Tetap teratur dengan koleksi
Simpan dan kategorikan konten berdasarkan preferensi Anda.
Ekstraksi berbasis template
Anda dapat melatih model berperforma tinggi dengan hanya tiga dokumen pelatihan dan tiga dokumen pengujian untuk kasus penggunaan tata letak tetap. Percepat pengembangan dan kurangi waktu produksi untuk jenis dokumen dengan template seperti W9, 1040, ACORD, survei, dan kuesioner.
Konfigurasi set data
Set data dokumen diperlukan untuk melatih, melakukan uptrain, atau mengevaluasi versi pemroses.
Pemroses Document AI belajar dari contoh, sama seperti manusia. Set data mendorong
stabilitas prosesor dalam hal performa.
Set data pelatihan
Untuk meningkatkan model dan akurasinya, latih set data pada dokumen Anda. Model ini
terdiri dari dokumen dengan kebenaran dasar. Anda memerlukan minimal tiga dokumen untuk melatih model baru.
Set data pengujian
Set data pengujian adalah yang digunakan model untuk menghasilkan skor F1 (akurasi). Set data ini
terdiri dari dokumen dengan kebenaran dasar. Untuk melihat seberapa sering model benar, kebenaran dasar digunakan untuk membandingkan prediksi model (kolom yang diekstrak dari
model) dengan jawaban yang benar. Set data pengujian harus memiliki minimal tiga dokumen.
Pelabelan yang tepat adalah salah satu langkah terpenting untuk mencapai akurasi tinggi.
Mode template memiliki beberapa metodologi pemberian label unik yang berbeda dari mode pelatihan lainnya:
Gambar kotak pembatas di sekitar seluruh area yang Anda harapkan berisi data (per label)
dalam dokumen, meskipun label kosong dalam dokumen pelatihan yang Anda beri label.
Anda dapat memberi label pada kolom kosong untuk pelatihan berbasis template. Jangan beri label pada kolom kosong
untuk pelatihan berbasis model.
Mem-build dan mengevaluasi ekstraktor kustom dengan mode template
Menetapkan lokasi set data. Pilih folder opsi default (terkelola Google). Tindakan ini
mungkin dilakukan secara otomatis segera setelah membuat pemroses.
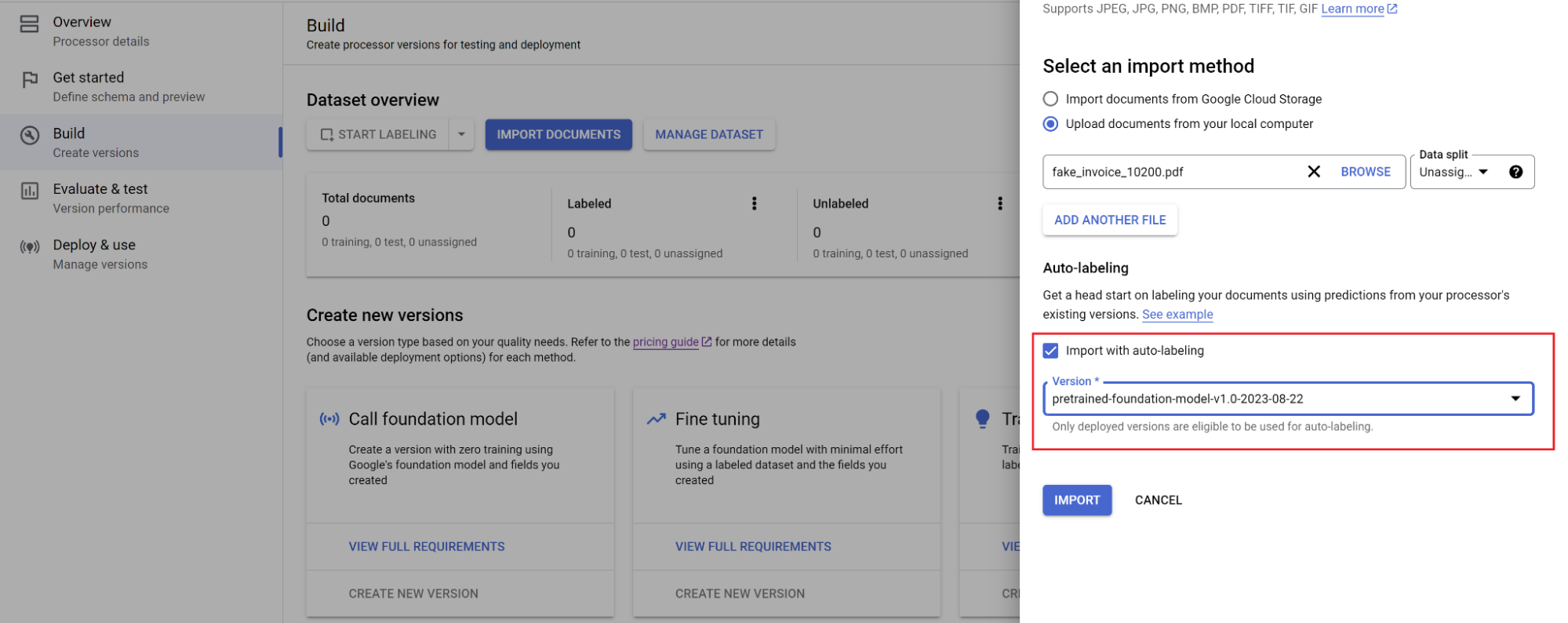
Buka tab Build, lalu pilih Import documents dengan label otomatis
diaktifkan. Menambahkan lebih banyak dokumen daripada tiga dokumen minimum yang diperlukan biasanya tidak meningkatkan kualitas untuk
pelatihan berbasis template. Daripada menambahkan lebih banyak, fokuslah pada pemberian label pada kumpulan kecil dengan sangat akurat.
Memperluas kotak pembatas. Kotak ini untuk mode template akan terlihat seperti contoh
sebelumnya. Luaskan kotak pembatas, dengan mengikuti praktik terbaik untuk hasil yang optimal.
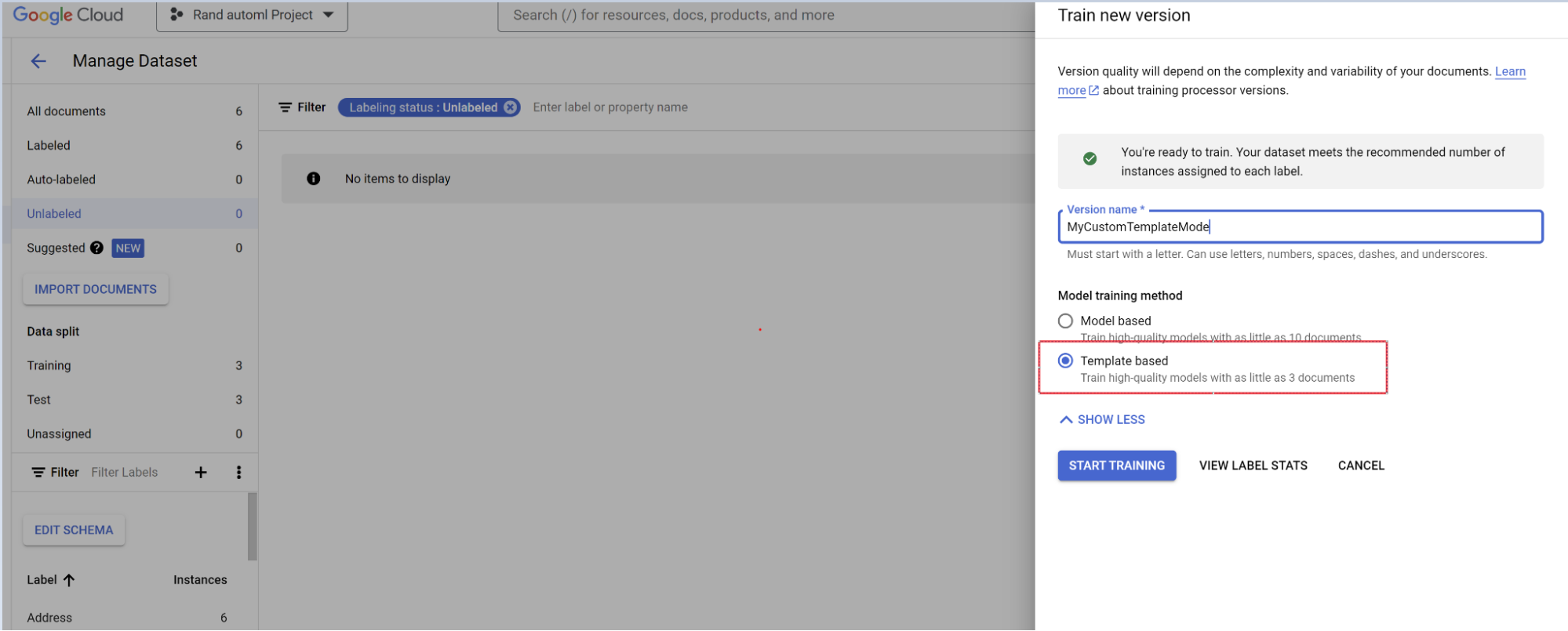
Melatih model.
Pilih Train new version.
Beri nama versi pemroses.
Buka Tampilkan opsi lanjutan dan pilih pendekatan model berbasis template.
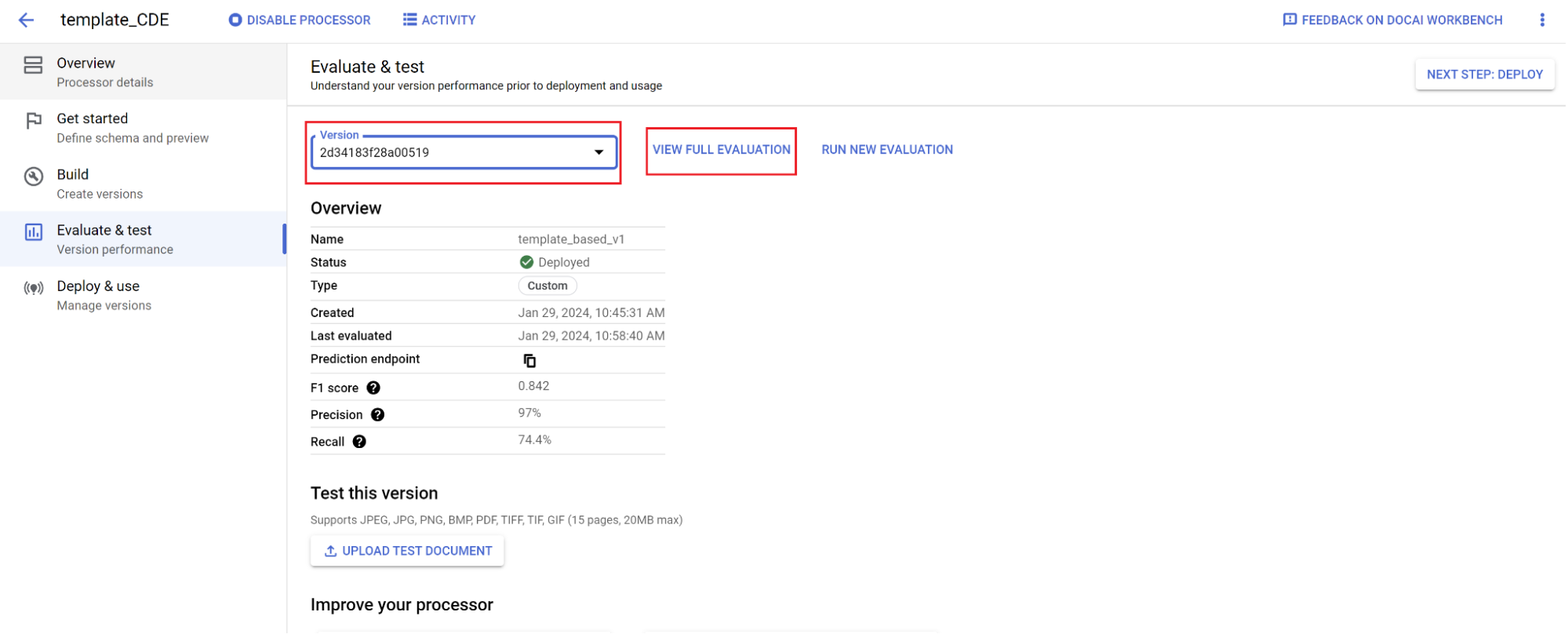
Evaluasi.
Buka Evaluasi & uji.
Pilih versi yang baru saja Anda latih, lalu pilih Lihat Evaluasi Lengkap.
Sekarang Anda akan melihat metrik seperti F1, presisi, dan recall untuk seluruh dokumen dan setiap kolom.
1. Tentukan apakah performa memenuhi sasaran produksi Anda, dan jika tidak, evaluasi ulang set pelatihan dan pengujian.
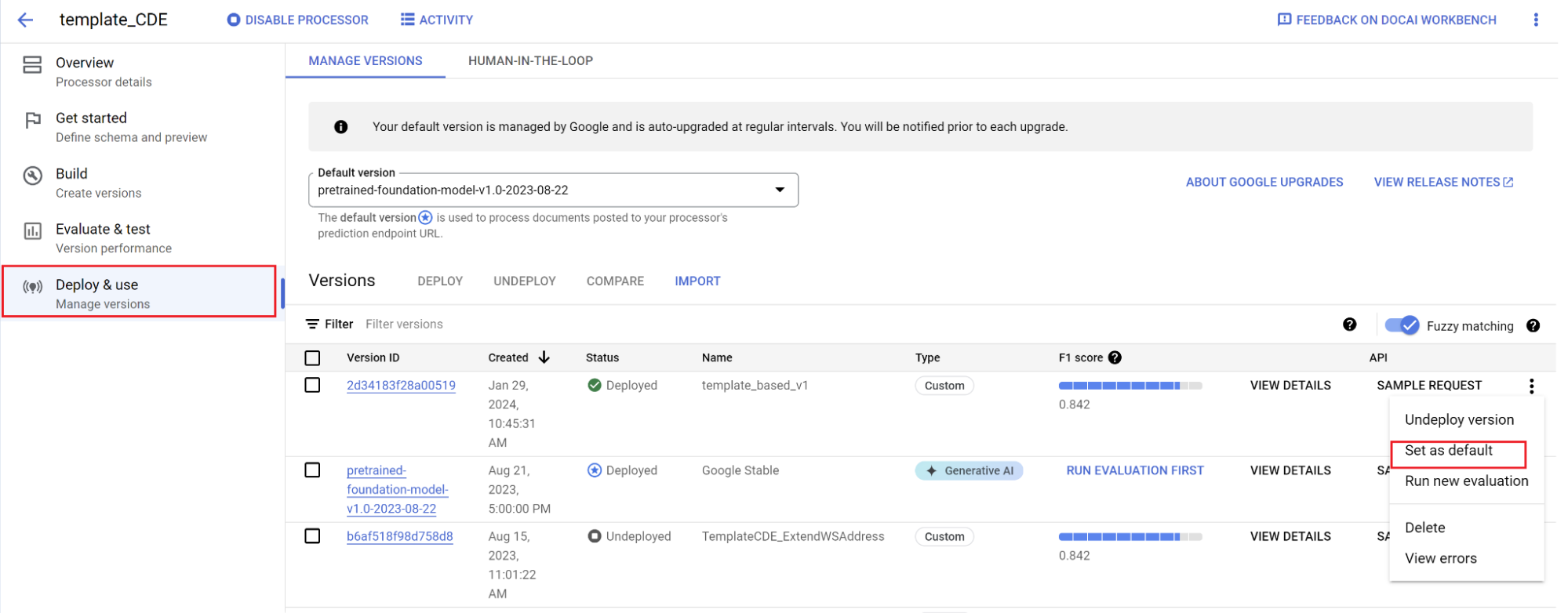
Tetapkan versi baru sebagai default.
Buka Kelola versi.
Pilih untuk melihat menu setelan, lalu tandai Tetapkan sebagai default.
Model Anda kini di-deploy dan dokumen yang dikirim ke pemroses ini menggunakan versi kustom Anda. Anda ingin mengevaluasi performa model (detail selengkapnya tentang cara melakukannya) untuk memeriksa apakah model memerlukan pelatihan lebih lanjut.
Referensi evaluasi
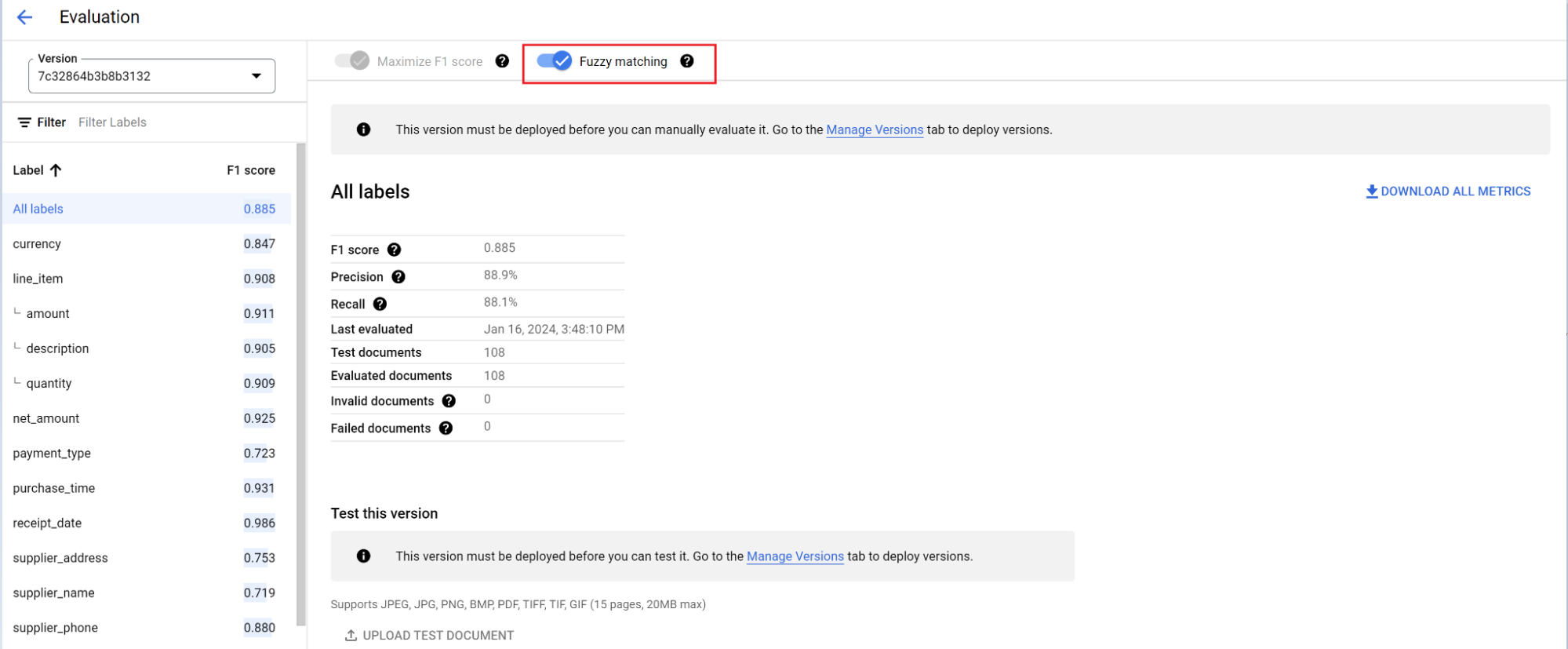
Mesin evaluasi dapat melakukan pencocokan persis atau pencocokan fuzzy.
Untuk kecocokan persis, nilai yang diekstrak harus sama persis dengan kebenaran dasar atau dihitung sebagai tidak cocok.
Ekstraksi pencocokan fuzzy yang memiliki sedikit perbedaan seperti perbedaan
kapitalisasi masih dihitung sebagai kecocokan. Hal ini dapat diubah di layar Evaluasi.
Pelabelan otomatis dengan model dasar
Model dasar dapat mengekstrak kolom secara akurat untuk berbagai jenis dokumen,
tetapi Anda juga dapat memberikan data pelatihan tambahan untuk meningkatkan akurasi
model untuk struktur dokumen tertentu.
Document AI menggunakan nama label yang Anda tentukan dan anotasi sebelumnya untuk mempercepat dan mempermudah pemberian label pada dokumen dalam skala besar dengan pelabelan otomatis.
Setelah membuat pemroses kustom, buka tab Mulai.
Pilih Buat Kolom Baru.
Buka tab Build, lalu pilih Import documents.
Pilih jalur dokumen dan set tempat dokumen akan diimpor. Centang kotak centang pemberian label otomatis dan pilih model dasar.
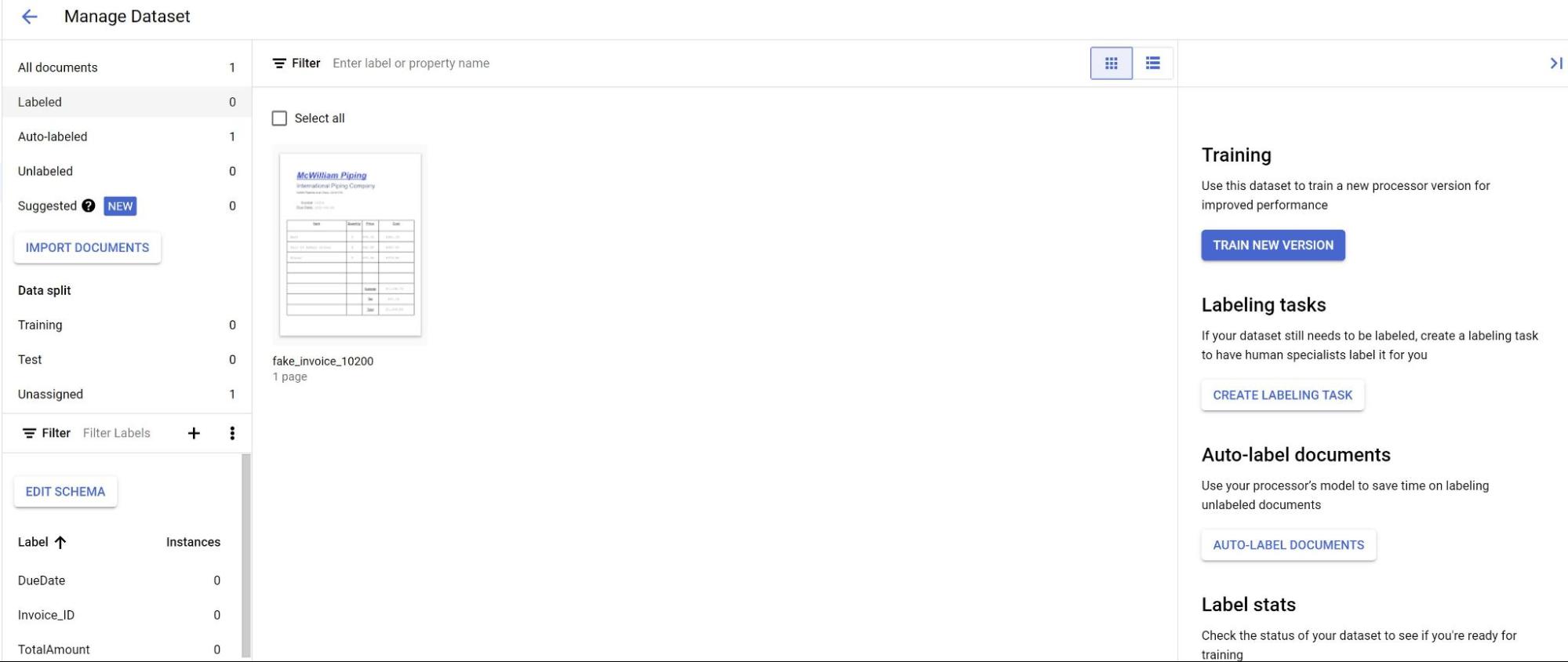
Di tab Build, pilih Kelola set data. Anda akan melihat dokumen yang diimpor. Pilih salah satu dokumen Anda.
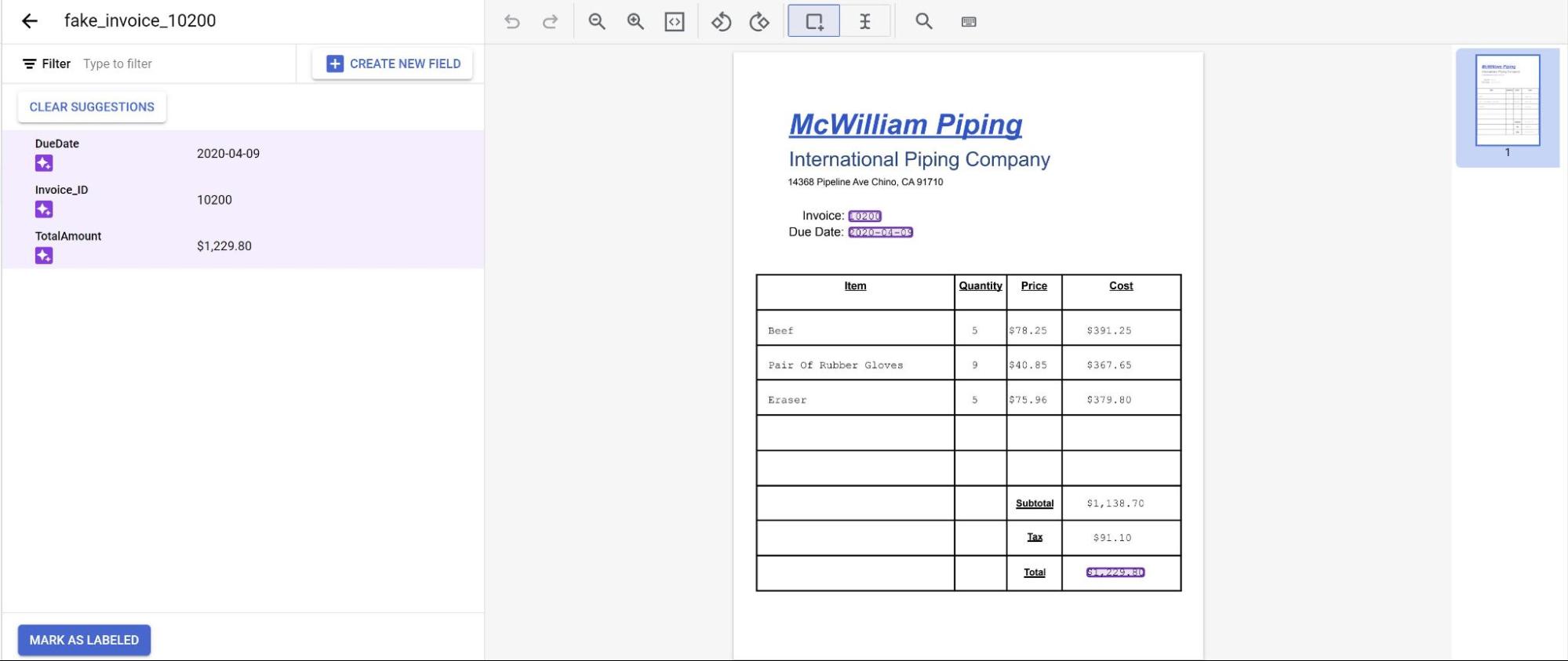
Anda melihat prediksi dari model yang ditandai dengan warna ungu, Anda perlu meninjau
setiap label yang diprediksi oleh model dan memastikannya sudah benar. Jika ada kolom yang tidak ada, Anda juga harus menambahkannya.
Setelah dokumen ditinjau, pilih Tandai sebagai telah diberi label.
Dokumen kini siap digunakan oleh model. Pastikan dokumen berada
dalam set pengujian atau pelatihan.
[[["Mudah dipahami","easyToUnderstand","thumb-up"],["Memecahkan masalah saya","solvedMyProblem","thumb-up"],["Lainnya","otherUp","thumb-up"]],[["Sulit dipahami","hardToUnderstand","thumb-down"],["Informasi atau kode contoh salah","incorrectInformationOrSampleCode","thumb-down"],["Informasi/contoh yang saya butuhkan tidak ada","missingTheInformationSamplesINeed","thumb-down"],["Masalah terjemahan","translationIssue","thumb-down"],["Lainnya","otherDown","thumb-down"]],["Terakhir diperbarui pada 2025-09-02 UTC."],[[["\u003cp\u003eTemplate-based extraction allows for training a high-performing model with a minimum of three training and three test documents, ideal for fixed-layout documents like W9s and questionnaires.\u003c/p\u003e\n"],["\u003cp\u003eA document dataset, comprising documents with ground-truth data, is essential for training, up-training, and evaluating a processor version, as the processor learns from these examples.\u003c/p\u003e\n"],["\u003cp\u003eFor template mode labeling, it is recommended to draw bounding boxes around the entire expected data area within a document, even if the field is empty in the training document, unlike model-based training.\u003c/p\u003e\n"],["\u003cp\u003eWhen building a custom extractor, auto-labeling can be enabled during document import, and it is advised to focus on accurately labeling a small set of documents rather than adding more documents during template-based training.\u003c/p\u003e\n"],["\u003cp\u003eThe foundation model allows for auto-labeling, which can be improved in accuracy and performance with the addition of training data with descriptive label names, while ensuring that all fields are accurate.\u003c/p\u003e\n"]]],[],null,["# Template-based extraction\n=========================\n\nYou can train a high-performing model with as little as three training and three test\ndocuments for fixed-layout use cases. Accelerate development and reduce time to\nproduction for templated document types like W9, 1040, ACORD, surveys, and questionnaires.\n\n\nDataset configuration\n---------------------\n\nA document dataset is required to train, up-train, or evaluate a processor version. Document AI processors learn from examples, just like humans. Dataset fuels processor stability in terms of performance. \n\n### Train dataset\n\nTo improve the model and its accuracy, train a dataset on your documents. The model is made up of documents with ground-truth. You need a minimum of three documents to train a new model. Ground-truth is the correctly labeled data, as determined by humans.\n\n### Test dataset\n\nThe test dataset is what the model uses to generate an F1 score (accuracy). It is made up of documents with ground-truth. To see how often the model is right, the ground truth is used to compare the model's predictions (extracted fields from the model) with the correct answers. The test dataset should have at least three documents.\n\n\u003cbr /\u003e\n\nBefore you begin\n----------------\n\nIf not already done, enable:\n\n- [Billing](/document-ai/docs/setup#billing)\n- [Document AI API](/document-ai/docs/setup)\n\nTemplate-mode labeling best practices\n-------------------------------------\n\nProper labeling is one of the most important steps to achieving high accuracy.\nTemplate mode has some unique labeling methodology that differs from other training modes:\n\n- Draw bounding boxes around the entire area you expect data to be in (per label) within a document, even if the label is empty in the training document you're labeling.\n- You may label empty fields for template-based training. Don't label empty fields for model-based training.\n\n| **Recommended.** Labeling example for template-based training to extract the top section of a 1040.\n| **Not recommended.** Labeling example for template-based training to extract the top section of a 1040. This is the labeling technique you should use for model-based training for documents with layout variation across documents.\n\nBuild and evaluate a custom extractor with template mode\n--------------------------------------------------------\n\n1. Create a custom extractor. [Create a processor](/document-ai/docs/workbench/build-custom-processor#create_a_processor)\n and [define fields](/document-ai/docs/workbench/build-custom-processor#define_processor_fields)\n you want to extract following [best practices](/document-ai/docs/workbench/label-documents#name-fields),\n which is important because it impacts extraction quality.\n\n2. Set dataset location. Select the default option folder (Google-managed). This\n might be done automatically shortly after creating the processor.\n\n3. Navigate to the **Build** tab and select **Import documents** with auto-labeling\n enabled. Adding more documents than the minimum of three needed typically doesn't improve quality for\n template-based training. Instead of adding more, focus on labeling a small set very accurately.\n\n | **Note:** You can experiment by increasing the training set size if you observe template variations in your dataset. Try to include at least three training documents per variation. At least three training documents, three test documents, and three schema labels are required per set.\n4. Extend bounding boxes. These boxes for template mode should look like the preceding\n examples. Extend the bounding boxes, following the best practices for the optimal result.\n\n5. Train model.\n\n 1. Select **Train new version**.\n 2. Name the processor version.\n 3. Go to **Show advanced options** and select the template-based model approach.\n\n | **Note:** It takes some time for the training to complete.\n6. Evaluation.\n\n 1. Go to **Evaluate \\& test**.\n 2. Select the version you just trained, then select **View Full Evaluation**.\n\n You now see metrics such as F1, precision, and recall for the entire document and each field.\n 1. Decide if performance meets your production goals, and if not, reevaluate training and testing sets.\n7. Set a new version as the default.\n\n 1. Navigate to **Manage versions**.\n 2. Select to see the settings menu, then mark **Set as default**.\n\n Your model is now deployed and documents sent to this processor use your custom\n version. You want to evaluate the model's performance ([more details](/document-ai/docs/workbench/evaluate)\n on how to do that) to check if it requires further training.\n\nEvaluation reference\n--------------------\n\nThe evaluation engine can do both exact match or [fuzzy matching](/document-ai/docs/workbench/evaluate#fuzzy_matching).\nFor an exact match, the extracted value must exactly match the ground truth or is counted as a miss.\n\nFuzzy matching extractions that had slight differences such as capitalization\ndifferences still count as a match. This can be changed at the **Evaluation** screen.\n\nAuto-labeling with the foundation model\n---------------------------------------\n\nThe foundation model can accurately extract fields for a variety of document types,\nbut you can also provide additional training data to improve the accuracy of the\nmodel for specific document structures.\n\nDocument AI uses the label names you define and previous annotations to make\nit quicker and easier to label documents at scale with auto-labeling.\n\n1. After creating a custom processor, go to the **Get started** tab.\n2. Select **Create New Field**.\n\n | **Note:** The label name with the foundation model can greatly affect model accuracy and performance. Be sure to give a descriptive name.\n\n3. Navigate to the **Build** tab and then select **Import documents**.\n\n4. Select the path of the documents and which set the documents should be imported\n into. Check the auto-labeling checkbox and select the foundation model.\n\n5. In the **Build** tab, select **Manage dataset**. You should see your imported\n documents. Select one of your documents.\n\n6. You see the predictions from the model highlighted in purple, you need to review\n each label predicted by the model and ensure it's correct. If there are missing\n fields, you need to add those as well.\n\n | **Note:** It's important that all fields are as accurate as possible or model performance is going to be affected. For more [details on labeling](/document-ai/docs/workbench/label-documents).\n\n7. Once the document has been reviewed, select **Mark as labeled**.\n\n8. The document is now ready to be used by the model. Make sure the document is\n in either the testing or training set."]]