적합 맞춤 기능은 Apache Beam 리소스 힌트를 사용하여 파이프라인의 작업자 리소스를 맞춤설정합니다. 여러 리소스를 특정 파이프라인 단계로 타겟팅하는 기능은 추가적인 파이프라인 유연성과 기능 및 잠재적인 비용 절감 효과를 제공합니다. 더 비싼 리소스가 필요한 파이프라인 단계에 이러한 리소스를 적용하고 다른 파이프라인 단계에는 보다 저렴한 리소스를 적용할 수 있습니다. 적합 맞춤을 사용하여 전체 파이프라인이나 특정 파이프라인 단계에 리소스 요구사항을 지정합니다.
지원 및 제한 사항
- 리소스 힌트는 Apache Beam Java 및 Python SDK 버전 2.31.0 이상에서 지원됩니다.
- 배치 파이프라인에서는 적합 맞춤이 지원됩니다.
수평 자동 확장이 사용 설정된 스트리밍 파이프라인에서는 적합 맞춤이 지원됩니다.
--experiments=enable_streaming_rightfitting파이프라인 옵션을 설정하여 사용 설정할 수 있습니다.
적합 맞춤은 Dataflow Prime을 지원합니다.
적합 맞춤은 FlexRS를 지원하지 않습니다.
적합 맞춤을 사용할 때는
worker_accelerator서비스 옵션을 사용하지 마세요.
적합 맞춤 사용 설정
적합 맞춤을 사용 설정하려면 파이프라인에서 사용 가능한 리소스 힌트를 하나 이상 사용합니다. 파이프라인에 리소스 힌트를 사용하면 적합 맞춤이 자동으로 사용 설정됩니다. 자세한 내용은 이 문서의 리소스 힌트 사용 섹션을 참조하세요.
사용 가능한 리소스 힌트
다음과 같은 리소스 힌트를 사용할 수 있습니다.
| 리소스 힌트 | 설명 |
|---|---|
min_ram |
작업자에 할당할 최소 RAM 양(GB)입니다. Dataflow Prime은 메모리를 새 작업자(수평 확장)나 기존 작업자(수직 확장)에 할당할 때 이 값을 하한값으로 사용합니다. 예를 들면 다음과 같습니다. min_ram=NUMBERGB
|
accelerator |
사용자가 제공하는 GPU 할당으로, 이를 사용하면 파이프라인과 해당 단계에서 GPU 사용 및 비용을 제어할 수 있습니다. 플래그에 대한 파라미터로 Dataflow 작업자에 연결할 GPU 유형과 수를 지정합니다. 예를 들면 다음과 같습니다. accelerator="type:GPU_TYPE;count:GPU_COUNT;machine_type:MACHINE_TYPE;CONFIGURATION_OPTIONS"
GPU 사용에 대한 자세한 내용은 Dataflow에서 GPU를 참조하세요. |
리소스 힌트 중첩
리소스 힌트는 다음과 같이 파이프라인 변환 계층 구조에 적용됩니다.
min_ram: 변환의 값은 변환 자체 및 변환의 계층 구조에 있는 모든 상위 항목에 설정된 값 사이의 가장 큰min_ram힌트 값으로 평가됩니다.- 예시: 내부 변환 힌트가
min_ram을 16GB로 설정하고, 계층 구조에서 외부 변환 힌트가min_ram을 32GB로 설정하는 경우, 전체 변환의 모든 단계에 32GB 힌트가 사용됩니다. - 예시: 내부 변환 힌트가
min_ram을 16GB로 설정하고 계층 구조의 외부 변환 힌트가min_ram을 8GB로 설정하는 경우 내부 변환에 없는 외부 변환의 모든 단계에 대해 8GB 힌트가 사용되고, 내부 변환의 모든 단계에 대해 16GB 힌트가 사용됩니다.
- 예시: 내부 변환 힌트가
accelerator: 변환 계층 구조의 가장 안쪽 값이 우선 적용됩니다.- 예시: 내부 변환
accelerator힌트가 계층 구조의 외부 변환accelerator힌트와 다르면 내부 변환에 대해 내부accelerator힌트가 사용됩니다.
- 예시: 내부 변환
전체 파이프라인에 설정된 힌트는 개별적으로 가장 바깥쪽 변환에 설정된 것처럼 취급됩니다.
리소스 힌트 사용
전체 파이프라인 또는 파이프라인 단계에 리소스 힌트를 설정할 수 있습니다.
파이프라인 리소스 힌트
명령줄에서 파이프라인을 실행할 때 전체 파이프라인에 리소스 힌트를 설정할 수 있습니다.
Python 환경을 설정하려면 Python 튜토리얼을 참고하세요.
예:
python my_pipeline.py \
--runner=DataflowRunner \
--resource_hints=min_ram=numberGB \
--resource_hints=accelerator="type:type;count:number;install-nvidia-driver" \
...
파이프라인 단계 리소스 힌트
파이프라인 단계(변환)의 리소스 힌트를 프로그래매틱 방식으로 설정할 수 있습니다.
자바
Java용 Apache Beam SDK를 설치하려면 Apache Beam SDK 설치를 참조하세요.
ResourceHints 클래스를 사용하여 파이프라인 변환에서 리소스 힌트를 프로그래매틱 방식으로 설정할 수 있습니다.
다음 예시에서는 파이프라인 변환에서 리소스 힌트를 프로그래매틱 방식으로 설정하는 방법을 보여줍니다.
pcoll.apply(MyCompositeTransform.of(...)
.setResourceHints(
ResourceHints.create()
.withMinRam("15GB")
.withAccelerator(
"type:nvidia-l4;count:1;install-nvidia-driver")))
pcoll.apply(ParDo.of(new BigMemFn())
.setResourceHints(
ResourceHints.create().withMinRam("30GB")))
전체 파이프라인에서 리소스 힌트를 프로그래매틱 방식으로 설정하려면 ResourceHintsOptions 인터페이스를 사용합니다.
Python
Python용 Apache Beam SDK를 설치하려면 Apache Beam SDK 설치를 참조하세요.
PTransforms.with_resource_hints 클래스를 사용하여 파이프라인 변환에서 리소스 힌트를 프로그래매틱 방식으로 설정할 수 있습니다.
자세한 내용은 ResourceHint 클래스를 참조하세요.
다음 예시에서는 파이프라인 변환에서 리소스 힌트를 프로그래매틱 방식으로 설정하는 방법을 보여줍니다.
pcoll | MyPTransform().with_resource_hints(
min_ram="4GB",
accelerator="type:nvidia-tesla-l4;count:1;install-nvidia-driver")
pcoll | beam.ParDo(BigMemFn()).with_resource_hints(
min_ram="30GB")
전체 파이프라인에 리소스 힌트를 설정하려면 파이프라인을 실행할 때 --resource_hints 파이프라인 옵션을 사용합니다. 예시는 파이프라인 리소스 힌트를 참조하세요.
Go
Go에서는 리소스 힌트가 지원되지 않습니다.
여러 가속기 지원
파이프라인 내에서 변환마다 가속기 구성이 다를 수 있습니다. 여기에는 서로 다른 머신 유형이 필요한 구성이 포함됩니다. 이러한 변환 수준 액셀러레이터 구성은 파이프라인 수준 구성이 제공된 경우 파이프라인 수준 구성보다 우선합니다.
적합 맞춤 및 융합
경우에 따라 여러 리소스 힌트로 설정된 변환은 융합 최적화 프로세스의 일부로 동일한 작업자 풀의 작업자에서 실행될 수 있습니다. 변환이 융합되면 Dataflow는 변환에 설정된 리소스 힌트의 통합을 충족하는 환경에서 변환을 실행합니다. 경우에 따라 전체 파이프라인이 포함됩니다.
리소스 힌트를 병합할 수 없으면 융합이 발생하지 않습니다. 예를 들어 서로 다른 GPU에 대한 리소스 힌트는 병합 가능하지 않으므로 해당 변환이 융합되지 않습니다.
Dataflow가 중간 PCollection을 강제로 구체화하도록 파이프라인에 작업을 추가하여 융합을 방지할 수도 있습니다. 이는 GPU나 메모리 부족 머신과 같은 비용이 많이 드는 리소스를 이러한 특수 리소스가 필요하지 않은 느리거나 계산 비용이 많이 드는 단계에서 격리하려고 할 때 특히 유용합니다. 이러한 경우 느린 CPU 바운드 단계와 고가의 GPU 또는 높은 메모리 머신이 필요한 단계 사이에 강제로 융합을 중단하고 융합 중단과 관련된 구체화 비용을 지불하는 것이 도움이 될 수 있습니다. 자세한 내용은 융합 방지를 참고하세요.
스트리밍 적합 맞춤
스트리밍 작업의 경우 --experiments=enable_streaming_rightfitting 파이프라인 옵션을 설정하여 적합 맞춤을 사용 설정할 수 있습니다.
다양한 리소스 요구사항이 있는 단계를 포함하는 경우 적합 맞춤을 통해 파이프라인의 성능을 개선할 수 있습니다.
예: CPU 집약적 단계와 GPU가 필요한 단계가 있는 파이프라인
적합 맞춤의 이점을 누릴 수 있는 파이프라인의 예는 CPU 집약적 단계를 실행한 후 GPU가 필요한 단계를 실행하는 파이프라인입니다. 적합 맞춤이 없으면 CPU 집약적 단계를 포함한 모든 파이프라인 단계를 실행하도록 단일 GPU 작업자 풀을 구성해야 합니다. 이로 인해 작업자 풀이 CPU 집약적 단계를 실행할 때 GPU 리소스가 충분히 활용되지 않을 수 있습니다.
적합 맞춤이 사용 설정되어 있고 리소스 힌트가 GPU가 필요한 단계에 적용되면 파이프라인에서 두 개의 별도 풀을 생성하므로 CPU 집약적 단계는 CPU 작업자 풀에서 실행되고 GPU가 필요한 단계는 GPU 작업자 풀에서 실행됩니다.
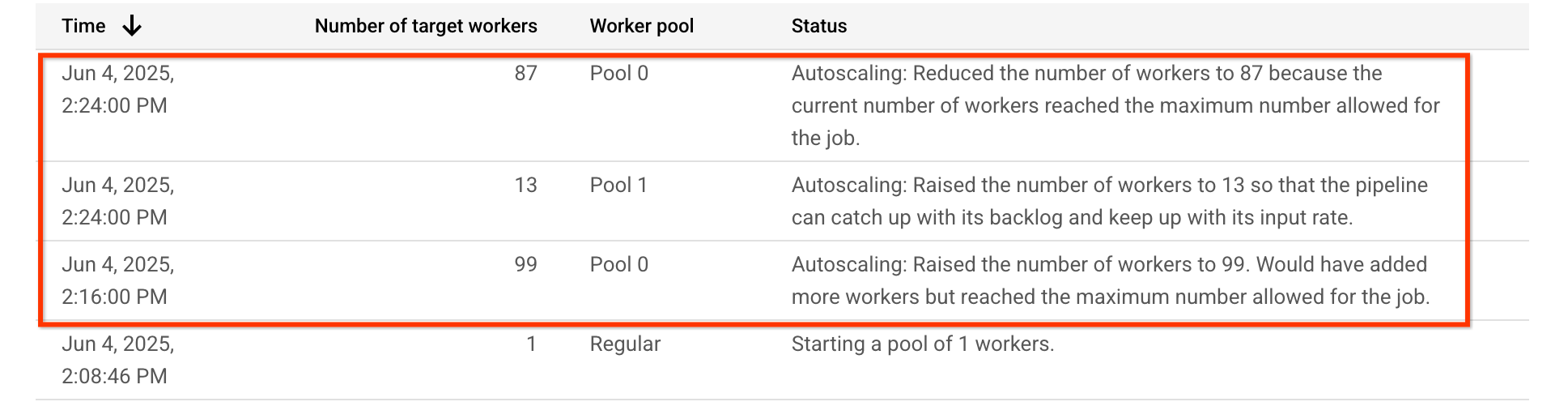
이 예시 파이프라인의 경우 자동 확장 표에 CPU 집약적 단계인 Pool 0을 실행하는 작업자 풀이 처음에는 작업자 99명으로 확장되고 나중에 작업자 87명으로 축소되는 것으로 표시됩니다. GPU가 필요한 단계를 실행하는 작업자 풀 Pool 1이 13개의 작업자로 스케일 업됩니다.
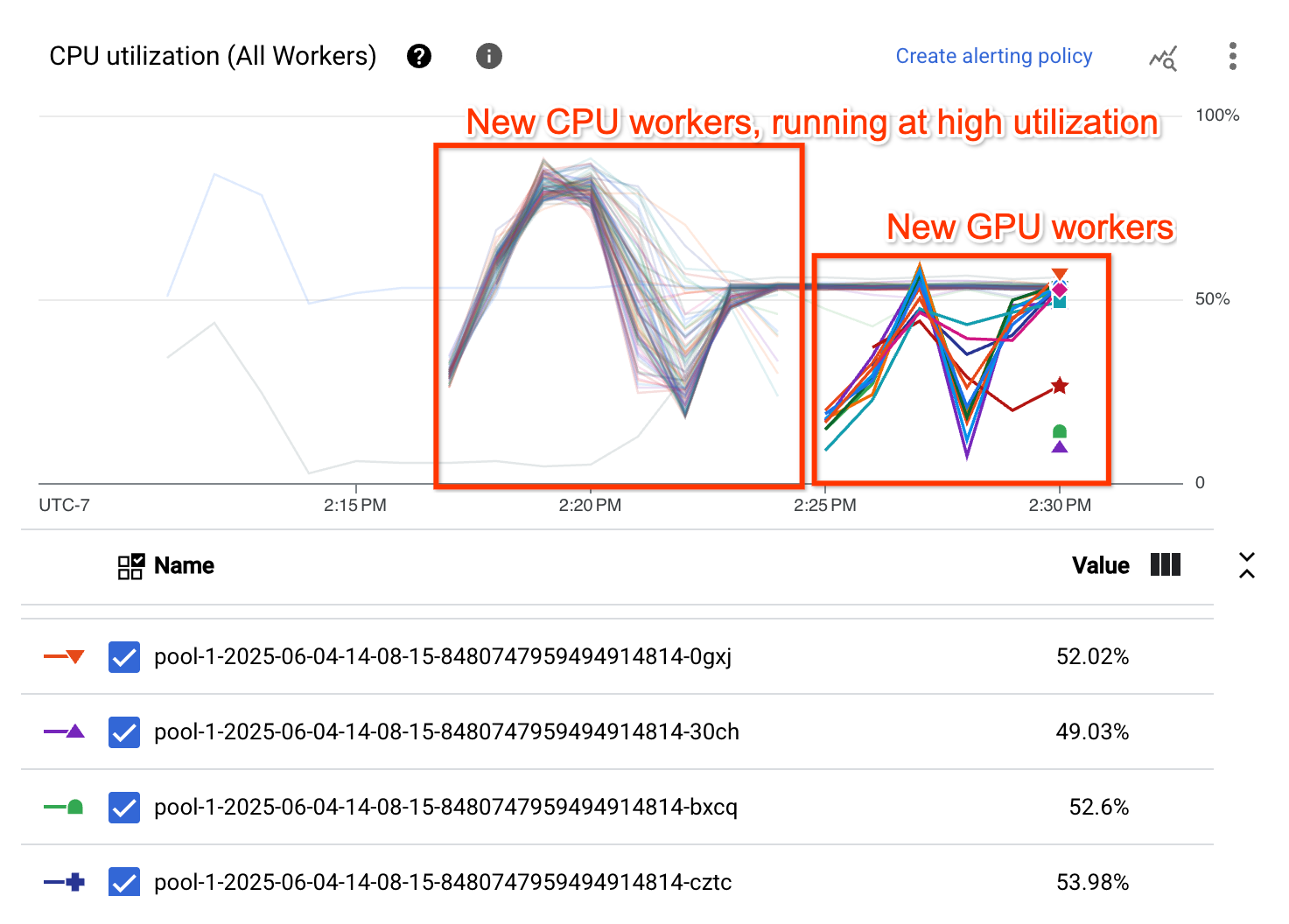
CPU 사용률 그래프는 두 작업자 풀의 작업자가 전반적으로 높은 CPU 사용률을 보임을 보여줍니다.
적합 맞춤 문제 해결
이 섹션에서는 적합 맞춤과 관련된 일반적인 문제를 해결하기 위한 지침을 제공합니다.
잘못된 구성
적합 맞춤을 사용하려고 하면 다음 오류가 발생합니다.
Workflow failed. Causes: One or more operations had an error: 'operation-OPERATION_ID':
[UNSUPPORTED_OPERATION] 'NUMBER vCpus with NUMBER MiB memory is
an invalid configuration for NUMBER count of 'GPU_TYPE' in family 'MACHINE_TYPE'.'.
이 오류는 선택한 GPU 유형이 선택한 머신 유형과 호환되지 않을 때 발생합니다. 이 오류를 해결하려면 호환되는 GPU 유형과 머신 유형을 선택합니다. 호환성에 대한 자세한 내용은 GPU 플랫폼을 참조하세요.
적합 맞춤 확인
자동 확장 측정항목을 확인하고 Worker pool 열이 표시되고 다양한 풀이 나열되는지 확인하여 적합 맞춤이 사용 설정되어 있는지 확인할 수 있습니다.
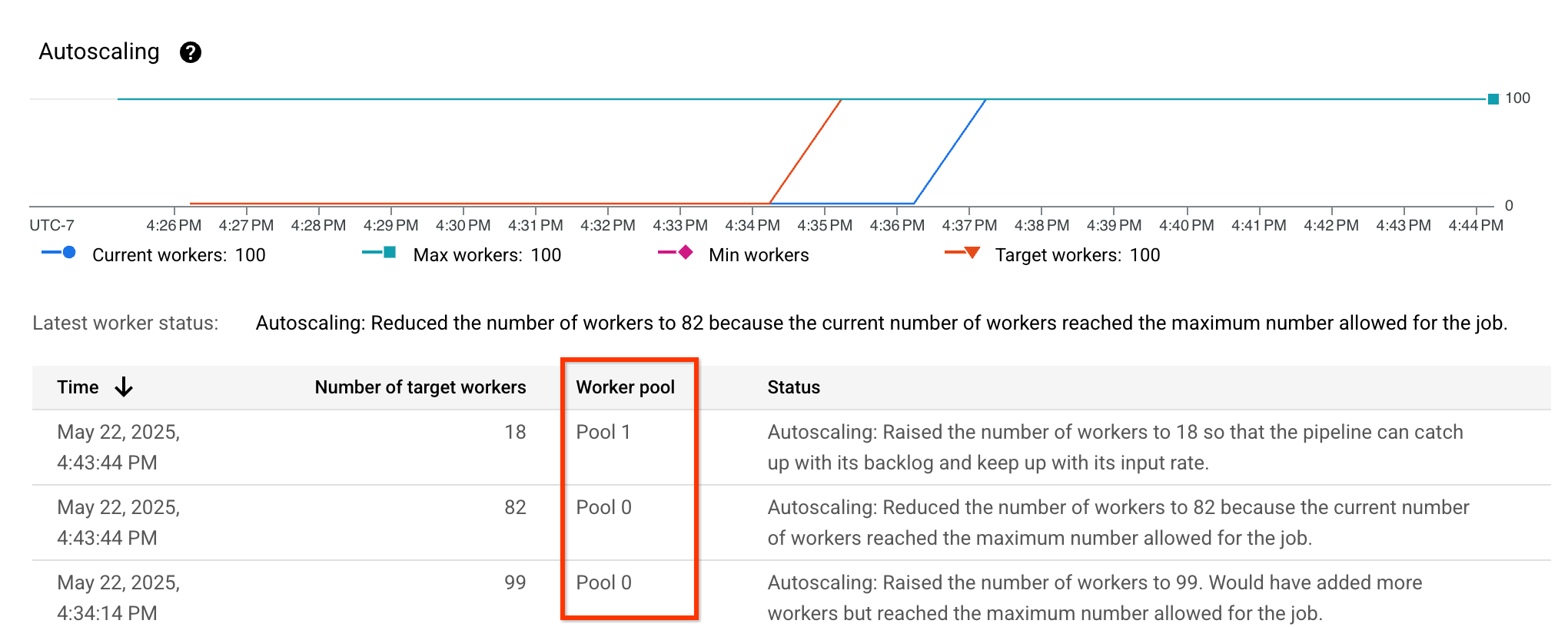
스트리밍 적합 맞춤 실적
적합 맞춤이 사용 설정된 스트리밍 파이프라인이 적합 맞춤이 사용 설정되지 않은 파이프라인보다 항상 더 나은 성능을 발휘하지는 않을 수 있습니다. 예를 들면 다음과 같습니다.
- 파이프라인에서 더 많은 작업자를 사용하는 경우
- 시스템 지연 시간이 높거나 처리량이 낮은 경우
- 작업자 풀 크기가 더 자주 변경되거나 안정화되지 않은 경우
파이프라인에서 이 문제가 발생하는 경우 --experiments=enable_streaming_rightfitting 파이프라인 옵션을 삭제하여 적합 맞춤을 사용 중지할 수 있습니다. 또한 액셀러레이터 리소스 힌트를 사용하여 적합 맞춤이 사용 설정된 스트리밍 파이프라인은 원하는 것보다 더 많은 액셀러레이터를 사용할 수 있습니다. 파이프라인에서 이 문제가 발생하는 경우 --experiments=max_num_accelerators=NUM 파이프라인 옵션을 설정하여 파이프라인에서 사용하는 최대 가속기 수를 구성할 수 있습니다.