Mengevaluasi performa
Document AI menghasilkan metrik evaluasi, seperti presisi dan perolehan, untuk membantu Anda menentukan performa prediktif pemroses.
Metrik evaluasi ini dihasilkan dengan membandingkan entitas yang ditampilkan oleh prosesor (prediksi) dengan anotasi dalam dokumen pengujian. Jika pemroses Anda tidak memiliki set pengujian, Anda harus membuat set data dan melabeli dokumen pengujian terlebih dahulu.
Jalankan evaluasi
Evaluasi otomatis dijalankan setiap kali Anda melatih atau melatih ulang versi prosesor.
Anda juga dapat menjalankan evaluasi secara manual. Hal ini diperlukan untuk menghasilkan metrik yang diperbarui setelah Anda mengubah set pengujian, atau jika Anda mengevaluasi versi prosesor terlatih.
UI Web
Di konsol Google Cloud , buka halaman Prosesor, lalu pilih prosesor Anda.
Di tab Evaluate & Test, pilih Version prosesor yang akan dievaluasi, lalu klik Run new evaluation.
Setelah selesai, halaman ini berisi metrik evaluasi untuk semua label dan untuk setiap label individual.
Python
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Python Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Mendapatkan hasil evaluasi
UI Web
Di konsol Google Cloud , buka halaman Prosesor, lalu pilih prosesor Anda.
Di tab Evaluate & Test, pilih Version prosesor untuk melihat evaluasi.
Setelah selesai, halaman ini berisi metrik evaluasi untuk semua label dan untuk setiap label individual.
Python
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Python Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Mencantumkan semua evaluasi untuk versi pemroses
Python
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Python Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Metrik evaluasi untuk semua label
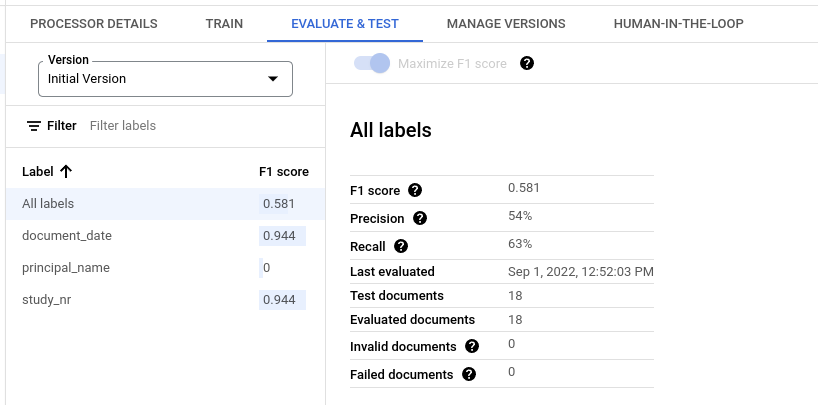
Metrik untuk Semua label dihitung berdasarkan jumlah positif benar, positif palsu, dan negatif palsu dalam set data di semua label, sehingga diberi bobot berdasarkan jumlah kemunculan setiap label dalam set data. Untuk definisi istilah ini, lihat Metrik evaluasi untuk setiap label.
Presisi: proporsi prediksi yang cocok dengan anotasi dalam set pengujian. Didefinisikan sebagai
True Positives / (True Positives + False Positives)Perolehan: proporsi anotasi dalam set pengujian yang diprediksi dengan benar. Didefinisikan sebagai
True Positives / (True Positives + False Negatives)Skor F1: rata-rata harmonis presisi dan perolehan, yang menggabungkan presisi dan perolehan ke dalam satu metrik, sehingga memberikan bobot yang sama untuk keduanya. Didefinisikan sebagai
2 * (Precision * Recall) / (Precision + Recall)
Metrik evaluasi untuk setiap label
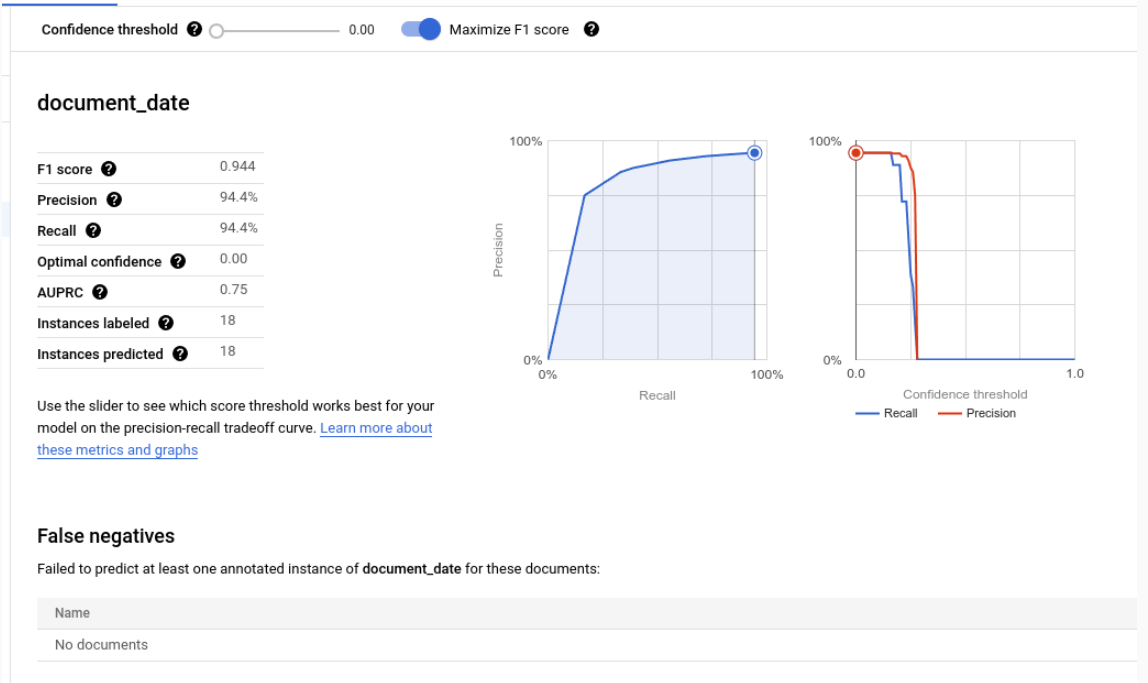
Positif Benar: entitas yang diprediksi dan cocok dengan anotasi dalam dokumen pengujian. Untuk mengetahui informasi selengkapnya, lihat perilaku pencocokan.
Positif Palsu: entity yang diprediksi yang tidak cocok dengan anotasi apa pun dalam dokumen pengujian.
Negatif Palsu: anotasi dalam dokumen pengujian yang tidak cocok dengan entitas yang diprediksi.
- Negatif Palsu (Di Bawah Nilai Minimum): anotasi dalam dokumen pengujian yang akan cocok dengan entitas yang diprediksi, tetapi nilai keyakinan entitas yang diprediksi berada di bawah nilai minimum keyakinan yang ditentukan.
Ambang batas keyakinan
Logika evaluasi mengabaikan prediksi apa pun dengan keyakinan di bawah Nilai Minimum Keyakinan yang ditentukan, meskipun prediksinya benar. Document AI menyediakan daftar Negatif Palsu (Di Bawah Nilai Minimum), yaitu anotasi yang akan memiliki kecocokan jika nilai minimum keyakinan ditetapkan lebih rendah.
Document AI secara otomatis menghitung nilai minimum optimal, yang memaksimalkan skor F1, dan secara default, menetapkan nilai minimum keyakinan ke nilai optimal ini.
Anda bebas memilih sendiri ambang batas keyakinan dengan menggerakkan panel penggeser. Secara umum, nilai minimum keyakinan yang lebih tinggi akan menghasilkan:
- presisi yang lebih tinggi, karena prediksi cenderung lebih akurat.
- recall yang lebih rendah, karena jumlah prediksinya lebih sedikit.
Entitas tabular
Metrik untuk label induk tidak dihitung dengan merata-ratakan metrik turunan secara langsung, tetapi dengan menerapkan nilai minimum keyakinan induk ke semua label turunannya dan menggabungkan hasilnya.
Nilai minimum yang optimal untuk induk adalah nilai nilai minimum keyakinan yang, jika diterapkan ke semua turunan, akan menghasilkan skor F1 maksimum untuk induk.
Perilaku pencocokan
Entitas yang diprediksi cocok dengan anotasi jika:
- jenis entity yang diprediksi
(
entity.type) cocok dengan nama label anotasi - nilai entity yang diprediksi
(
entity.mention_textatauentity.normalized_value.text) cocok dengan nilai teks anotasi, tunduk pada pencocokan tidak pasti jika diaktifkan.
Perhatikan bahwa nilai jenis dan teks adalah semua yang digunakan untuk pencocokan. Informasi lain, seperti anchor teks dan kotak pembatas (kecuali entitas tabel yang dijelaskan di bawah) tidak digunakan.
Label kejadian tunggal vs. multi-kejadian
Label kemunculan tunggal memiliki satu nilai per dokumen (misalnya, ID invoice), meskipun nilai tersebut diberi anotasi beberapa kali dalam dokumen yang sama (misalnya, ID invoice muncul di setiap halaman dokumen yang sama). Meskipun beberapa anotasi memiliki teks yang berbeda, anotasi tersebut dianggap sama. Dengan kata lain, jika entity yang diprediksi cocok dengan anotasi apa pun, entity tersebut dianggap cocok. Anotasi tambahan dianggap sebagai sebutan duplikat dan tidak berkontribusi terhadap jumlah positif benar, positif palsu, atau negatif palsu.
Label multi-kemunculan dapat memiliki beberapa nilai yang berbeda. Dengan demikian, setiap prediksi entity dan anotasi dipertimbangkan dan dicocokkan secara terpisah. Jika dokumen berisi N anotasi untuk label multi-kemunculan, maka dapat ada N kecocokan dengan entitas yang diprediksi. Setiap entity dan anotasi yang diprediksi dihitung secara independen sebagai positif benar, positif palsu, atau negatif palsu.
Pencocokan Fuzzy
Tombol Pencocokan Fuzzy memungkinkan Anda memperketat atau melonggarkan beberapa aturan pencocokan untuk mengurangi atau menambah jumlah kecocokan.
Misalnya, tanpa pencocokan fuzzy, string ABC tidak cocok dengan abc karena
kapitalisasi. Namun, dengan pencocokan fuzzy, keduanya cocok.
Jika pencocokan fuzzy diaktifkan, berikut perubahan aturannya:
Normalisasi spasi kosong: menghapus spasi kosong di awal dan akhir serta memadatkan spasi kosong di tengah yang berurutan (termasuk baris baru) menjadi satu spasi.
Penghapusan tanda baca di awal/akhir: menghapus karakter tanda baca di awal/akhir
!,.:;-"?|berikut.Pencocokan yang tidak peka huruf besar/kecil: mengonversi semua karakter menjadi huruf kecil.
Normalisasi nilai uang: Untuk label dengan jenis data
money, hapus simbol mata uang di awal dan akhir.
Entitas tabular
Entitas dan anotasi induk tidak memiliki nilai teks dan dicocokkan berdasarkan gabungan kotak pembatas turunannya. Jika hanya ada satu induk yang diprediksi dan satu induk yang dianotasi, keduanya akan otomatis dicocokkan, terlepas dari kotak pembatas.
Setelah orang tua dicocokkan, anak mereka dicocokkan seolah-olah mereka adalah entitas non-tabulasi. Jika orang tua tidak dicocokkan, Document AI tidak akan mencoba mencocokkan anak mereka. Artinya, meskipun dengan konten teks yang sama, entity turunan dapat dianggap salah jika entity induknya tidak cocok.
Entitas induk / turunan adalah fitur Pratinjau dan hanya didukung untuk tabel dengan satu lapisan penyusunan.
Mengekspor metrik evaluasi
Di konsol Google Cloud , buka halaman Prosesor, lalu pilih prosesor Anda.
Di tab Evaluate & Test, klik Download Metrics untuk mendownload metrik evaluasi sebagai file JSON.