Dataproc クラスタを作成するときに Dataproc 個人用クラスタ認証を有効にすると、クラスタ上のインタラクティブなワークロードをユーザー ID として安全に実行できるようになります。つまり、Cloud Storage などの他の Google Cloud リソースとのやり取りは、クラスタのサービス アカウントではなくユーザー自身として認証されます。
考慮事項
個人用クラスタ認証を有効にしてクラスタを作成すると、クラスタはユーザーの ID でのみ使用できるようになります。他のユーザーは、クラスタでジョブを実行したり、クラスタ上のコンポーネント ゲートウェイのエンドポイントにアクセスしたりできなくなります。
個人用クラスタ認証が有効になっているクラスタでは、SSH アクセスと Compute Engine の機能(クラスタ内のすべての VM の起動スクリプトなど)が使えなくなります。
個人用クラスタ認証が有効になっているクラスタでは、クラスタ内で安全な通信を行うために Kerberos が自動的に有効になり、クラスタ上に構成されます。ただし、クラスタのすべての Kerberos ID は、同じユーザーとして Google Cloudリソースとやり取りします。
個人用クラスタ認証が有効になっているクラスタでは、カスタム イメージはサポートされません。
Dataproc 個人用クラスタ認証は、Dataproc ワークフローをサポートしていません。
Dataproc 個人用クラスタ認証は、個人(人間の)ユーザーが実行するインタラクティブ ジョブのみを対象としています。長時間実行されるジョブとオペレーションでは、適切なサービス アカウント ID を構成して使用する必要があります。
伝播される認証情報は、認証情報アクセス境界によって範囲が限定されます。デフォルトのアクセス境界は、クラスタを含む同じプロジェクトが所有する Cloud Storage バケット内の Cloud Storage オブジェクトの読み取りと書き込みに限定されます。enable_an_interactive_session では、デフォルト以外のアクセス境界を定義できます。
Dataproc 個人用クラスタ認証では、Compute Engine のゲスト属性を使用します。ゲスト属性機能が無効になっている場合、個人用クラスタ認証は失敗します。
目標
Dataproc 個人用クラスタ認証を有効にして Dataproc クラスタを作成します。
クラスタへの認証情報の伝播を開始します。
クラスタで Jupyter ノートブックを使用して、認証情報で認証された Spark ジョブを実行します。
始める前に
プロジェクトを作成する
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
外部 ID プロバイダ(IdP)を使用している場合は、まず連携 ID を使用して gcloud CLI にログインする必要があります。
-
gcloud CLI を初期化するには、次のコマンドを実行します。
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
外部 ID プロバイダ(IdP)を使用している場合は、まず連携 ID を使用して gcloud CLI にログインする必要があります。
-
gcloud CLI を初期化するには、次のコマンドを実行します。
gcloud init - Cloud Shell セッションを開始します。
gcloud auth loginを実行して、有効なユーザー認証情報を取得します。gcloud でアクティブなアカウントのメールアドレスを確認します。
gcloud auth list --filter=status=ACTIVE --format="value(account)"
クラスタを作成します。
gcloud dataproc clusters create CLUSTER_NAME \ --properties=dataproc:dataproc.personal-auth.user=your-email-address \ --enable-component-gateway \ --optional-components=JUPYTER \ --region=REGION
Google Cloudリソースとやり取りするときに、クラスタの認証情報伝播セッションを有効にして、自身の個人用認証情報の使用を開始します。
gcloud dataproc clusters enable-personal-auth-session \ --region=REGION \ CLUSTER_NAME
出力例:
Injecting initial credentials into the cluster CLUSTER_NAME...done. Periodically refreshing credentials for cluster CLUSTER_NAME. This will continue running until the command is interrupted...
範囲が限定されたアクセス境界の例: 次の例では、範囲が限定されたデフォルトのアクセス境界よりも制限が厳しい個人用認証セッションを有効にしています。これによって、Dataproc クラスタのステージング バケットへのアクセスが制限されます(詳細については、認証情報アクセス境界によるダウンスコープをご覧ください)。
gcloud dataproc clusters enable-personal-auth-session \ --project=PROJECT_ID \ --region=REGION \ --access-boundary=<(echo -n "{ \ \"access_boundary\": { \ \"accessBoundaryRules\": [{ \ \"availableResource\": \"//storage.googleapis.com/projects/_/buckets/$(gcloud dataproc clusters describe --project=PROJECT_ID --region=REGION CLUSTER_NAME --format="value(config.configBucket)")\", \ \"availablePermissions\": [ \ \"inRole:roles/storage.objectViewer\", \ \"inRole:roles/storage.objectCreator\", \ \"inRole:roles/storage.objectAdmin\", \ \"inRole:roles/storage.legacyBucketReader\" \ ] \ }] \ } \ }") \ CLUSTER_NAME
コマンドを実行したまま、新しい Cloud Shell タブかターミナル セッションに切り替えます。クライアントがコマンドの実行中に認証情報を更新します。
「
Ctrl-C」と入力してセッションを終了します。- クラスタの詳細を取得します。
gcloud dataproc clusters describe CLUSTER_NAME --region=REGION
Jupyter のウェブ インターフェース URL はクラスタの詳細に掲載されています。
... JupyterLab: https://UUID-dot-us-central1.dataproc.googleusercontent.com/jupyter/lab/ ...
- ローカル ブラウザに URL をコピーして、Jupyter UI を起動します。
- 個人用クラスタ認証が成功したことを確認します。
- Jupyter ターミナルを起動します。
gcloud auth listを実行します。- ユーザー名が唯一のアクティブなアカウントであることを確認します。
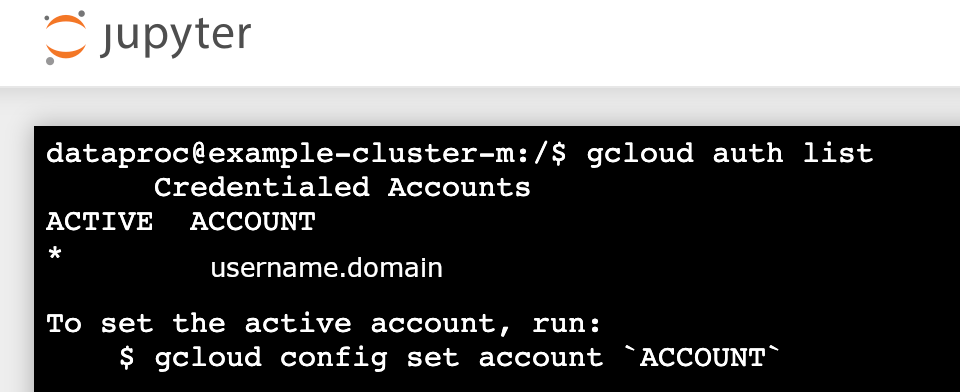
- Jupyter ターミナルで、Jupyter による Kerberos での認証と Spark ジョブの送信を有効化します。
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
klistを実行して、Jupyter が有効な TGT を取得したことを確認します。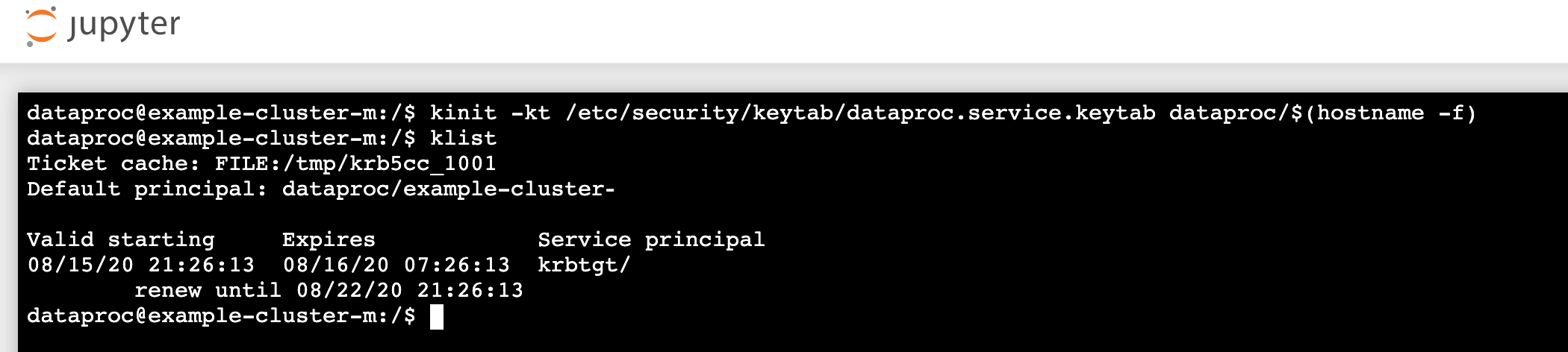
- Jupyter ターミナルで gcloud CLI を使用して、プロジェクトの Cloud Storage バケットに
rose.txtファイルを作成します。echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- ファイルを非公開に指定すると、自分のユーザー アカウントからのみファイルの読み取りやファイルへの書き込みができるようになります。Jupyter は、Cloud Storage とやり取りするときには個人の認証情報を使用します。
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- プライベート アクセスを確認します。
gcloud storage objects describe gs://$BUCKET/rose.txt
acl:
- ファイルを非公開に指定すると、自分のユーザー アカウントからのみファイルの読み取りやファイルへの書き込みができるようになります。Jupyter は、Cloud Storage とやり取りするときには個人の認証情報を使用します。
- email: $USER entity: user-$USER role: OWNER
- コンポーネント ゲートウェイの Jupyter リンクをクリックして Jupyter UI を起動します。
- 個人用クラスタ認証が成功したことを確認します。
- Jupyter ターミナルを起動します。
gcloud auth listを実行します。- ユーザー名が唯一のアクティブなアカウントであることを確認します。
- Jupyter ターミナルで、Jupyter による Kerberos での認証と Spark ジョブの送信を有効化します。
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
klistを実行して、Jupyter が有効な TGT を取得したことを確認します。
- Jupyter ターミナルで gcloud CLI を使用して、プロジェクトの Cloud Storage バケットに
rose.txtファイルを作成します。echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- ファイルを非公開に指定すると、自分のユーザー アカウントからのみファイルの読み取りやファイルへの書き込みができるようになります。Jupyter は、Cloud Storage とやり取りするときには個人の認証情報を使用します。
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- プライベート アクセスを確認します。
gcloud storage objects describe gs://bucket-name/rose.txt
acl:
- ファイルを非公開に指定すると、自分のユーザー アカウントからのみファイルの読み取りやファイルへの書き込みができるようになります。Jupyter は、Cloud Storage とやり取りするときには個人の認証情報を使用します。
- email: $USER entity: user-$USER role: OWNER
- 任意のフォルダに移動して、PySpark ノートブックを作成します。
上記で作成した
rose.txtファイルに対して、基本的な文字数カウント ジョブを実行します。text_file = sc.textFile("gs://bucket-name/rose.txt") counts = text_file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) print(counts.collect())rose.txtファイルを読み取ることができます。また、Cloud Storage バケットの監査ログを調べ、ジョブが ID を使用して Cloud Storage にアクセスしていることも確認できます(Cloud Storage での Cloud Audit Logs をご覧ください)。

- Dataproc クラスタを削除します。
gcloud dataproc clusters delete CLUSTER_NAME --region=REGION
環境を構成する
Cloud Shell またはローカル ターミナルから環境を構成します。