Benutzerdefinierter Extrahierer mit generativer KI
Mit dem Training und der Extraktion von generativer KI können Sie:
- Mit Zero-Shot- und Few-Shot-Technologie können Sie mit dem Foundation Model ein leistungsstarkes Modell mit wenig bis gar keinen Trainingsdaten erstellen.
- Mit Fine-Tuning können Sie die Genauigkeit weiter steigern, wenn Sie immer mehr Trainingsdaten bereitstellen.
Trainingsmethoden für generative KI
Die von Ihnen gewählte Trainingsmethode hängt von der Anzahl der verfügbaren Dokumente und dem Aufwand ab, den Sie in das Training Ihres Modells investieren können. Es gibt drei Möglichkeiten, ein Modell für generative KI zu trainieren:
| Trainingsmethode | Zero-Shot | Few-Shot | Abstimmung |
|---|---|---|---|
| Genauigkeit | Mittel | Mittel bis hoch | Hoch |
| Aufwand | Niedrig | Niedrig | Mittel |
| Empfohlene Anzahl von Trainingsdokumenten | 0 | 5 bis 10 | 10 bis 50+ |
Benutzerdefinierte Versionen von Extraktormodellen
Die folgenden Modelle sind für benutzerdefinierte Extraktoren verfügbar. Informationen zum Ändern von Modellversionen finden Sie unter Prozessorversionen verwalten.
Die Versionen 1.3, 1.4, 1.5 und 1.5 Pro unterstützen Konfidenzwerte, Version 1.2 jedoch nicht.
| Modellversion | Beschreibung | Stabil | ML-Verarbeitung in den USA/EU | Feinabstimmung in den USA/EU | Releasedatum |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.4-2025-02-05 |
Release-Kandidat, der auf dem Gemini 2.0 Flash-LLM basiert. Unterstützt ein Kontingent von bis zu 120 Seiten pro Minute für Online-Verarbeitungsanfragen. Enthält auch erweiterte OCR-Funktionen wie die Erkennung von Kontrollkästchen. | Ja | Ja | USA, EU (Vorschau) | 5. Februar 2025 |
pretrained-foundation-model-v1.5-2025-05-05 |
Allgemein verfügbares Modell, das auf dem LLM Gemini 2.5 Flash basiert. Unterstützt ein Kontingent von bis zu 120 Seiten pro Minute für Online-Verarbeitungsanfragen. Empfohlen für Nutzer, die neuere Modelle ausprobieren möchten. | Ja | Ja | USA, EU (Vorschau) | 5. Mai 2025 |
pretrained-foundation-model-v1.5-pro-2025-06-20 |
Vorschaumodell, das auf dem Gemini 2.5 Pro-LLM basiert. Unterstützt ein Kontingent von bis zu 30 Seiten pro Minute für Online-Verarbeitungsanfragen. Dieses Modell bietet eine höhere Qualität als Version 1.5 und kann eine höhere Latenz haben. | Nein | Ja | Nein | 20. Juli 2025 |
Informationen zum Ändern der Prozessorversion in Ihrem Projekt finden Sie unter Prozessorversionen verwalten.
Ersteinrichtung
Aktivieren Sie die Abrechnung und die Document AI APIs, falls Sie dies noch nicht getan haben.
Generatives KI-Modell erstellen und bewerten
Erstellen Sie einen Prozessor und definieren Sie die Felder, die Sie extrahieren möchten, gemäß den Best Practices. Das ist wichtig, da es sich auf die Qualität der Extraktion auswirkt.
- Rufen Sie Workbench > Benutzerdefinierter Extraktor > Prozessor erstellen > Namen zuweisen auf.
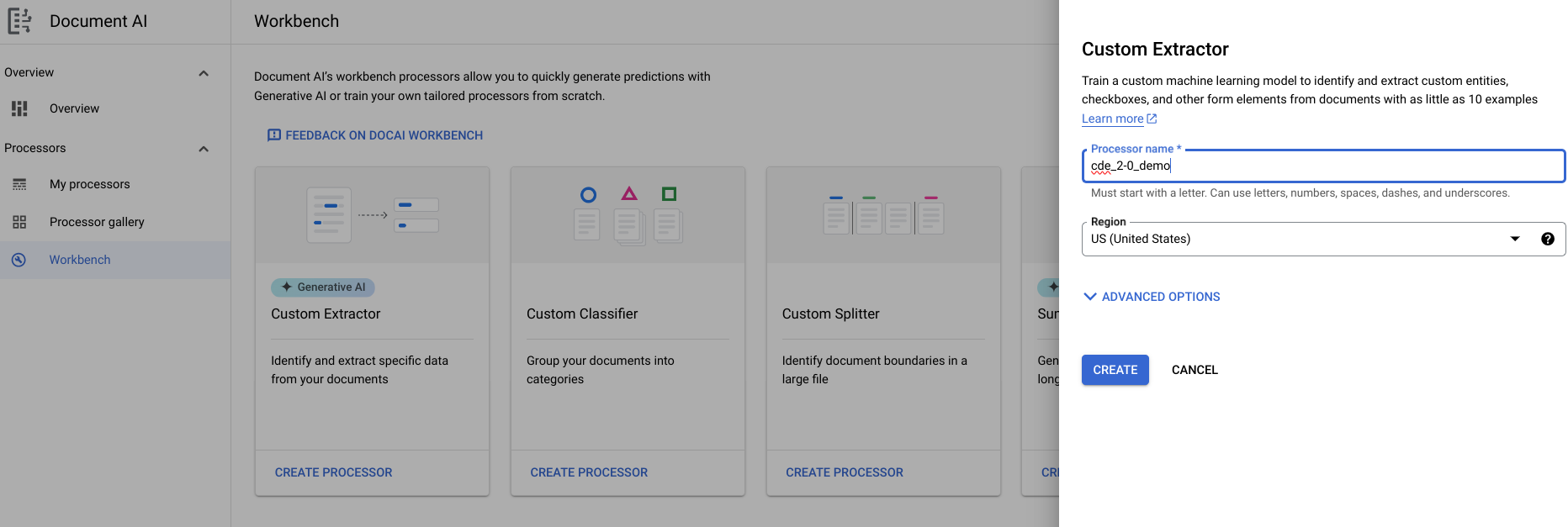
- Klicken Sie auf Jetzt loslegen > Neues Feld erstellen.
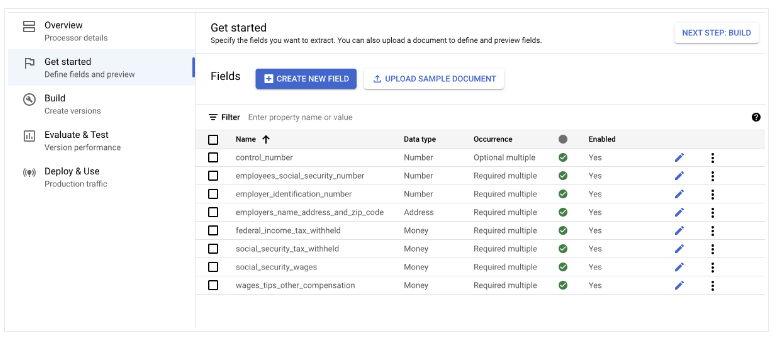
Dokumente importieren
- Importieren Sie Dokumente mit automatischem Labeling und weisen Sie dem Trainings- und Testset Dokumente zu.
- Für Zero-Shot ist nur das Schema erforderlich. Zur Bewertung der Genauigkeit des Modells ist nur ein Test-Set erforderlich.
- Für Few-Shot-Lernen empfehlen wir fünf Trainingsdokumente.
- Die Anzahl der benötigten Testdokumente hängt vom Anwendungsfall ab. Im Allgemeinen gilt: Je mehr Testdokumente, desto besser.
- Bestätigen oder bearbeiten Sie die Labels im Dokument.
Modell trainieren:
- Wählen Sie Build und dann Neue Version erstellen aus.
- Geben Sie einen Namen ein und wählen Sie Erstellen aus.
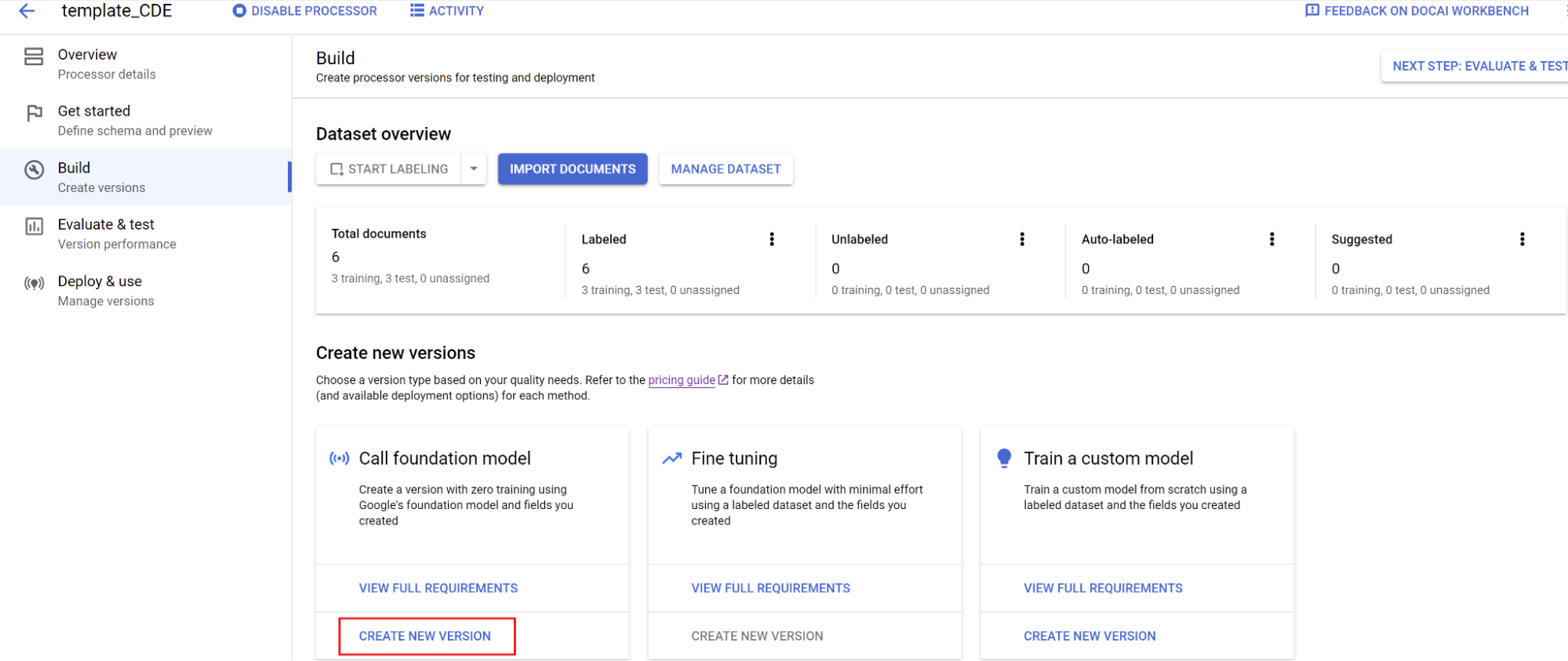
Bewertung:
- Rufen Sie Bewerten und testen auf, wählen Sie die gerade trainierte Version aus und klicken Sie dann auf Vollständige Bewertung ansehen.
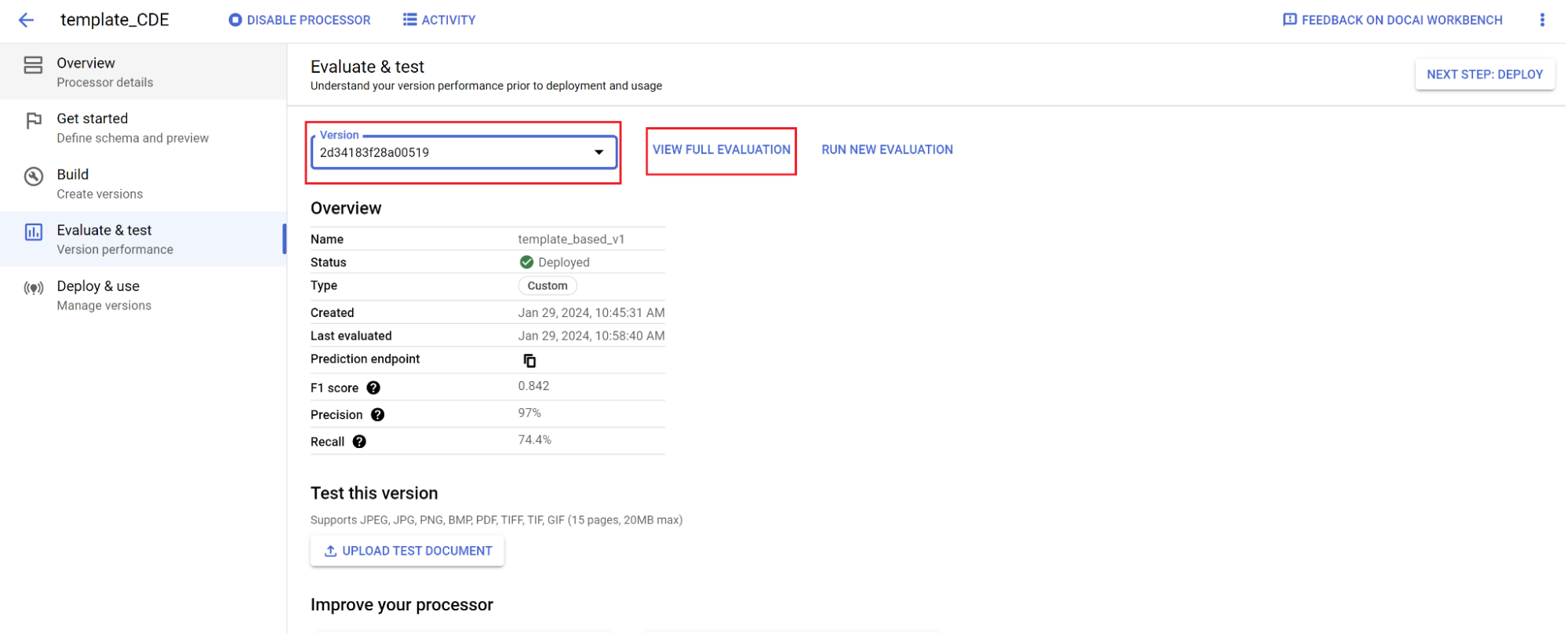
- Sie sehen jetzt Messwerte wie F1-Wert, Genauigkeit und Trefferquote für das gesamte Dokument und jedes Feld.
- Entscheiden Sie, ob die Leistung Ihren Produktionszielen entspricht. Wenn nicht, sollten Sie die Trainings- und Testsets neu bewerten.
Neue Version als Standard festlegen:
- Rufen Sie Versionen verwalten auf.
- Wählen Sie die Option aus, um sie zu maximieren, und wählen Sie dann Als Standard festlegen aus.
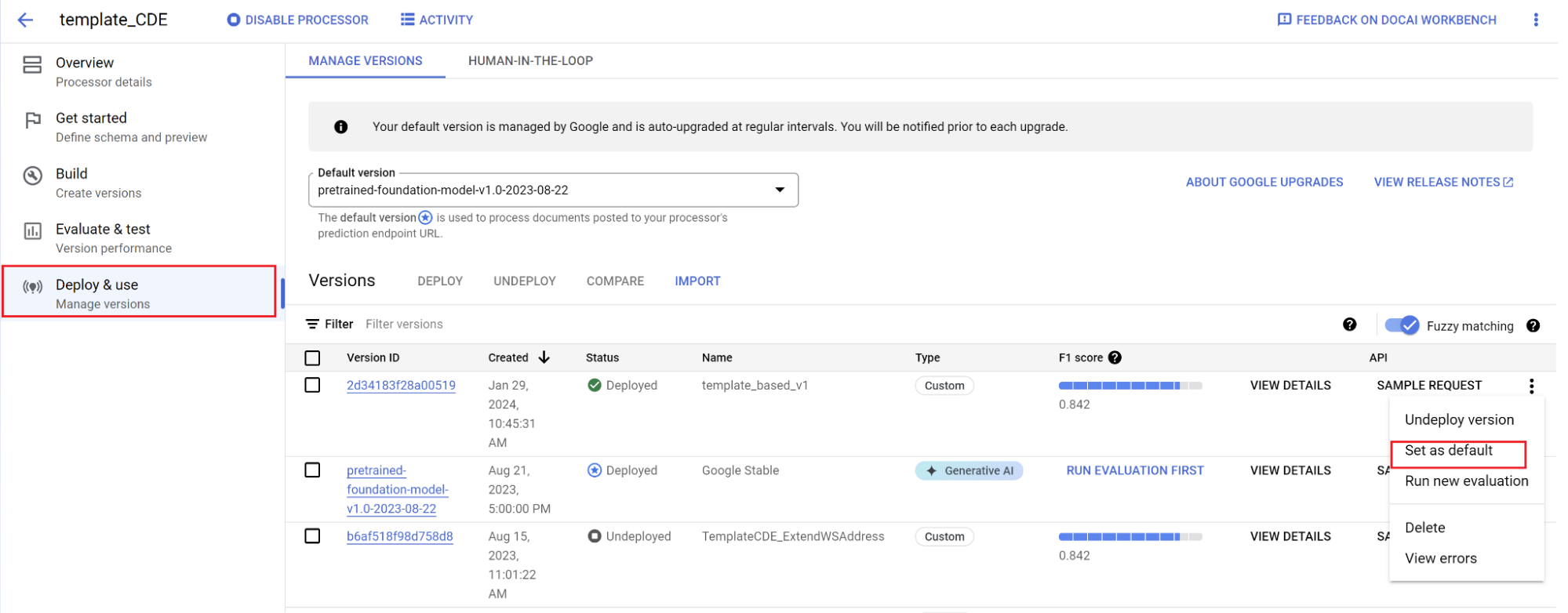
Ihr Modell wurde bereitgestellt. Dokumente, die an diesen Prozessor gesendet werden, verwenden Ihre benutzerdefinierte Version. Sie können die Leistung des Modells bewerten, um festzustellen, ob es weiter trainiert werden muss.
Bewertungsreferenz
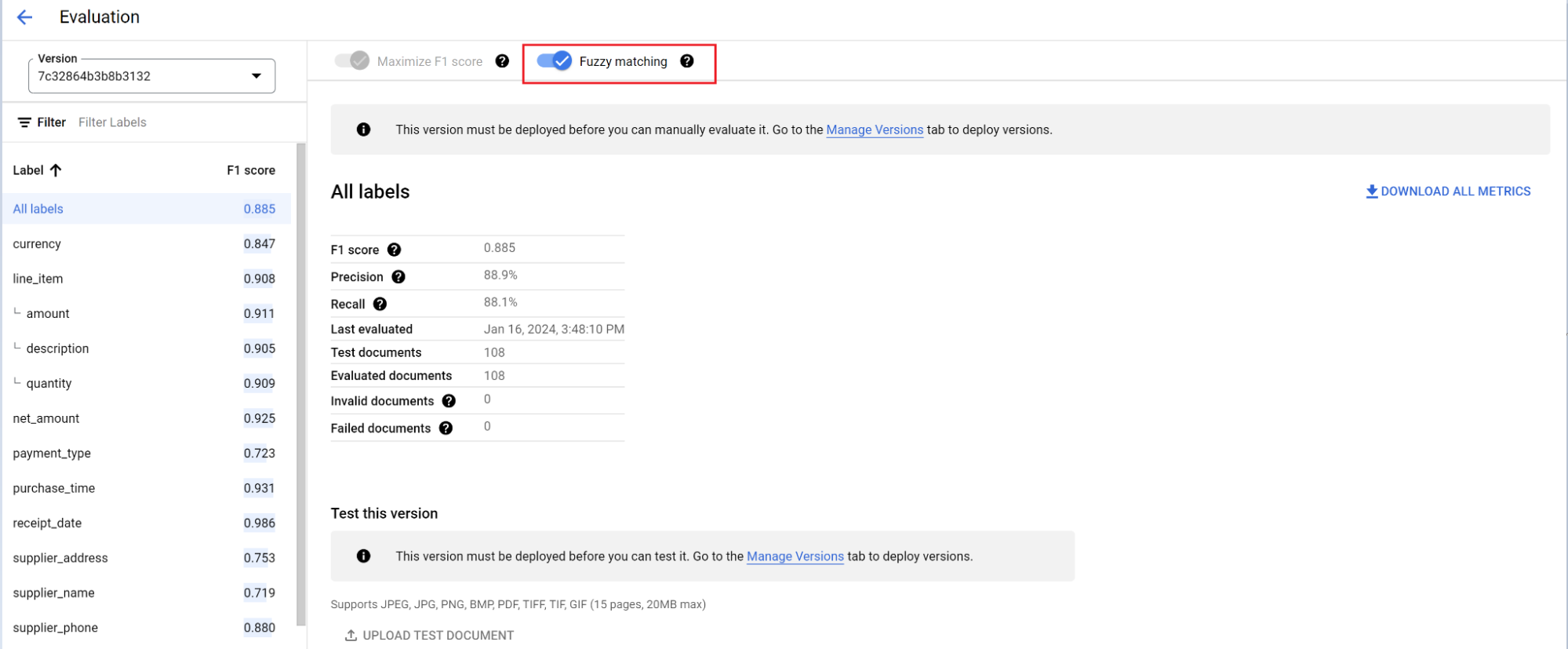
Die Auswertungs-Engine kann sowohl genaue als auch unscharfe Übereinstimmungen erkennen. Bei einer genauen Übereinstimmung muss der extrahierte Wert genau mit der Ground Truth übereinstimmen. Andernfalls wird er als Fehler gezählt.
Extraktionen mit unscharfem Abgleich, die geringfügige Unterschiede wie unterschiedliche Groß- und Kleinschreibung aufwiesen, werden weiterhin als Übereinstimmung gezählt. Dies kann auf dem Bildschirm Bewertung geändert werden.
Abstimmung
Beim Fine-Tuning verwenden Sie Hunderte oder Tausende von Dokumenten für das Training.
Erstellen Sie einen Prozessor und definieren Sie die Felder, die Sie extrahieren möchten. Beachten Sie dabei die Best Practices, da diese sich auf die Qualität der Extraktion auswirken.
Importieren Sie Dokumente mit automatischem Labeling und weisen Sie Dokumente dem Trainings- und Testset zu.
Bestätigen oder bearbeiten Sie die Labels im Dokument.
Modell trainieren
- Wählen Sie den Tab Build (Erstellen) und dann im Feld Fine-tuning (Feinabstimmung) die Option Create New Version (Neue Version erstellen) aus.

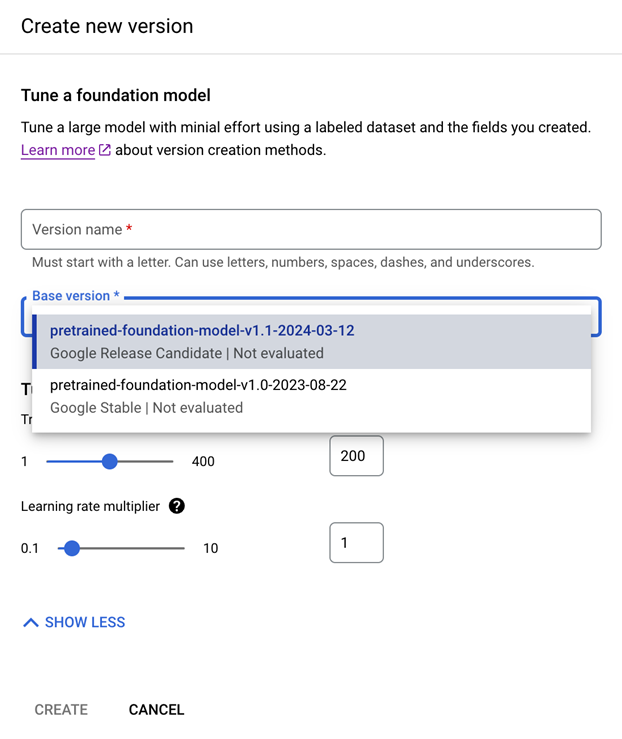
Testen Sie die Standardtrainingsparameter oder die bereitgestellten Werte. Wenn die Ergebnisse nicht zufriedenstellend sind, können Sie mit diesen erweiterten Optionen experimentieren:
Trainingsschritte (zwischen 100 und 400): Steuert, wie oft die Gewichte während des Tunings für einen Batch von Daten optimiert werden.
- Ein zu niedriger Wert deutet auf das Risiko hin, dass das Training vor der Konvergenz endet (Underfitting).
- Wenn der Wert zu hoch ist, wird das Modell während des Trainings möglicherweise mehrmals mit demselben Datenbatch trainiert, was zu einer Überanpassung führen kann.
- Weniger Schritte führen zu einer kürzeren Trainingszeit. Höhere Werte können bei Dokumenten mit geringer Vorlagenvariation hilfreich sein, niedrigere Werte bei Dokumenten mit mehr Variation.
Multiplikator für die Lernrate (zwischen 0,1 und 10): Steuert, wie schnell die Modellparameter anhand der Trainingsdaten optimiert werden. Sie entspricht in etwa der Größe jedes Trainingsschritts.
- Niedrige Raten bedeuten kleine Änderungen der Modellgewichte bei jedem Trainingsschritt. Wenn der Wert zu niedrig ist, konvergiert das Modell möglicherweise nicht zu einer stabilen Lösung.
- Hohe Raten deuten auf große Änderungen hin. Wenn sie zu hoch sind, kann das Modell die optimale Lösung überschreiten und stattdessen zu einer suboptimalen Lösung konvergieren.
- Die Trainingszeit wird durch die Wahl der Lernrate nicht beeinflusst.
Geben Sie einen Namen ein, wählen Sie die erforderliche Basisprozessorversion aus und klicken Sie auf Erstellen.
Bewertung: Klicken Sie auf Bewerten und testen, wählen Sie die gerade trainierte Version aus und klicken Sie auf Vollständige Bewertung ansehen.
- Sie sehen jetzt Messwerte wie F1-Wert, Genauigkeit und Trefferquote für das gesamte Dokument und jedes Feld.
- Entscheiden Sie, ob die Leistung Ihren Produktionszielen entspricht. Wenn nicht, sind möglicherweise weitere Trainingsdokumente erforderlich.
So legen Sie eine neue Version als Standard fest:
- Rufen Sie Versionen verwalten auf.
- Wählen Sie die Option aus, um sie zu maximieren, und wählen Sie Als Standard festlegen aus.
Ihr Modell wird jetzt bereitgestellt und für Dokumente, die an diesen Prozessor gesendet werden, wird jetzt Ihre benutzerdefinierte Version verwendet. Sie möchten die Leistung des Modells bewerten, um zu prüfen, ob es weiter trainiert werden muss.
Automatisches Labeling mit dem Foundation Model
Mit dem Basismodell lassen sich Felder für eine Vielzahl von Dokumenttypen präzise extrahieren. Sie können jedoch auch zusätzliche Trainingsdaten bereitstellen, um die Genauigkeit des Modells für bestimmte Dokumentstrukturen zu verbessern.
Document AI verwendet die von Ihnen definierten Labelnamen und vorherige Annotationen, um Dokumenten in großem Umfang mithilfe der automatischen Labels schneller und einfacher Labels hinzuzufügen.
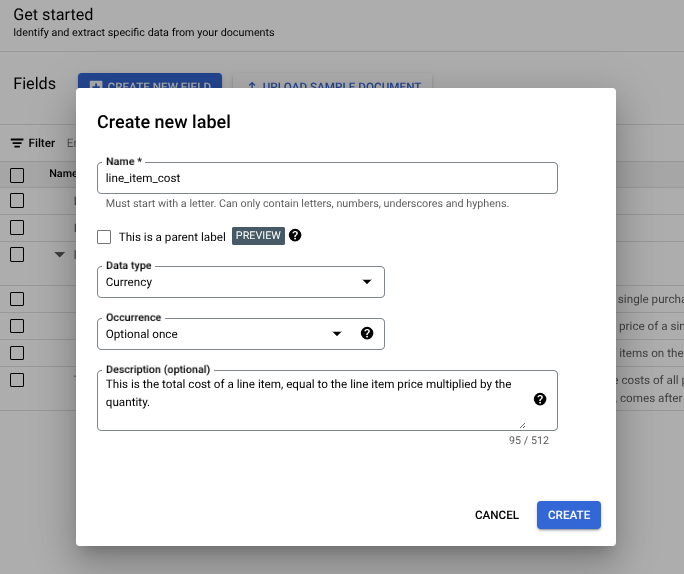
- Nachdem Sie einen benutzerdefinierten Prozessor erstellt haben, rufen Sie den Tab Erste Schritte auf.
- Wählen Sie Neues Feld erstellen aus.
Geben Sie dem Label einen aussagekräftigen, eindeutigen Namen. Dadurch werden die Genauigkeit und Leistung des Foundation Models verbessert.
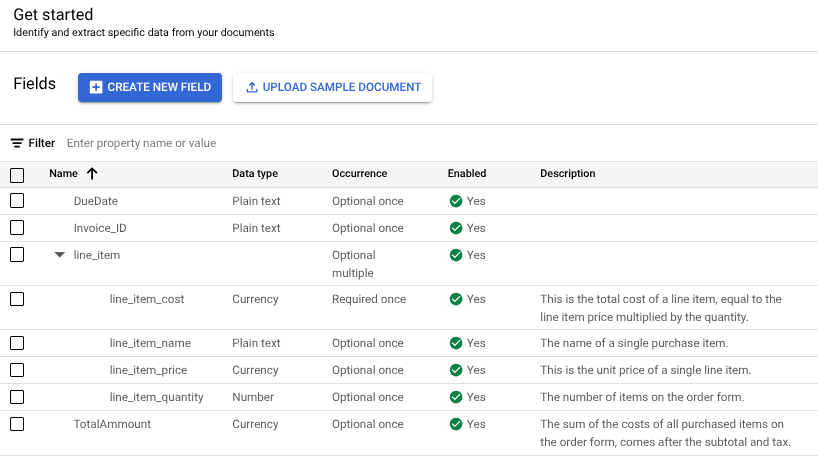
Um die Genauigkeit und Leistung der Extraktion zu verbessern, fügen Sie eine Beschreibung für die Arten von Entitäten hinzu, die er erfassen soll, z. B. zusätzlichen Kontext, Statistiken und Vorwissen für jede Entität.
Rufen Sie den Tab Erstellen auf und wählen Sie Dokumente importieren aus.
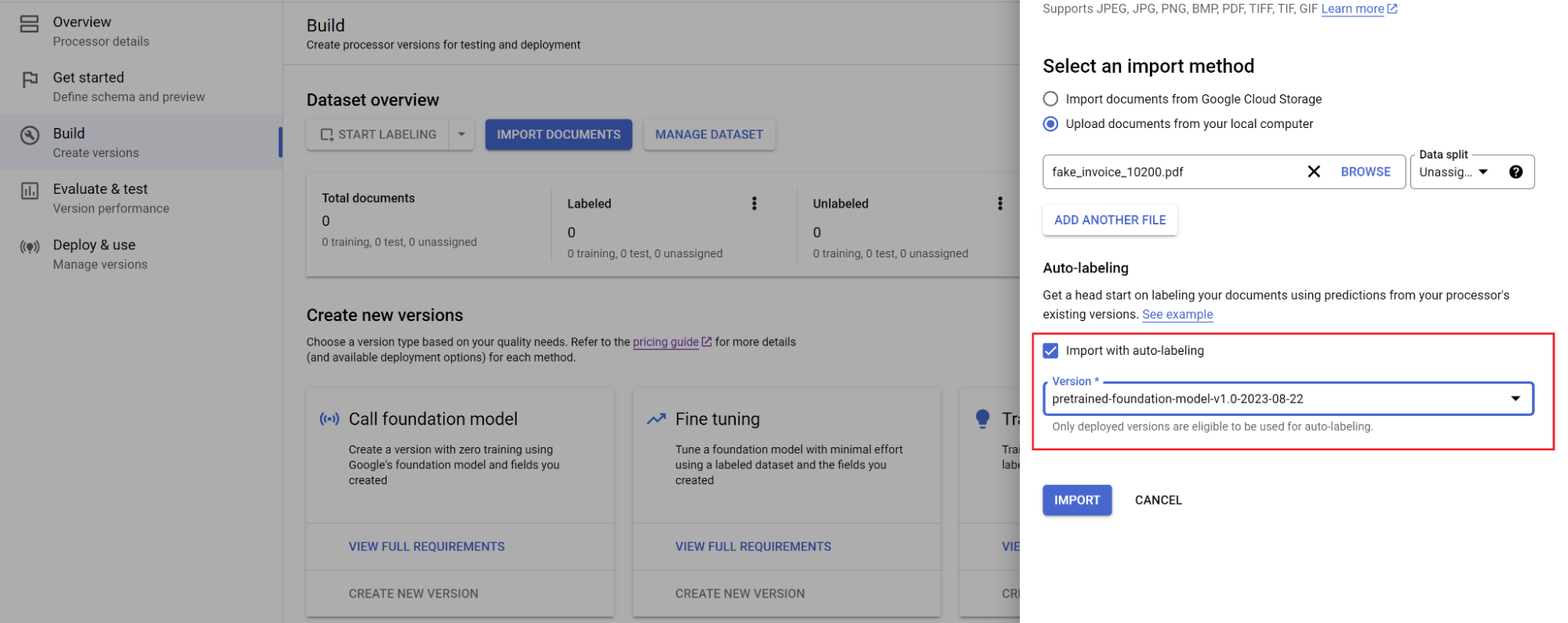
Wählen Sie den Pfad der Dokumente und das Set aus, in das die Dokumente importiert werden sollen. Aktivieren Sie die Option für das automatische Labeling und wählen Sie das Basismodell aus.
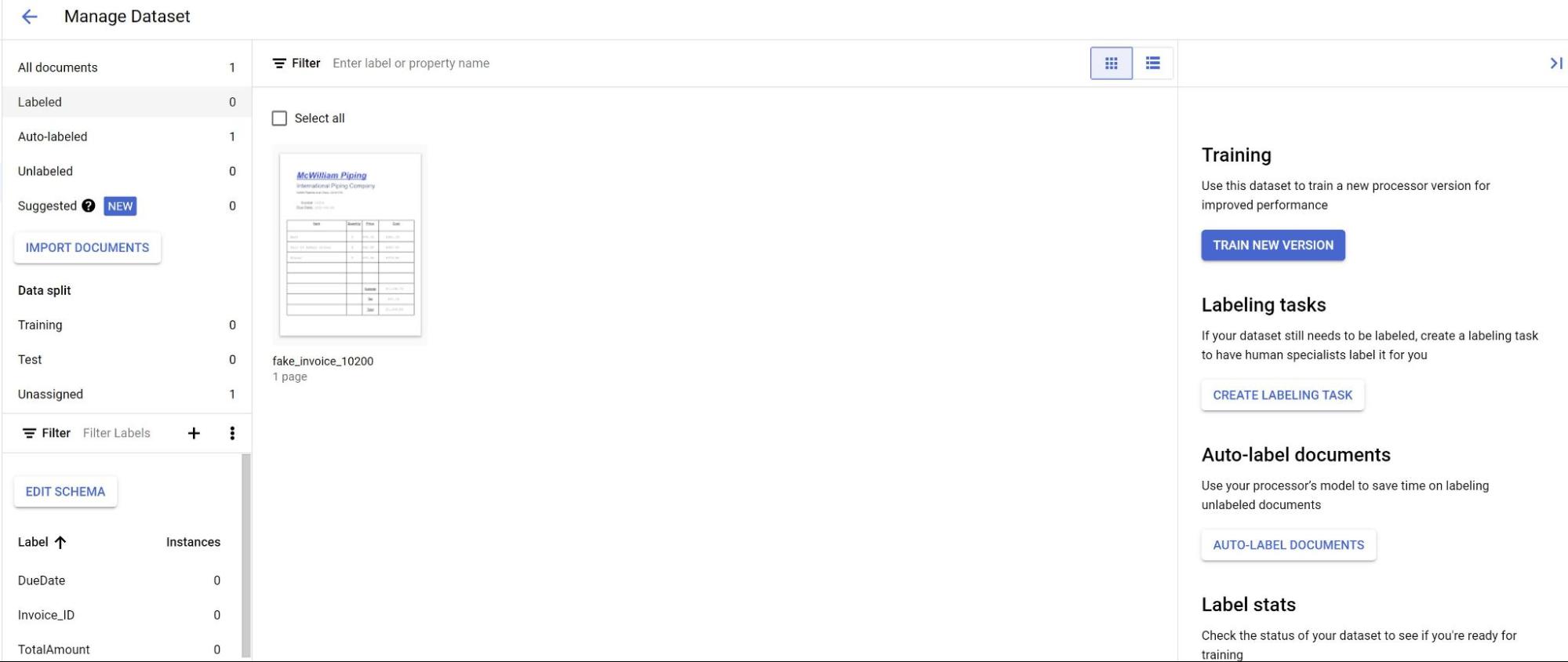
Wählen Sie auf dem Tab Erstellen die Option Dataset verwalten aus.
Wenn Sie Ihre importierten Dokumente sehen, wählen Sie eines davon aus.
Die Vorhersagen des Modells werden jetzt lila hervorgehoben.
- Prüfen Sie jedes vom Modell vorhergesagte Label und bestätigen Sie, dass es korrekt ist.
Fügen Sie auch fehlende Felder hinzu.
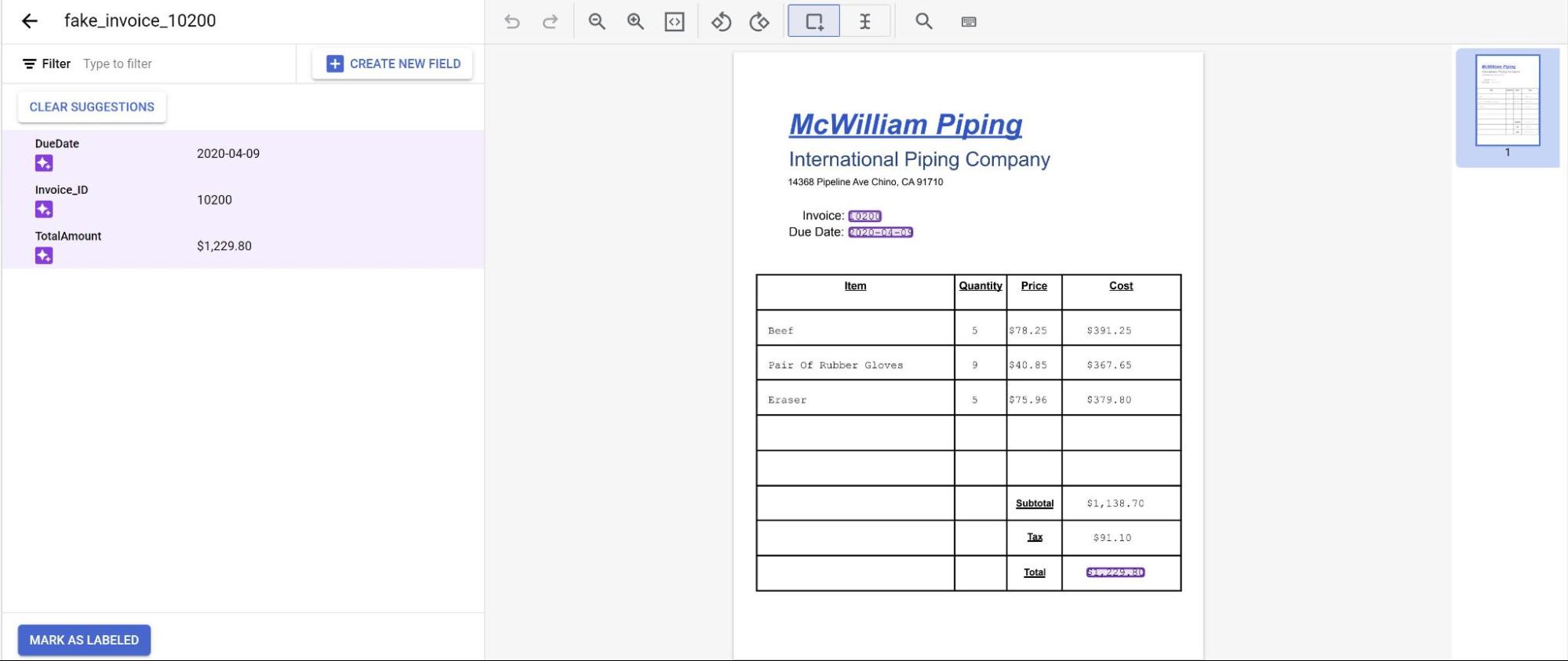
Wenn das Dokument überprüft wurde, wählen Sie Als „Mit Label versehen“ markieren aus. Das Dokument kann jetzt vom Modell verwendet werden.
Achten Sie darauf, dass sich das Dokument entweder im Test- oder im Trainingsset befindet.
Verschachtelung auf drei Ebenen
Der benutzerdefinierte Extrahierer bietet jetzt drei Verschachtelungsebenen. Diese Funktion ermöglicht eine bessere Extraktion für komplexe Tabellen.
Mit den folgenden API-Aufrufen können Sie den Modelltyp ermitteln:
Die Antwort ist ein ProcessorVersion-Objekt, das das Feld modelType in der v1beta3-Vorabversion enthält.
Vorgehensweise und Beispiel
Wir verwenden dieses Beispiel:
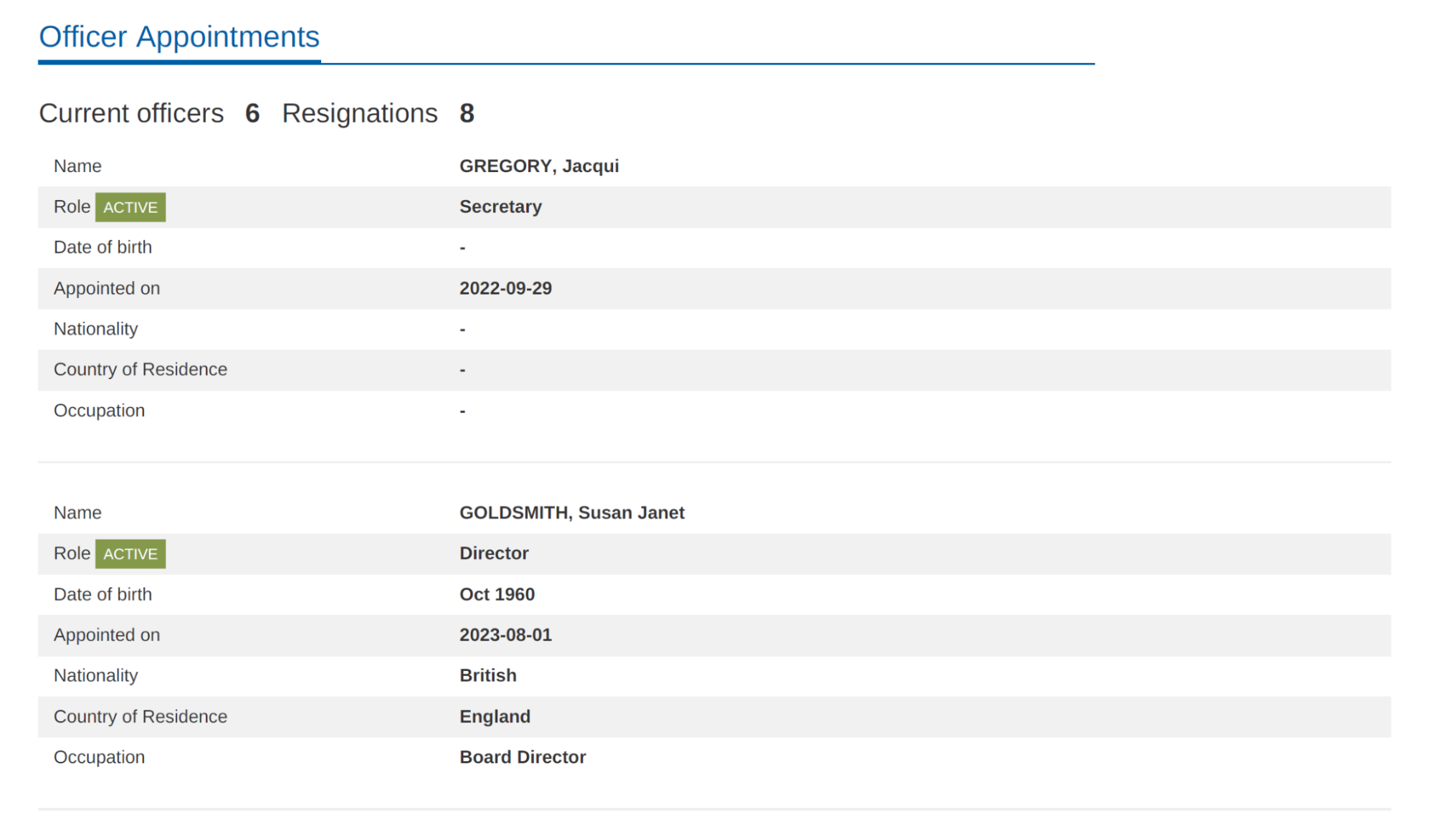
Wählen Sie Jetzt starten aus und erstellen Sie dann ein Feld:
- Erstellen Sie die oberste Ebene.
- In diesem Beispiel wird
officer_appointmentsverwendet. - Wählen Sie Dies ist ein übergeordnetes Label aus.
- Wählen Sie Vorkommen aus:
Optional multiple.
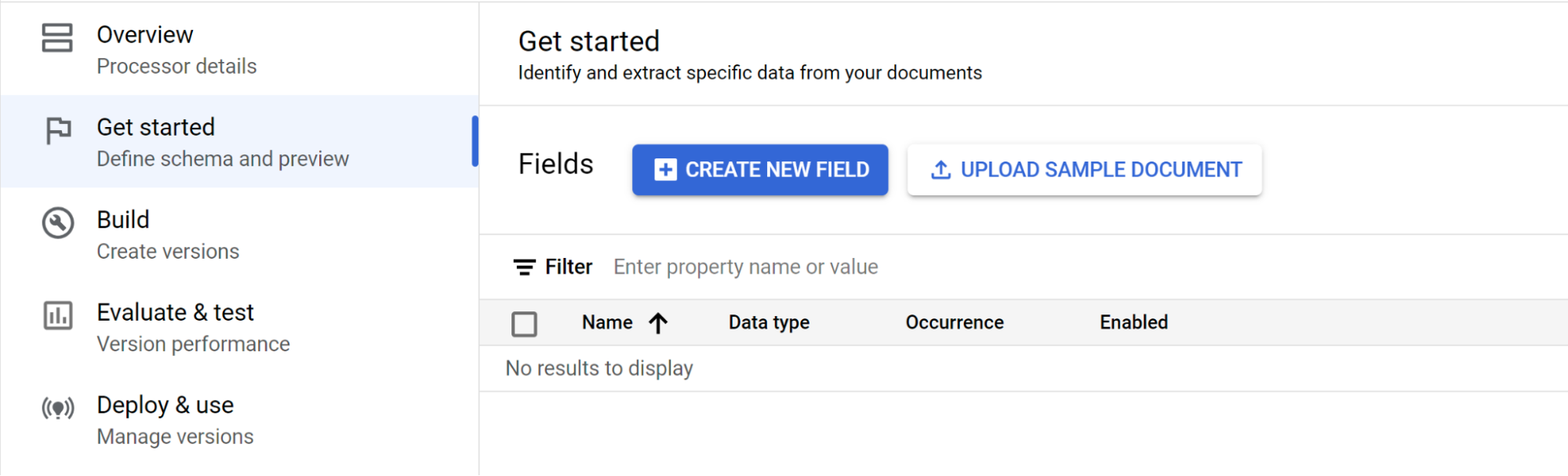
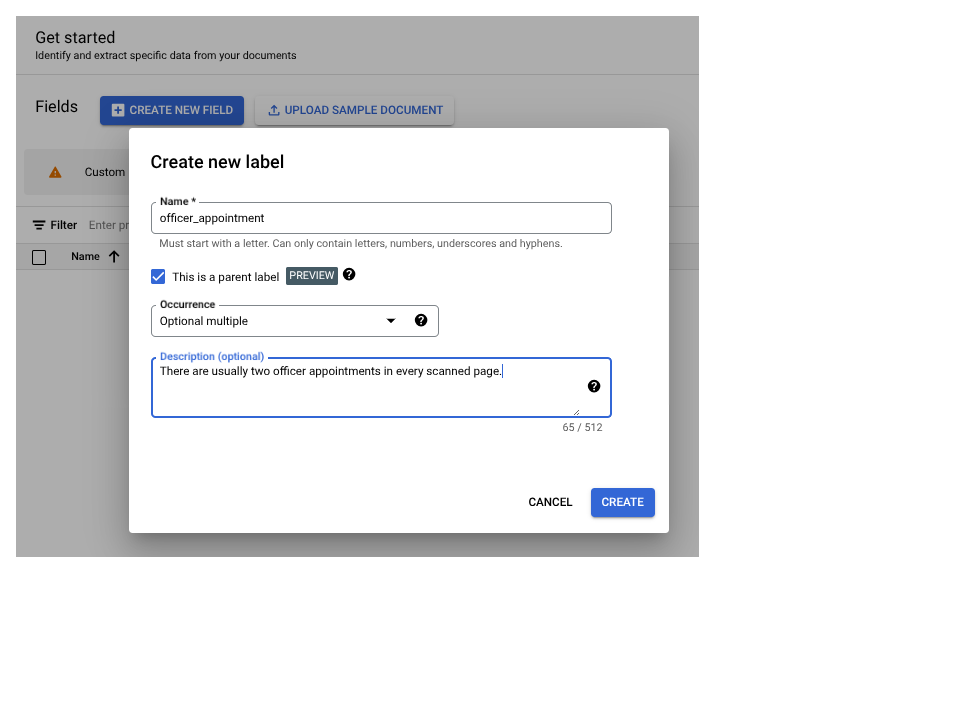
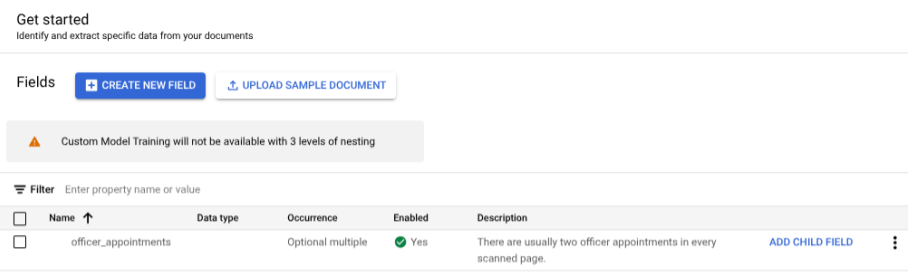
Wählen Sie Untergeordnetes Feld hinzufügen aus. Das Label der zweiten Ebene kann jetzt erstellt werden:
- Erstellen Sie für dieses Label auf Ebene
officer. - Wählen Sie Dies ist ein übergeordnetes Label aus.
- Wählen Sie Vorkommen aus:
Optional multiple.

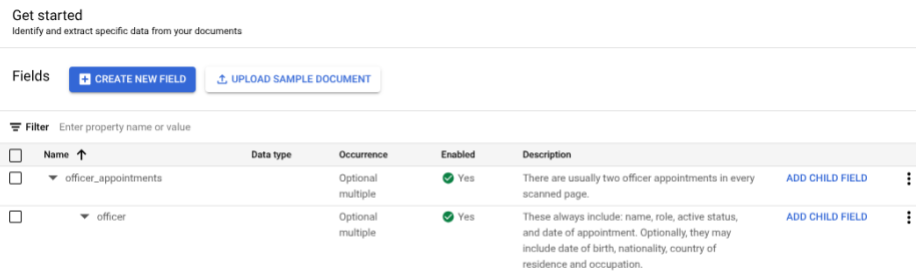
- Erstellen Sie für dieses Label auf Ebene
Wählen Sie auf der zweiten Ebene
officerdie Option Untergeordnetes Feld hinzufügen aus. Erstellen Sie untergeordnete Labels für die dritte Verschachtelungsebene.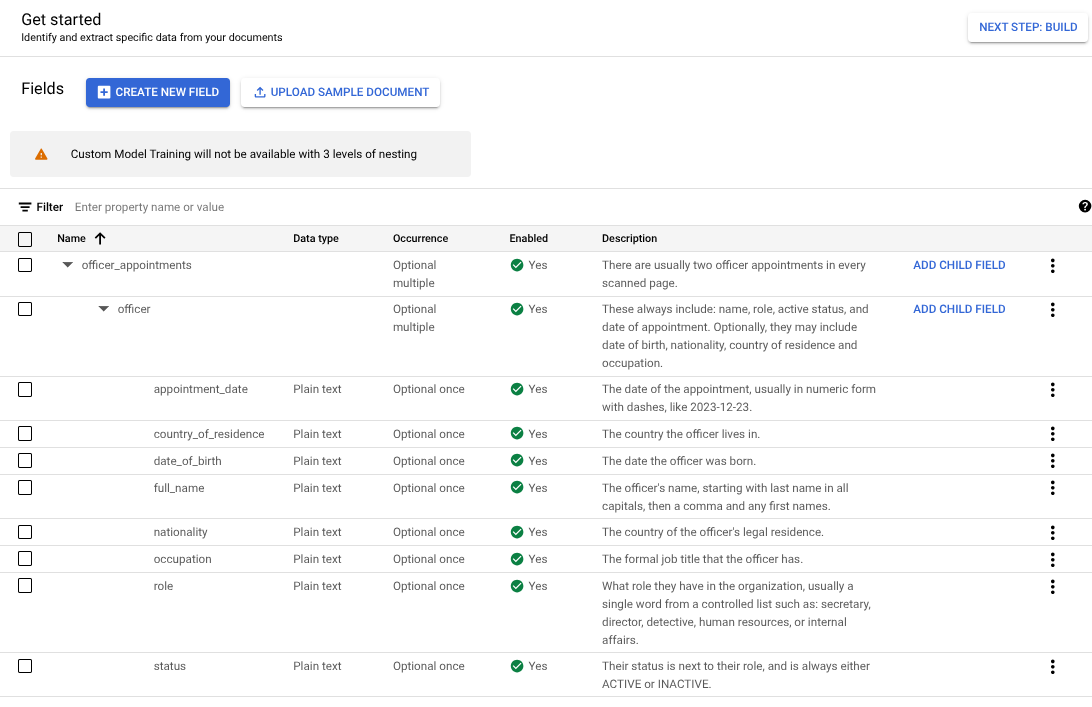
Wenn Ihr Schema festgelegt ist, können Sie mit der automatischen Labelerstellung Vorhersagen aus Dokumenten mit drei Verschachtelungsebenen abrufen.
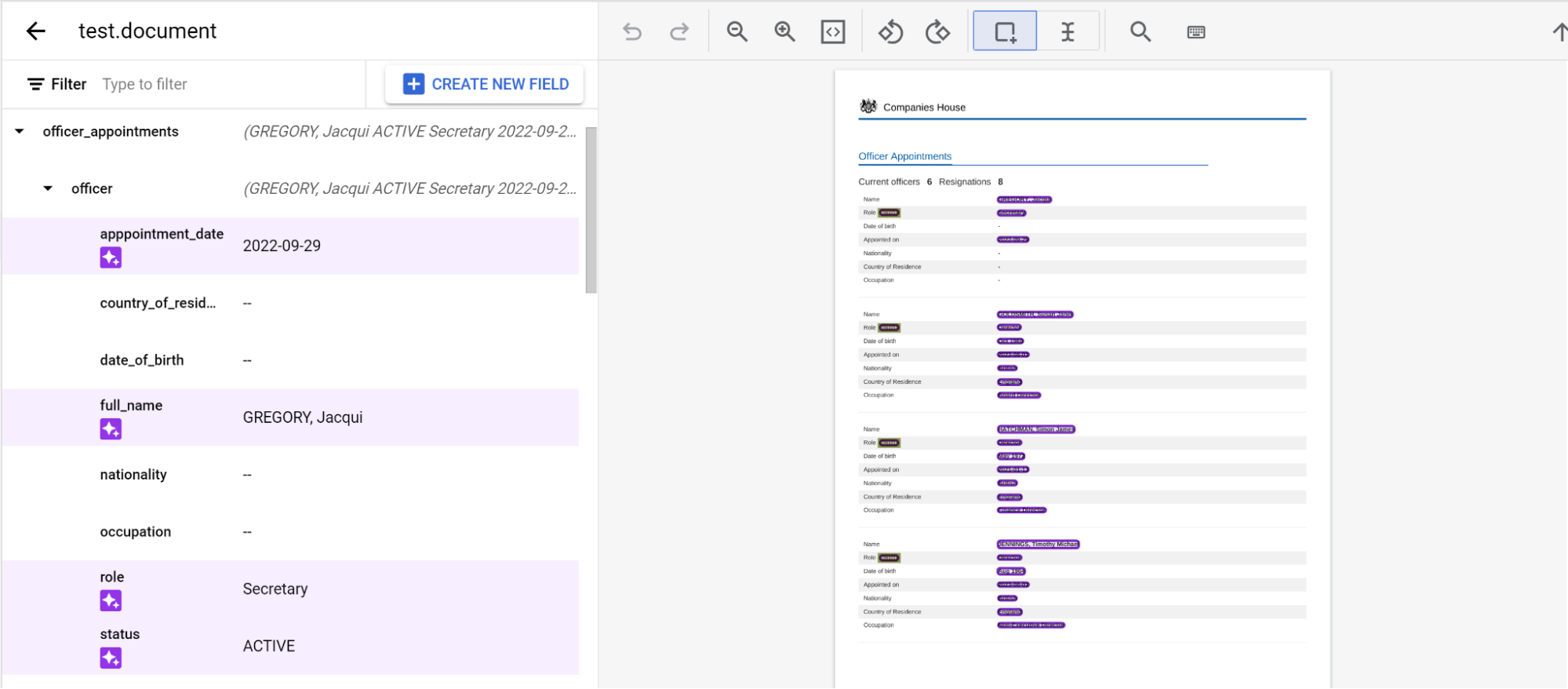
Seitenübergreifende verschachtelte Entitäten mit Labels versehen
Der pretrained-foundation-model-v1.5-2025-05-05-Prozessor unterstützt die Verschachtelung auf drei Ebenen auf Seiten.
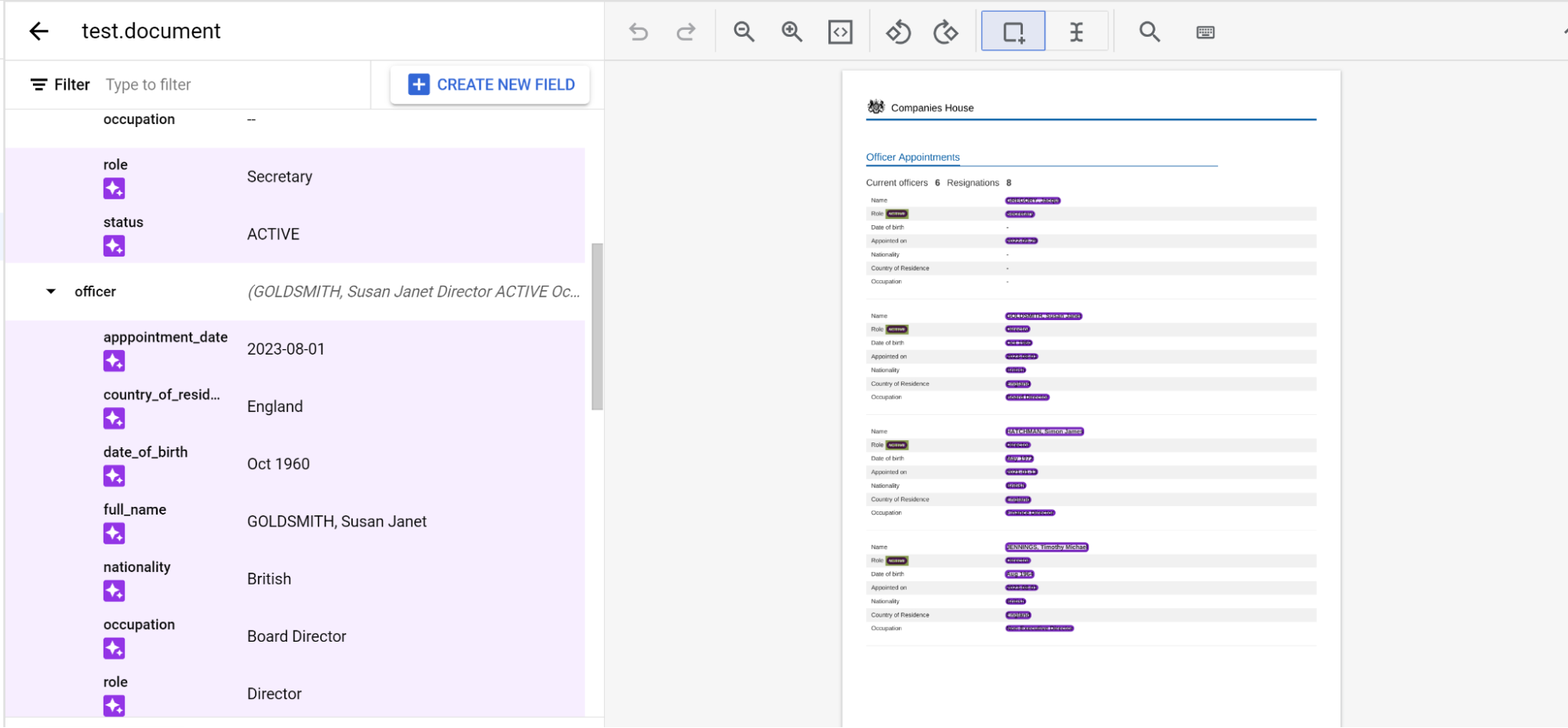
Kennzeichnen Sie eine Entität wie gewohnt auf einer Seite. Hinweis: Die gekennzeichnete Entität ist nur auf der Seite sichtbar, auf der sie gekennzeichnet wurde. Die Navigationsleiste ändert sich von Seite zu Seite. Wenn Sie die übergeordnete Entität anpinnen, bleibt diese Navigationsleiste erhalten.

Pinnen Sie die übergeordnete Einheit mit den untergeordneten Einheiten, die Sie seitenübergreifend kennzeichnen möchten.

Rufen Sie die Seite mit dem untergeordneten Element oder den untergeordneten Elementen auf, die Sie mit einem Label versehen möchten.

Dataset-Konfiguration
Zum Trainieren, Aktualisieren oder Bewerten einer Prozessorversion ist ein Dokument-Dataset erforderlich. Document AI-Prozessoren lernen aus Beispielen, genau wie Menschen. Das Dataset trägt zur Stabilität des Prozessors in Bezug auf die Leistung bei.Trainings-Dataset
Um das Modell und seine Genauigkeit zu verbessern, trainieren Sie ein Dataset mit Ihren Dokumenten. Das Modell besteht aus Dokumenten mit Ground Truth.- Für das Fine-Tuning benötigen Sie mindestens ein Dokument, um ein neues Modell mit Version für
pretrained-foundation-model-v1.2-2024-05-10undpretrained-foundation-model-v1.3-2024-08-31zu trainieren. - Für Few-Shot-Prompts werden fünf Dokumente empfohlen.
- Für Zero-Shot ist nur ein Schema erforderlich.
Test-Dataset
Das Test-Dataset wird vom Modell verwendet, um einen F1-Wert (Genauigkeit) zu generieren. Es besteht aus Dokumenten mit Ground Truth. Um zu sehen, wie oft das Modell richtig liegt, wird der Ground Truth verwendet, um die Vorhersagen des Modells (extrahierte Felder aus dem Modell) mit den richtigen Antworten zu vergleichen. Das Test-Dataset sollte mindestens ein Dokument fürpretrained-foundation-model-v1.2-2024-05-10 und pretrained-foundation-model-v1.3-2024-08-31 enthalten.
Benutzerdefinierter Extrahierer mit Attributbeschreibungen
Mit Property-Beschreibungen können Sie ein Modell trainieren, indem Sie beschreiben, wie die Felder mit Labels aussehen. Sie können für jede Einheit zusätzlichen Kontext und Statistiken angeben. So kann das Modell trainieren, indem es Felder abgleicht, die der von Ihnen angegebenen Beschreibung entsprechen, und die Genauigkeit der Extraktion verbessern. Eigenschaftsbeschreibungen können sowohl für übergeordnete als auch für untergeordnete Einheiten angegeben werden.
Gute Beispiele für Property-Beschreibungen sind Standortinformationen und Textmuster der Property-Werte, die helfen, potenzielle Verwechslungsquellen im Dokument zu beseitigen. Klare und präzise Attributbeschreibungen geben dem Modell Regeln vor, die zuverlässigere und konsistentere Extraktionen ermöglichen, unabhängig von der spezifischen Dokumentstruktur oder den Inhaltsabweichungen.
Dokumentschema für einen Prozessor aktualisieren
Informationen zum Festlegen der Property-Beschreibungen finden Sie unter Dokumentschema aktualisieren.
Verarbeitungsanfrage mit Property-Beschreibungen senden
Wenn im Dokumentschema bereits Beschreibungen festgelegt sind, können Sie eine Verarbeitungsanfrage mit der Anleitung unter Verarbeitungsanfrage senden senden.
Prozessor mit Property-Beschreibungen optimieren
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- LOCATION: Der Standort Ihres Prozessors, z. B.
us– USAeu– Europäische Union
- PROJECT_ID: Ihre Google Cloud -Projekt-ID
- PROCESSOR_ID: Die ID Ihres benutzerdefinierten Prozessors.
- DISPLAY_NAME: Anzeigename für den Prozessor.
- PRETRAINED_PROCESSOR_VERSION: die Kennung der Prozessorversion. Weitere Informationen finden Sie unter Prozessorversion auswählen. Beispiel:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- TRAIN_STEPS: Trainingsschritte für die Feinabstimmung des Modells.
- LEARN_RATE_MULTIPLIER: Multiplikator für die Lernrate für das Feinabstimmen des Modells.
- DOCUMENT_SCHEMA: Schema für den Prozessor. Weitere Informationen finden Sie unter DocumentSchema-Darstellung.
HTTP-Methode und URL:
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
JSON-Text der Anfrage:
{
"rawDocument": {
"parent": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID",
"processor_version": {
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/DISPLAY_NAME",
"display_name": "DISPLAY_NAME",
"model_type": "MODEL_TYPE_GENERATIVE",
},
"base_processor_version": "projects/PROJECT_ID/locations/us/processors/PROCESSOR_ID/processorVersions/PRETRAINED_PROCESSOR_VERSION",
"foundation_model_tuning_options": {
"train_steps": TRAIN_STEPS,
"learning_rate_multiplier": LEARN_RATE_MULTIPLIER,
}
"document_schema": DOCUMENT_SCHEMA
}
}
Wenn Sie die Anfrage senden möchten, wählen Sie eine der folgenden Optionen aus:
curl
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
Nächste Schritte
Spezialprozessor weiter trainieren