创建 Dataproc 集群时,您可以启用 Dataproc 个人集群身份验证,以允许集群上的交互式工作负载以用户身份安全地运行。这意味着,与其他 Google Cloud 资源(如 Cloud Storage)的交互会以您自己的身份而非集群服务账号身份进行身份验证。
注意事项
如果您在创建集群时启用了个人集群身份验证,则只能您的身份才能使用该集群。其他用户将无法在集群上运行作业,也无法访问集群上的组件网关端点。
启用了个人集群身份验证的集群会禁止 SSH 访问和 Compute Engine 功能,例如集群中所有虚拟机上的启动脚本。
启用了个人集群身份验证的集群会自动在集群上启用和配置 Kerberos,以确保集群内通信的安全。但是,集群上的所有 Kerberos 身份都会以同一用户身份与 Google Cloud资源进行交互。
启用了个人集群身份验证的集群不支持自定义映像。
Dataproc 个人集群身份验证不支持 Dataproc 工作流。
Dataproc 个人集群身份验证仅适用于个人(真人)用户运行的交互式作业。长时间运行的作业和操作应配置和使用适当的服务账号身份。
传播的凭据使用凭据访问边界缩小范围。默认访问边界仅限于对包含集群的同一项目拥有的 Cloud Storage 存储分区中的 Cloud Storage 对象执行读写操作。 您可以在 enable_an_interactive_session 时定义非默认访问边界。
Dataproc 个人集群身份验证使用 Compute Engine 客机属性。如果停用了客机属性功能,个人集群身份验证会失败。
目标
创建启用了 Dataproc 个人集群身份验证的 Dataproc 集群。
开始向该集群传播凭据。
在该集群上使用 Jupyter 笔记本来运行 Spark 作业,以使用您的凭据进行身份验证。
准备工作
创建项目
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
如果您使用的是外部身份提供方 (IdP),则必须先使用联合身份登录 gcloud CLI。
-
如需初始化 gcloud CLI,请运行以下命令:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
如果您使用的是外部身份提供方 (IdP),则必须先使用联合身份登录 gcloud CLI。
-
如需初始化 gcloud CLI,请运行以下命令:
gcloud init - 启动 Cloud Shell 会话。
- 运行
gcloud auth login以获取有效的用户凭据。 在 gcloud 中查找活跃账号的电子邮件地址。
gcloud auth list --filter=status=ACTIVE --format="value(account)"
创建集群。
gcloud dataproc clusters create CLUSTER_NAME \ --properties=dataproc:dataproc.personal-auth.user=your-email-address \ --enable-component-gateway \ --optional-components=JUPYTER \ --region=REGION
为集群启用凭据传播会话,以便在与 Google Cloud资源交互时开始使用您的个人凭据。
gcloud dataproc clusters enable-personal-auth-session \ --region=REGION \ CLUSTER_NAME
示例输出:
Injecting initial credentials into the cluster CLUSTER_NAME...done. Periodically refreshing credentials for cluster CLUSTER_NAME. This will continue running until the command is interrupted...
缩小范围的访问权限边界示例:以下示例启用了比默认范围缩小的凭据访问边界更具限制性的个人身份验证会话。它会限制对 Dataproc 集群的暂存存储桶的访问(如需了解详情,请参阅使用凭据访问边界缩小范围)。
gcloud dataproc clusters enable-personal-auth-session \ --project=PROJECT_ID \ --region=REGION \ --access-boundary=<(echo -n "{ \ \"access_boundary\": { \ \"accessBoundaryRules\": [{ \ \"availableResource\": \"//storage.googleapis.com/projects/_/buckets/$(gcloud dataproc clusters describe --project=PROJECT_ID --region=REGION CLUSTER_NAME --format="value(config.configBucket)")\", \ \"availablePermissions\": [ \ \"inRole:roles/storage.objectViewer\", \ \"inRole:roles/storage.objectCreator\", \ \"inRole:roles/storage.objectAdmin\", \ \"inRole:roles/storage.legacyBucketReader\" \ ] \ }] \ } \ }") \ CLUSTER_NAME
保持运行该命令并切换到新的 Cloud Shell 标签页或终端会话。客户端会在运行命令的同时刷新凭据。
输入
Ctrl-C以结束会话。- 获取集群详情。
gcloud dataproc clusters describe CLUSTER_NAME --region=REGION
集群详情中列出了 Jupyter 网页界面网址。
... JupyterLab: https://UUID-dot-us-central1.dataproc.googleusercontent.com/jupyter/lab/ ...
- 将网址复制到本地浏览器中以启动 Jupyter 界面。
- 检查个人集群身份验证是否成功。
- 启动 Jupyter 终端。
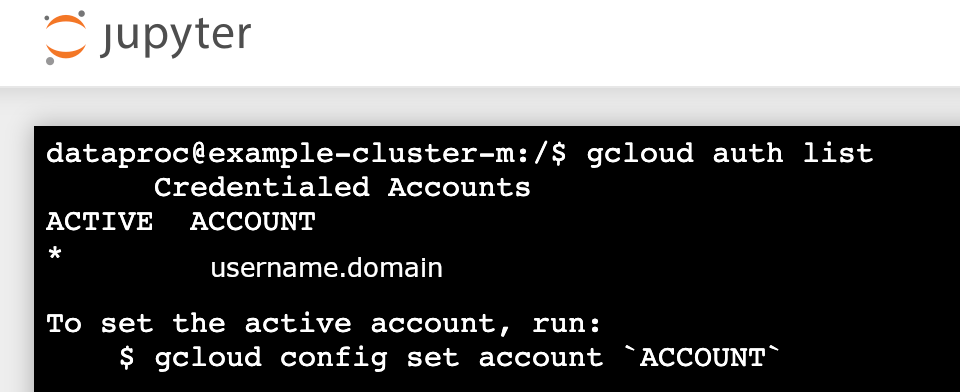
- 运行
gcloud auth list - 验证您的用户名是否是唯一的活跃账号。
- 在 Jupyter 终端中,启用 Jupyter 以通过 Kerberos 进行身份验证并提交 Spark 作业。
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- 运行
klist以验证 Jupyter 是否已获取有效的 TGT。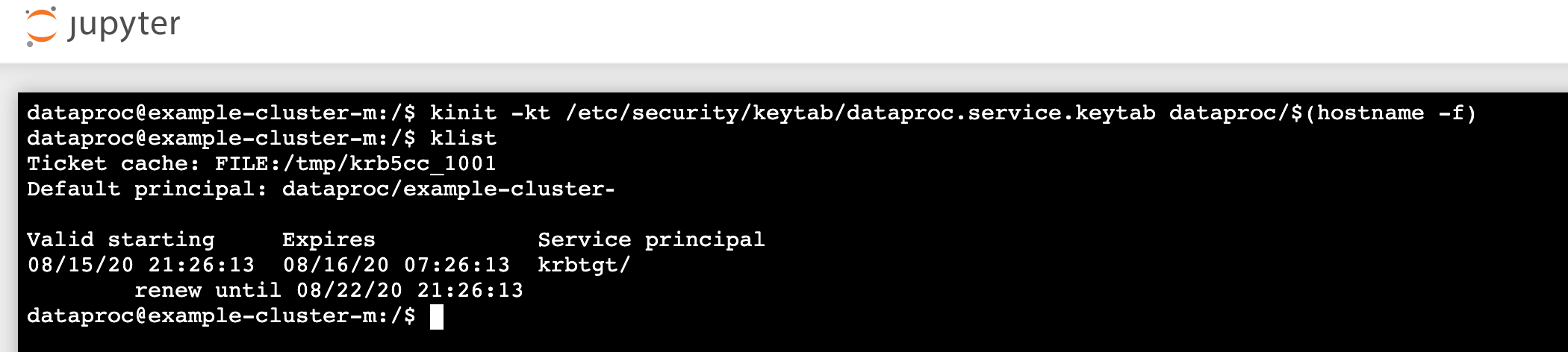
- 运行
- 在 Juypter 终端中,使用 gcloud CLI 在您的项目的 Cloud Storage 存储桶中创建
rose.txt文件。echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- 将文件标记为不公开,以便只有您的用户账号可以读取其中的内容或写入其中。在与 Cloud Storage 交互时,Jupyter 将使用您的个人凭据。
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- 验证您的私人访问权限。
gcloud storage objects describe gs://$BUCKET/rose.txt
acl:
- 将文件标记为不公开,以便只有您的用户账号可以读取其中的内容或写入其中。在与 Cloud Storage 交互时,Jupyter 将使用您的个人凭据。
- email: $USER entity: user-$USER role: OWNER
- 点击组件网关 Jupyter 链接以启动 Jupyter 界面。
- 检查个人集群身份验证是否成功。
- 启动 Jupyter 终端
- 运行
gcloud auth list - 验证您的用户名是否是唯一的活跃账号。
- 在 Jupyter 终端中,启用 Jupyter 以通过 Kerberos 进行身份验证并提交 Spark 作业。
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- 运行
klist以验证 Jupyter 是否已获取有效的 TGT。
- 运行
- 在 Juypter 终端中,使用 gcloud CLI 在您的项目的 Cloud Storage 存储桶中创建
rose.txt文件。echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- 将文件标记为不公开,以便只有您的用户账号可以读取其中的内容或写入其中。在与 Cloud Storage 交互时,Jupyter 将使用您的个人凭据。
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- 验证您的私人访问权限。
gcloud storage objects describe gs://bucket-name/rose.txt
acl:
- 将文件标记为不公开,以便只有您的用户账号可以读取其中的内容或写入其中。在与 Cloud Storage 交互时,Jupyter 将使用您的个人凭据。
- email: $USER entity: user-$USER role: OWNER
- 转到相应文件夹,然后创建 PySpark 笔记本。
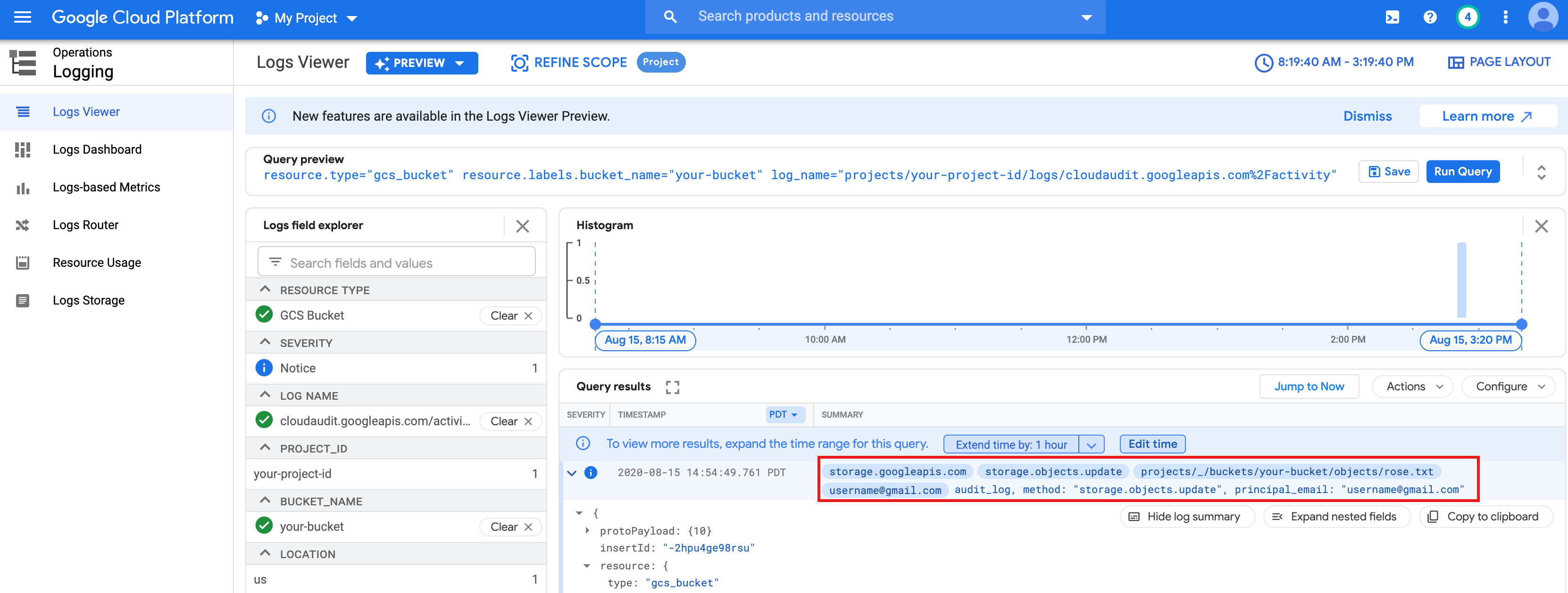
针对上面创建的
rose.txt文件运行基本字数统计作业。text_file = sc.textFile("gs://bucket-name/rose.txt") counts = text_file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) print(counts.collect())rose.txt文件,因为它是使用您的用户凭据运行的。您还可以查看 Cloud Storage 存储桶审核日志,以验证作业是否使用您的身份访问 Cloud Storage(如需了解详情,请参阅将 Cloud Audit Logs 与 Cloud Storage 结合使用)。
- 删除 Dataproc 集群。
gcloud dataproc clusters delete CLUSTER_NAME --region=REGION
配置环境
通过 Cloud Shell 或本地终端配置环境: