Usa el conector de Spark-BigQuery con Apache Spark para leer y escribir datos desde y hacia BigQuery.
En este instructivo, se muestra una aplicación de PySpark que usa spark-bigquery-connector.
Usa el conector de BigQuery con tu carga de trabajo
Consulta las versiones de tiempo de ejecución de Serverless for Apache Spark para determinar la versión del conector de BigQuery que está instalada en la versión de tiempo de ejecución de tu carga de trabajo por lotes. Si el conector no aparece en la lista, consulta la siguiente sección para obtener instrucciones sobre cómo hacer que el conector esté disponible para las aplicaciones.
Cómo usar el conector con la versión 2.0 del entorno de ejecución de Spark
El conector de BigQuery no está instalado en la versión 2.0 del tiempo de ejecución de Spark. Cuando usas la versión 2.0 del entorno de ejecución de Spark, puedes hacer que el conector esté disponible para tu aplicación de una de las siguientes maneras:
- Usa el parámetro
jarspara apuntar a un archivo JAR del conector cuando envíes tu carga de trabajo por lotes de Google Cloud Serverless for Apache Spark. En el siguiente ejemplo, se especifica un archivo JAR del conector (consulta el repositorio de GoogleCloudDataproc/spark-bigquery-connector en GitHub para obtener una lista de los archivos JAR del conector disponibles).- Ejemplo de Google Cloud CLI:
gcloud dataproc batches submit pyspark \ --region=region \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.13-version.jar \ ... other args
- Ejemplo de Google Cloud CLI:
- Incluye el archivo jar del conector en tu aplicación de Spark como una dependencia (consulta Compila con el conector)
Calcula los costos
En este instructivo, se usan los siguientes componentes facturables de Google Cloud:
- Serverless para Apache Spark
- BigQuery
- Cloud Storage
Usa la calculadora de precios para generar una estimación de los costos según el uso previsto.
BigQuery E/S
Este ejemplo lee los datos de BigQuery en un DataFrame de Spark para realizar un recuento de palabras mediante la API de fuente de datos estándar.
El conector escribe el resultado del recuento de palabras en BigQuery de la siguiente manera:
Almacenamiento en búfer de los datos en archivos temporales en tu bucket de Cloud Storage
Copiar los datos en una operación desde tu bucket de Cloud Storage a BigQuery
Borra los archivos temporales en Cloud Storage después de que se completa la operación de carga de BigQuery (los archivos temporales también se borran después de que finaliza la aplicación Spark). Si falla la eliminación, deberás borrar los archivos temporales no deseados de Cloud Storage, que suelen colocarse en
gs://YOUR_BUCKET/.spark-bigquery-JOB_ID-UUID.
Configura la facturación
De forma predeterminada, el proyecto asociado con las credenciales o la cuenta de servicio se factura por el uso de la API. Para facturar un proyecto diferente, establece la siguiente configuración: spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>").
También puedes agregarla a una operación de lectura o escritura, de la siguiente manera: .option("parentProject", "<BILLED-GCP-PROJECT>").
Envía una carga de trabajo por lotes de conteo de palabras de PySpark
Ejecuta una carga de trabajo por lotes de Spark que cuenta la cantidad de palabras en un conjunto de datos públicos.
- Abre una terminal local o Cloud Shell.
- Crea el
wordcount_datasetcon la herramienta de línea de comandos de bq en una terminal local o en Cloud Shell.bq mk wordcount_dataset
- Crea un bucket de Cloud Storage con Google Cloud CLI.
gcloud storage buckets create gs://YOUR_BUCKET
YOUR_BUCKETpor el nombre del bucket de Cloud Storage que creaste. - Copia el siguiente código de PySpark para crear el archivo
wordcount.pyde forma local en un editor de texto.#!/usr/bin/python """BigQuery I/O PySpark example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName('spark-bigquery-demo') \ .getOrCreate() # Use the Cloud Storage bucket for temporary BigQuery export data used # by the connector. bucket = "YOUR_BUCKET" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. words = spark.read.format('bigquery') \ .option('table', 'bigquery-public-data:samples.shakespeare') \ .load() words.createOrReplaceTempView('words') # Perform word count. word_count = spark.sql( 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word') word_count.show() word_count.printSchema() # Saving the data to BigQuery word_count.write.format('bigquery') \ .option('table', 'wordcount_dataset.wordcount_output') \ .save()
- Envía la carga de trabajo por lotes de PySpark:
gcloud dataproc batches submit pyspark wordcount.py \ --region=REGION \ --deps-bucket=YOUR_BUCKET
... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
Para obtener una vista previa de la tabla de salida en la consola de Google Cloud , abre la página de tu proyecto de BigQuery, selecciona la tablawordcount_outputy, luego, haz clic en Vista previa.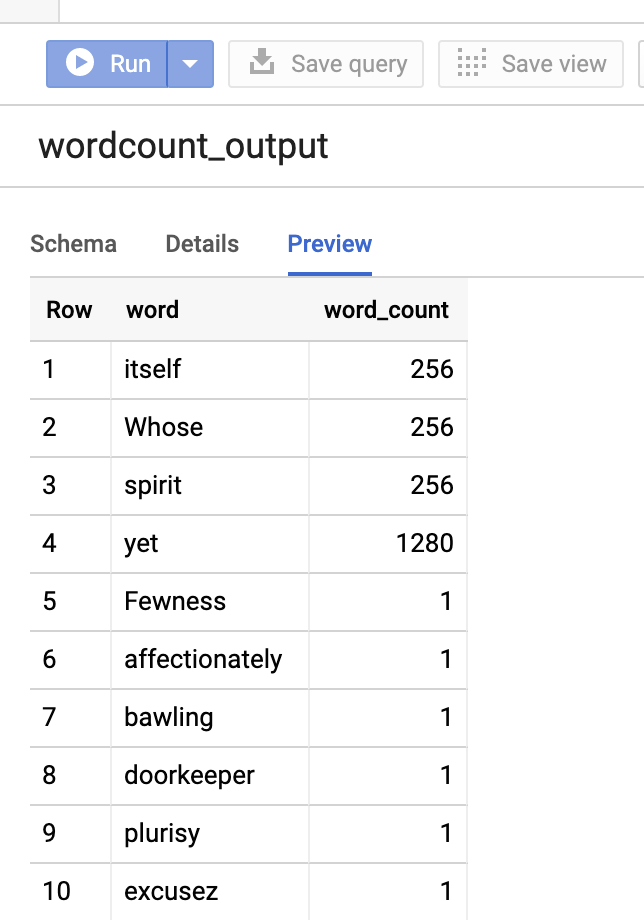
Más información
- BigQuery Storage y Spark SQL: Python
- Crea un archivo de definición de tablas para una fuente de datos externa
- Usa datos particionados de forma externa