan pemrosesan ke pemroses yang ada.
Gunakan toolkit impor untuk mengonversi label yang ada dari sistem lain, misalnya, label format CSV ke dokumen JSON.
Praktik terbaik untuk memberi label pada dokumen
Pelabelan yang konsisten diperlukan untuk melatih prosesor berkualitas tinggi. Sebaiknya Anda:
Buat petunjuk pelabelan: Petunjuk Anda harus menyertakan contoh untuk kasus umum dan kasus ekstrem. Beberapa tips:
- Jelaskan kolom mana yang harus diberi anotasi dan cara membuat pelabelan yang konsisten. Misalnya, saat memberi label "jumlah", tentukan apakah simbol mata uang harus diberi label. Jika label tidak konsisten, kualitas pemrosesan akan berkurang.
- Beri label semua kemunculan entity, meskipun jenis labelnya adalah
REQUIRED_ONCEatauOPTIONAL_ONCE. Misalnya, jikainvoice_idmuncul dua kali dalam dokumen, beri label pada semua kemunculannya. - Umumnya, sebaiknya beri label dengan alat kotak pembatas default terlebih dahulu. Jika gagal, gunakan alat pilih teks.
- Jika nilai label tidak terdeteksi dengan benar oleh OCR, jangan memperbaiki nilai secara manual. Hal ini akan membuatnya tidak dapat digunakan untuk tujuan pelatihan.
Berikut beberapa contoh petunjuk pemberian label:
- Melatih penganotasi: pastikan penganotasi memahami dan dapat mengikuti pedoman tanpa error sistematis. Salah satu cara untuk melakukannya adalah dengan meminta peserta pelatihan yang berbeda menganotasi kumpulan dokumen yang sama. Pelatih kemudian dapat memeriksa kualitas pekerjaan anotasi setiap peserta pelatihan. Anda mungkin perlu mengulangi proses ini hingga peserta pelatihan mencapai tingkat akurasi tolok ukur.
- Ulasan awal: Beberapa dokumen pertama (sekitar 10) yang diberi label untuk kasus penggunaan oleh pemberi label baru harus ditinjau sebelum sejumlah besar dokumen diberi label untuk mencegah sejumlah besar kesalahan yang perlu diperbaiki.
- Peninjauan kualitas anotasi: Mengingat sifat anotasi yang melelahkan, bahkan anotator terlatih pun dapat membuat kesalahan. Sebaiknya anotasi diperiksa oleh setidaknya satu anotator terlatih lainnya.
Menambahkan perintah deskripsi
Saat menambahkan label ke skema di ekstraktor kustom dan pengklasifikasi kustom, Anda dapat menambahkan deskripsi untuk label tersebut. Hal ini membantu melatih prosesor dengan memberikan perintah untuk mengidentifikasi label. Anda dapat mencoba sedikit variasi untuk menguji kualitas respons. Misalnya, "total amount", "total invoice amount", atau "total amount of invoice".
Set data sinkron ulang
Sinkronisasi ulang menjaga konsistensi folder Cloud Storage set data Anda dengan indeks metadata internal Document AI. Hal ini berguna jika Anda tidak sengaja mengubah folder Cloud Storage dan ingin menyinkronkan data.
Untuk menyinkronkan ulang:
Di tab Processor Details, di samping baris Storage location, pilih , lalu pilih Re-sync Dataset.
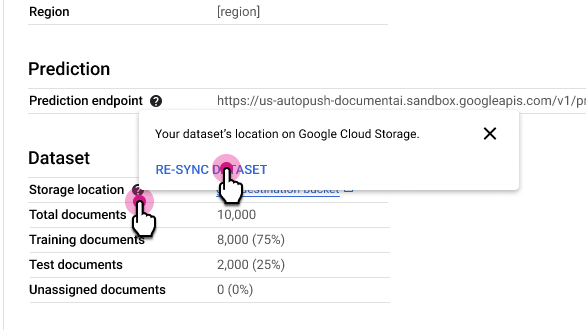
Catatan penggunaan:
- Jika Anda menghapus dokumen dari folder Cloud Storage, sinkronisasi ulang akan menghapusnya dari set data.
- Jika Anda menambahkan dokumen ke folder Cloud Storage, sinkronisasi ulang tidak akan menambahkannya ke set data. Untuk menambahkan dokumen, impor dokumen tersebut.
- Jika Anda mengubah label dokumen di folder Cloud Storage, sinkronkan ulang untuk memperbarui label dokumen di set data.
Memigrasikan set data
Impor dan ekspor memungkinkan Anda memindahkan semua dokumen dalam set data dari satu pemroses ke pemroses lainnya. Hal ini dapat berguna jika Anda memiliki pemroses di region atau Google Cloud project yang berbeda, jika Anda memiliki pemroses yang berbeda untuk penyiapan dan produksi, atau untuk penggunaan offline umum.
Perhatikan bahwa hanya dokumen dan labelnya yang diekspor. Metadata set data, seperti skema prosesor, tugas dokumen (pelatihan/pengujian/tidak ditetapkan), dan status pelabelan dokumen (berlabel, tidak berlabel, berlabel otomatis) tidak diekspor.
Menyalin dan mengimpor set data, lalu melatih prosesor target tidak
persis sama dengan melatih prosesor sumber. Hal ini karena nilai acak digunakan
di awal proses pelatihan. Gunakan panggilan API importProcessorVersion untuk mengimpor dan memigrasikan model yang sama persis antar-project. Ini adalah praktik terbaik untuk migrasi prosesor ke lingkungan yang lebih tinggi (misalnya, pengembangan ke penyiapan ke produksi) jika kebijakan mengizinkan.
Ekspor set data
Untuk mengekspor semua dokumen sebagai file JSON
Document ke folder Cloud Storage,
pilih Ekspor Set Data.
Beberapa hal penting yang perlu diperhatikan:
Selama proses ekspor, tiga subfolder dibuat: Test, Train, dan Unassigned. Dokumen Anda akan ditempatkan ke dalam sub-folder tersebut.
Status pelabelan dokumen tidak diekspor. Jika Anda mengimpor dokumen tersebut nanti, dokumen tersebut tidak akan ditandai sebagai berlabel otomatis.
Jika Cloud Storage Anda berada di project Google Cloud lain, pastikan untuk memberikan akses agar Document AI diizinkan menulis file ke lokasi tersebut. Secara khusus, Anda harus memberikan peran Storage Object Creator kepada agen layanan inti Document AI
service-{project-id}@gcp-sa-prod-dai-core.. Untuk mengetahui informasi selengkapnya, lihat Agen layanan.
Mengimpor set data
Prosedurnya sama dengan Mengimpor dokumen.
Panduan pengguna pelabelan selektif
Pelabelan selektif membantu memberikan rekomendasi dokumen mana yang harus diberi label. Anda dapat membuat set data pelatihan dan pengujian yang beragam untuk melatih model representatif. Setiap kali pelabelan selektif dilakukan, dokumen yang paling beragam (hingga 30) dari set data akan dipilih.
Mendapatkan dokumen yang disarankan
Buat prosesor CDE dan impor dokumen.
- Setidaknya 100 diperlukan untuk pelatihan (25 untuk pengujian).
- Setelah dokumen yang cukup diimpor dan setelah pemberian label selektif, kolom informasi akan muncul.
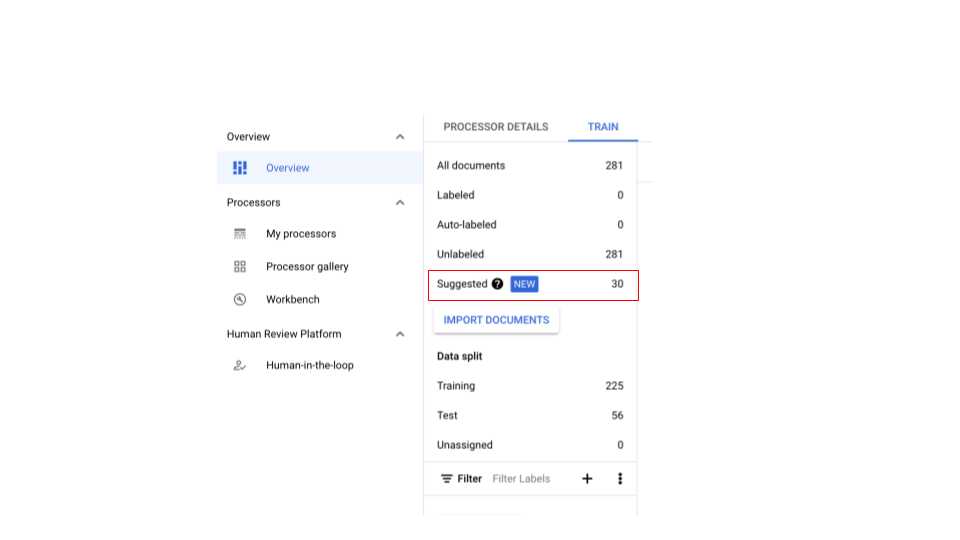
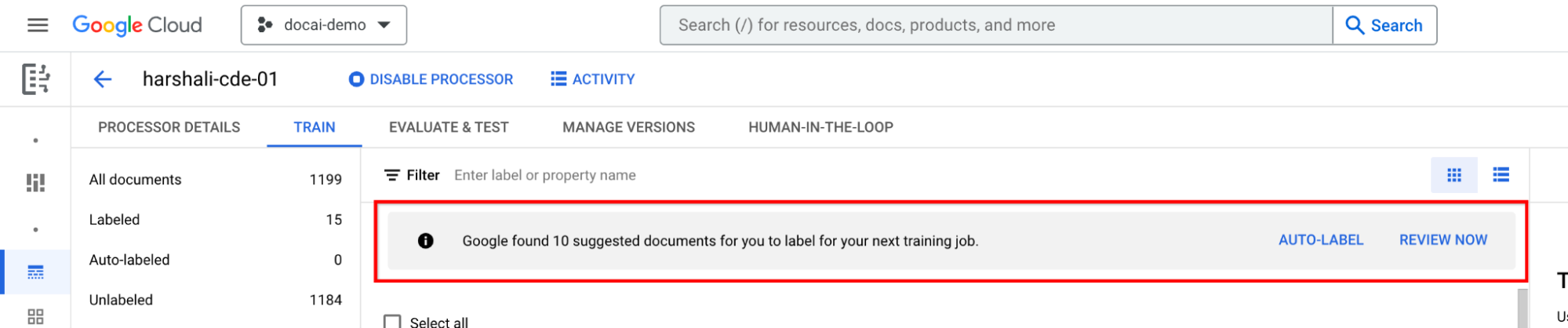
Jika pemroses CDE memiliki nol dokumen yang disarankan, impor lebih banyak dokumen agar memiliki dokumen yang cukup di salah satu bagian untuk pengambilan sampel.
- Tindakan ini akan mengaktifkan dokumen yang disarankan di Kategori yang disarankan. Anda dapat meminta dokumen yang disarankan secara manual.
- Ada filter baru di bagian atas untuk memfilter dokumen yang disarankan.
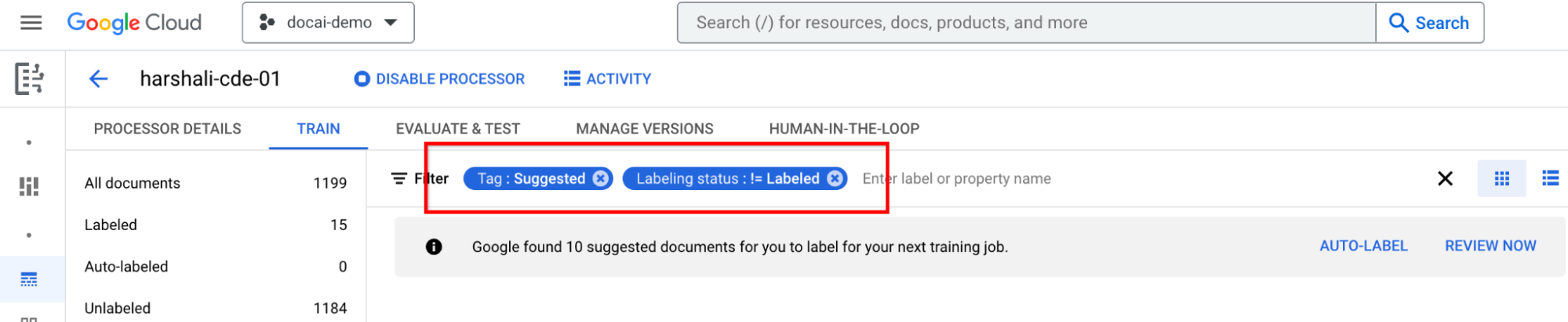
Memberi label pada dokumen yang disarankan
Buka Kategori yang disarankan di panel daftar label sebelah kiri. Mulai beri label pada dokumen ini.
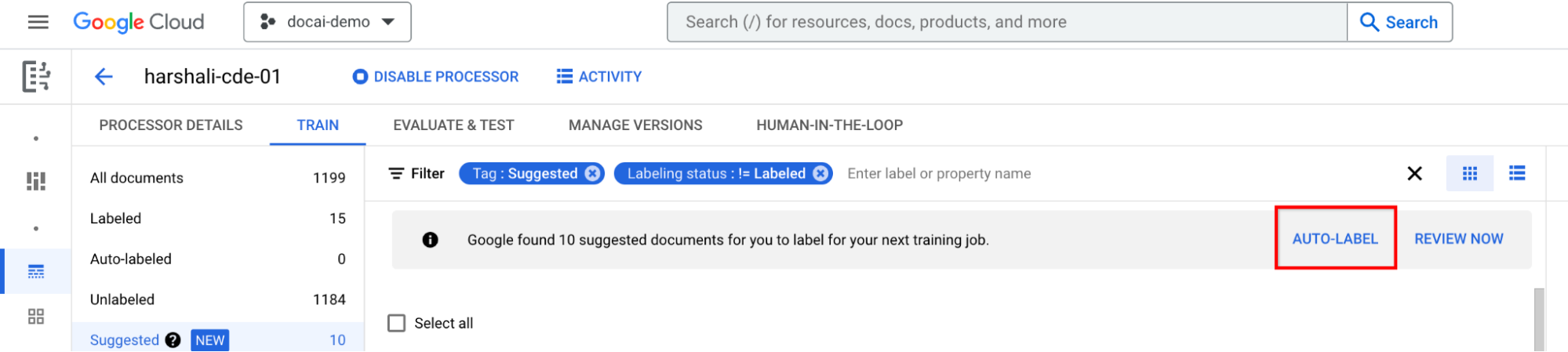
Pilih Label otomatis di panel informasi jika pemroses dilatih. Beri label pada dokumen yang disarankan.
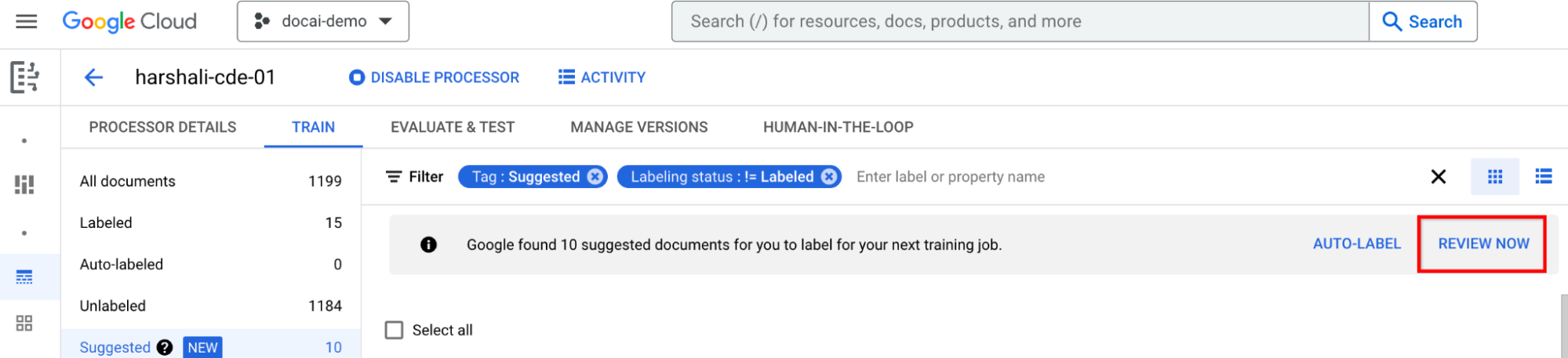
Kemudian, Anda dapat memilih Tinjau sekarang di panel saat Anda menyarankan dokumen di prosesor untuk dibuka. Semua dokumen yang diberi label otomatis harus ditinjau keakuratannya. Mulai meninjau.
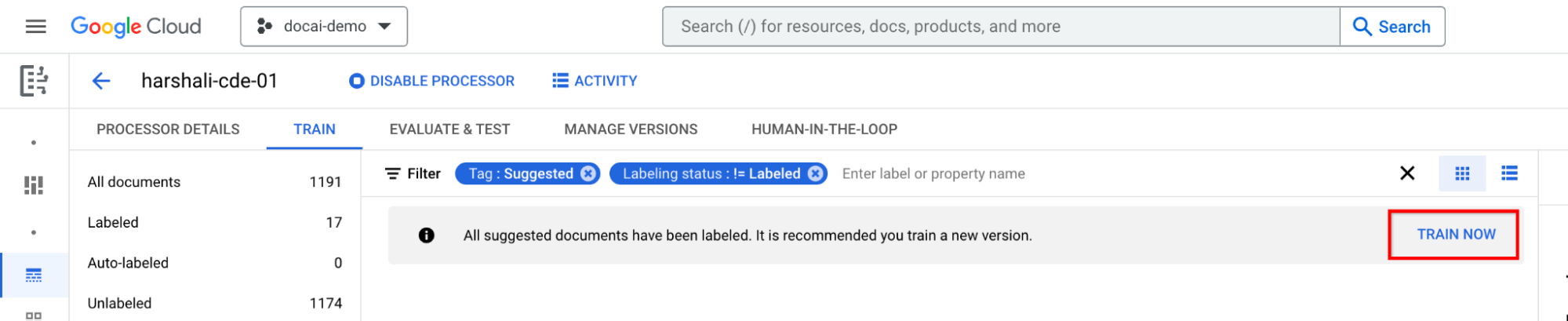
Latih setelah memberi label pada semua dokumen yang disarankan
Buka Latih sekarang di panel informasi. Saat dokumen yang disarankan diberi label, Anda akan melihat kolom informasi berikut yang merekomendasikan pelatihan.
Fitur yang didukung dan batasan
| Fitur | Deskripsi | Didukung |
|---|---|---|
| Dukungan untuk prosesor lama | Mungkin tidak berfungsi dengan baik pada prosesor lama dengan set data yang diimpor sebelumnya |