Mantenha tudo organizado com as coleções
Salve e categorize o conteúdo com base nas suas preferências.
Com o conector Hive-BigQuery de código aberto, suas cargas de trabalho do Apache Hive podem ler e gravar dados das tabelas do BigQuery e do BigLake. É possível armazenar dados no armazenamento do BigQuery ou em formatos de dados de código aberto no Cloud Storage.
O conector Hive-BigQuery implementa a
API Hive Storage Handler
para permitir que as cargas de trabalho do Hive se integrem às tabelas do BigQuery e do BigLake. O mecanismo de execução do Hive processa operações de computação, como agregações e junções, e o conector gerencia as interações com dados armazenados no BigQuery ou em buckets do Cloud Storage conectados ao BigLake.
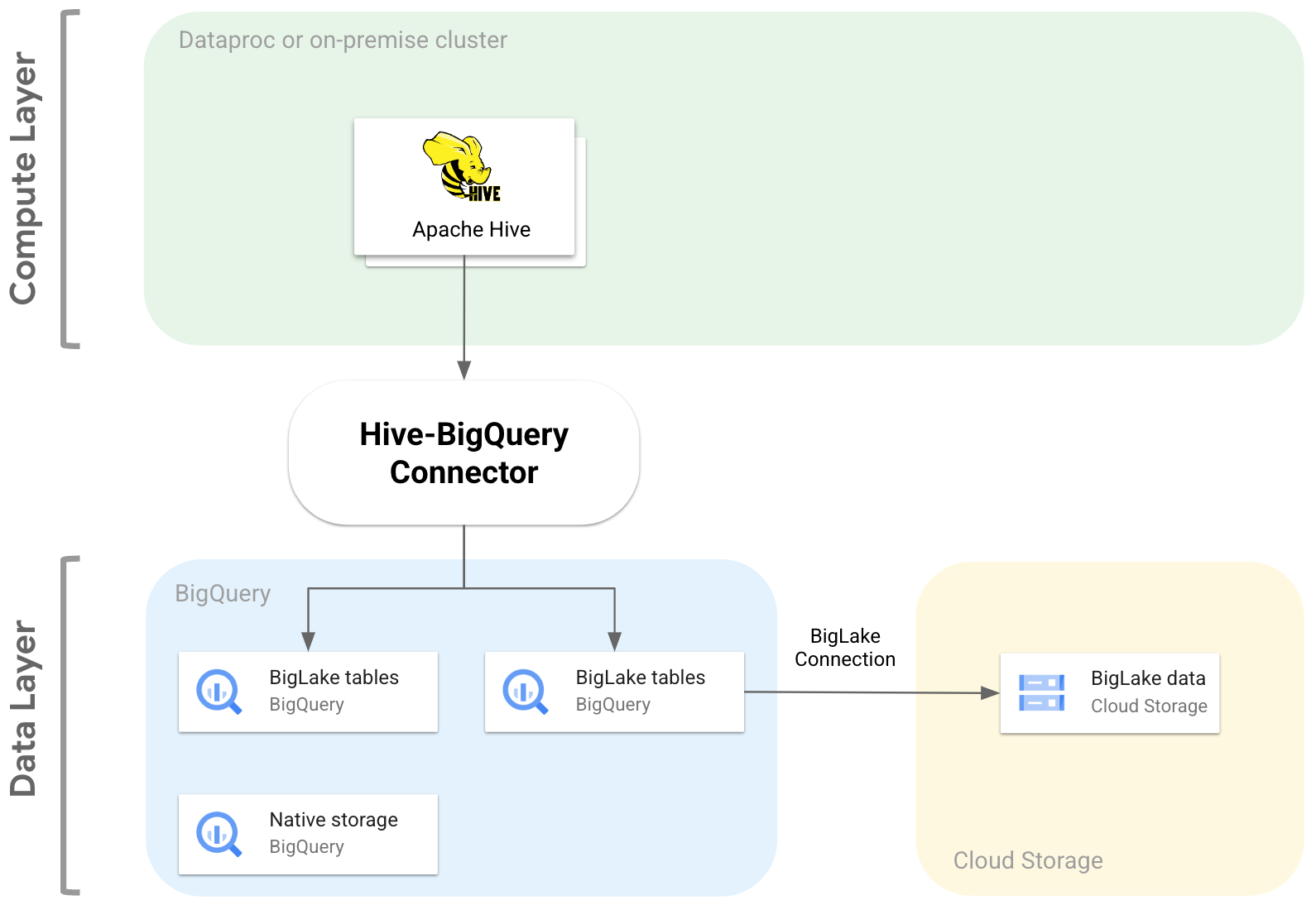
O diagrama a seguir ilustra como o conector Hive-BigQuery
se encaixa entre as camadas de computação e dados.
Casos de uso
Confira algumas maneiras como o conector Hive-BigQuery pode ajudar você em
cenários comuns baseados em dados:
Migração de dados. Você planeja mover seu armazenamento de dados do Hive para o BigQuery e, em seguida, traduzir incrementalmente suas consultas do Hive para o dialeto SQL do BigQuery.
Você espera que a migração leve um tempo significativo devido ao tamanho do data warehouse e ao grande número de aplicativos conectados, e precisa garantir a continuidade durante as operações de migração. Este é o fluxo de trabalho:
Você move seus dados para o BigQuery
Usando o conector, você acessa e executa suas consultas originais do Hive enquanto
traduz gradualmente as consultas do Hive para o dialeto SQL
compatível com ANSI do BigQuery.
Depois de concluir a migração e a tradução, desative o Hive.
Fluxos de trabalho do Hive e do BigQuery. Você planeja usar o Hive para algumas tarefas e o BigQuery para cargas de trabalho que se beneficiam dos recursos dele, como o BigQuery BI Engine ou o BigQuery ML. Você usa o conector para unir tabelas do Hive às tabelas do BigQuery.
Confiança em uma pilha de software de código aberto (OSS). Para evitar o bloqueio de fornecedor, use uma pilha completa de OSS para seu data warehouse. Este é seu plano de dados:
Migre seus dados no formato OSS original, como Avro, Parquet ou ORC, para buckets do Cloud Storage usando uma conexão do BigLake.
Você continua usando o Hive para executar e processar consultas do dialeto SQL do Hive.
Use o conector conforme necessário para se conectar ao BigQuery e aproveitar os seguintes recursos:
Grave dados no BigQuery usando os seguintes
métodos:
Gravações diretas usando a API BigQuery Storage Write no modo pendente. Use
esse método para cargas de trabalho que exigem baixa latência de gravação, como painéis
quase em tempo real com janelas de atualização curtas.
Gravações indiretas ao armazenar arquivos Avro temporários no Cloud Storage e
carregar os arquivos em uma tabela de destino usando a API Load Job.
Esse método é menos caro do que o direto, já que os jobs de carregamento do BigQuery não geram cobranças. Como esse método é mais lento e é mais adequado para cargas de trabalho que não são sensíveis ao tempo
Acesse tabelas do BigQuery particionadas por tempo e em cluster. O exemplo a seguir define a relação entre uma tabela do Hive e uma tabela particionada e agrupada em cluster no BigQuery.
Remova colunas para evitar a recuperação de colunas desnecessárias da camada de dados.
Use pushdowns de predicado para pré-filtrar linhas de dados na camada de armazenamento do BigQuery. Essa técnica pode melhorar significativamente a performance geral da consulta, reduzindo a quantidade de dados que atravessam a rede.
Converter automaticamente tipos de dados do Hive em tipos de dados do BigQuery.
[[["Fácil de entender","easyToUnderstand","thumb-up"],["Meu problema foi resolvido","solvedMyProblem","thumb-up"],["Outro","otherUp","thumb-up"]],[["Difícil de entender","hardToUnderstand","thumb-down"],["Informações incorretas ou exemplo de código","incorrectInformationOrSampleCode","thumb-down"],["Não contém as informações/amostras de que eu preciso","missingTheInformationSamplesINeed","thumb-down"],["Problema na tradução","translationIssue","thumb-down"],["Outro","otherDown","thumb-down"]],["Última atualização 2025-09-02 UTC."],[[["\u003cp\u003eThe Hive-BigQuery connector enables Apache Hive workloads to interact with data in BigQuery and BigLake tables, allowing for data storage in either BigQuery or open-source formats on Cloud Storage.\u003c/p\u003e\n"],["\u003cp\u003eThis connector is beneficial for migrating from Hive to BigQuery, utilizing both Hive and BigQuery in tandem, or maintaining an entirely open-source data warehouse stack.\u003c/p\u003e\n"],["\u003cp\u003eUsing the Hive Storage Handler API, the connector manages data interactions, while Hive handles compute operations, like aggregates and joins, offering integration between the two platforms.\u003c/p\u003e\n"],["\u003cp\u003eThe connector supports direct writes to BigQuery for low-latency needs or indirect writes via temporary Avro files for cost-effective, non-time-critical operations.\u003c/p\u003e\n"],["\u003cp\u003eFeatures of the Hive-BigQuery connector include running queries with MapReduce and Tez engines, creating/deleting BigQuery tables from Hive, joining BigQuery and Hive tables, fast reads using the Storage Read API, column pruning, and predicate pushdowns for performance optimization.\u003c/p\u003e\n"]]],[],null,["The open source\n[Hive-BigQuery connector](https://github.com/GoogleCloudDataproc/hive-bigquery-connector)\nlets your [Apache Hive](https://hive.apache.org/)\nworkloads read and write data from and to [BigQuery](/bigquery) and\n[BigLake](/biglake) tables. You can store data in\nBigQuery storage or in open source data formats on\nCloud Storage.\n| Use the connector to work with Hive and BigQuery together or to migrate your data warehouse from Hive to BigQuery.\n\nThe Hive-BigQuery connector implements the\n[Hive Storage Handler API](https://cwiki.apache.org/confluence/display/Hive/StorageHandlers)\nto allow Hive workloads to integrate with BigQuery and BigLake\ntables. The Hive execution engine handles compute operations, such\nas aggregates and joins, and the connector manages interactions with\ndata stored in BigQuery or in BigLake-connected\nCloud Storage buckets.\n\nThe following diagram illustrates how Hive-BigQuery connector\nfits between the compute and data layers.\n\nUse cases\n\nHere are some of the ways the Hive-BigQuery connector can help you in\ncommon data-driven scenarios:\n\n- Data migration. You plan to move your Hive data warehouse to BigQuery,\n then incrementally translate your Hive queries into BigQuery SQL dialect.\n You expect the migration to take a significant amount of time due to the size\n of your data warehouse and the large number of connected applications, and\n you need to ensure continuity during the migration operations. Here's the\n workflow:\n\n 1. You move your data to BigQuery\n 2. Using the connector, you access and run your original Hive queries while you gradually translate the Hive queries to BigQuery ANSI-compliant SQL dialect.\n 3. After completing the migration and translation, you retire Hive.\n- Hive and BigQuery workflows. You plan to use\n Hive for some tasks, and BigQuery for workloads that benefit\n from its features, such as [BigQuery BI Engine](/bigquery/docs/bi-engine-intro) or\n [BigQuery ML](/bigquery/docs/bqml-introduction). You use\n the connector to join Hive tables to your BigQuery tables.\n\n- Reliance on an open source software (OSS) stack. To avoid vendor lock-in,\n you use a full OSS stack for your data warehouse. Here's your data plan:\n\n 1. You migrate your data in its original OSS format, such as Avro, Parquet, or\n ORC, to Cloud Storage buckets using a BigLake connection.\n\n 2. You continue to use Hive to execute and process your Hive SQL dialect queries.\n\n 3. You use the connector as needed to connect to BigQuery\n to benefit from the following features:\n\n - [Metadata caching](/bigquery/docs/biglake-intro#metadata_caching_for_performance) for query performance\n - [Data loss prevention](/bigquery/docs/scan-with-dlp)\n - [Column-level access control](/bigquery/docs/column-level-security-intro)\n - [Dynamic data masking](/bigquery/docs/column-data-masking-intro) for security and governance at scale.\n\nFeatures\n\nYou can use the Hive-BigQuery connector to work with your\nBigQuery data and accomplish the following tasks:\n\n- Run queries with MapReduce and Tez execution engines.\n- Create and delete BigQuery tables from Hive.\n- Join BigQuery and BigLake tables with Hive tables.\n- Perform fast reads from BigQuery tables using the [Storage Read API](/bigquery/docs/reference/storage) streams and the [Apache Arrow](https://arrow.apache.org/) format\n- Write data to BigQuery using the following methods:\n - Direct writes using the BigQuery [Storage Write API in pending mode](/bigquery/docs/write-api-batch). Use this method for workloads that require low write latency, such as near-real-time dashboards with short refresh time windows.\n - Indirect writes by staging temporary Avro files to Cloud Storage, and then loading the files into a destination table using the [Load Job API](/bigquery/docs/batch-loading-data). This method is less expensive than the direct method, since BigQuery load jobs don't accrue charges. Since this method is slower, and finds its best use in workloads that aren't time critical\n- Access BigQuery [time-partitioned](/bigquery/docs/partitioned-tables)\n and [clustered](/bigquery/docs/clustered-tables) tables. The following example\n defines the relation between a Hive table and a table\n that is partitioned and clustered in BigQuery.\n\n ```sql\n CREATE TABLE my_hive_table (int_val BIGINT, text STRING, ts TIMESTAMP)\n STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler'\n TBLPROPERTIES (\n 'bq.table'='myproject.mydataset.mytable',\n 'bq.time.partition.field'='ts',\n 'bq.time.partition.type'='MONTH',\n 'bq.clustered.fields'='int_val,text'\n );\n ```\n- Prune columns to avoid retrieving unnecessary columns from the data layer.\n\n- Use predicate pushdowns to pre-filter data rows at the BigQuery storage\n layer. This technique can significantly improve overall query performance by\n reducing the amount of data traversing the network.\n\n- Automatically convert Hive data types to BigQuery data types.\n\n- Read BigQuery [views](/bigquery/docs/views-intro) and\n [table snapshots](/bigquery/docs/table-snapshots-intro).\n\n- Integrate with Spark SQL.\n\n- Integrate with Apache Pig and HCatalog.\n\nGet started\n\nSee the instructions to\n[install and configure the Hive-BigQuery connector on a Hive cluster](https://github.com/GoogleCloudDataproc/hive-bigquery-connector/blob/main/README.md)."]]