Los clústeres de Dataproc se compilan en instancias de Compute Engine. Los recursos de hardware virtualizados disponibles para una instancia dependen de los tipos de máquinas. Compute Engine ofrece tipos predefinidos de máquinas y tipos personalizados de máquinas. Los clústeres de Dataproc pueden usar tipos predefinidos y personalizados para los nodos principales o trabajadores.
Los clústeres de Dataproc admiten los siguientes tipos de máquinas predefinidos de Compute Engine (la disponibilidad de tipo de máquina varía según la región):
- Tipos de máquinas de uso general, que incluyen los tipos de máquinas N1, N2, N2D, E2, C3, C4 y N4 (Dataproc también es compatible con los tipos de máquinas personalizados N1, N2, N2D, E2, C3, C4 y N4).
Limitaciones:
- El tipo de máquina n1-standard-1 no es compatible con imágenes 2.0 o posteriores (el tipo de máquina n1-standard-1 no se recomienda para imágenes anteriores a la versión 2.0; en su lugar, usa un tipo de máquina con más memoria).
- Los tipos de máquinas de núcleo compartido no son compatibles, que incluyen los siguientes tipos de máquinas no compatibles:
- E2: Tipos de máquinas de núcleo compartido, e2-micro, e2-small y
- N1: Tipos de máquinas de núcleo compartido f1-micro y g1-small
- Dataproc selecciona
hyperdisk-balancedcomo el tipo de disco de arranque si el tipo de máquina es C3, C4 o N4.
- Tipos de máquinas optimizados para procesamiento, que incluyen tipos de máquinas C2 y C2D.
- Tipos de máquina con optimización de memoria, que incluyen tipos de máquinas M1 y M2.
- Tipos de máquinas ARM, que incluyen tipos de máquinas C4A.
Tipos personalizados de máquinas
Dataproc admite tipos personalizados de máquinas de la serie N1.
Los tipos personalizados de máquinas son ideales para las siguientes cargas de trabajo:
- Las cargas de trabajo que no son adecuadas para los tipos predefinidos de máquina
- Las cargas de trabajo que requieren mayor memoria o poder de procesamiento, pero no todas las actualizaciones que proporciona el próximo nivel de tipo de máquina
Por ejemplo, si tienes una carga de trabajo que necesita más potencia de procesamiento que la que proporciona una instancia de n1-standard-4, pero en el siguiente paso, una instancia de n1-standard-8, proporciona demasiada capacidad. Con los tipos personalizados de máquinas, puedes crear clústeres de Dataproc con nodos principales o trabajadores en el rango medio, con 6 CPU virtuales y 25 GB de memoria.
Especifica un tipo de máquina personalizado
Los tipos personalizados de máquinas usan una especificación machine type especial y están sujetos a limitaciones. A modo de ejemplo, la especificación del tipo personalizado de máquina para una VM personalizada con 6 CPU virtuales y 22.5 GB de memoria es custom-6-23040:
Los números en la especificación de tipo de máquina corresponden al número de CPU virtuales (vCPU) en la máquina (6) y la cantidad de memoria (23040). Se calcula la cantidad de memoria multiplicando la cantidad de memoria en gigabytes por 1024 (consulta Expresa la memoria en GB o MB). En este ejemplo, 22.5 (GB) se multiplica por 1024: 22.5 * 1024 = 23040.
Usa la sintaxis anterior para especificar el tipo personalizado de máquina con tus clústeres. Puedes establecer el tipo de máquina para nodos principales o trabajadores, o para ambos, cuando creas un clúster. Si estableces los dos, el nodo principal puede usar un tipo personalizado de máquina diferente al del tipo que usan los trabajadores. El tipo de máquina que usan los trabajadores secundarios sigue la configuración de los trabajadores principales y no se puede establecer por separado (consulta Trabajadores secundarios: VM interrumpibles y no interrumpibles).
Precios de los tipos personalizados de máquinas
Los precios de los tipos personalizados de máquinas se basan en los recursos usados en una máquina personalizada. El precio de Dataproc se agrega al costo de los recursos de procesamiento y se basa en la cantidad total de CPU virtuales usadas en un clúster.
Crea un clúster de Dataproc con un tipo de máquina especificado
Console
En el panel Configure nodes de la página Create a cluster de Dataproc en la consola de Google Cloud, selecciona las familias de máquinas, series y tipos para los nodos principales y trabajadores del clúster.
Comando de gcloud
Ejecuta el comando gcloud dataproc clusters create con las siguientes marcas para crear un clúster de Dataproc con tipos de máquinas principales o trabajadoras:
- La marca
--master-machine-type machine-typete permite configurar el tipo predefinido o personalizado de máquina que usa la instancia de VM principal en tu clúster (o instancias principales si creas un Clúster de HA ). - La marca
--worker-machine-type custom-machine-typete permite establecer el tipo predefinido o personalizado de máquina que usan las instancias de VM de trabajador en tu clúster.
Ejemplo:
gcloud dataproc clusters create test-cluster / --master-machine-type custom-6-23040 / --worker-machine-type custom-6-23040 / other args
... properties: distcp:mapreduce.map.java.opts: -Xmx1638m distcp:mapreduce.map.memory.mb: '2048' distcp:mapreduce.reduce.java.opts: -Xmx4915m distcp:mapreduce.reduce.memory.mb: '6144' mapred:mapreduce.map.cpu.vcores: '1' mapred:mapreduce.map.java.opts: -Xmx1638m ...
API de REST
Para crear un clúster con tipos de máquina personalizados, establece machineTypeUri en InstanceGroupConfig masterConfig y/o workerConfig en la solicitud a la API cluster.create.
Ejemplo:
POST /v1/projects/my-project-id/regions/is-central1/clusters/
{
"projectId": "my-project-id",
"clusterName": "test-cluster",
"config": {
"configBucket": "",
"gceClusterConfig": {
"subnetworkUri": "default",
"zoneUri": "us-central1-a"
},
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "n1-highmem-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "n1-highmem-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
}
}
}
Crea un clúster de Dataproc con un tipo de máquina personalizado con memoria extendida
Dataproc admite tipos personalizados de máquinas con memoria extendida más allá del límite de 6.5 GB por CPU virtual (consulta Precios de memoria extendida).
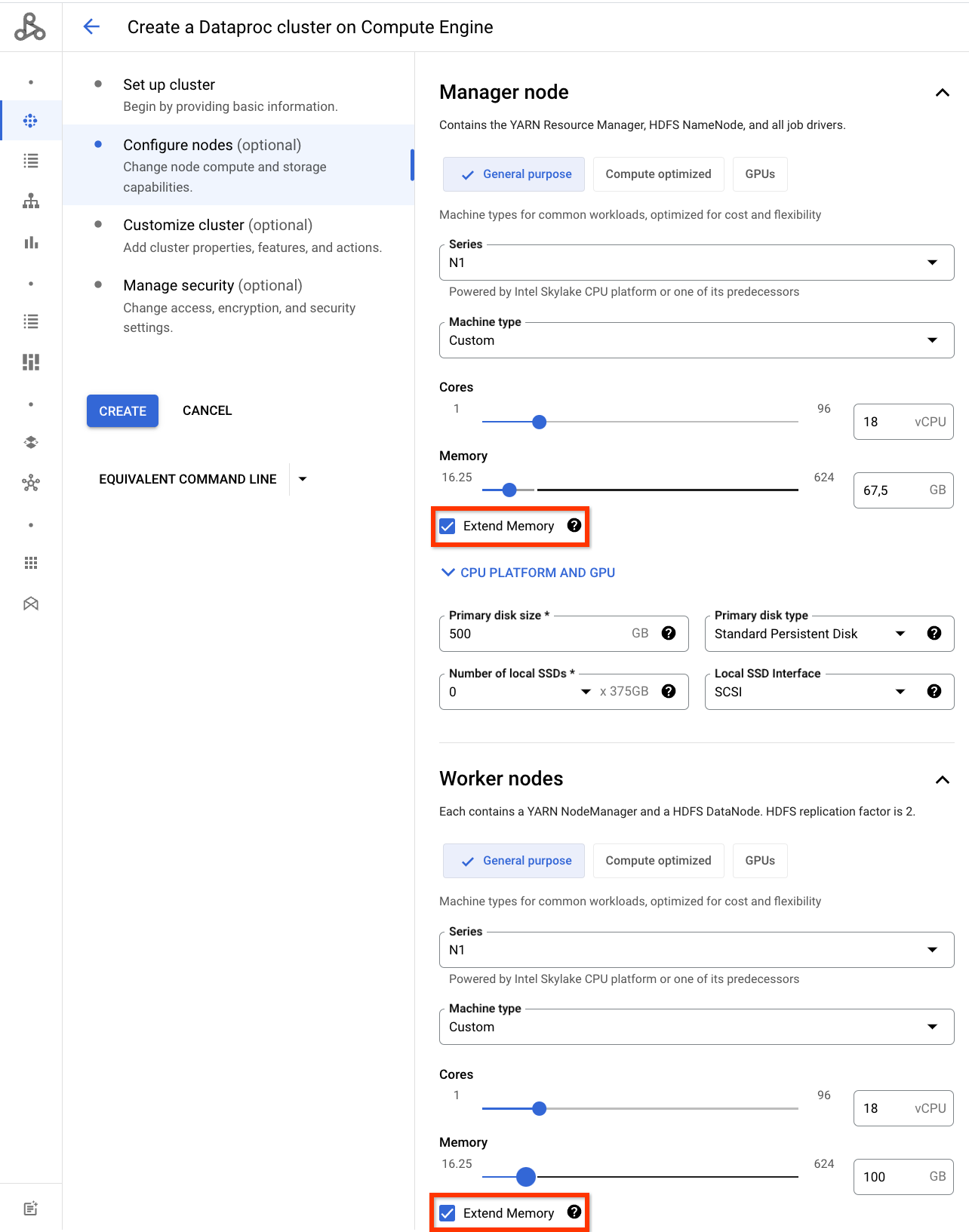
Console
Haz clic en Extender memoria cuando personalices la memoria en Machine type (Tipo de máquina) en la sección Master node (Nodo principal) o Worker nodes (Nodos trabajadores) del panel Configure nodes en la página Create a cluster de Dataproc en la consola de Google Cloud.
Comando de gcloud
Para crear un clúster desde la línea de comandos de gcloud con CPU personalizadas con memoria extendida, agrega un sufijo -ext a las marcas ‑‑master-machine-type o ‑‑worker-machine-type.
Ejemplo
La siguiente línea de comandos de gcloud de muestra crea un clúster de Dataproc con 1 CPU con 50 GB de memoria (50 * 1,024 = 51,200) en cada nodo:
gcloud dataproc clusters create test-cluster / --master-machine-type custom-1-51200-ext / --worker-machine-type custom-1-51200-ext / other args
API
El siguiente fragmento JSON de muestra <code.instancegroupconfig< code="" dir="ltr" translate="no"></code.instancegroupconfig<> de una solicitud a la API de REST de Dataproc clusters.create especifica 1 CPU y 50 GB de memoria (50 * 1,024 = 51,200) en cada nodo:
...
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "custom-1-51200-ext",
...
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "custom-1-51200-ext",
...
...
Tipos de máquinas ARM
Dataproc admite la creación de un clúster con nodos que usan tipos de máquinas ARM, como el tipo de máquina C4A.
Requisitos y limitaciones:
- La imagen de Dataproc debe ser compatible con el chipset ARM (actualmente, solo la imagen de Dataproc 2.1-ubuntu20-arm es compatible con el CHIPSET ARM). Ten en cuenta que esta imagen no admite muchos componentes opcionales ni de acción de inicialización (consulta las versiones de lanzamiento 2.1.x).
- Dado que se debe especificar una imagen para un clúster, los nodos principal, trabajador y secundario deben usar un tipo de máquina ARM que sea compatible con la imagen de ARM de Dataproc seleccionada.
- Las funciones de Dataproc que no son compatibles con los tipos de máquinas ARM no están disponibles (por ejemplo, los tipos de máquinas C4A no admiten SSD locales).
Crea un clúster de Dataproc con un tipo de máquina ARM
Console
Actualmente, la consola de Google Cloud no admite la creación de un clúster de tipo de máquina ARM de Dataproc.
gcloud
Para crear un clúster de Dataproc que use el tipo de máquina c4a-standard-4 de ARM, ejecuta el siguiente comando gcloud de forma local en una ventana de terminal o en Cloud Shell.
gcloud dataproc clusters create cluster-name \ --region=REGION \ --image-version=2.1-ubuntu20-arm \ --master-machine-type=c4a-standard-4 \ --worker-machine-type=c4a-standard-4
Notas:
REGION: Es la región en la que se ubicará el clúster.
Las imágenes ARM están disponibles a partir de
2.1.18-ubuntu20-arm.Consulta la documentación de referencia de gcloud dataproc clusters create para obtener información sobre las marcas de línea de comandos adicionales que puedes usar para personalizar tu clúster.
*-arm imagessolo admite los componentes instalados y los siguientes componentes opcionales que se enumeran en la página Versiones de actualización 2.1.x (no se admiten los componentes opcionales 2.1 restantes ni todas las acciones de inicialización que se enumeran en esa página):- Apache Hive WebHCat
- Docker
- Zookeeper (instalado en clústeres de alta disponibilidad; componente opcional en clústeres sin alta disponibilidad)
API
La siguiente solicitud de muestra clusters.create de la API de REST de Dataproc crea un clúster de tipo de máquina ARM.
POST /v1/projects/my-project-id/regions/is-central1/clusters/
{
"projectId": "my-project-id",
"clusterName": "sample-cluster",
"config": {
"configBucket": "",
"gceClusterConfig": {
"subnetworkUri": "default",
"zoneUri": "us-central1-a"
},
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "c4a-standard-4",
"diskConfig": {
"bootDiskSizeGb": 500,
}
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "c4a-standard-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
},
"softwareConfig": {
"imageVersion": "2.1-ubuntu20-arm"
}
}
}
Más información
- Consulta VMs de Arm en Compute
- Consulta Crea una VM con un tipo personalizado de máquina.
- Consulta Crea y, luego, inicia una instancia de Compute Engine.