This page outlines best practices to use when developing your Dataflow pipelines. Using these best practices has the following benefits:
- Improve pipeline observability and performance
- Improve developer productivity
- Enhance pipeline testability
The Apache Beam code examples on this page use Java, but the content applies to the Apache Beam Java, Python, and Go SDKs.
Questions to consider
When designing your pipeline, consider the following questions:
- Where is your pipeline's input data stored? How many sets of input data do you have?
- What does your data look like?
- What do you want to do with your data?
- Where should your pipeline's output data go?
- Does your Dataflow job use Assured Workloads?
Use templates
To accelerate pipeline development, instead of building a pipeline by writing Apache Beam code, use a Dataflow template when possible. Templates have the following benefits:
- Templates are reusable.
- Templates let you customize each job by changing specific pipeline parameters.
- Anyone you provide permissions to can use the template to deploy the pipeline. For example, a developer can create a job from a template, and a data scientist in the organization can deploy that template at a later time.
You can use a Google-provided template, or you can create your own template. Some Google-provided templates allow you to add custom logic as a pipeline step. For example, the Pub/Sub to BigQuery template provides a parameter to run a JavaScript user-defined function (UDF) that's stored in Cloud Storage.
Because Google-provided templates are open source under the Apache License 2.0, you can use them as the basis for new pipelines. The templates are also useful as code examples. View the template code in the GitHub repository.
Assured Workloads
Assured Workloads helps enforce security and compliance requirements for Google Cloud Platform customers. For example, EU Regions and Support with Sovereignty Controls helps enforce data residency and data sovereignty guarantees for EU-based customers. To provide these features, some Dataflow features are restricted or limited. If you use Assured Workloads with Dataflow, all of the resources that your pipeline accesses must be located in your organization's Assured Workloads project or folder. These resources include:
- Cloud Storage buckets
- BigQuery datasets
- Pub/Sub topics and subscriptions
- Firestore datasets
- I/O connectors
In Dataflow, for streaming jobs created after March 7, 2024, all user data is encrypted with CMEK.
For streaming jobs created before March 7, 2024, data keys used in key-based operations, such as windowing, grouping, and joining, are not protected by CMEK encryption. To enable this encryption for your jobs, drain or cancel the job, and then restart it. For more information, see Encryption of pipeline state artifacts.
Share data across pipelines
There is no Dataflow-specific cross pipeline communication mechanism for sharing data or processing context between pipelines. You can use durable storage like Cloud Storage or an in-memory cache like App Engine to share data between pipeline instances.
Schedule jobs
You can automate pipeline execution in the following ways:
- Use Cloud Scheduler.
- Use the Apache Airflow Dataflow Operator, one of several Google Cloud Platform Operators in a Cloud Composer workflow.
- Run custom (cron) job processes on Compute Engine.
Best practices for writing pipeline code
The following sections provide best practices to use when you create pipelines by writing Apache Beam code.
Structure your Apache Beam code
To create pipelines, it's common to use the generic
ParDo
parallel processing Apache Beam transform.
When you apply a ParDo transform, you provide code in the form of a
DoFn object. DoFn is an Apache Beam SDK class that defines a distributed
processing function.
You can think of your DoFn code as small, independent entities: there can
potentially be many instances running on different machines, each with no
knowledge of the others. As such, we recommend creating pure functions, which
are ideal for the parallel and distributed nature of DoFn elements.
Pure functions have the following characteristics:
- Pure functions don't depend on hidden or external state.
- They have no observable side effects.
- They are deterministic.
The pure function model is not strictly rigid. When your code doesn't depend on
things that aren't guaranteed by the Dataflow service, state
information or external initialization data can be valid for DoFn and other
function objects.
When structuring your ParDo transforms and creating your DoFn elements,
consider the following guidelines:
- When you use exactly-once processing,
the Dataflow service guarantees that every element in your
input
PCollectionis processed by aDoFninstance exactly once. - The Dataflow service doesn't guarantee how many times a
DoFnis invoked. - The Dataflow service doesn't guarantee exactly how the distributed elements are grouped. It does not guarantee which, if any, elements are processed together.
- The Dataflow service doesn't guarantee the exact number of
DoFninstances created over the course of a pipeline. - The Dataflow service is fault-tolerant and might retry your code multiple times if the workers encounter issues.
- The Dataflow service might create backup copies of your code. Issues might occur with manual side effects, such as if your code relies on or creates temporary files with non-unique names.
- The Dataflow service serializes element processing per
DoFninstance. Your code doesn't need to be strictly thread-safe, but any state shared between multipleDoFninstances must be thread-safe.
Create libraries of reusable transforms
The Apache Beam programming model lets you reuse transforms. By creating a shared library of common transforms, you can improve reusability, testability, and code ownership by different teams.
Consider the following two Java code examples, which both read payment events. Assuming that both pipelines perform the same processing, they can use the same transforms through a shared library for the remaining processing steps.
The first example is from an unbounded Pub/Sub source:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options)
// Initial read transform
PCollection<PaymentEvent> payments =
p.apply("Read from topic",
PubSubIO.readStrings().withTimestampAttribute(...).fromTopic(...))
.apply("Parse strings into payment events",
ParDo.of(new ParsePaymentEventFn()));
The second example is from a bounded relational database source:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
PCollection<PaymentEvent> payments =
p.apply(
"Read from database table",
JdbcIO.<PaymentEvent>read()
.withDataSourceConfiguration(...)
.withQuery(...)
.withRowMapper(new RowMapper<PaymentEvent>() {
...
}));
How you implement code reusability best practices varies by programming language and by build tool. For example, if you use Maven, you can separate transform code into its own module. You can then include the module as a submodule in larger multi-module projects for different pipelines, as shown in the following code example:
// Reuse transforms across both pipelines
payments
.apply("ValidatePayments", new PaymentTransforms.ValidatePayments(...))
.apply("ProcessPayments", new PaymentTransforms.ProcessPayments(...))
...
For more information, see the following Apache Beam documentation pages:
- Requirements for writing user code for Apache Beam transforms
PTransformstyle guide: a style guide for writers of new reusablePTransformcollections
Use dead-letter queues for error handling
Sometimes your pipeline can't process elements. Data issues are a common cause. For example, an element that contains badly formatted JSON can cause parsing failures.
Although you can catch exceptions within the
DoFn.ProcessElement
method, log the error, and drop the element, this approach both loses the data
and prevents the data from being inspected later for manual handling or troubleshooting.
Instead, use a pattern called a dead-letter queue (unprocessed messages queue).
Catch exceptions in the DoFn.ProcessElement method and log
errors. Instead of dropping the failed element,
use branching outputs to write failed elements into a separate PCollection
object. These elements are then written to a data sink for later inspection
and handling with a separate transform.
The following Java code example shows how to implement the dead-letter queue pattern.
TupleTag<Output> successTag = new TupleTag<>() {};
TupleTag<Input> deadLetterTag = new TupleTag<>() {};
PCollection<Input> input = /* ... */;
PCollectionTuple outputTuple =
input.apply(ParDo.of(new DoFn<Input, Output>() {
@Override
void processElement(ProcessContext c) {
try {
c.output(process(c.element()));
} catch (Exception e) {
LOG.severe("Failed to process input {} -- adding to dead-letter file",
c.element(), e);
c.sideOutput(deadLetterTag, c.element());
}
}).withOutputTags(successTag, TupleTagList.of(deadLetterTag)));
// Write the dead-letter inputs to a BigQuery table for later analysis
outputTuple.get(deadLetterTag)
.apply(BigQueryIO.write(...));
// Retrieve the successful elements...
PCollection<Output> success = outputTuple.get(successTag);
// and continue processing ...
Use Cloud Monitoring to apply different monitoring and alerting policies for your pipeline's dead-letter queue. For example, you can visualize the number and size of elements processed by your dead-letter transform and configure alerting to trigger if certain threshold conditions are met.
Handle schema mutations
You can handle data that has unexpected but valid schemas by using a dead-letter
pattern, which writes failed elements to a separate PCollection object.
In some cases, you want to automatically handle elements
that reflect a mutated schema as valid elements. For example, if an element's
schema reflects a mutation like the addition of new fields, you can adapt the
schema of the data sink to accommodate mutations.
Automatic schema mutation relies on the branching-output approach used by the dead-letter pattern. However, in this case it triggers a transform that mutates the destination schema whenever additive schemas are encountered. For an example of this approach, see How to handle mutating JSON schemas in a streaming pipeline, with Square Enix on the Google Cloud blog.
Decide how to join datasets
Joining datasets is a common use case for data pipelines. You can use
side inputs or the CoGroupByKey transform to perform joins in your pipeline.
Each has benefits and downsides.
Side inputs
provide a flexible way to solve common data processing problems, such as data
enrichment and keyed lookups. Unlike PCollection objects, side inputs are
mutable and can be determined at runtime. For example, the values in a
side input might be computed by another branch in your pipeline or determined by
calling a remote service.
Dataflow supports side inputs by persisting data into persistent storage, similar to a shared disk. This configuration makes the complete side input available to all workers.
However, side input sizes can be very large and might not fit into worker memory. Reading from a large side input can cause performance issues if workers need to constantly read from persistent storage.
The CoGroupByKey
transform is a
core Apache Beam transform
that merges (flattens) multiple PCollection objects and groups elements that
have a common key. Unlike a side input, which makes the entire side input data
available to each worker, CoGroupByKey performs a shuffle (grouping) operation
to distribute data across workers. CoGroupByKey is therefore ideal when the
PCollection objects that you want to join are very large and don't fit into worker
memory.
Follow these guidelines to help decide whether to use side inputs or
CoGroupByKey:
- Use side inputs when one of the
PCollectionobjects you are joining is disproportionately smaller than the others, and the smallerPCollectionobject fits into worker memory. Caching the side input entirely into memory makes it fast and efficient to fetch elements. - Use side inputs when you have a
PCollectionobject that must be joined multiple times in your pipeline. Instead of using multipleCoGroupByKeytransforms, create a single side input that can be reused by multipleParDotransforms. - Use
CoGroupByKeyif you need to fetch a large proportion of aPCollectionobject that significantly exceeds worker memory.
For more information, see Troubleshoot Dataflow out of memory errors.
Minimize expensive per-element operations
A DoFn instance processes batches of elements called
bundles,
which are atomic units of work that consist of zero or more
elements. Individual elements are then processed by the
DoFn.ProcessElement
method, which runs for every element. Because the DoFn.ProcessElement
method is called for every element, any time-consuming or computationally
expensive operations that are invoked by that method
run for every single element processed by the method.
If you need to perform costly operations only once for a batch of elements,
include those operations in the DoFn.Setup method or the DoFn.StartBundle
method instead of in the DoFn.ProcessElement element. Examples include the
following operations:
Parsing a configuration file that controls some aspect of the
DoFninstance's behavior. Only invoke this action one time, when theDoFninstance is initialized, by using theDoFn.Setupmethod.Instantiating a short-lived client that is reused across all elements in a bundle, such as when all elements in the bundle are sent over a single network connection. Invoke this action one time per bundle by using the
DoFn.StartBundlemethod.
Limit batch sizes and concurrent calls to external services
When you call external services, you can reduce per-call overheads by using the
GroupIntoBatches
transform. This transform creates batches of elements of a specified size.
Batching sends elements to an external service as one payload instead of
individually.
In combination with batching, limit the maximum number of parallel (concurrent) calls to the external service by choosing appropriate keys to partition the incoming data. The number of partitions determines the maximum parallelization. For example, if every element is given the same key, a downstream transform for calling the external service doesn't run in parallel.
Consider one of the following approaches to produce keys for elements:
- Choose an attribute of the dataset to use as data keys, such as user IDs.
- Generate data keys to split elements randomly over a fixed number of
partitions, where the number of possible key values determines the number
of partitions. You need to create enough partitions for parallelism.
Each partition needs to have enough elements for the
GroupIntoBatchestransform to be useful.
The following Java code example shows how to randomly split elements over ten partitions:
// PII or classified data which needs redaction.
PCollection<String> sensitiveData = ...;
int numPartitions = 10; // Number of parallel batches to create.
PCollection<KV<Long, Iterable<String>>> batchedData =
sensitiveData
.apply("Assign data into partitions",
ParDo.of(new DoFn<String, KV<Long, String>>() {
Random random = new Random();
@ProcessElement
public void assignRandomPartition(ProcessContext context) {
context.output(
KV.of(randomPartitionNumber(), context.element()));
}
private static int randomPartitionNumber() {
return random.nextInt(numPartitions);
}
}))
.apply("Create batches of sensitive data",
GroupIntoBatches.<Long, String>ofSize(100L));
// Use batched sensitive data to fully utilize Redaction API,
// which has a rate limit but allows large payloads.
batchedData
.apply("Call Redaction API in batches", callRedactionApiOnBatch());
Identify performance issues caused by fused steps
Dataflow builds a graph of steps that represents your pipeline based on the transforms and data that you used to construct it. This graph is called the pipeline execution graph.
When you deploy your pipeline, Dataflow might modify
your pipeline's execution graph to improve performance. For example, Dataflow
might fuse some operations together, a process known as
fusion optimization,
to avoid the performance and cost impact of writing every intermediate
PCollection object in your pipeline.
In some cases, Dataflow might incorrectly determine the optimal way to fuse operations in the pipeline, which can limit your job's ability to make use of all available workers. In those cases, you can prevent operations from being fused.
Consider the following example Apache Beam code. A
GenerateSequence
transform creates a small bounded PCollection object, which is then further
processed by two downstream ParDo transforms.
The Find Primes Less-than-N transform might be computationally expensive and is
likely to run slowly for large numbers. In contrast, the
Increment Number transform probably completes quickly.
import com.google.common.math.LongMath;
...
public class FusedStepsPipeline {
final class FindLowerPrimesFn extends DoFn<Long, String> {
@ProcessElement
public void processElement(ProcessContext c) {
Long n = c.element();
if (n > 1) {
for (long i = 2; i < n; i++) {
if (LongMath.isPrime(i)) {
c.output(Long.toString(i));
}
}
}
}
}
public static void main(String[] args) {
Pipeline p = Pipeline.create(options);
PCollection<Long> sequence = p.apply("Generate Sequence",
GenerateSequence
.from(0)
.to(1000000));
// Pipeline branch 1
sequence.apply("Find Primes Less-than-N",
ParDo.of(new FindLowerPrimesFn()));
// Pipeline branch 2
sequence.apply("Increment Number",
MapElements.via(new SimpleFunction<Long, Long>() {
public Long apply(Long n) {
return ++n;
}
}));
p.run().waitUntilFinish();
}
}
The following diagram shows a graphical representation of the pipeline in the Dataflow monitoring interface.
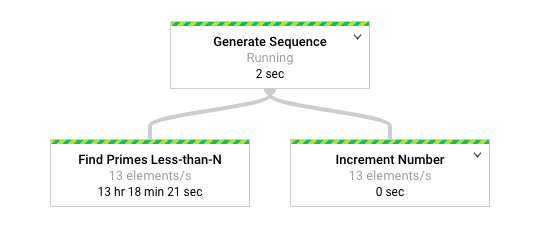
The
Dataflow monitoring interface
shows that the same slow rate of processing occurs for both transforms, specifically 13
elements-per-second. You might expect the Increment Number transform to process
elements quickly, but instead it appears to be tied to the same rate of
processing as Find Primes Less-than-N.
The reason is that Dataflow fused the steps into a single
stage, which prevents them from running independently. You can use the
gcloud dataflow jobs describe
command to find more information:
gcloud dataflow jobs describe --full job-id --format json
In the resulting output, the fused steps are described in the
ExecutionStageSummary
object in the
ComponentTransform
array:
...
"executionPipelineStage": [
{
"componentSource": [
...
],
"componentTransform": [
{
"name": "s1",
"originalTransform": "Generate Sequence/Read(BoundedCountingSource)",
"userName": "Generate Sequence/Read(BoundedCountingSource)"
},
{
"name": "s2",
"originalTransform": "Find Primes Less-than-N",
"userName": "Find Primes Less-than-N"
},
{
"name": "s3",
"originalTransform": "Increment Number/Map",
"userName": "Increment Number/Map"
}
],
"id": "S01",
"kind": "PAR_DO_KIND",
"name": "F0"
}
...
In this scenario, because the Find Primes Less-than-N transform is the slow step,
breaking the fusion before that step is an appropriate strategy. One method to
unfuse steps is to insert a
GroupByKey
transform and ungroup before the step, as shown in the following Java code
example.
sequence
.apply("Map Elements", MapElements.via(new SimpleFunction<Long, KV<Long, Void>>() {
public KV<Long, Void> apply(Long n) {
return KV.of(n, null);
}
}))
.apply("Group By Key", GroupByKey.<Long, Void>create())
.apply("Emit Keys", Keys.<Long>create())
.apply("Find Primes Less-than-N", ParDo.of(new FindLowerPrimesFn()));
You can also combine these unfusing steps into a reusable composite transform.
After you unfuse the steps, when you run the pipeline, Increment Number
completes in a matter of seconds, and the much longer-running
Find Primes Less-than-N transform runs in a separate stage.
This example applies a group and ungroup operation to unfuse steps.
You can use other approaches for other circumstances. In this case, handling
duplicate output is not an issue, given the consecutive output of the
GenerateSequence transform.
KV
objects with duplicate keys are deduplicated to a single key in the group
(GroupByKey) transform
and the ungroup
(Keys)
transform. To retain duplicates after the group and ungroup operations,
create key-value pairs by using the following steps:
- Use a random key and the original input as the value.
- Group using the random key.
- Emit the values for each key as the output.
You can also use a
Reshuffle
transform to prevent fusion of surrounding transforms. However, the side effects of the
Reshuffle transform are not portable across different
Apache Beam runners.
For more information about parallelism and fusion optimization, see Pipeline lifecycle.
Use Apache Beam metrics to collect pipeline insights
Apache Beam metrics is a utility class that produces metrics for reporting the properties of a running pipeline. When you use Cloud Monitoring, Apache Beam metrics are available as Cloud Monitoring custom metrics.
The following example shows Apache Beam
Counter metrics
used in a DoFn subclass.
The example code uses two counters. One counter tracks JSON parsing failures
(malformedCounter), and the other counter tracks whether the JSON message is
valid but contains an empty payload (emptyCounter). In Cloud Monitoring,
the custom metric names are custom.googleapis.com/dataflow/malformedJson and
custom.googleapis.com/dataflow/emptyPayload. You can use the custom metrics
to create visualizations and alerting policies in Cloud Monitoring.
final TupleTag<String> errorTag = new TupleTag<String>(){};
final TupleTag<MockObject> successTag = new TupleTag<MockObject>(){};
final class ParseEventFn extends DoFn<String, MyObject> {
private final Counter malformedCounter = Metrics.counter(ParseEventFn.class, "malformedJson");
private final Counter emptyCounter = Metrics.counter(ParseEventFn.class, "emptyPayload");
private Gson gsonParser;
@Setup
public setup() {
gsonParser = new Gson();
}
@ProcessElement
public void processElement(ProcessContext c) {
try {
MyObject myObj = gsonParser.fromJson(c.element(), MyObject.class);
if (myObj.getPayload() != null) {
// Output the element if non-empty payload
c.output(successTag, myObj);
}
else {
// Increment empty payload counter
emptyCounter.inc();
}
}
catch (JsonParseException e) {
// Increment malformed JSON counter
malformedCounter.inc();
// Output the element to dead-letter queue
c.output(errorTag, c.element());
}
}
}
Learn more
The following pages provide more information about how to structure your pipeline, how to choose which transforms to apply to your data, and what to consider when choosing your pipeline's input and output methods.
For more information about building your user code, see the
requirements for user-provided functions.