The following examples create and use a Kerberos enabled Dataproc cluster with Ranger and Solr components to control access by users to Hadoop, YARN, and HIVE resources.
Notes:
The Ranger Web UI can be accessed through the Component Gateway.
In a Ranger with Kerberos cluster, Dataproc maps a Kerberos user to the system user by stripping the Kerberos user's realm and instance. For example, Kerberos principal
user1/cluster-m@MY.REALMis mapped to systemuser1, and Ranger policies are defined to allow or deny permissions foruser1.
Create the cluster.
- The following
gcloudcommand can be run in a local terminal window or from a project's Cloud Shell.gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=SOLR,RANGER \ --enable-component-gateway \ --properties="dataproc:ranger.kms.key.uri=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key,dataproc:ranger.admin.password.uri=gs://bucket/admin-password.encrypted" \ --kerberos-root-principal-password-uri=gs://bucket/kerberos-root-principal-password.encrypted \ --kerberos-kms-key=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key
- The following
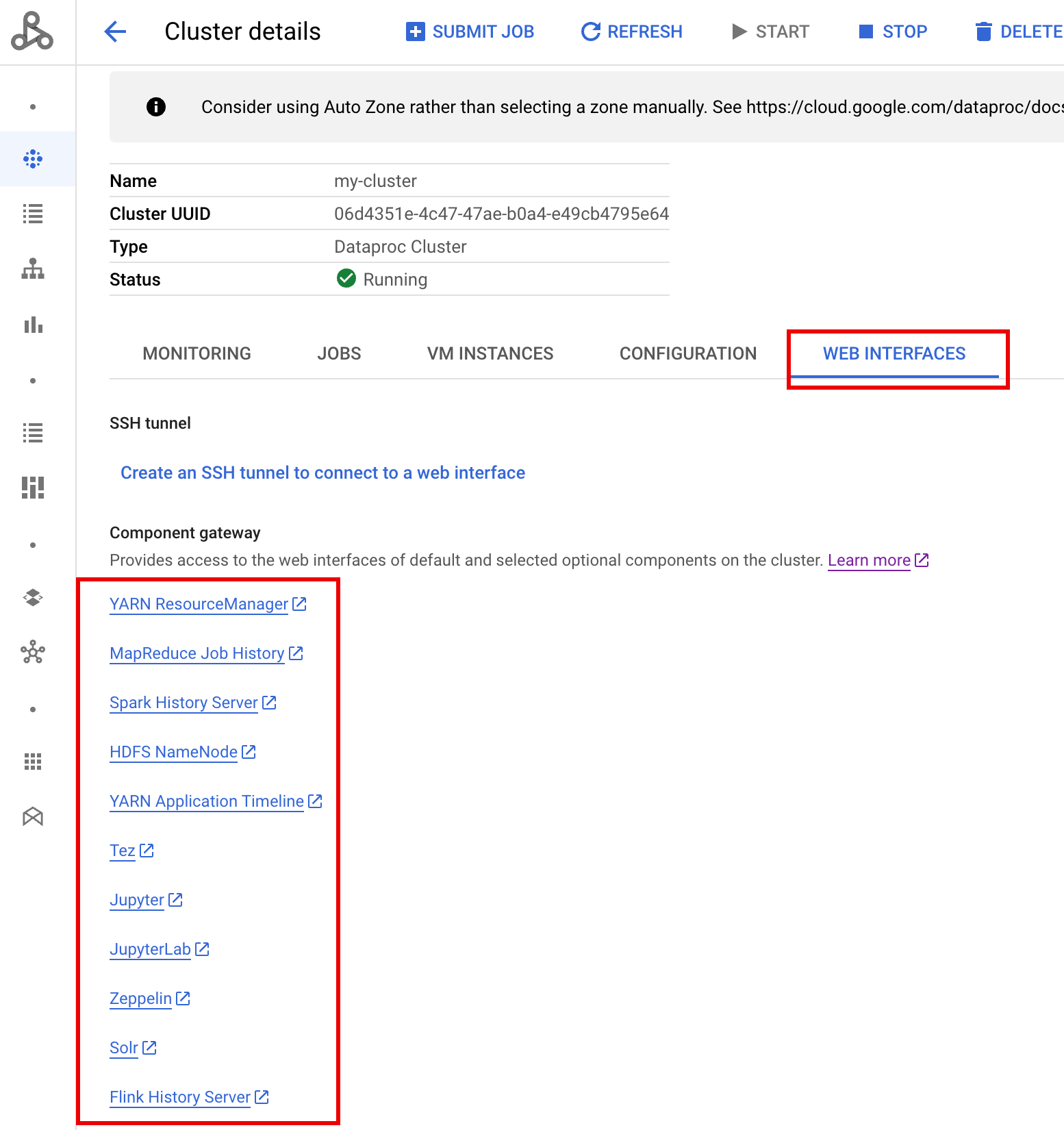
After the cluster is running, navigate to the Dataproc Clusters page on Google Cloud console, then select the cluster's name to open the Cluster details page. Click the Web Interfaces tab to display a list of Component Gateway links to the web interfaces of default and optional components installed on the cluster. Click the Ranger link.
Sign in to Ranger by entering the "admin" username and the Ranger admin password.
The Ranger admin UI opens in a local browser.
YARN access policy
This example creates a Ranger policy to allow and deny user access to the YARN root.default queue.
Select
yarn-dataprocfrom the Ranger Admin UI.
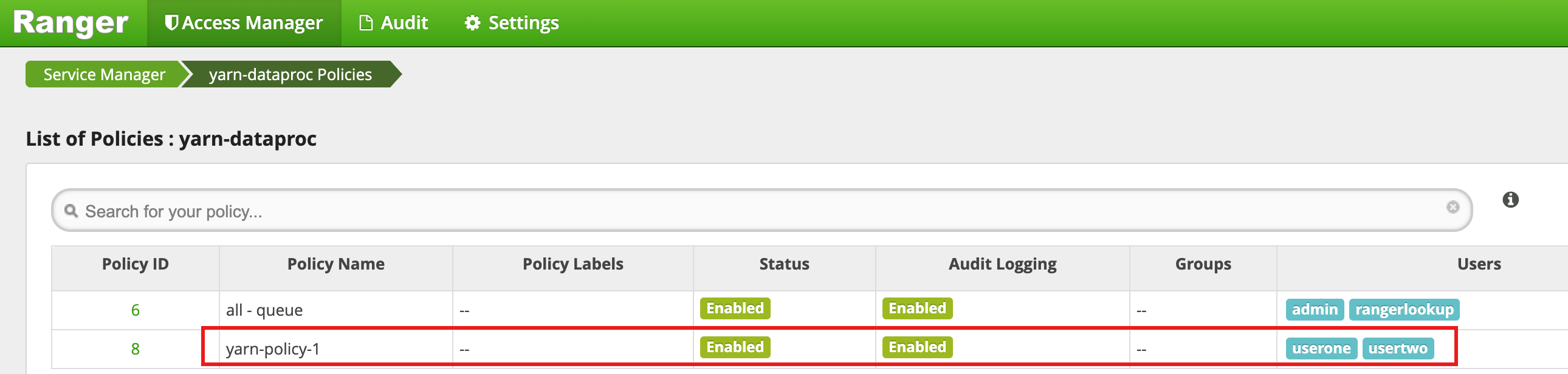
On the yarn-dataproc Policies page, click Add New Policy. On the Create Policy page, the following fields are entered or selected:
Policy Name: "yarn-policy-1"Queue: "root.default"Audit Logging: "Yes"Allow Conditions:Select User: "userone"Permissions: "Select All" to grant all permissions
Deny Conditions:Select User: "usertwo"Permissions: "Select All" to deny all permissions
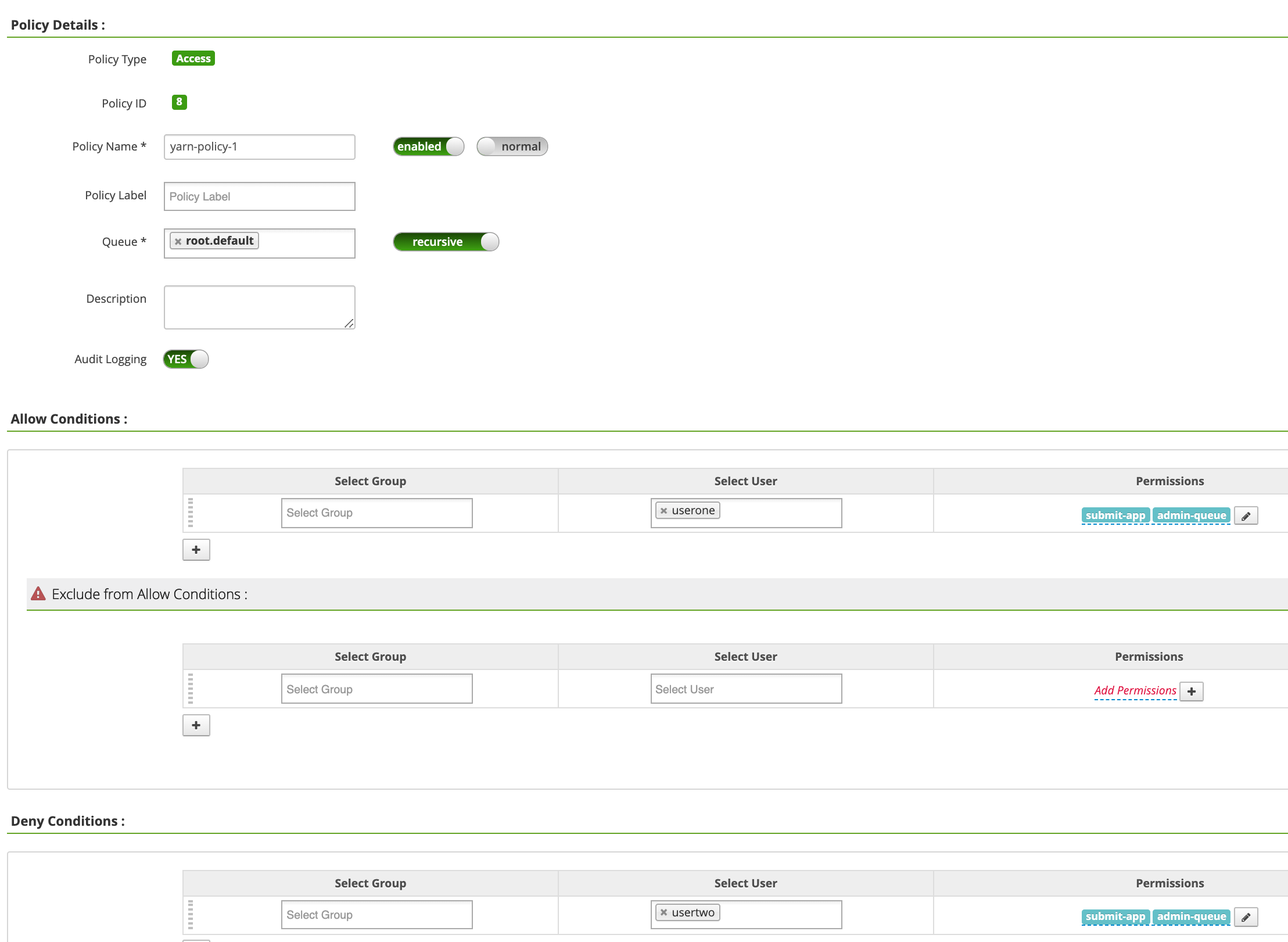
Click Add to save the policy. The policy is listed on the yarn-dataproc Policies page:
Run a Hadoop mapreduce job in the master SSH session window as userone:
userone@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- The Ranger UI shows that
useronewas allowed to submit the job.
- The Ranger UI shows that
Run the Hadoop mapreduce job from the VM master SSH session window as
usertwo:usertwo@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- The Ranger UI shows that
usertwowas denied access to submit the job.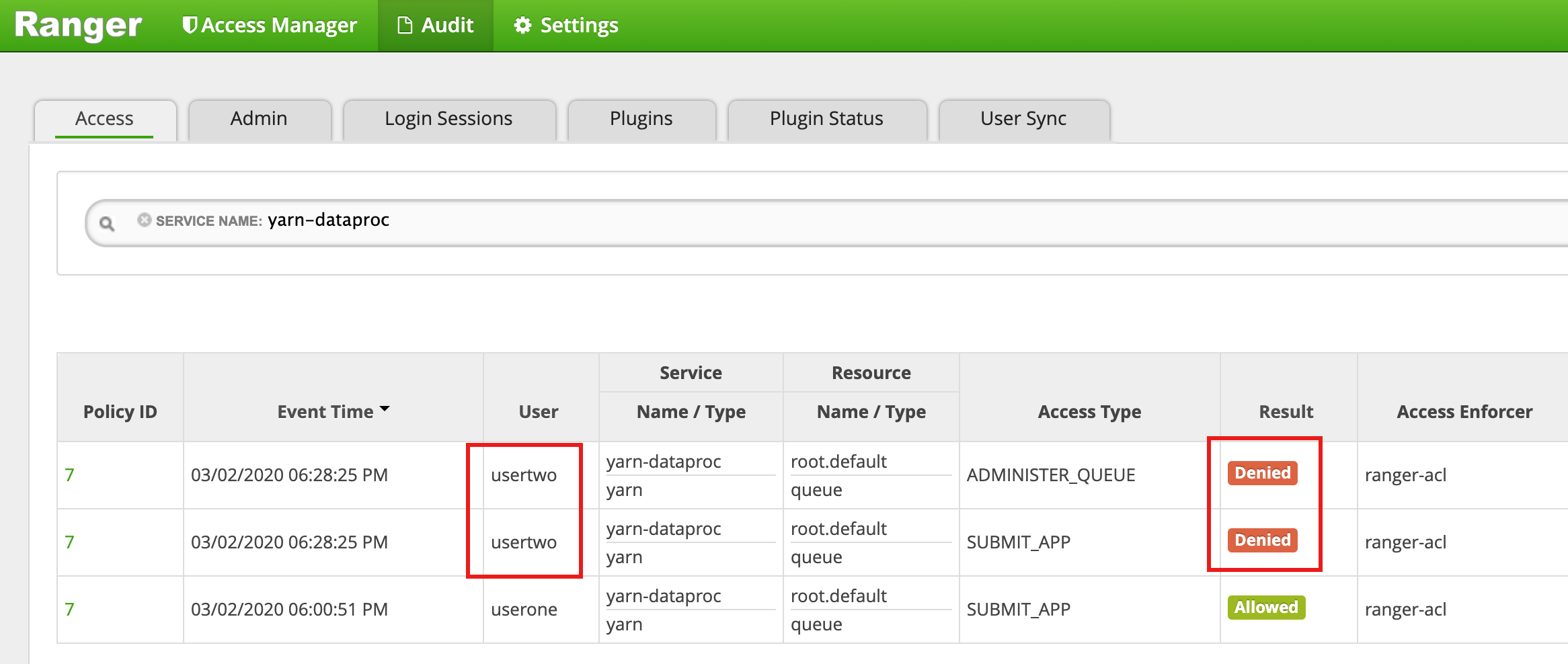
- The Ranger UI shows that
HDFS access policy
This example creates a Ranger policy to allow and deny user access to the
HDFS /tmp directory.
Select
hadoop-dataprocfrom the Ranger Admin UI.
On the hadoop-dataproc Policies page, click Add New Policy. On the Create Policy page, the following fields are entered or selected:
Policy Name: "hadoop-policy-1"Resource Path: "/tmp"Audit Logging: "Yes"Allow Conditions:Select User: "userone"Permissions: "Select All" to grant all permissions
Deny Conditions:Select User: "usertwo"Permissions: "Select All" to deny all permissions

Click Add to save the policy. The policy is listed on the hadoop-dataproc Policies page:

Access the HDFS
/tmpdirectory as userone:userone@example-cluster-m:~$ hadoop fs -ls /tmp
- The Ranger UI shows that
useronewas allowed access to the HDFS /tmp directory.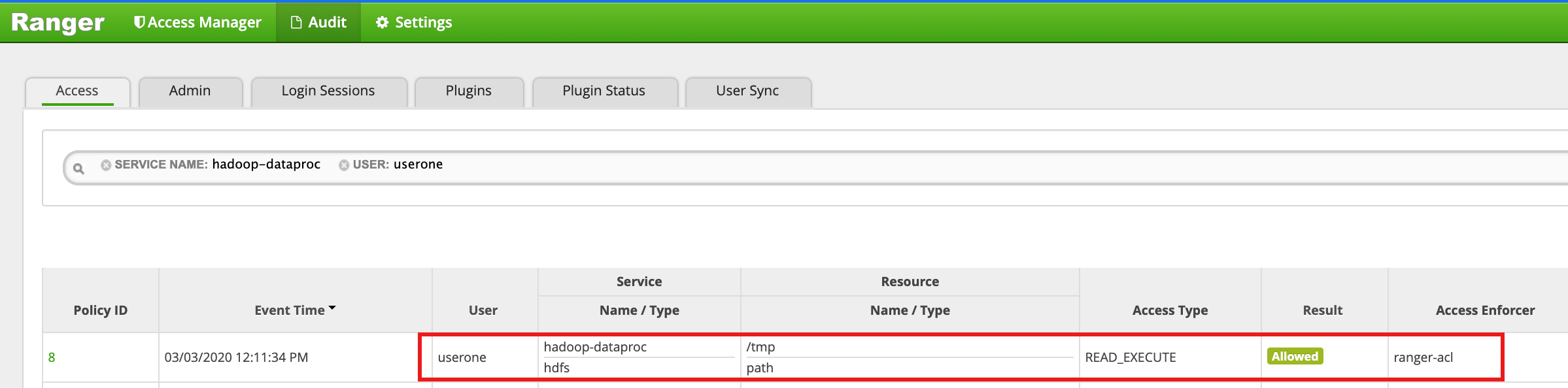
- The Ranger UI shows that
Access the HDFS
/tmpdirectory asusertwo:usertwo@example-cluster-m:~$ hadoop fs -ls /tmp
- The Ranger UI shows that
usertwowas denied access to the HDFS /tmp directory.
- The Ranger UI shows that
Hive access policy
This example creates a Ranger policy to allow and deny user access to a Hive table.
Create a small
employeetable using the hive CLI on the master instance.hive> CREATE TABLE IF NOT EXISTS employee (eid int, name String); INSERT INTO employee VALUES (1 , 'bob') , (2 , 'alice'), (3 , 'john');
Select
hive-dataprocfrom the Ranger Admin UI.
On the hive-dataproc Policies page, click Add New Policy. On the Create Policy page, the following fields are entered or selected:
Policy Name: "hive-policy-1"database: "default"table: "employee"Hive Column: "*"Audit Logging: "Yes"Allow Conditions:Select User: "userone"Permissions: "Select All" to grant all permissions
Deny Conditions:Select User: "usertwo"Permissions: "Select All" to deny all permissions
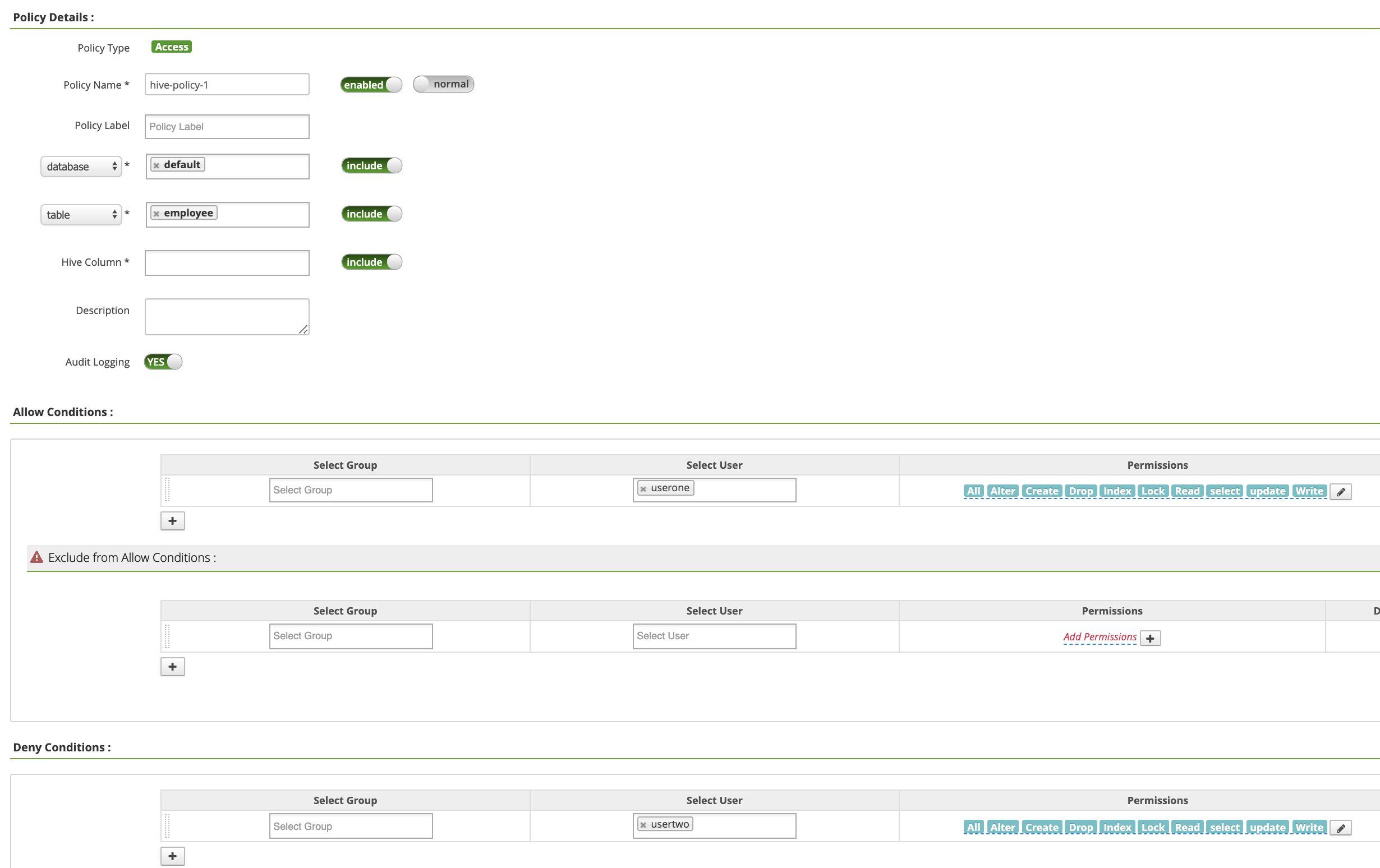
Click Add to save the policy. The policy is listed on the hive-dataproc Policies page:

Run a query from the VM master SSH session against Hive employee table as userone:
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- The userone query succeeds:
Connected to: Apache Hive (version 2.3.6) Driver: Hive JDBC (version 2.3.6) Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 1 | bob | | 2 | alice | | 3 | john | +---------------+----------------+ 3 rows selected (2.033 seconds)
- The userone query succeeds:
Run a query from the VM master SSH session against Hive employee table as usertwo:
usertwo@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- usertwo is denied access to the table:
Error: Could not open client transport with JDBC Uri: ... Permission denied: user=usertwo, access=EXECUTE, inode="/tmp/hive"
- usertwo is denied access to the table:
Fine-Grained Hive Access
Ranger supports Masking and Row Level Filters on Hive. This example
builds on the previous hive-policy-1 by adding masking and filter
policies.
Select
hive-dataprocfrom the Ranger Admin UI, then select the Masking tab and click Add New Policy.
On the Create Policy page, the following fields are entered or selected to create a policy to mask (nullify) the employee name column.:
Policy Name: "hive-masking policy"database: "default"table: "employee"Hive Column: "name"Audit Logging: "Yes"Mask Conditions:Select User: "userone"Access Types: "select" add/edit permissionsSelect Masking Option: "nullify"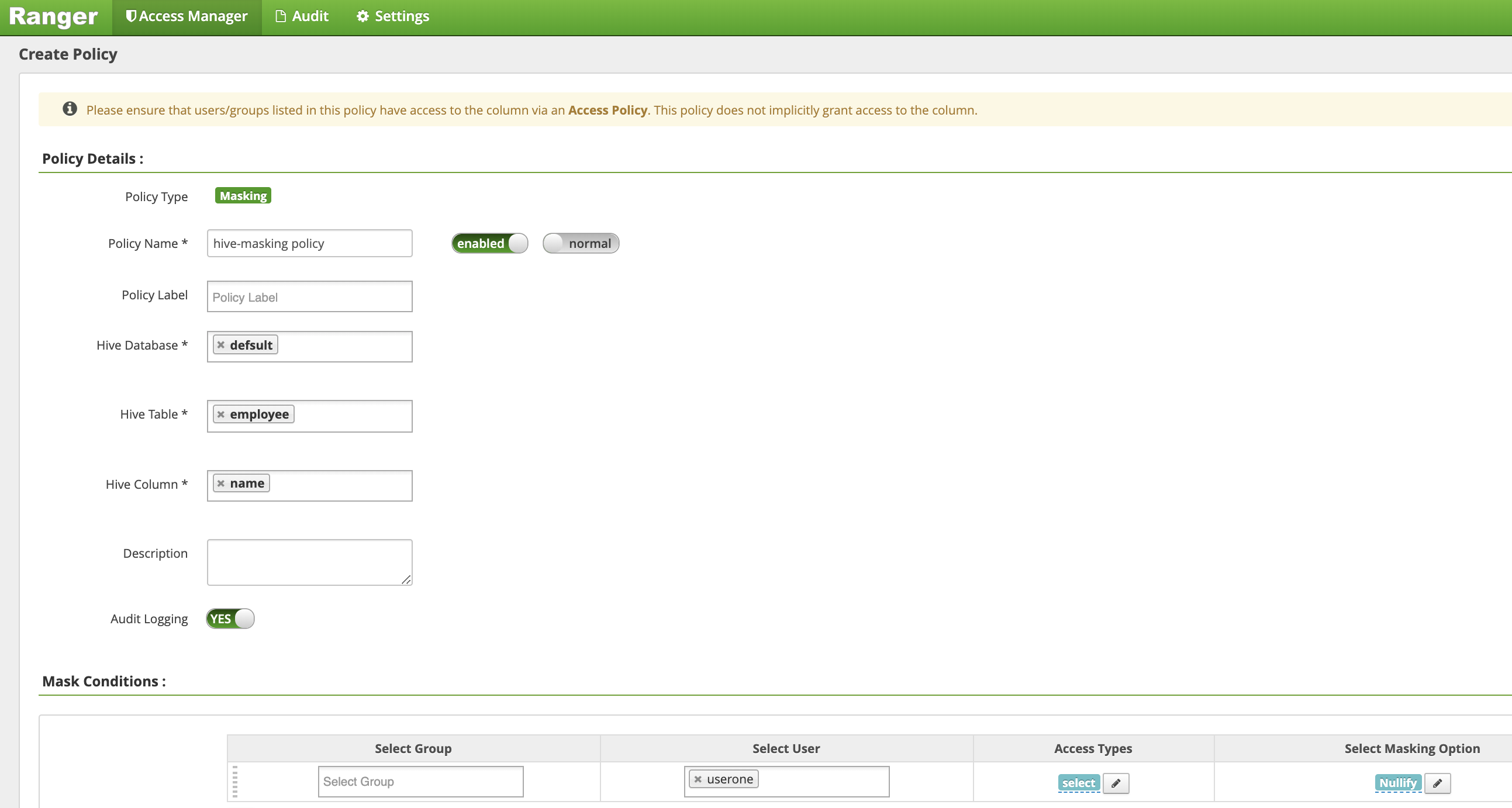
Click Add to save the policy.
Select
hive-dataprocfrom the Ranger Admin UI, then select the Row Level Filter tab and click Add New Policy.
On the Create Policy page, the following fields are entered or selected to create a policy to filter (return) rows where
eidis not equal to1:Policy Name: "hive-filter policy"Hive Database: "default"Hive Table: "employee"Audit Logging: "Yes"Mask Conditions:Select User: "userone"Access Types: "select" add/edit permissionsRow Level Filter: "eid != 1" filter expression
Click Add to save the policy.
Repeat the previous query from the VM master SSH session against Hive employee table as userone:
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- The query returns with the name column masked out and bob
(eid=1) filtered from the results.:
Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 2 | NULL | | 3 | NULL | +---------------+----------------+ 2 rows selected (0.47 seconds)
- The query returns with the name column masked out and bob
(eid=1) filtered from the results.: