Dataproc Ranger Cloud Storage 插件(适用于 Dataproc 映像版本 1.5 和 2.0)会在每个 Dataproc 集群虚拟机上启用授权服务。授权服务会根据 Ranger 政策评估来自 Cloud Storage 连接器的请求,如果请求获准,则会返回集群虚拟机服务账号的访问令牌。
Ranger Cloud Storage 插件依赖于 Kerberos 进行身份验证,并与 Cloud Storage 连接器集成以支持委托令牌。委托令牌存储在集群主节点上的 MySQL 数据库中。数据库的 root 密码在创建 Dataproc 集群时通过集群属性指定。
准备工作
为项目中的 Dataproc 虚拟机服务账号授予 Service Account Token Creator 角色和 IAM Role Admin 角色。
安装 Ranger Cloud Storage 插件
在本地终端窗口或 Cloud Shell 中运行以下命令,以在创建 Dataproc 集群时安装 Ranger Cloud Storage 插件。
设置环境变量
export CLUSTER_NAME=new-cluster-name \ export REGION=region \ export KERBEROS_KMS_KEY_URI=Kerberos-KMS-key-URI \ export KERBEROS_PASSWORD_URI=Kerberos-password-URI \ export RANGER_ADMIN_PASSWORD_KMS_KEY_URI=Ranger-admin-password-KMS-key-URI \ export RANGER_ADMIN_PASSWORD_GCS_URI=Ranger-admin-password-GCS-URI \ export RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI=MySQL-root-password-KMS-key-URI \ export RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI=MySQL-root-password-GCS-URI
注意:
- CLUSTER_NAME:新集群的名称。
- REGION:要在其中创建集群的区域,例如
us-west1。 - KERBEROS_KMS_KEY_URI 和 KERBEROS_PASSWORD_URI:请参阅设置 Kerberos root 主账号密码。
- RANGER_ADMIN_PASSWORD_KMS_KEY_URI 和 RANGER_ADMIN_PASSWORD_GCS_URI:请参阅设置 Ranger 管理员密码。
- RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI 和 RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI:按照您设置 Ranger 管理员密码时所使用的过程设置 MySQL 密码。
创建 Dataproc 集群
运行以下命令以创建 Dataproc 集群,并在该集群上安装 Ranger Cloud Storage 插件。
gcloud dataproc clusters create ${CLUSTER_NAME} \
--region=${REGION} \
--scopes cloud-platform \
--enable-component-gateway \
--optional-components=SOLR,RANGER \
--kerberos-kms-key=${KERBEROS_KMS_KEY_URI} \
--kerberos-root-principal-password-uri=${KERBEROS_PASSWORD_URI} \
--properties="dataproc:ranger.gcs.plugin.enable=true, \
dataproc:ranger.kms.key.uri=${RANGER_ADMIN_PASSWORD_KMS_KEY_URI}, \
dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PASSWORD_GCS_URI}, \
dataproc:ranger.gcs.plugin.mysql.kms.key.uri=${RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI}, \
dataproc:ranger.gcs.plugin.mysql.password.uri=${RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI}"
注意:
- 1.5 映像版本:如果您要创建 1.5 映像版本的集群(请参阅选择版本),请添加
--metadata=GCS_CONNECTOR_VERSION="2.2.6" or higher标志以安装所需的连接器版本。
验证 Ranger Cloud Storage 插件安装
集群创建完成后,Ranger 管理员网页界面中会显示一个名为 gcs-dataproc 的 GCS 服务类型。
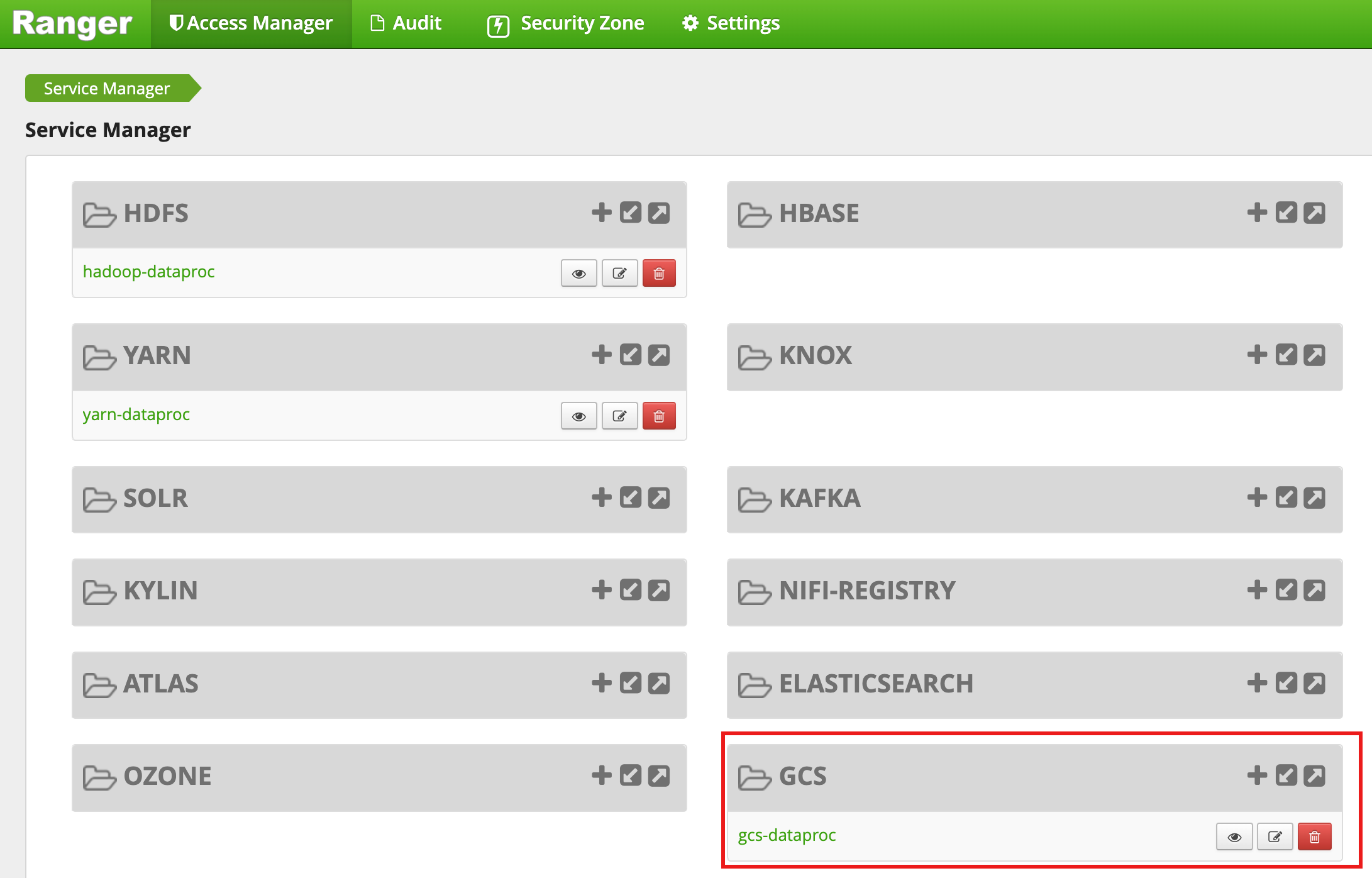
Ranger Cloud Storage 插件默认政策
默认 gcs-dataproc 服务具有以下政策:
用于从 Dataproc 集群暂存和临时存储桶读取数据以及向其中写入数据的政策
all - bucket, object-path政策,允许所有用户访问所有对象的元数据。此访问权限是必需的,以允许 Cloud Storage 连接器执行 HCFS(Hadoop 兼容文件系统)操作。
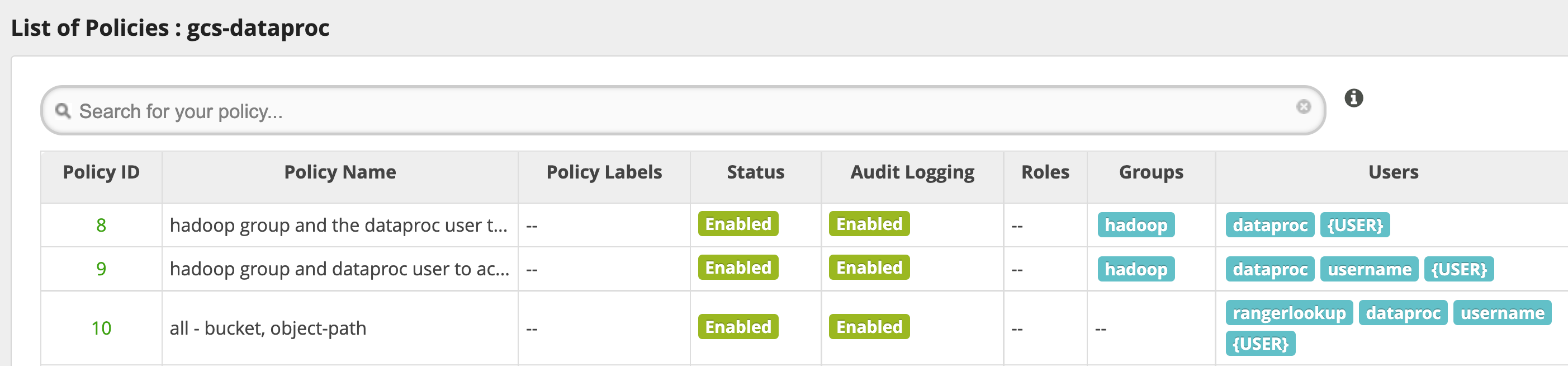
使用提示
应用对存储桶文件夹的访问权限
为了适应在 Cloud Storage 存储桶中创建中间文件的应用,您可以授予对 Cloud Storage 存储桶路径的 Modify Objects、List Objects 和 Delete Objects 权限,然后选择 recursive 模式,以将权限扩展到指定路径的子路径。
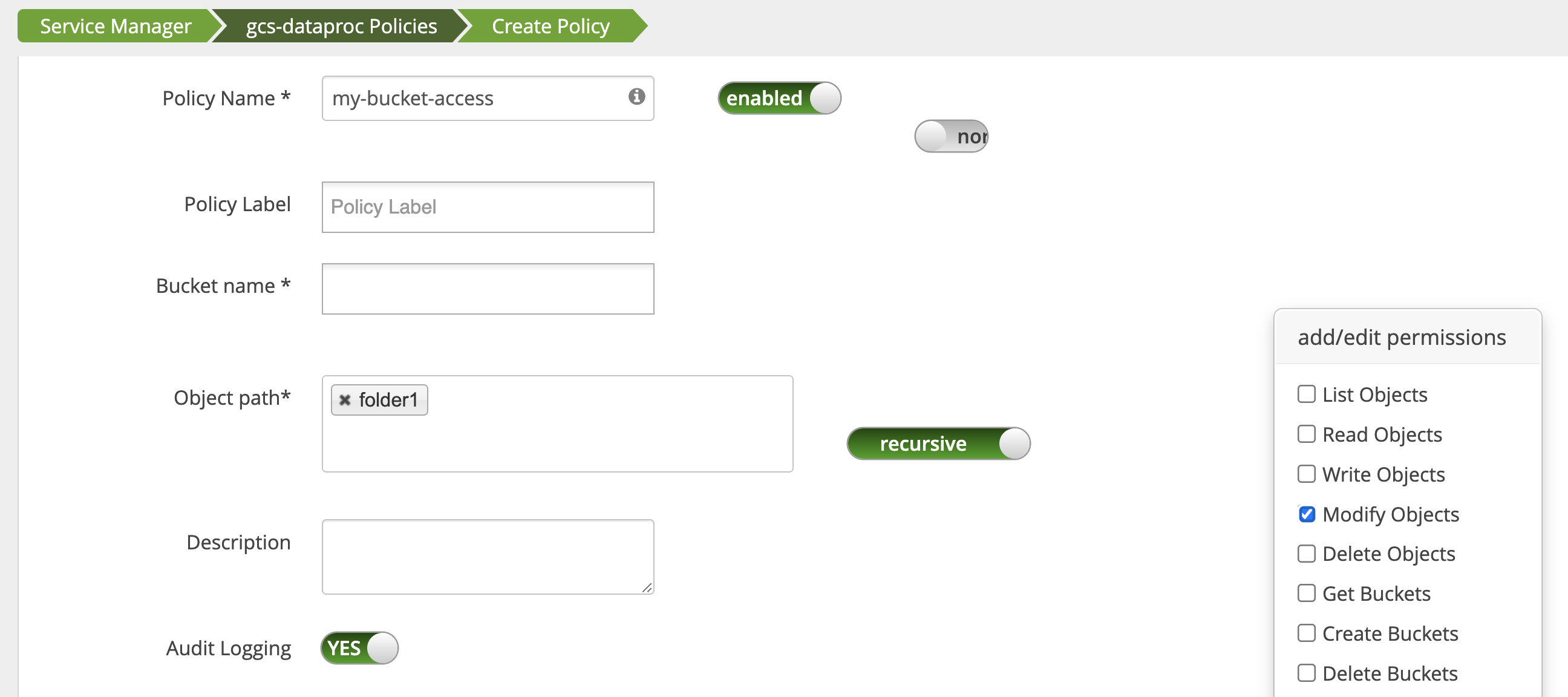
保护措施
为防止插件被规避,请执行以下操作:
为虚拟机服务账号授予对 Cloud Storage 存储桶中资源的访问权限,以便其能够使用范围缩小的访问令牌授予对这些资源的访问权限(请参阅 Cloud Storage 的 IAM 权限)。此外,请移除用户对存储桶资源的访问权限,以避免用户直接访问存储桶。
在集群虚拟机上停用
sudo和其他 root 访问权限方式,包括更新sudoer文件,以防止模拟或更改身份验证和授权设置。如需了解详情,请参阅有关添加/移除sudo用户权限的 Linux 说明。使用
iptable阻止集群虚拟机直接访问 Cloud Storage 的请求。例如,您可以阻止访问虚拟机元数据服务器,以防止访问用于对 Cloud Storage 的访问权限进行身份验证和授权的虚拟机服务账号凭据或访问令牌(请参阅block_vm_metadata_server.sh,这是一个使用iptable规则阻止访问虚拟机元数据服务器的初始化脚本)。
Spark、Hive-on-MapReduce 和 Hive-on-Tez 作业
为了保护敏感的用户身份验证详细信息并减轻密钥分发中心 (KDC) 的负载,Spark 驱动程序不会向执行器分发 Kerberos 凭据。但是,Spark 驱动程序会从 Ranger Cloud Storage 插件获取委托令牌,然后将委托令牌分发给执行器。执行器使用委托令牌对 Ranger Cloud Storage 插件进行身份验证,并将其换成可访问 Cloud Storage 的 Google 访问令牌。
Hive-on-MapReduce 和 Hive-on-Tez 作业也使用令牌来访问 Cloud Storage。在提交以下作业类型时,使用以下属性获取令牌以访问指定的 Cloud Storage 存储桶:
Spark 作业:
--conf spark.yarn.access.hadoopFileSystems=gs://bucket-name,gs://bucket-name,...
Hive-on-MapReduce 作业:
--hiveconf "mapreduce.job.hdfs-servers=gs://bucket-name,gs://bucket-name,..."
Hive-on-Tez 作业:
--hiveconf "tez.job.fs-servers=gs://bucket-name,gs://bucket-name,..."
Spark 作业场景
在安装了 Ranger Cloud Storage 插件的 Dataproc 集群虚拟机上的终端窗口中运行 Spark wordcount 作业时,该作业会失败。
spark-submit \
--conf spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET} \
--class org.apache.spark.examples.JavaWordCount \
/usr/lib/spark/examples/jars/spark-examples.jar \
gs://bucket-name/wordcount.txt
注意:
- FILE_BUCKET:用于访问 Spark 的 Cloud Storage 存储桶。
错误输出:
Caused by: com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: '<USER>', Bucket: '<dataproc_temp_bucket>', Object Path: 'a97127cf-f543-40c3-9851-32f172acc53b/spark-job-history/', Action: 'LIST_OBJECTS'
注意:
- 在启用了 Kerberos 的环境中,
spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET}是必需的。
错误输出:
Caused by: java.lang.RuntimeException: Failed creating a SPNEGO token. Make sure that you have run `kinit` and that your Kerberos configuration is correct. See the full Kerberos error message: No valid credentials provided (Mechanism level: No valid credentials provided)
使用 Ranger 管理员网页界面中的访问管理器修改政策,以将 username 添加到拥有 List Objects 和其他 temp 存储桶权限的用户列表中。
运行作业会生成新错误。
错误输出:
com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: <USER>, Bucket: '<file-bucket>', Object Path: 'wordcount.txt', Action: 'READ_OBJECTS'
添加了一条政策,以向用户授予对 wordcount.text Cloud Storage 路径的读取权限。
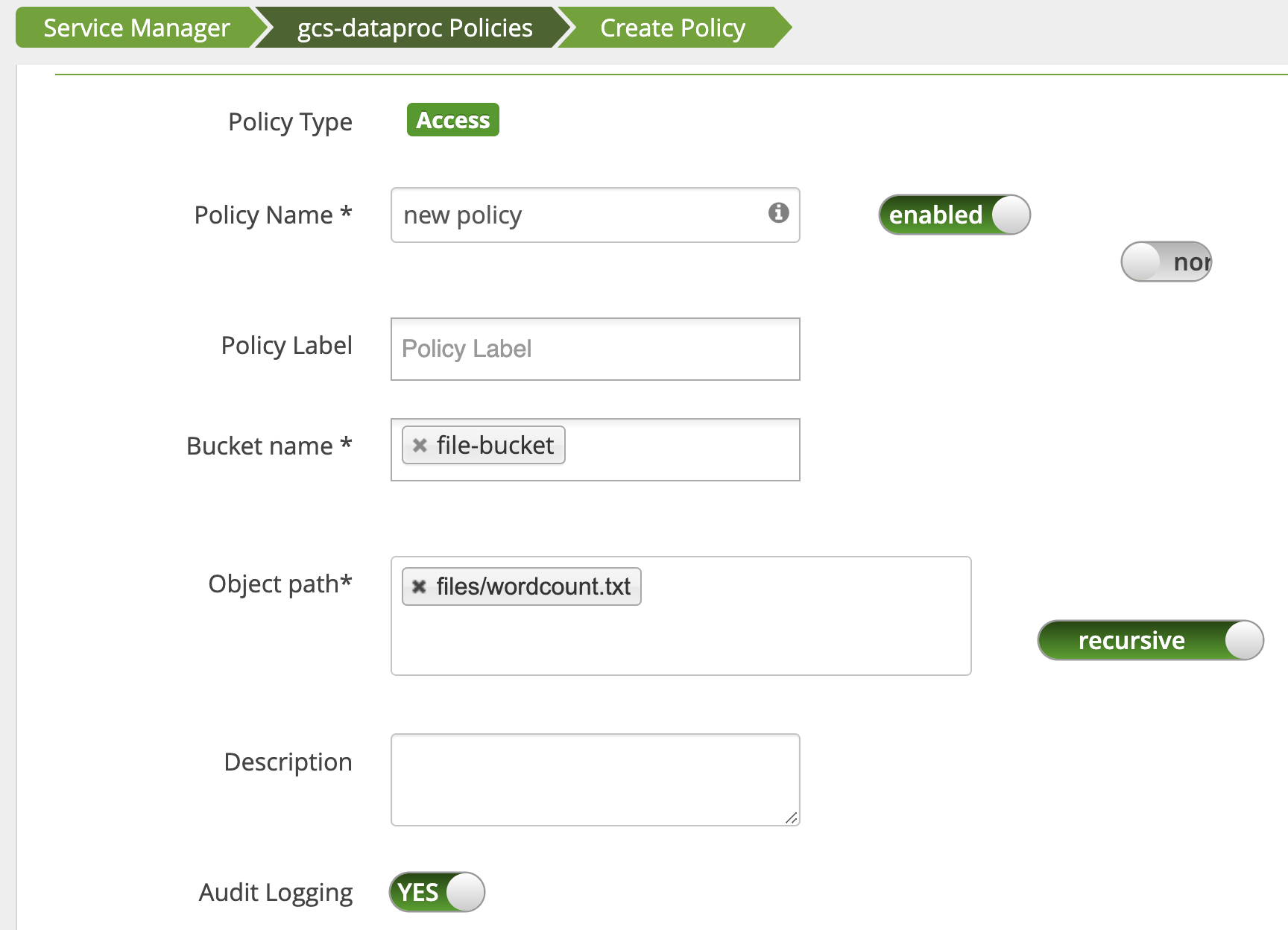
作业运行并成功完成。
INFO com.google.cloud.hadoop.fs.gcs.auth.GcsDelegationTokens: Using delegation token RangerGCSAuthorizationServerSessionToken owner=<USER>, renewer=yarn, realUser=, issueDate=1654116824281, maxDate=0, sequenceNumber=0, masterKeyId=0 this: 1 is: 1 a: 1 text: 1 file: 1 22/06/01 20:54:13 INFO org.sparkproject.jetty.server.AbstractConnector: Stopped