Ce document décrit les outils et les fichiers que vous pouvez utiliser pour surveiller et résoudre les problèmes liés aux charges de travail par lot Serverless pour Apache Spark.
Résoudre les problèmes liés aux charges de travail depuis la console Google Cloud
Lorsqu'un job par lot échoue ou présente de mauvaises performances, la première étape recommandée consiste à ouvrir la page Détails du lot à partir de la page Lots de la console Google Cloud .
Utiliser l'onglet "Récapitulatif" : votre centre de dépannage
L'onglet Récapitulatif, sélectionné par défaut lorsque la page Détails du lot s'ouvre, affiche des métriques critiques et des journaux filtrés pour vous aider à évaluer rapidement l'état du lot. Après cette évaluation initiale, vous pouvez effectuer une analyse plus approfondie à l'aide d'outils plus spécialisés disponibles sur la page Détails du lot, tels que l'interface utilisateur Spark, l'explorateur de journaux et Gemini Cloud Assist.
Métriques clés par lot
L'onglet Récapitulatif de la page Détails du lot inclut des graphiques qui affichent les valeurs importantes des métriques de charge de travail par lot. Les graphiques de métriques sont générés une fois l'opération terminée. Ils fournissent une indication visuelle des problèmes potentiels, tels que la contention des ressources, l'asymétrie des données ou la pression sur la mémoire.
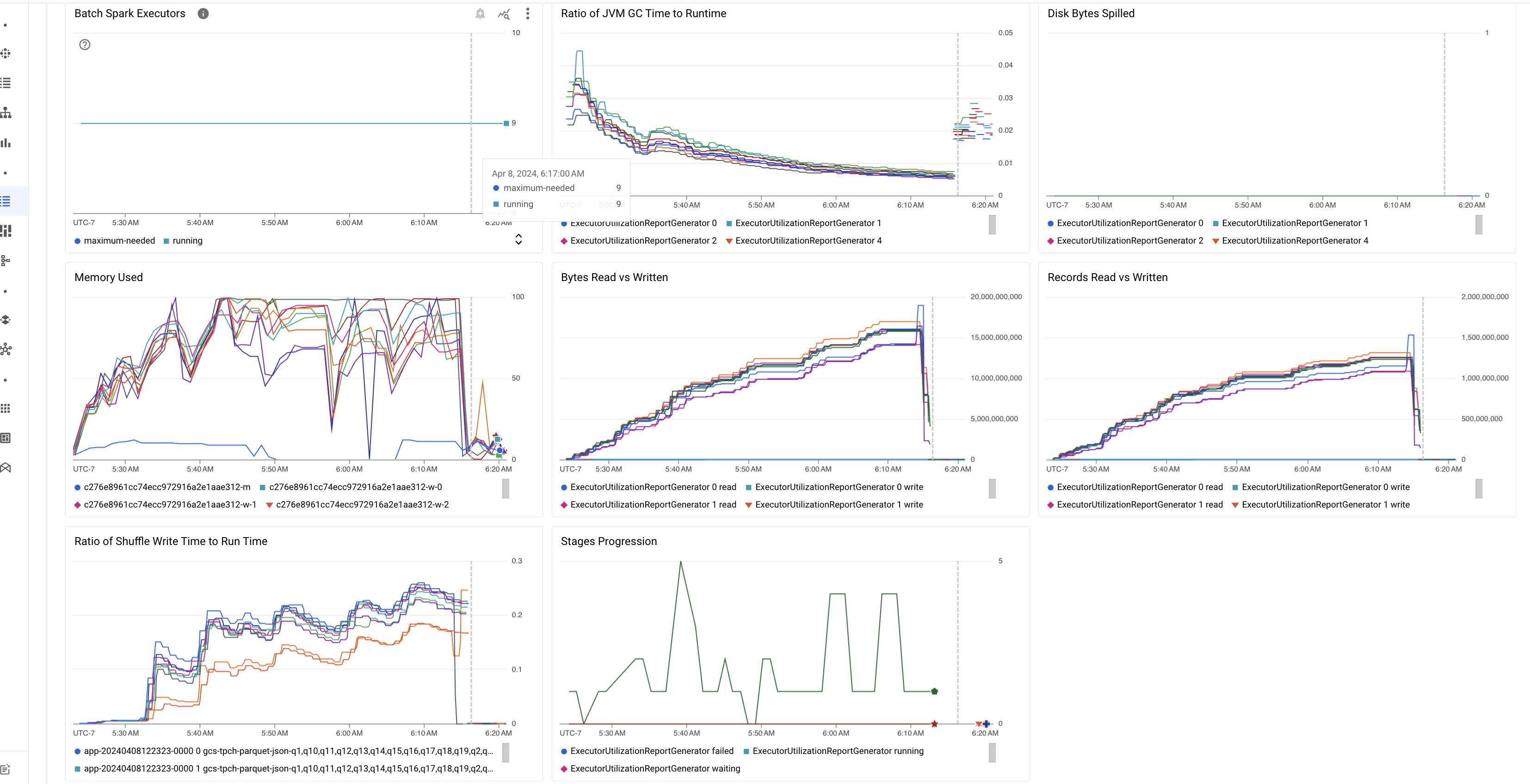
Le tableau suivant liste les métriques de charge de travail Spark affichées sur la page Détails du lot de la console Google Cloud . Il décrit également comment les valeurs des métriques peuvent fournir des informations sur l'état et les performances de la charge de travail.
| Métrique | Quelles informations sont affichées ? |
|---|---|
| Métriques au niveau de l'exécuteur | |
| Ratio entre la durée de récupération de mémoire de la JVM et la durée d'exécution | Cette métrique indique le ratio entre le temps de GC (garbage collection) de la JVM et le temps d'exécution par exécuteur. Des ratios élevés peuvent indiquer des fuites de mémoire dans les tâches exécutées sur des exécuteurs spécifiques ou des structures de données inefficaces, ce qui peut entraîner un fort taux de renouvellement des objets. |
| Octets répandus sur le disque | Cette métrique indique le nombre total d'octets de disque déversés sur différents exécuteurs. Si un exécuteur affiche un nombre élevé d'octets de disque déversés, cela peut indiquer un déséquilibre des données. Si la métrique augmente au fil du temps, cela peut indiquer qu'il existe des étapes avec une pression ou des fuites de mémoire. |
| Octets lus et écrits | Cette métrique indique le nombre d'octets écrits par rapport au nombre d'octets lus par exécuteur. Des écarts importants dans les octets lus ou écrits peuvent indiquer des scénarios dans lesquels les jointures répliquées entraînent une amplification des données sur des exécuteurs spécifiques. |
| Enregistrements lus et écrits | Cette métrique indique les enregistrements lus et écrits par exécuteur. Un grand nombre d'enregistrements lus avec un faible nombre d'enregistrements écrits peut indiquer un goulot d'étranglement dans la logique de traitement sur des exécuteurs spécifiques, ce qui entraîne la lecture des enregistrements en attente. Les exécuteurs qui accusent systématiquement un retard dans les lectures et les écritures peuvent indiquer une contention des ressources sur ces nœuds ou des inefficacités de code spécifiques aux exécuteurs. |
| Ratio entre le temps d'écriture aléatoire et le temps d'exécution | La métrique indique le temps passé par l'exécuteur dans le temps d'exécution du shuffle par rapport au temps d'exécution global. Si cette valeur est élevée pour certains exécuteurs, cela peut indiquer un déséquilibre des données ou une sérialisation inefficace des données. Vous pouvez identifier les étapes avec de longs temps d'écriture du shuffle dans l'interface utilisateur Spark. Recherchez les tâches aberrantes dans ces étapes qui prennent plus de temps que la moyenne. Vérifiez si les exécuteurs avec des temps d'écriture shuffle élevés affichent également une activité d'E/S de disque élevée. Une sérialisation plus efficace et des étapes de partitionnement supplémentaires peuvent être utiles. Un nombre très élevé d'écritures d'enregistrements par rapport aux lectures d'enregistrements peut indiquer une duplication involontaire des données en raison de jointures inefficaces ou de transformations incorrectes. |
| Métriques au niveau de l'application | |
| Progression des étapes | Cette métrique indique le nombre d'étapes en échec, en attente et en cours d'exécution. Un grand nombre d'étapes en échec ou en attente peut indiquer un déséquilibre des données. Recherchez les partitions de données et déterminez la raison de l'échec de l'étape à l'aide de l'onglet Étapes de l'UI Spark. |
| Exécuteurs Spark par lot | Cette métrique indique le nombre d'exécuteurs qui pourraient être nécessaires par rapport au nombre d'exécuteurs en cours d'exécution. Une grande différence entre les exécuteurs requis et ceux en cours d'exécution peut indiquer des problèmes d'autoscaling. |
| Métriques au niveau de la VM | |
| Mémoire utilisée | Cette métrique indique le pourcentage de mémoire de VM utilisée. Si le pourcentage du maître est élevé, cela peut indiquer que le pilote est soumis à une pression de mémoire. Pour les autres nœuds de VM, un pourcentage élevé peut indiquer que les exécuteurs manquent de mémoire, ce qui peut entraîner un débordement de disque élevé et un temps d'exécution de la charge de travail plus lent. Utilisez l'UI Spark pour analyser les exécuteurs et vérifier si le temps de GC est élevé et si le nombre d'échecs de tâches est élevé. Déboguez également le code Spark pour la mise en cache de grands ensembles de données et la diffusion inutile de variables. |
Journaux de la tâche
La page Détails du lot inclut une section Journaux des jobs qui liste les avertissements et les erreurs filtrés à partir des journaux des jobs (charge de travail par lot). Cette fonctionnalité permet d'identifier rapidement les problèmes critiques sans avoir à analyser manuellement de volumineux fichiers journaux. Vous pouvez sélectionner une gravité de journal (par exemple, Error) dans le menu déroulant et ajouter un filtre textuel pour affiner les résultats. Pour effectuer une analyse plus approfondie, cliquez sur l'icône Afficher dans l'explorateur de journaux pour ouvrir les journaux de lot sélectionnés dans l'explorateur de journaux.
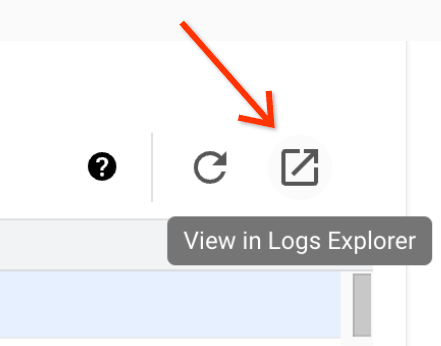
Exemple : L'explorateur de journaux s'ouvre après avoir sélectionné Errors dans le sélecteur de gravité sur la page Détails du lot de la console Google Cloud .
UI Spark
L'UI Spark collecte les détails d'exécution Apache Spark à partir des charges de travail par lot Serverless pour Apache Spark. La fonctionnalité UI Spark, activée par défaut, est gratuite.
Les données collectées par la fonctionnalité UI Spark sont conservées pendant 90 jours. Vous pouvez utiliser cette interface Web pour surveiller et déboguer les charges de travail Spark sans avoir à créer de serveur d'historique persistant.
Autorisations et rôles Identity and Access Management requis
Les autorisations suivantes sont requises pour utiliser la fonctionnalité d'UI Spark avec les charges de travail par lot.
Autorisation de collecte de données :
dataproc.batches.sparkApplicationWrite. Cette autorisation doit être accordée au compte de service qui exécute les charges de travail par lot. Cette autorisation est incluse dans le rôleDataproc Worker, qui est automatiquement accordé au compte de service Compute Engine par défaut que Serverless pour Apache Spark utilise par défaut (voir Compte de service Serverless pour Apache Spark). Toutefois, si vous spécifiez un compte de service personnalisé pour votre charge de travail par lot, vous devez ajouter l'autorisationdataproc.batches.sparkApplicationWriteà ce compte de service (généralement en attribuant le rôle DataprocWorkerau compte de service).Autorisation d'accès à l'UI Spark :
dataproc.batches.sparkApplicationRead. Cette autorisation doit être accordée à un utilisateur pour qu'il puisse accéder à l'interface utilisateur Spark dans la consoleGoogle Cloud . Cette autorisation est incluse dans les rôlesDataproc Viewer,Dataproc EditoretDataproc Administrator. Pour ouvrir l'interface utilisateur Spark dans la console Google Cloud , vous devez disposer de l'un de ces rôles ou d'un rôle personnalisé qui inclut cette autorisation.
Ouvrir l'UI Spark
La page de l'UI Spark est disponible dans les charges de travail par lot de la console Google Cloud .
Accédez à la page Sessions interactives Serverless pour Apache Spark.
Cliquez sur un ID de lot pour ouvrir la page Informations sur le lot.
Cliquez sur Afficher l'UI Spark dans le menu du haut.
Le bouton Afficher l'UI Spark est désactivé dans les cas suivants :
- Si une autorisation requise n'est pas accordée
- Si vous décochez la case Activer l'UI Spark sur la page Détails du lot
- Si vous définissez la propriété
spark.dataproc.appContext.enabledsurfalselorsque vous soumettez une charge de travail par lot
Journaux Serverless pour Apache Spark
La journalisation est activée par défaut dans Serverless pour Apache Spark, et les journaux de charge de travail sont conservés une fois la charge de travail terminée. Serverless pour Apache Spark collecte les journaux de charge de travail dans Cloud Logging.
Vous pouvez accéder aux journaux Serverless pour Apache Spark sous la ressource Cloud Dataproc Batch dans l'explorateur de journaux.
Interroger les journaux Serverless pour Apache Spark
L'explorateur de journaux de la console Google Cloud fournit un volet de requête pour vous aider à créer une requête permettant d'examiner les journaux des charges de travail par lot. Voici les étapes à suivre pour créer une requête permettant d'examiner les journaux de charge de travail par lot :
- Votre projet actuel est sélectionné. Vous pouvez cliquer sur Affiner le projet de portée pour sélectionner un autre projet.
Définissez une requête par lot pour les journaux.
Utilisez les menus de filtre pour filtrer une charge de travail par lot.
Sous Toutes les ressources, sélectionnez la ressource Batch Cloud Dataproc.
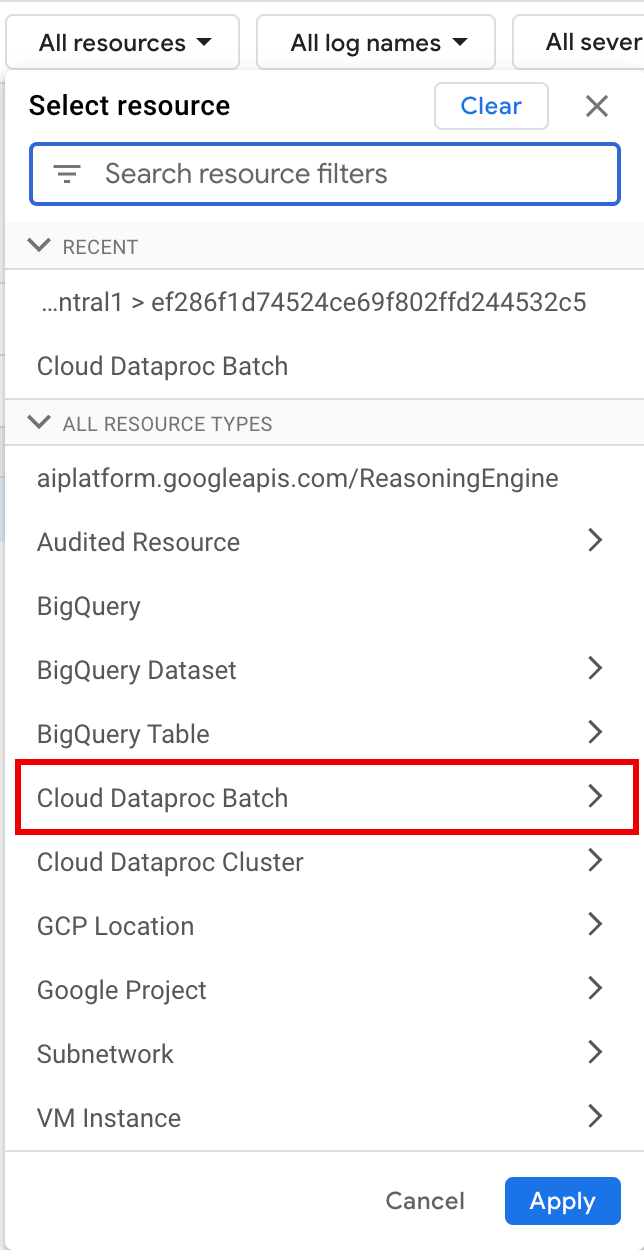
Dans le panneau Sélectionner une ressource, sélectionnez le LIEU du lot, puis l'ID DU LOT. Ces paramètres de lot sont listés sur la page Lots de Dataproc dans la console Google Cloud .
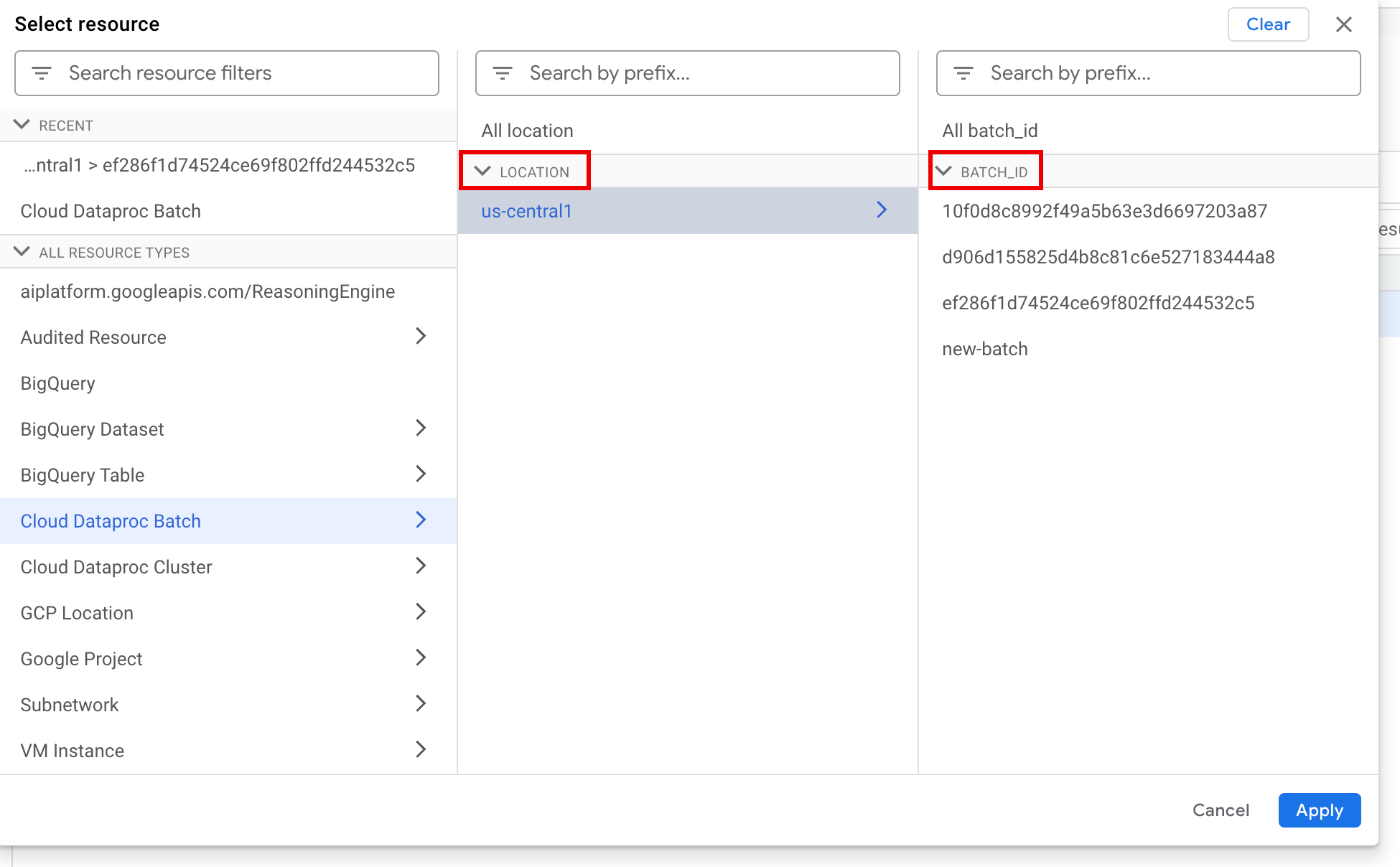
Cliquez sur Appliquer.
Sous Sélectionner les noms de journaux, saisissez
dataproc.googleapis.comdans le champ Rechercher des noms de journaux pour limiter les types de journaux à interroger. Sélectionnez un ou plusieurs noms de fichiers journaux listés.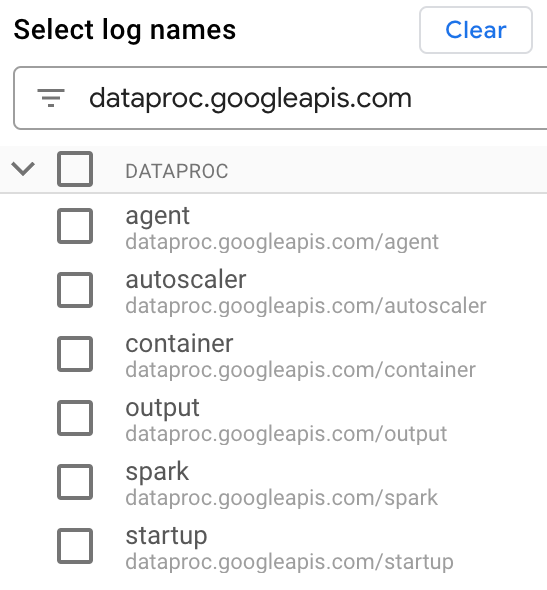
Utilisez l'éditeur de requête pour filtrer les journaux spécifiques aux VM.
Spécifiez le type de ressource et le nom de la ressource de VM, comme indiqué dans l'exemple suivant :
resource.type="cloud_dataproc_batch" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
- BATCH_UUID : l'UUID du lot est indiqué sur la page "Informations sur le lot" de la console Google Cloud , qui s'ouvre lorsque vous cliquez sur l'ID du lot sur la page Lots.
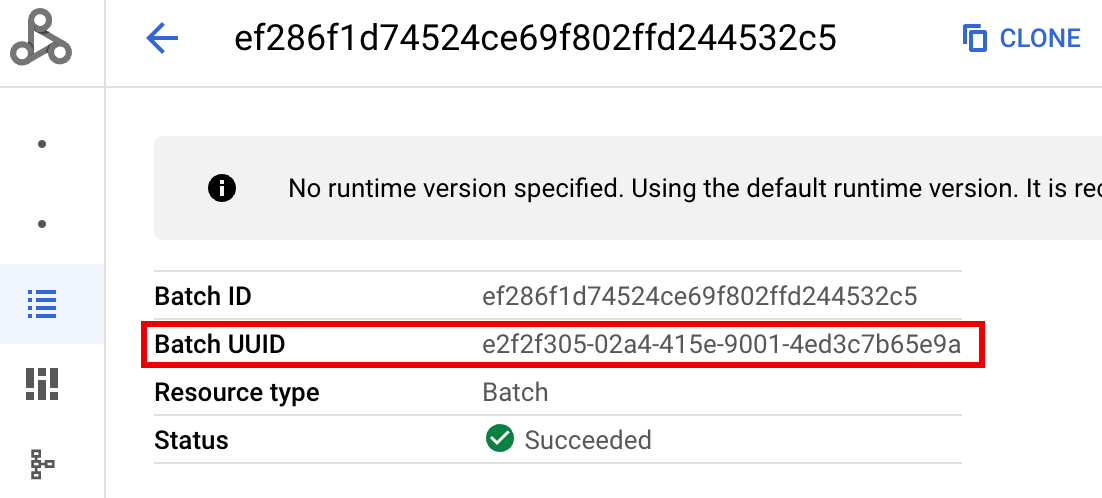
Les journaux de traitement par lot indiquent également l'UUID du lot dans le nom de la ressource de VM. Voici un exemple tiré d'un fichier driver.log par lot :
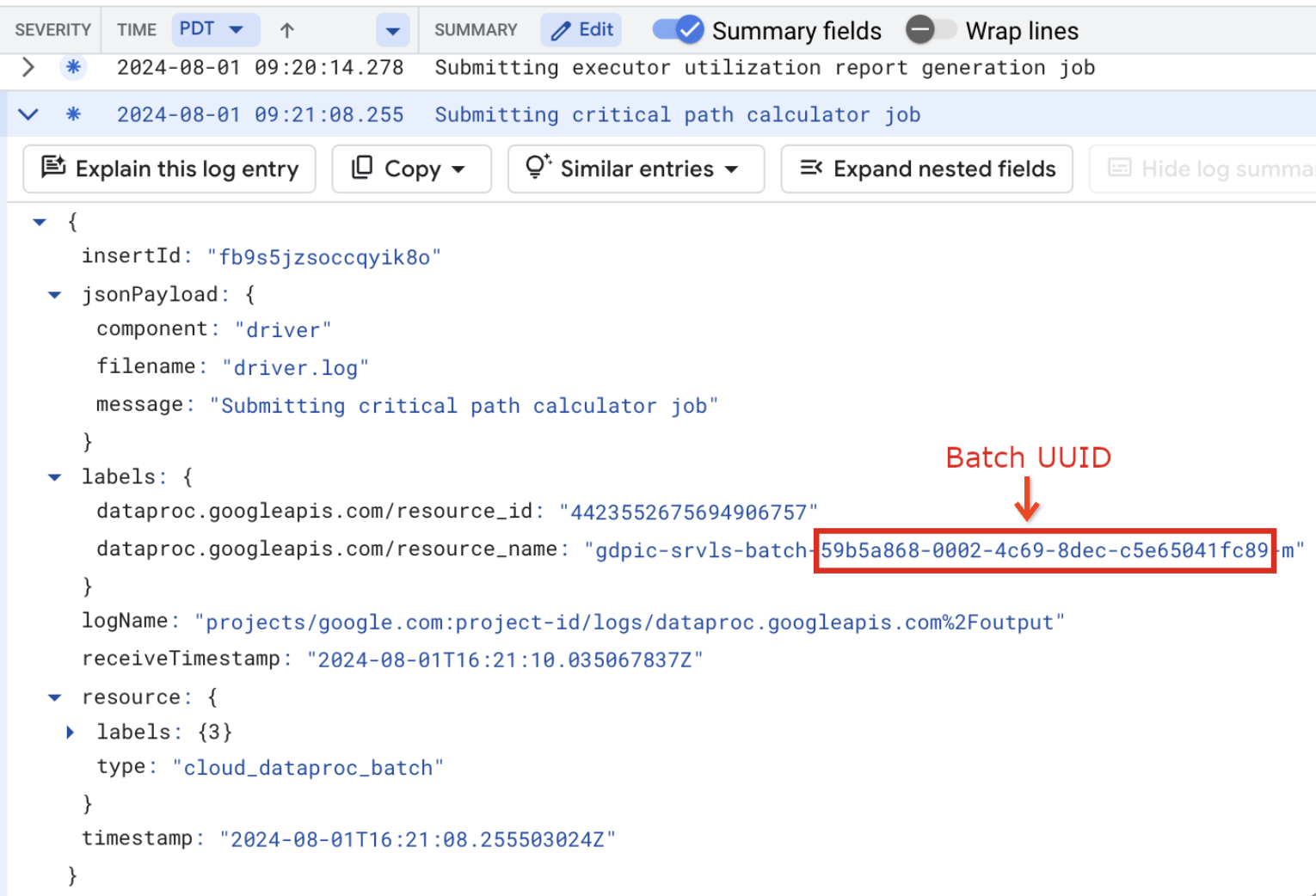
- BATCH_UUID : l'UUID du lot est indiqué sur la page "Informations sur le lot" de la console Google Cloud , qui s'ouvre lorsque vous cliquez sur l'ID du lot sur la page Lots.
Cliquez sur Exécuter la requête.
Types de journaux et exemples de requêtes Serverless pour Apache Spark
La liste suivante décrit les différents types de journaux Serverless pour Apache Spark et fournit des exemples de requêtes de l'explorateur de journaux pour chaque type de journal.
dataproc.googleapis.com/output: ce fichier journal contient la sortie de la charge de travail par lot. Serverless pour Apache Spark diffuse la sortie par lot dans l'espace de nomsoutputet définit le nom de fichier surJOB_ID.driver.log.Exemple de requête de l'explorateur de journaux pour les journaux de sortie :
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Foutput"
dataproc.googleapis.com/spark: l'espace de nomssparkagrège les journaux Spark pour les démons et les exécuteurs s'exécutant sur les VM maître et de nœud de calcul du cluster Dataproc. Chaque entrée de journal inclut un libellé de composantmaster,workerouexecutorpour identifier la source du journal, comme suit :executor: journaux des exécutants de code utilisateur. Il s'agit généralement de journaux distribués.master: journaux du maître du gestionnaire de ressources autonome Spark, qui sont semblables aux journauxResourceManagerde Dataproc sur Compute Engine YARN.worker: journaux du nœud de calcul du gestionnaire de ressources autonome Spark, qui sont semblables aux journauxNodeManagerde Dataproc sur Compute Engine YARN.
Exemple de requête de l'explorateur de journaux pour tous les journaux de l'espace de noms
spark:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark"
Exemple de requête de l'explorateur de journaux pour les journaux de composants autonomes Spark dans l'espace de noms
spark:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark" jsonPayload.component="COMPONENT"
dataproc.googleapis.com/startup: l'espace de nomsstartupinclut les journaux de démarrage par lot (cluster). Les journaux de script d'initialisation sont inclus. Les composants sont identifiés par un libellé, par exemple :startup-script[855]: ... activate-component-spark[3050]: ... enable spark-worker
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fstartup" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
dataproc.googleapis.com/agent: l'espace de nomsagentagrège les journaux de l'agent Dataproc. Chaque entrée de journal inclut un libellé de nom de fichier qui identifie la source du journal.Exemple de requête de l'explorateur de journaux pour les journaux d'agent générés par une VM de nœud de calcul spécifique :
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fagent" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
dataproc.googleapis.com/autoscaler: l'espace de nomsautoscaleragrège les journaux de l'autoscaler Serverless pour Apache Spark.Exemple de requête de l'explorateur de journaux pour les journaux d'agent générés par une VM de nœud de calcul spécifique :
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fautoscaler" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
Pour en savoir plus, consultez la page Journaux Dataproc.
Pour en savoir plus sur les journaux d'audit de Serverless pour Apache Spark, consultez Journaux d'audit Dataproc.
Métriques liées aux charges de travail
Serverless pour Apache Spark fournit des métriques de lot et Spark que vous pouvez afficher dans l'explorateur de métriques ou sur la page Détails du lot de la console Google Cloud .
Métriques par lot
Les métriques de ressources batch Dataproc fournissent des informations sur les ressources par lot, telles que le nombre d'exécuteurs de lot. Les métriques de lot sont précédées du préfixe dataproc.googleapis.com/batch.
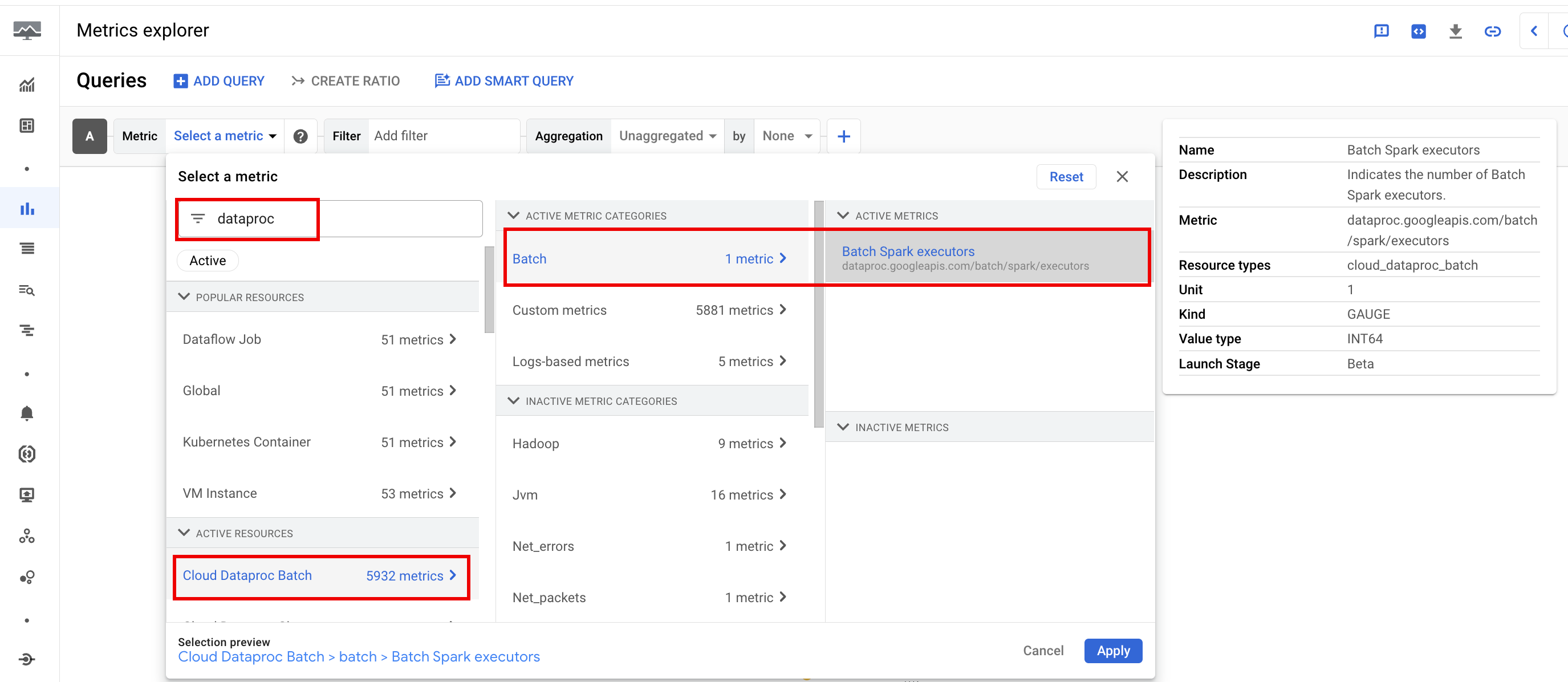
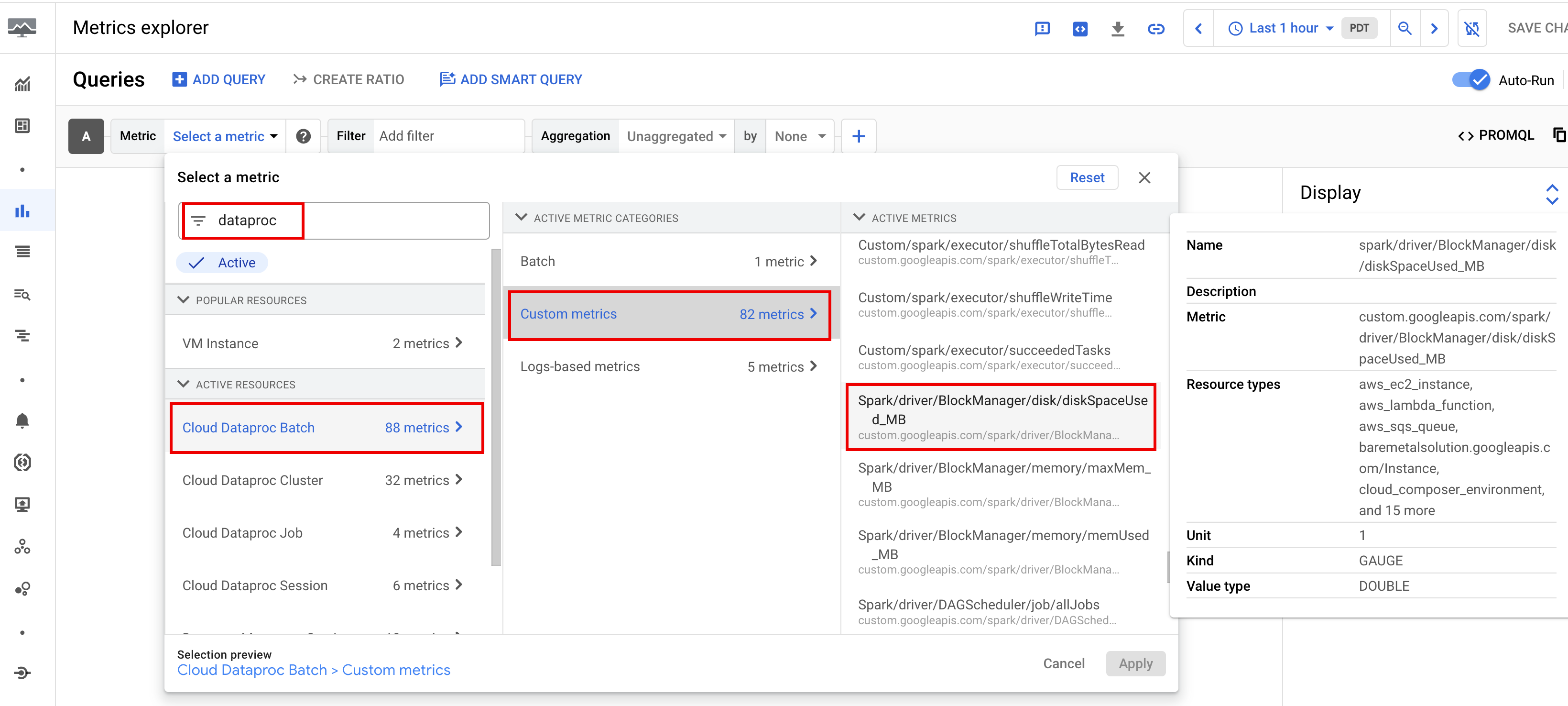
Métriques Spark
Par défaut, Serverless pour Apache Spark active la collecte des métriques Spark disponibles, sauf si vous utilisez les propriétés de collecte des métriques Spark pour désactiver ou remplacer la collecte d'une ou de plusieurs métriques Spark.
Les métriques Spark disponibles incluent les métriques du pilote et de l'exécuteur Spark, ainsi que les métriques système. Les métriques Spark disponibles sont précédées de custom.googleapis.com/.
Configurer des alertes de métrique
Vous pouvez créer des alertes de métriques Dataproc pour être averti des problèmes liés aux charges de travail.
Créer des graphiques
Vous pouvez créer des graphiques qui visualisent les métriques de charge de travail à l'aide de l'explorateur de métriques dans la consoleGoogle Cloud . Par exemple, vous pouvez créer un graphique pour afficher disk:bytes_used, puis filtrer par batch_id.
Cloud Monitoring
Monitoring utilise les métadonnées et les métriques des charges de travail pour fournir des insights sur l'état et les performances des charges de travail Serverless pour Apache Spark. Les métriques de charge de travail incluent les métriques Spark, les métriques de lot et les métriques d'opération.
Vous pouvez utiliser Cloud Monitoring dans la console Google Cloud pour explorer les métriques, ajouter des graphiques, créer des tableaux de bord et créer des alertes.
Créer des tableaux de bord
Vous pouvez créer un tableau de bord pour surveiller les charges de travail à l'aide de métriques provenant de plusieurs projets et de différents produits Google Cloud . Pour en savoir plus, consultez Créer et gérer des tableaux de bord personnalisés.
Serveur d'historique persistant
Serverless pour Apache Spark crée les ressources de calcul nécessaires à l'exécution d'une charge de travail, exécute la charge de travail sur ces ressources, puis supprime les ressources une fois la charge de travail terminée. Les métriques et les événements de charge de travail ne persistent pas une fois la charge de travail terminée. Toutefois, vous pouvez utiliser un serveur d'historique persistant (PHS) pour conserver l'historique des applications de charge de travail (journaux d'événements) dans Cloud Storage.
Pour utiliser un PHS avec une charge de travail par lot, procédez comme suit :
Spécifiez votre PHS lorsque vous soumettez une charge de travail.
Utilisez la passerelle des composants pour vous connecter au PHS et afficher les détails des applications, les étapes du planificateur, les détails au niveau des tâches, ainsi que les informations sur l'environnement et l'exécuteur.
Réglage automatique
- Activez l'optimisation automatique pour Serverless pour Apache Spark : vous pouvez activer l'optimisation automatique pour Serverless pour Apache Spark lorsque vous envoyez chaque charge de travail par lot Spark récurrente à l'aide de la console Google Cloud , de la gcloud CLI ou de l'API Dataproc.
Console
Pour activer le réglage automatique sur chaque charge de travail Spark par lot récurrente, procédez comme suit :
Dans la console Google Cloud , accédez à la page Lots de Dataproc.
Pour créer une charge de travail par lot, cliquez sur Créer.
Dans la section Conteneur, saisissez le nom de la cohorte, qui identifie le lot comme faisant partie d'une série de charges de travail récurrentes. L'analyse assistée par Gemini est appliquée à la deuxième charge de travail et aux suivantes qui sont envoyées avec ce nom de cohorte. Par exemple, spécifiez
TPCH-Query1comme nom de cohorte pour une charge de travail planifiée qui exécute une requête TPC-H quotidienne.Remplissez les autres sections de la page Créer un lot selon vos besoins, puis cliquez sur Envoyer. Pour en savoir plus, consultez Envoyer une charge de travail par lot.
gcloud
Exécutez la commande gcloud CLI gcloud dataproc batches submit en local dans une fenêtre de terminal ou dans Cloud Shell pour activer l'optimisation automatique sur chaque charge de travail par lot Spark récurrente :
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ other arguments ...
Remplacez les éléments suivants :
- COMMAND : type de charge de travail Spark, tel que
Spark,PySpark,Spark-SqlouSpark-R. - REGION : région dans laquelle votre charge de travail sera exécutée.
- COHORT : nom de la cohorte, qui identifie le lot comme faisant partie d'une série de charges de travail récurrentes.
L'analyse assistée par Gemini est appliquée à la deuxième charge de travail et aux suivantes qui sont envoyées avec ce nom de cohorte. Par exemple, spécifiez
TPCH Query 1comme nom de cohorte pour une charge de travail planifiée qui exécute une requête TPC-H quotidienne.
API
Incluez le nom RuntimeConfig.cohort dans une requête batches.create pour activer le réglage automatique sur chaque charge de travail par lot Spark récurrente. Le réglage automatique est appliqué à la deuxième charge de travail et aux suivantes envoyées avec ce nom de cohorte. Par exemple, spécifiez TPCH-Query1 comme nom de cohorte pour une charge de travail planifiée qui exécute une requête TPC-H quotidienne.
Exemple :
...
runtimeConfig:
cohort: TPCH-Query1
...