Los registros de trabajos y del clúster de Dataproc se pueden ver, buscar, filtrar y archivar en Cloud Logging.
Consulta los precios de Google Cloud Observability para comprender tus costos.
Consulta Períodos de retención de registros para obtener información sobre el tema.
Consulta Exclusiones de registros para inhabilitar todos los registros o excluirlos de Logging.
Consulta Descripción general de enrutamiento y almacenamiento para enrutar los registros de Logging a CloudStorage, BigQuery o Pub/Sub.
Niveles de registro de componentes
Configura los niveles de registro de Spark, Hadoop, Flink y otros componentes de Dataproc con propiedades del clúster específicas del componente log4j, como hadoop-log4j, cuando creas un clúster. Los niveles de registro de componentes basados en clústeres se aplican a los daemons de servicio, como el ResourceManager de YARN, y a los trabajos que se ejecutan en el clúster.
Si las propiedades de log4j no son compatibles con un componente, como el componente de Presto, escribe una acción de inicialización que edite el archivo log4j.properties o log4j2.properties del componente.
Niveles de registro de componentes específicos del trabajo: También puedes establecer niveles de registro de componentes cuando envías un trabajo. Estos niveles de registro se aplican al trabajo y tienen prioridad sobre los niveles de registro establecidos cuando creaste el clúster. Consulta Propiedades del clúster y del trabajo para obtener más información.
Niveles de registro de versiones de componentes de Spark y Hive:
Los componentes de Spark 3.3.X y Hive 3.X usan propiedades de log4j2, mientras que las versiones anteriores de estos componentes usan propiedades de log4j (consulta Apache Log4j2).
Usa un prefijo spark-log4j: para establecer los niveles de registro de Spark en un clúster.
Ejemplo: Versión 2.0 de la imagen de Dataproc con Spark 3.1 para establecer
log4j.logger.org.apache.spark:gcloud dataproc clusters create ... \ --properties spark-log4j:log4j.logger.org.apache.spark=DEBUG
Ejemplo: Versión de imagen 2.1 de Dataproc con Spark 3.3 para establecer
logger.sparkRoot.level:gcloud dataproc clusters create ...\ --properties spark-log4j:logger.sparkRoot.level=debug
Niveles de registro del controlador de trabajos
Dataproc usa un nivel de registro predeterminado de INFO para los programas de controladores de trabajos. Puedes cambiar este parámetro de configuración para uno o más paquetes con la marca --driver-log-levels del comando gcloud dataproc jobs submit.
Ejemplo:
Establece el nivel de registro de DEBUG cuando envíes un trabajo de Spark que lea archivos de Cloud Storage.
gcloud dataproc jobs submit spark ...\ --driver-log-levels org.apache.spark=DEBUG,com.google.cloud.hadoop.gcsio=DEBUG
Ejemplo:
Establece el nivel de registro de root en WARN y el nivel de registro de com.example en INFO.
gcloud dataproc jobs submit hadoop ...\ --driver-log-levels root=WARN,com.example=INFO
Niveles de registro del ejecutor de Spark
Para configurar los niveles de registro del ejecutor de Spark, haz lo siguiente:
Prepara un archivo de configuración de log4j y, luego, súbelo a Cloud Storage
.Haz referencia a tu archivo de configuración cuando envíes el trabajo.
Ejemplo:
gcloud dataproc jobs submit spark ...\ --file gs://my-bucket/path/spark-log4j.properties \ --properties spark.executor.extraJavaOptions=-Dlog4j.configuration=file:spark-log4j.properties
Spark descarga el archivo de propiedades de Cloud Storage en el directorio de trabajo local del trabajo, al que se hace referencia como file:<name> en -Dlog4j.configuration.
Registros de trabajos de Dataproc en Logging
Consulta Registros y resultados de trabajos de Dataproc para obtener información sobre cómo habilitar los registros del controlador de trabajos de Dataproc en Logging.
Accede a los registros de trabajos en Logging
Accede a los registros de trabajos de Dataproc con el Explorador de registros, el comando gcloud logging o la API de Logging.
Console
El controlador de trabajos de Dataproc y los registros del contenedor de YARN se enumeran en el recurso Trabajo de Cloud Dataproc.
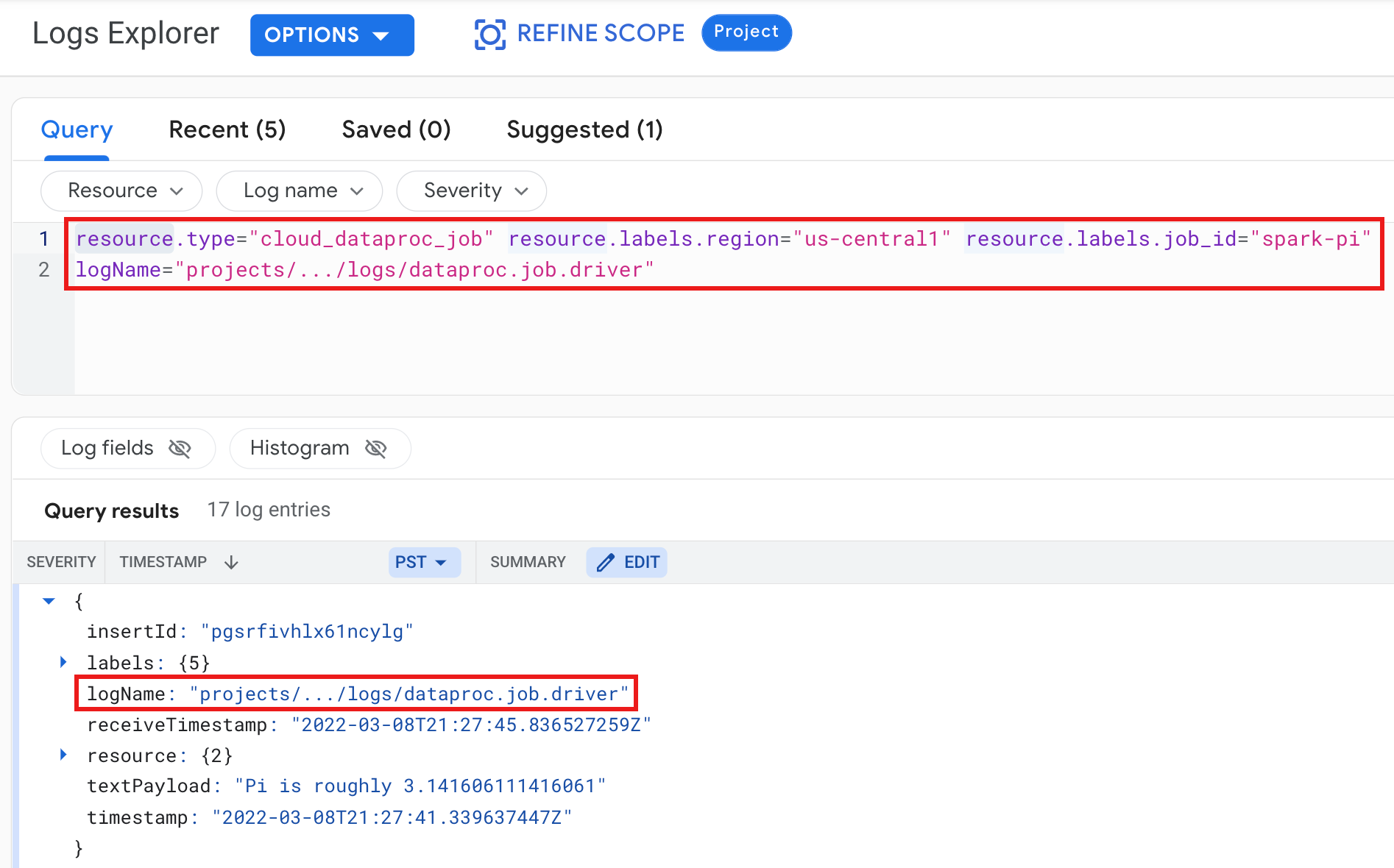
Ejemplo: Registro del controlador de trabajos después de ejecutar una consulta del Explorador de registros con las siguientes selecciones:
- Recurso:
Cloud Dataproc Job - Nombre del registro:
dataproc.job.driver
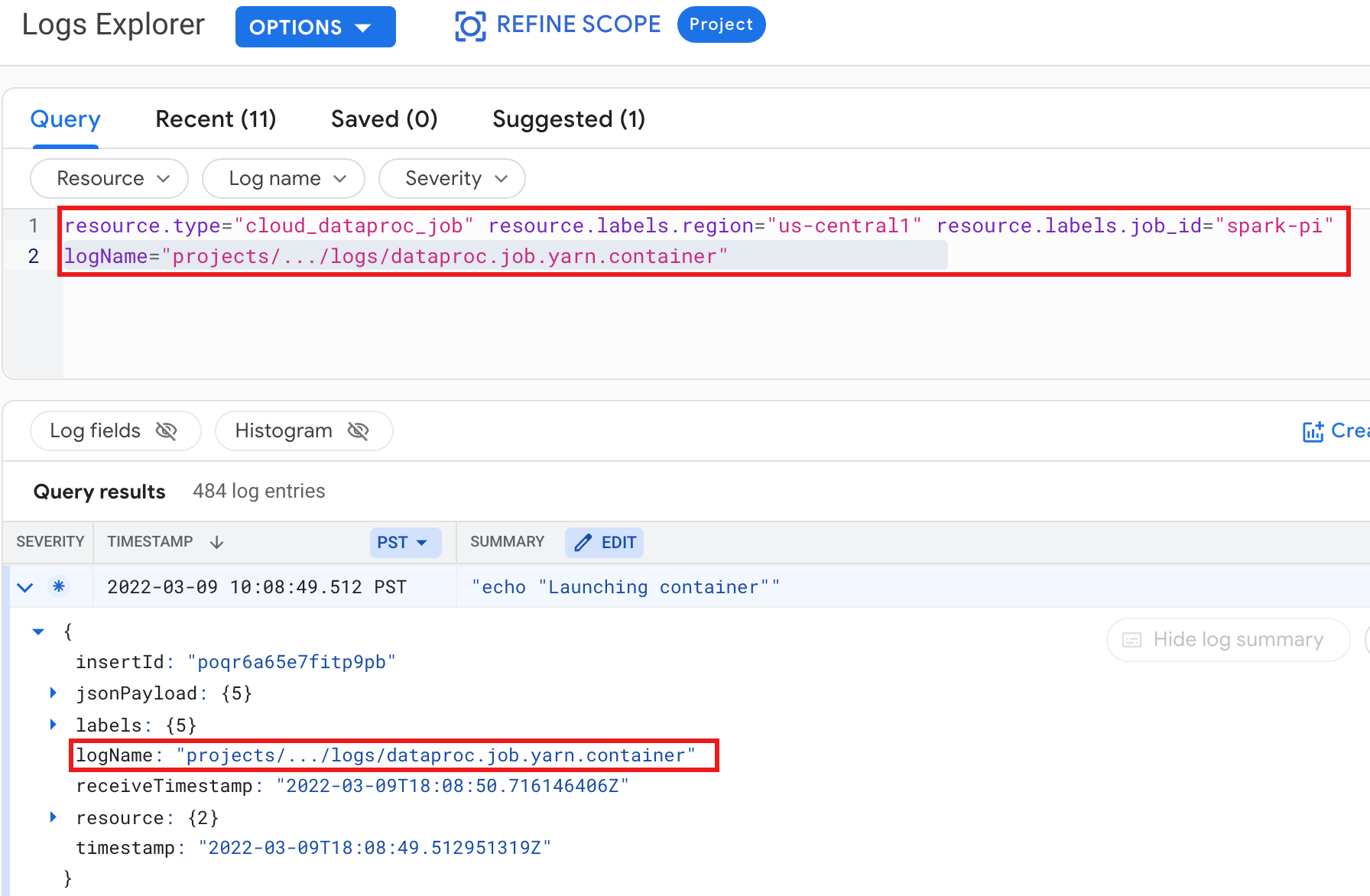
Ejemplo: Registro de contenedor de YARN después de ejecutar una consulta del Explorador de registros con las siguientes selecciones:
- Recurso:
Cloud Dataproc Job - Nombre del registro:
dataproc.job.yarn.container
gcloud
Puedes leer las entradas del registro de trabajos con el comando gcloud logging read. Los argumentos de recursos se deben encerrar entre comillas (“…”). En el siguiente comando, se usan etiquetas de clúster para filtrar las entradas de registro devueltas.
gcloud logging read \ "resource.type=cloud_dataproc_job \ resource.labels.region=cluster-region \ resource.labels.job_id=my-job-id"
Resultado de muestra (parcial):
jsonPayload: class: org.apache.hadoop.hdfs.StateChange filename: hadoop-hdfs-namenode-test-dataproc-resize-cluster-20190410-38an-m-0.log ,,, logName: projects/project-id/logs/hadoop-hdfs-namenode --- jsonPayload: class: SecurityLogger.org.apache.hadoop.security.authorize.ServiceAuthorizationManager filename: cluster-name-dataproc-resize-cluster-20190410-38an-m-0.log ... logName: projects/google.com:hadoop-cloud-dev/logs/hadoop-hdfs-namenode
API de REST
Puedes usar la API de REST de Logging para mostrar las entradas de registros (consulta entries.list).
Registros del clúster de Dataproc en Logging
Dataproc exporta los siguientes registros de Apache Hadoop, Spark, Hive, Zookeeper y otros registros de clúster de Dataproc a Cloud Logging.
| Tipo de registro | Nombre del registro | Descripción | Notas |
|---|---|---|---|
| Registros de daemon principal | hadoop-hdfs hadoop-hdfs-namenode hadoop-hdfs-secondarynamenode hadoop-hdfs-zkfc hadoop-yarn-resourcemanager hadoop-yarn-timelineserver hive-metastore hive-server2 mapred-mapred-historyserver zookeeper |
Nodo de registro Namenode de HDFS Namenode secundario de HDFS Controlador de conmutación por error de Zookeeper Administrador de recursos de YARN Servidor de línea de tiempo de YARN Metastore de Hive Server2 de Hive Servidor de historial de trabajos de Mapreduce Servidor de Zookeeper |
|
| Registros de daemon trabajador |
hadoop-hdfs-datanode hadoop-yarn-nodemanager |
Datanode de HDFS Nodemanager de YARN |
|
| Registros del sistema | autoscaler google.dataproc.agent google.dataproc.startup |
Registro del escalador automático de Dataproc Registro de agente de Dataproc Registro de secuencia de comandos de inicio de Dataproc y registro de acciones de inicialización |
|
| Registros extendidos (adicionales) |
knox gateway-audit zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
Todos los registros dentro de los subdirectorios de /var/log/ que coinciden con lo siguiente:knox (incluye gateway-audit.log) zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
Si configuras la propiedad
dataproc:dataproc.logging.extended.enabled=false, se inhabilita la recopilación de registros extendidos en el clúster.
|
| Syslogs de la VM |
syslog |
Registros del sistema de los nodos principales y trabajadores del clúster |
Si se configura la propiedad
dataproc:dataproc.logging.syslog.enabled=false, se inhabilita la recopilación de registros del sistema de la VM en el clúster.
|
Accede a los registros del clúster en Cloud Logging
Puedes acceder a los registros del clúster de Dataproc con el Explorador de registros, el comando gcloud logging o la API de Logging.
Console
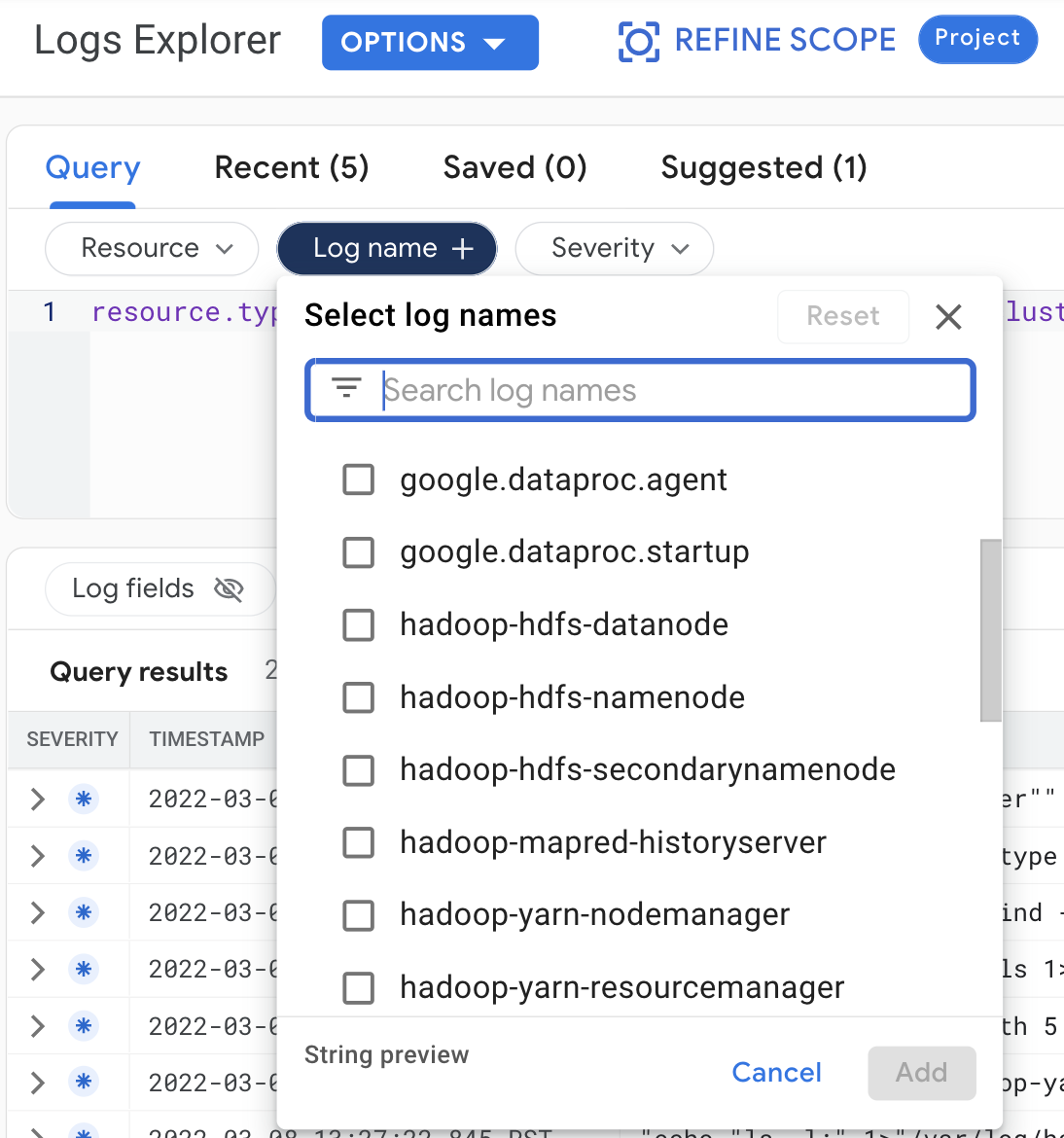
Realiza las siguientes selecciones de consultas para ver los registros del clúster en el Explorador de registros:
- Recurso:
Cloud Dataproc Cluster - Nombre del registro: log name
gcloud
Puedes leer las entradas del registro del clúster con el comando gcloud logging read. Los argumentos de recursos se deben encerrar entre comillas (“…”). En el siguiente comando, se usan etiquetas de clúster para filtrar las entradas de registro devueltas.
gcloud logging read <<'EOF' "resource.type=cloud_dataproc_cluster resource.labels.region=cluster-region resource.labels.cluster_name=cluster-name resource.labels.cluster_uuid=cluster-uuid" EOF
Resultado de muestra (parcial):
jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-cluster-name-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager --- jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-component-gateway-cluster-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager
API de REST
Puedes usar la API de REST de Logging para mostrar las entradas de registros (consulta entries.list).
Permisos
Para escribir registros en Logging, la cuenta de servicio de la VM de Dataproc debe tener el rol de IAM logging.logWriter. La cuenta de servicio de Dataproc predeterminada tiene esta función. Si usas una cuenta de servicio personalizada, debes asignarle esta función.
Protege los registros
De forma predeterminada, los registros de Logging se encriptan en reposo. Puedes habilitar las claves de encriptación administradas por el cliente (CMEK) para encriptar los registros. Para obtener más información sobre la compatibilidad con CMEK, consulta Administra las claves que protegen los datos del enrutador de registros y Administra las claves que protegen los datos del almacenamiento de Logging.
¿Qué sigue?
- Explora Google Cloud Observability.