オープンソースの Hive-BigQuery コネクタを使用すると、Apache Hive ワークロードにより BigQuery および BigLake テーブルとの間でデータの読み取りと書き込みを行うことができます。データは、BigQuery ストレージまたは Cloud Storage のオープンソース データ形式で保存できます。
Hive-BigQuery コネクタは Hive Storage Handler API を実装し、Hive ワークロードを BigQuery テーブルや BigLake テーブルと統合できるようにします。Hive 実行エンジンは、集約や結合などのコンピューティング オペレーションを処理し、コネクタは BigQuery または BigLake 接続の Cloud Storage バケットに保存されているデータとのインタラクションを管理します。
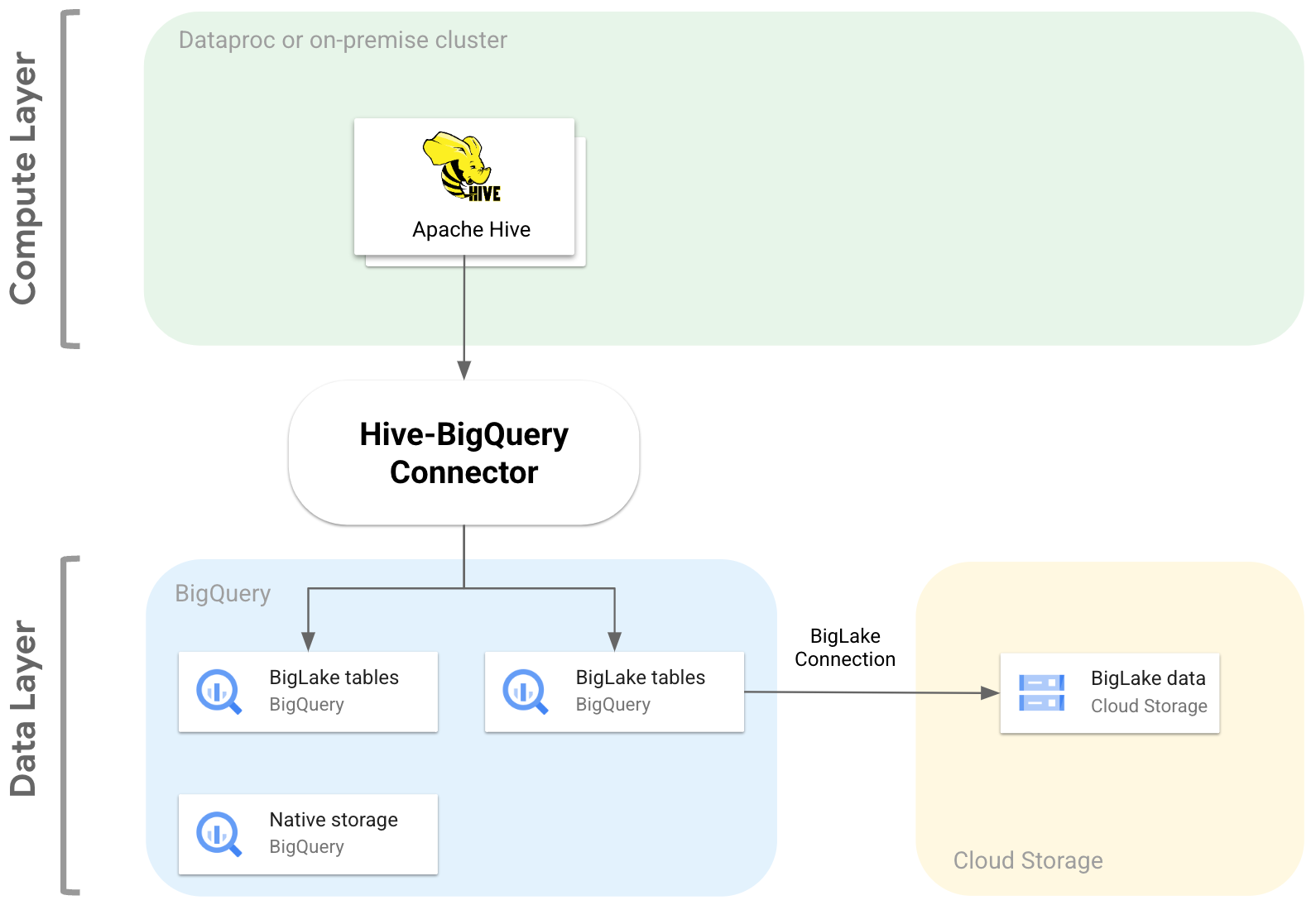
次の図は、Hive-BigQuery コネクタがコンピューティング レイヤとデータレイヤの間にどのように適合するかを示しています。
ユースケース
Hive-BigQuery コネクタは、一般的なデータドリブン シナリオで次のような役割を果たします。
データの移行。Hive データ ウェアハウスを BigQuery に移行し、Hive クエリを BigQuery SQL 言語に段階的に変換することを計画しているとします。この場合、データ ウェアハウスの規模が大きく、接続されているアプリケーションの数が多いため、移行にはかなりの時間がかかることが予想されます。また、移行オペレーション中も継続性を確保する必要があります。ワークフローは次のとおりです。
- データを BigQuery に移動する
- コネクタを使用すると、元の Hive クエリにアクセスして実行しながら、Hive クエリを BigQuery ANSI 準拠 SQL 言語に段階的に変換できます。
- 移行と変換が完了したら、Hive を廃止します。
Hive と BigQuery のワークフロー。一部のタスクには Hive を使用し、BigQuery BI Engine や BigQuery ML などの機能を利用するワークロードには BigQuery を使用することを計画しているとします。コネクタを使用して、Hive テーブルを BigQuery テーブルに結合します。
オープンソース ソフトウェア(OSS)スタックの信頼性。ベンダー ロックインを回避するために、データ ウェアハウスに完全な OSS スタックを使用します。データプランは以下のとおりです。
この場合、データは、元の OSS 形式(Avro、Parquet、ORC など)で BigLake 接続を使用して Cloud Storage バケットに移行します。
引き続き Hive を使用して、Hive SQL 言語のクエリを実行し、処理します。
コネクタは、必要に応じて BigQuery に接続して、次の機能を利用するために使用します。
- クエリ パフォーマンスのためのメタデータ キャッシュ
- データ損失防止
- 列レベルのアクセス制御
- 大規模なセキュリティとガバナンスのための動的データ マスキング。
機能
Hive-BigQuery コネクタを使用すると、BigQuery データを操作して次のタスクを実行できます。
- MapReduce および Tez 実行エンジンを使用してクエリを実行する。
- Hive から BigQuery テーブルを作成および削除する。
- BigQuery テーブル / BigLake テーブルと Hive テーブルを結合する。
- Storage Read API ストリームおよび Apache Arrow 形式を使用して BigQuery テーブルからの高速読み取りを実行する。
- 次の方法で BigQuery にデータを書き込みます。
- BigQuery Storage Write API を保留モードで使用した直接書き込み。この方法は、更新間隔が短いニア リアルタイムのダッシュボードなど、低い書き込みレイテンシを必要とするワークロードに使用します。
- 一時的な Avro ファイルを Cloud Storage にステージングしてから、Load Job API を使用して宛先テーブルにファイルを読み込んだ間接的書き込み。BigQuery の読み込みジョブは課金されないため、この方法は直接書き込みよりも費用がかかりません。この方法は処理速度が遅く、時間を重視しないワークロードに最適です。
BigQuery の時間パーティション分割テーブルおよびクラスタ化テーブルへのアクセス。次の例は、Hive テーブルと BigQuery でパーティション分割およびクラスタ化されたテーブルとの関係を定義しています。
CREATE TABLE my_hive_table (int_val BIGINT, text STRING, ts TIMESTAMP) STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler' TBLPROPERTIES ( 'bq.table'='myproject.mydataset.mytable', 'bq.time.partition.field'='ts', 'bq.time.partition.type'='MONTH', 'bq.clustered.fields'='int_val,text' );
列をプルーニングして、データレイヤから不要な列を取得しないようにします。
BigQuery ストレージ レイヤでデータ行を事前にフィルタするための述語プッシュダウンの使用。この手法により、ネットワークを通過するデータ量を削減できるため、クエリの全体的なパフォーマンスが大幅に向上します。
Hive データ型を BigQuery データ型に自動的に変換します。
BigQuery のビューとテーブル スナップショットを読み取ります。
Spark SQL と統合します。
Apache Pig と HCatalog と統合します。
使ってみる
Hive クラスタに Hive-BigQuery コネクタをインストールして構成する手順をご覧ください。