Cortex für Meridian
Auf dieser Seite wird der Prozess der Datenvorbereitung und Cloud-Automatisierung für Google Meridian beschrieben. Cortex Framework für Meridian optimiert die Open-Source-Marketing-Mix-Modellierung (MMM) mit Media- und Verkaufsdaten. Cortex Framework vereinfacht diesen Prozess durch die Bereitstellung vorkonfigurierter Datenmodelle und die Automatisierung der Ausführung von Meridian-Open-Source-Modellen mit Google Cloud Diensten wie Colab Enterprise und Workflows.
Einer der wichtigsten Vorteile des Google Cloud Cortex Framework ist die Bereitstellung einer Daten- und KI-Grundlage für die nächste Generation von Unternehmensinformationen, die Analysen in wichtigen Bereichen wie Vertrieb, Marketing, Auftragsabwicklung und Bestandsverwaltung ermöglicht.
Das Cortex Framework für Marketing bietet plattformübergreifende Media-KPIs und ‑Messwerte. Diese Messwerte sind ein wichtiger Bestandteil des Schritts zur Vorbereitung der Daten vor der Modellierung für das neueste Open-Source-MMM von Google namens Meridian. Werbetreibende, Agenturen und Partner können die Datenvorbereitung vor der Modellierung mit Google Cloud Cortex Framework Data Foundation beschleunigen.
Cortex for Meridian vereinfacht die Vormodellierung, indem Daten aus wichtigen Cortex Framework-Datenquellen effizient erfasst und transformiert werden. Dazu gehören:
Weitere Informationen finden Sie in der Meridian-Dokumentation.
Konfigurationsdatei
Während der Notebook-Ausführung ruft das System Konfigurationsparameter aus der Datei cortex_meridian_config.json ab, die sich im Ordner configuration in Cloud Storage befindet.
Im folgenden Abschnitt finden Sie verschiedene Beispiele für YAML-Konfigurationsdateien für die Meridian-Ausführung:
Vertrieb
Beispiel für eine YAML-Konfigurationsdatei für Umsatz als KPI:
{
"cortex_bq_project_id": "PROJECT_ID",
"cortex_meridian_marketing_data_set_id": "K9_REPORTING",
"cortex_meridian_marketing_view_name": "CrossMediaSalesInsightsWeeklyAgg",
"column_mappings": {
"controls": [],
"geo": "geo",
"kpi": "number_of_sales_orders",
"media": [
"Tiktok_impression",
"Meta_impression",
"YouTube_impression",
"GoogleAds_impression"
],
"media_spend": [
"Tiktok_spend",
"Meta_spend",
"YouTube_spend",
"GoogleAds_spend"
],
"population": "population",
"revenue_per_kpi": "average_revenue_per_sales_order",
"time": "time"
},
"channel_names": [
"TikTok",
"Meta",
"YouTube",
"GoogleAds"
],
"data_processing": {
"kpi_type": "{USE_CASE_SPECIFIC}",
"roi_mu": {USE_CASE_SPECIFIC},
"roi_sigma": {USE_CASE_SPECIFIC},
"sample": {
"prior": {USE_CASE_SPECIFIC},
"posterior": {
"n_chains": {USE_CASE_SPECIFIC},
"n_adapt": {USE_CASE_SPECIFIC},
"n_burnin": {USE_CASE_SPECIFIC},
"n_keep": {USE_CASE_SPECIFIC}
}
}
}
}
Conversions
Beispiele für YAML-Konfigurationsdateien für Conversions als KPIs:
...
"kpi": "conversions",
"revenue_per_kpi": "",
...
In der folgenden Tabelle wird der Wert für jeden Konfigurationsparameter aus der Datei cortex_meridian_config.json beschrieben:
| Parameter | Bedeutung | Standardwert | Beschreibung |
cortex_bq_project_id
|
Projekt mit den Cortex Framework-Datasets. | {PROJECT_ID}
|
Die Google Cloud Projekt-ID. |
cortex_meridian_marketing_data_set_id
|
BigQuery-Dataset mit Cortex for Meridian-Ansicht. | Der Konfigurationswert von k9.datasets.reporting in der Datei config.json.
|
Das Dataset, das die Ansicht cortex_meridian_marketing_view_name enthält.
|
cortex_meridian_marketing_view_name
|
BigQuery-Ansicht mit Cortex für Marketingdaten und Verkäufe von Meridian. | "CrossMediaSalesInsightsWeeklyAgg"
|
Die Ansicht mit wöchentlich aggregierten Marketing- und Verkaufsdaten. |
column_mappings.controls
|
Optional: Sie kann die Störfaktoren enthalten, die sowohl eine kausale Wirkung auf den Ziel-KPI als auch auf den Media-Messwert haben. | []
|
Weitere Informationen zu Kontrollvariablen für die Datenmodellierung in Meridian finden Sie unter Kontrollvariablen. |
column_mappings.geo
|
Die Spalten mit geografischen Informationen. | "geo"
|
Weitere Informationen zur Datenmodellierung in Meridian finden Sie unter Daten erheben und organisieren. |
column_mappings.kpi
|
Der Ziel-KPI für das Modell. | "number_of_sales_orders" oder „conversions" “.
|
Weitere Informationen zur Datenmodellierung in Meridian finden Sie unter Daten erheben und organisieren. |
column_mappings.media
|
Array von Spalten mit Impressionen für den Channel. | [
"Tiktok_impression",
|
Weitere Informationen zur Datenmodellierung in Meridian finden Sie unter Daten erheben und organisieren. |
column_mappings.media_spend
|
Spalten mit Ausgaben für den Channel. | [
"Tiktok_spend",
|
Weitere Informationen zur Datenmodellierung in Meridian finden Sie unter Daten erheben und organisieren. |
column_mappings.population
|
Die Grundgesamtheit für jede geografische Einheit. | "population"
|
Weitere Informationen zur Datenmodellierung in Meridian finden Sie unter Daten erheben und organisieren. |
column_mappings.revenue_per_kpi
|
Der durchschnittliche Umsatz für eine KPI-Einheit. | "average_revenue_per_sales_order" oder ""
|
Weitere Informationen zur Datenmodellierung in Meridian finden Sie unter Daten erheben und organisieren. |
column_mappings.time
|
Die Zeitspalte – Wochenbeginn (Montag). | "time"
|
Weitere Informationen zur Datenmodellierung in Meridian finden Sie unter Daten erheben und organisieren. |
channel_names
|
Array mit Channelnamen. | [
"TikTok",
|
Die Namen, die für den Channel-Index verwendet werden, sollten mit column_mappings.media und column_mappings.media_spend übereinstimmen.
|
data_processing.kpi_type
|
Der KPI kann entweder ein umsatzbezogener oder ein anderer (nicht umsatzbezogener) KPI sein. Ein nicht umsatzbezogener KPI-Typ kann auch dann verwendet werden, wenn Umsatz letztendlich der KPI ist. | "{USE_CASE_SPECIFIC}"
|
Weitere Informationen zur Datenmodellierung für KPI in Meridian finden Sie unter KPI. |
data_processing.roi_mu
|
Die Prior-Verteilung für den ROI der einzelnen Media-Channels. roi_mu
(wird mit ROI_M im Notebook verwendet).
|
{USE_CASE_SPECIFIC}
|
Weitere Informationen zur Meridian-Datenverarbeitung finden Sie unter Modell konfigurieren und in der API-Referenz. |
data_processing.roi_sigma
|
Die Prior-Verteilung für den ROI der einzelnen Media-Channels roi_sigma (wird mit ROI_M im Notebook verwendet).
|
{USE_CASE_SPECIFIC}
|
Weitere Informationen zur Meridian-Datenverarbeitung finden Sie unter Modell konfigurieren und API-Referenz. |
data_processing.sample.prior
|
Anzahl der Stichproben, die aus der Prior-Verteilung gezogen werden. | {USE_CASE_SPECIFIC}
|
Weitere Informationen zur Datenverarbeitung in Meridian finden Sie unter Standardparameterisierungen für Priors und in der API-Referenz. |
data_processing.sample.posterior.n_chains
|
Anzahl der MCMC-Ketten. | {USE_CASE_SPECIFIC}
|
Weitere Informationen zur Meridian-Datenverarbeitung finden Sie unter Modell konfigurieren und API-Referenz. |
data_processing.sample.posterior.n_adapt
|
Anzahl der Anpassungsziehungen pro Kette. | {USE_CASE_SPECIFIC}
|
Weitere Informationen zur Meridian-Datenverarbeitung finden Sie unter Modell konfigurieren und API-Referenz. |
data_processing.sample.posterior.n_burnin
|
Anzahl der Burn-in-Ziehungen pro Kette. | {USE_CASE_SPECIFIC}
|
Weitere Informationen zur Meridian-Datenverarbeitung finden Sie unter Modell konfigurieren und API-Referenz. |
data_processing.sample.posterior.n_keep
|
Anzahl der Ziehungen pro Kette, die für die Inferenz beibehalten werden sollen. | {USE_CASE_SPECIFIC}
|
Weitere Informationen zur Meridian-Datenverarbeitung finden Sie unter Modell konfigurieren und API-Referenz. |
Kompatibilität mit Meridian
Cortex Framework Data Foundation und Meridian werden separat veröffentlicht. Die Versionshinweise zum Cortex Framework enthalten eine Übersicht über die Releases und Versionen. Im GitHub-Repository von Meridian finden Sie die neuesten verfügbaren Meridian-Versionen. Voraussetzungen und Systemempfehlungen für Meridian finden Sie im Meridian-Nutzerhandbuch.
Cortex Framework Data Foundation-Releases werden mit einer bestimmten Version von Meridian getestet. Das kompatible Meridian finden Sie im Jupyter-Notebook, wie im folgenden Bild dargestellt:

Wenn Sie auf eine neuere Meridian-Version aktualisieren möchten, ändern Sie die entsprechende Zeile im Notebook. Möglicherweise sind zusätzliche Codeanpassungen im Notebook erforderlich.
Datenmodell
In diesem Abschnitt wird das CrossMediaSalesInsightsWeeklyAgg-Datenmodell anhand des Entity-Relationship-Diagramms (ERD) beschrieben.
Cortex für Meridian basiert auf einer einzelnen Ansicht, CrossMediaSalesInsightsWeeklyAgg. Die Datenquelle für diese Ansicht wird durch die Konfigurationseinstellung k9.Meridian.salesDataSourceType bestimmt. Mögliche Werte sind:
BYOD(Bring Your Own Data): Benutzerdefinierte Datenintegration.SAP_SALES: Verkaufsdaten aus SAP-Systemen.ORACLE_SALES: Verkaufsdaten aus Oracle EBS-Systemen.
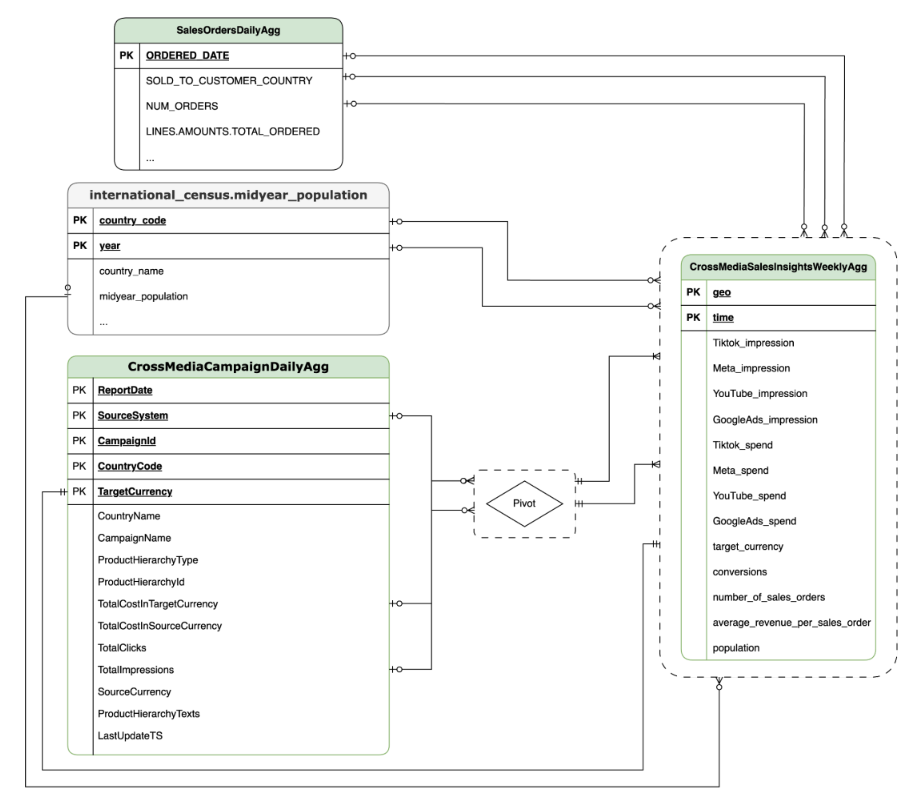
Im folgenden Abschnitt finden Sie die Entity-Relationship-Diagramme für CrossMediaForMeridian:
BYOD
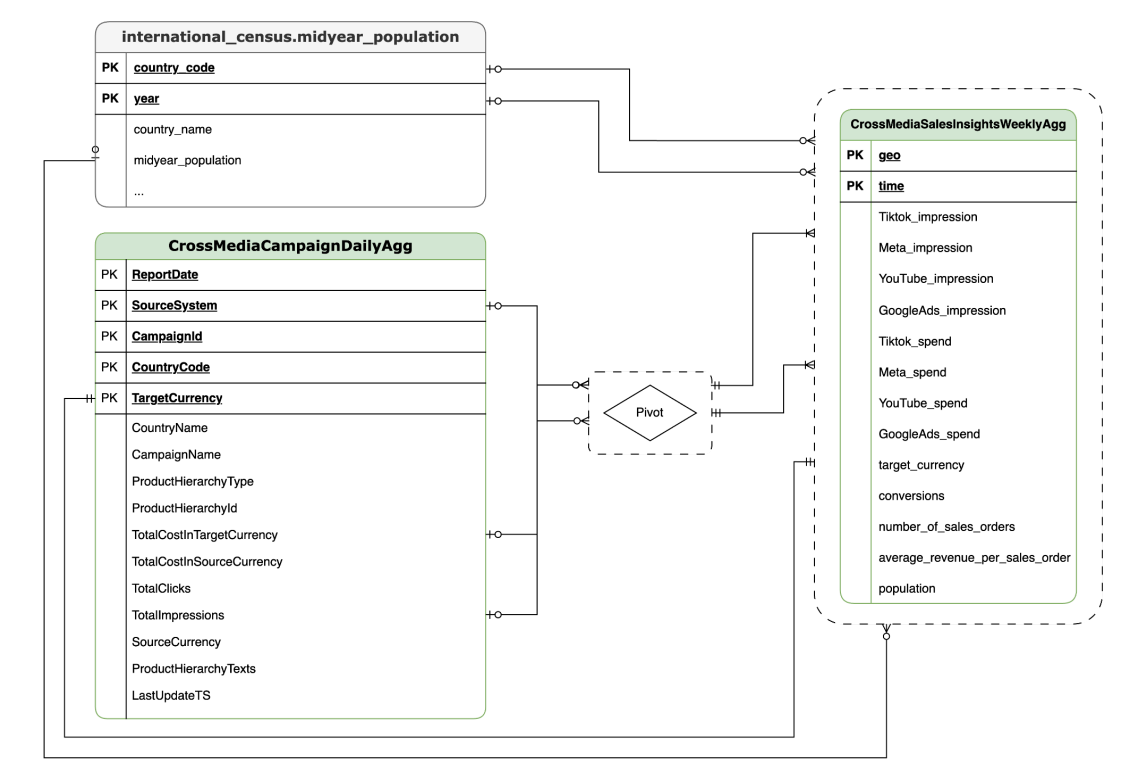
CortexForMeridian ohne Umsatzdaten.SAP
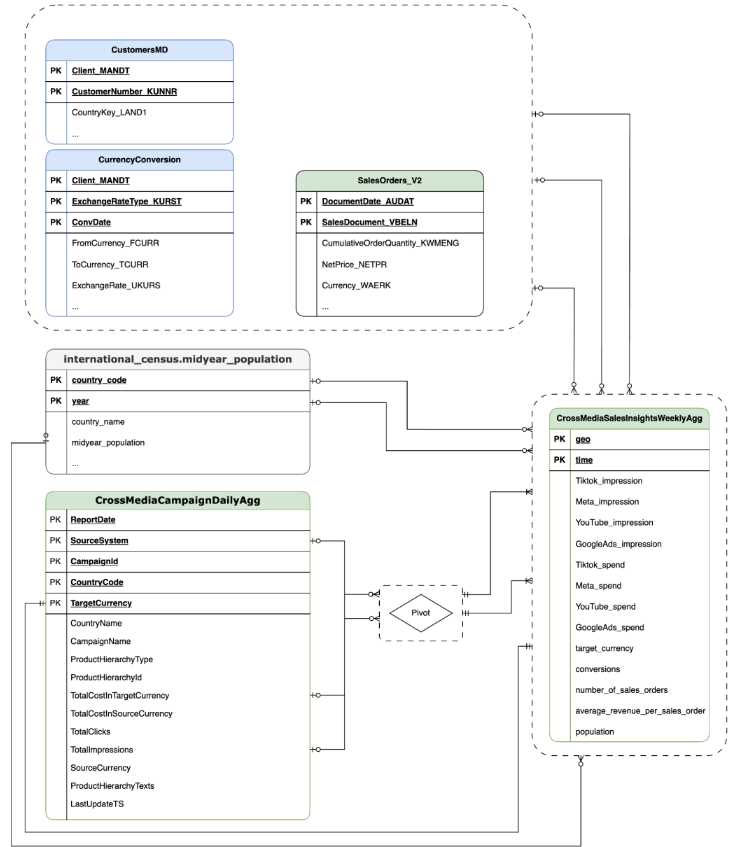
CortexForMeridian mit SAP-Daten.OracleEBS
CortexForMeridian mit Oracle EBS-Daten.In der folgenden Tabelle sehen Sie das detaillierte Schema für die Ansicht CrossMediaSalesInsightsWeeklyAgg, die Teil von Cortex für Meridian ist:
| Spalte | Typ | Beschreibung |
| geo | String | Das geografische Gebiet, das zum Aggregieren aller anderen Werte verwendet wird. |
| Zeit | String | Die Zeitdimension, mit der alle anderen Werte aggregiert werden. |
| Tiktok_impression | Integer | Gibt an, wie oft Ihre Anzeigen auf TikTok ausgeliefert wurden. |
| Meta_impression | Integer | Gibt an, wie oft Ihre Anzeigen auf Meta ausgeliefert wurden. |
| YouTube_impression | Integer | Gibt an, wie oft Ihre Anzeigen auf YouTube ausgeliefert wurden. |
| GoogleAds_impression | Integer | Gibt an, wie oft Ihre Anzeigen in Google Ads ausgeliefert wurden. |
| Tiktok_spend | Float | Der Betrag, der für Werbung auf TikTok ausgegeben wurde. |
| Meta_spend | Float | Der Betrag, der für Werbung auf Meta ausgegeben wurde. |
| YouTube_spend | Float | Der Betrag, der für Werbung auf YouTube ausgegeben wurde. |
| GoogleAds_spend | Float | Der Betrag, der für Werbung in Google Ads ausgegeben wurde. |
| target_currency | String | Zielwährung, die für alle Umsatzspalten verwendet wird. |
| Conversions | Integer | Conversions. |
| number_of_sales_orders | Integer | Anzahl der Verkaufsaufträge aus Oracle EBS oder SAP. |
| average_revenue_per_sales_order | Float | Durchschnittlicher Umsatz pro Kundenauftrag aus Oracle EBS oder SAP. |
| Bevölkerung | Integer | Bevölkerungsgröße der geografischen Einheit. |
Bereitstellung
Auf dieser Seite wird beschrieben, wie Sie das Cortex Framework für Meridian bereitstellen, um in Ihrer Google Cloud -Umgebung die beste MMM-Lösung zu erhalten.
Eine Kurzanleitung finden Sie unter Kurzanleitung für Meridian.
Architektur
Cortex for Meridian verwendet Cortex Framework für Marketing und Cross-Media-Daten in Kombination mit Verkaufsdaten. Sie können Vertriebsdaten aus Oracle EBS, SAP oder einem anderen Quellsystem importieren.
Das folgende Diagramm zeigt die wichtigsten Komponenten von Cortex für Meridian:
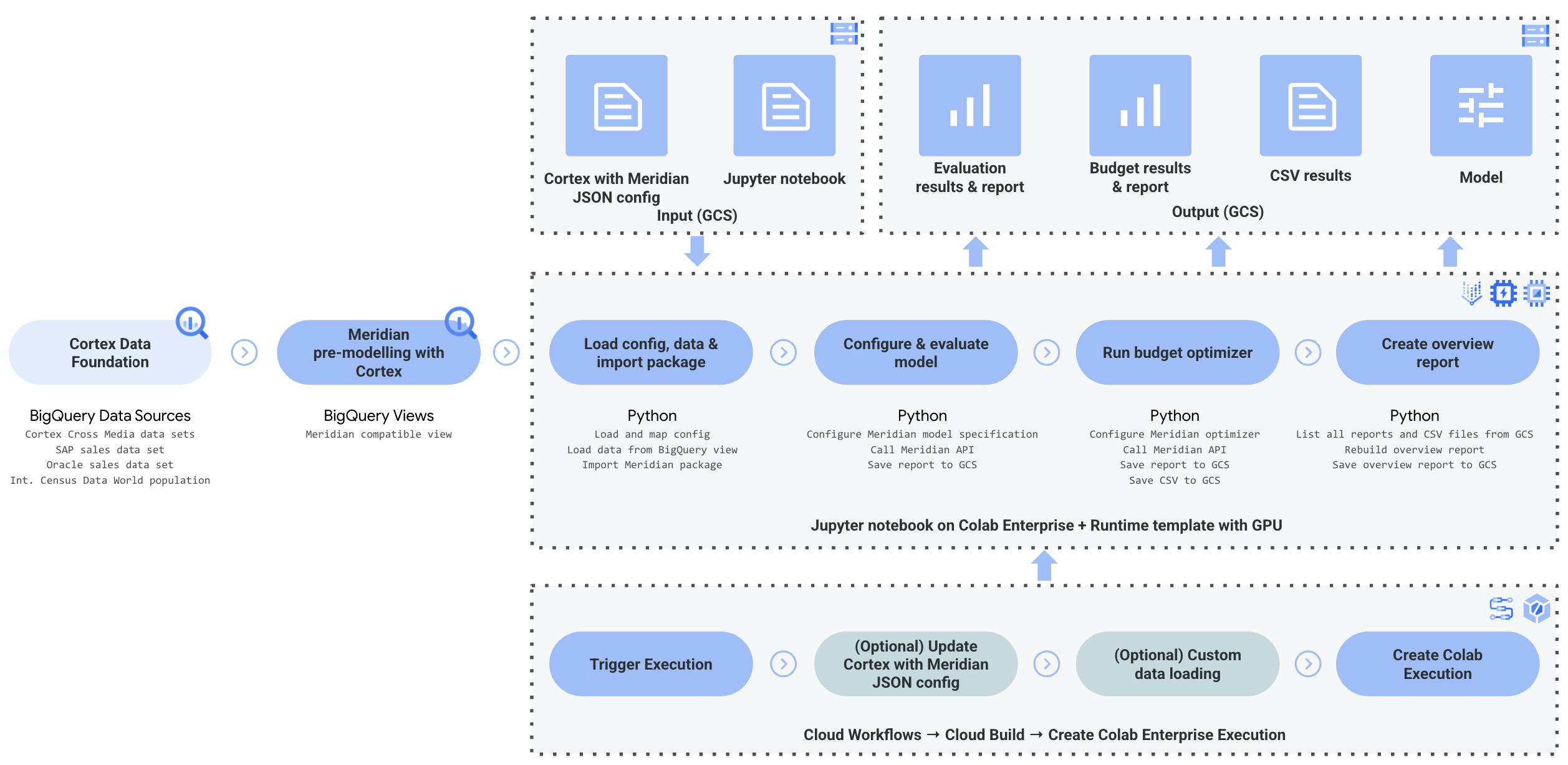
Meridian-Komponenten und -Dienste
Während der Bereitstellung von Cortex Framework Data Foundation (siehe Voraussetzungen für die Bereitstellung) können Sie Cortex für Meridian aktivieren, indem Sie in der Datei config.json deployMeridian auf true festlegen. Mit dieser Option wird eine zusätzliche Cloud Build-Pipeline gestartet, in der die folgenden für Meridian erforderlichen Komponenten und Dienste installiert werden:
BigQuery-Ansicht: Im K9-Berichtsdataset wird eine Ansicht mit dem Namen
CrossMediaSalesInsightsWeeklyAggerstellt. So können Sie Marketing- und Verkaufsdaten aus Cortex Framework abfragen. Die tatsächliche Implementierung der Ansicht und der zugrunde liegenden Quellen hängt von der Vertriebsdatenquelle ab, die Sie bei der Bereitstellung auswählen.Cloud Storage-Bucket:Der
PROJECT_ID-cortex-meridian-Bucket enthält alle Artefakte, die von Cortex für Meridian benötigt und erstellt werden, in den folgenden Ordnern:configuration: Einstellungen und Parameter für Cortex für Meridian definieren. Sie wird vom Colab Enterprise-Notebook während der Notebook-Ausführung verwendet.csv: Die Rohdatenausgabe aus der Ausführung von Meridian wird hier als CSV-Dateien gespeichert.models: Das generierte Modell aus der Ausführung von Meridian wird hier gespeichert.notebook-run-logs: Hier werden Notebook-Kopien für die einzelnen Ausführungen und Logs gespeichert.notebooks: Enthält das Haupt-Notebook mit Code und Logik für die Ausführung von Cortex für Meridian. Dieses Notebook ist für die weitere Anpassung an Ihre spezifischen Anforderungen vorgesehen.reporting: In diesem Ordner werden Berichte aus Meridian-Ausführungen gespeichert. Enthält auch eine HTML-Vorlage zum Generieren eines Übersichtsberichts mit Links zur Berichtsausgabe von Meridian.
Colab Enterprise:Colab Enterprise ist ein verwalteter Dienst auf Google Cloud , der eine sichere und kollaborative Umgebung für Data-Science- und Machine-Learning-Workflows mit Jupyter-Notebooks bietet. Sie bietet Funktionen wie verwaltete Infrastruktur, Sicherheitskontrollen auf Unternehmensniveau und Integration mit anderen Google Cloud -Diensten. Daher eignet sie sich für Teams, die mit sensiblen Daten arbeiten und eine robuste Governance benötigen. Eine verwaltete Umgebung zum Ausführen des Jupyter-Notebooks.
Cortex für Meridian verwendet Colab Enterprise, um eine Laufzeitvorlage mit der erforderlichen Infrastruktur zu definieren, um Meridian-Ausführungen zu automatisieren.
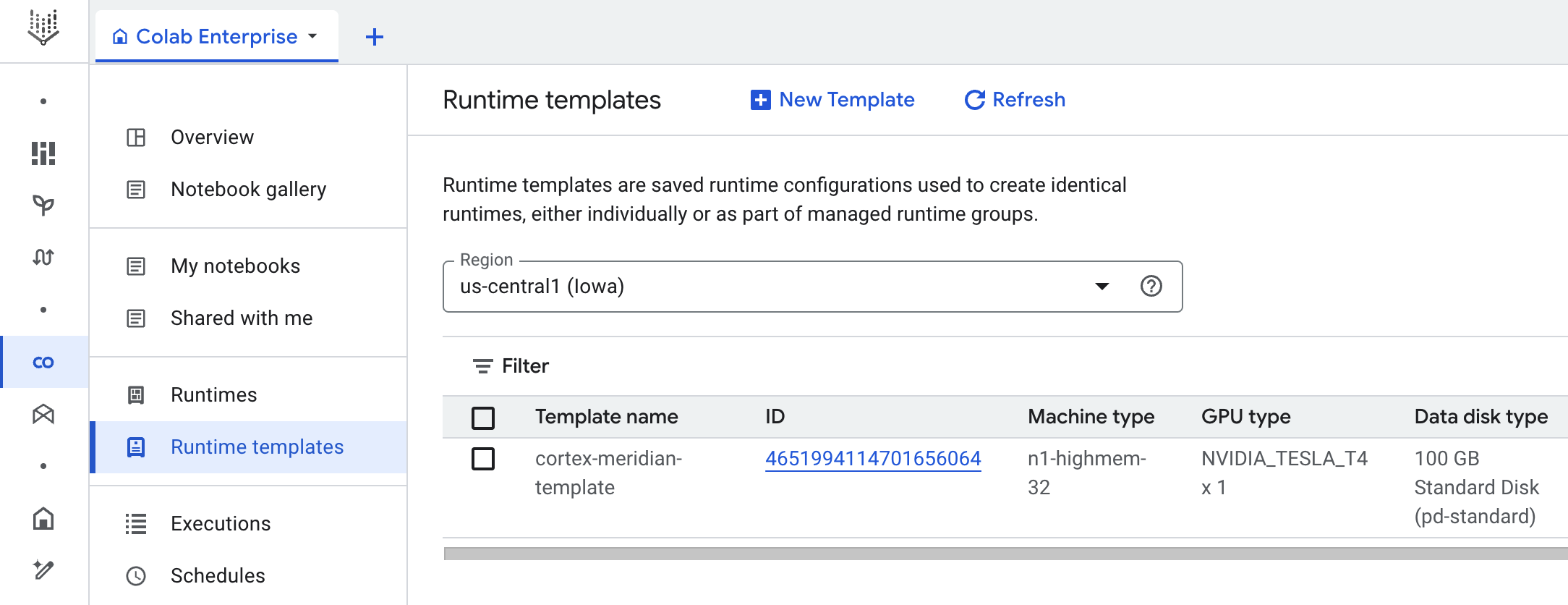
Wenn Sie die End-to-End-Pipeline mit einem Workflow auslösen, wird eine Ausführung erstellt. Dadurch wird eine Kopie des aktuellen Jupyter-Notebooks aus Cloud Storage mit der neuesten Konfiguration ausgeführt.
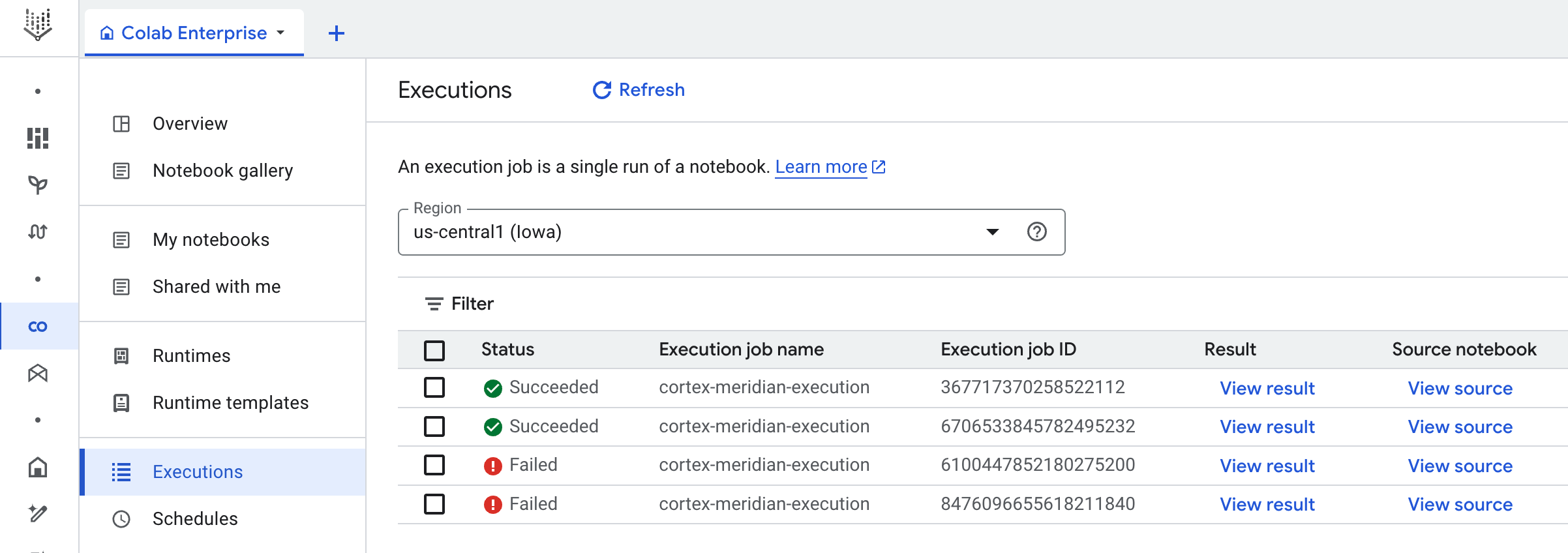
Workflow:Ein Cloud-Workflow mit dem Namen
cortex-meridian-execute-notebookorchestriert die Ausführung der gesamten Cortex for Meridian-Pipeline. Im Workflow wird die Colab Enterprise API aufgerufen, die eine Laufzeit basierend auf der Laufzeitvorlage erstellt und einen Notebook-Lauf mit den aktuellen Konfigurationen ausführt. Schließlich werden alle Ergebnisse in Cloud Storage gespeichert.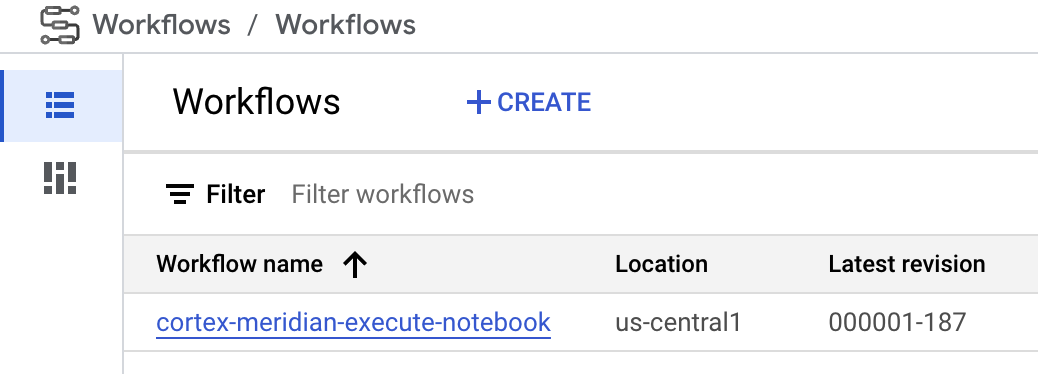
Abbildung 8. Workflows für Meridian. Für den Workflow stehen zwei optionale Konfigurationsoptionen zur Verfügung:
- Wenn Sie eine neue Cortex for Meridian-JSON-Konfiguration als Eingabe für den Workflow bereitstellen können. In diesem Fall wird eine Sicherung der alten Konfiguration erstellt und die Konfiguration mit Ihren Eingaben aktualisiert. Weitere Informationen finden Sie unter REPLACE.
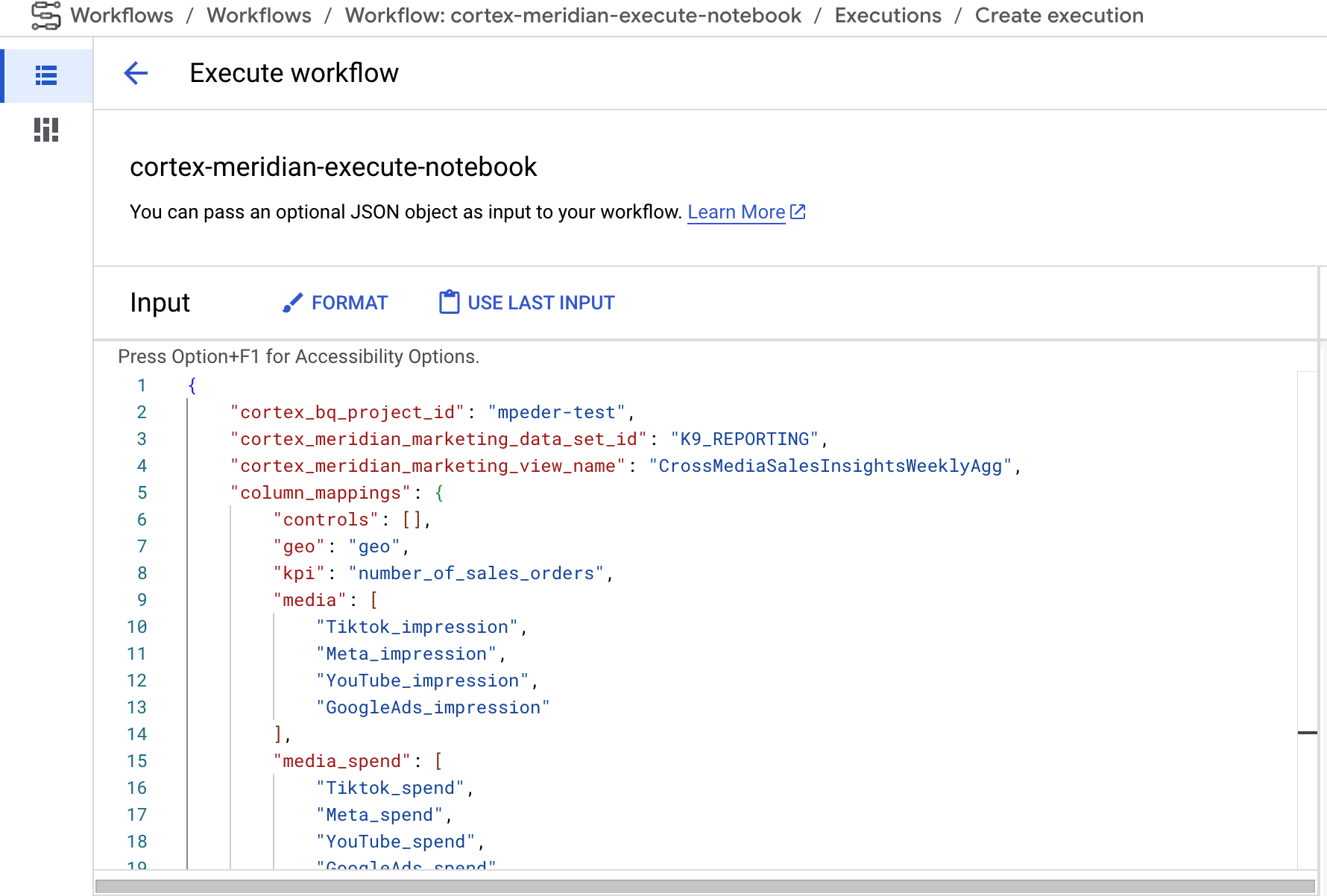
Abbildung 9. Beispiel für das Ändern und Ausführen einer neuen JSON-Eingabe. - Im Schritt
pre_notebook_executionkönnen Sie alle zusätzlichen Aufgaben starten, die Sie vor dem Ausführen des Notebooks automatisieren müssen. Beispielsweise das Laden von Daten aus Quellen außerhalb des Google Cloud Cortex Framework.
Dienstkonto: Bei der Bereitstellung muss ein dediziertes Dienstkonto angegeben werden. Dies ist für die Ausführung des Workflows und des Notebooks in Colab Enterprise erforderlich.
Zusätzliche Bereitstellungsparameter für Meridian
In der Datei config.json werden die Einstellungen konfiguriert, die zum Ausführen von Meridian mit Cortex Framework erforderlich sind. Diese Datei enthält die folgenden Parameter für Cortex für Meridian:
"k9": {
...
"deployMeridian": false,
...
"Meridian":{
"salesDataSourceType": "",
"salesDatasetID":"",
"deploymentType": "",
"defaultNotebookFile":"meridian_cortex_marketing.ipynb",
"defaultConfigFile":"cortex_meridian_config.json",
"gcsBucketNameSuffix": "cortex-meridian",
"workflow": {
"template": "create_notebook_execution_run.yaml",
"name": "cortex-meridian-execute-notebook",
"region": "us-central1"
},
"runnerServiceAccount": "cortex-meridian-colab-runner",
"colabEnterprise": {
"region": "us-central1",
"runtimeTemplateName": "cortex-meridian-template",
"runtimeMachine_type": "n1-highmem-32",
"runtimeAcceleratorCoreCount": 1,
"runtimeAcceleratorType": "NVIDIA_TESLA_T4",
"executionName": "cortex-meridian-execution",
"notebookRunLogsFolder": "notebook-run-logs"
}
}
}
In der folgenden Tabelle werden die Werte und Beschreibungen für die einzelnen Meridian-Parameter aufgeführt:
| Parameter | Bedeutung | Standardwert | Beschreibung |
k9.deployMeridian
|
Meridian bereitstellen oder nicht. | false
|
Gibt an, ob Cortex für Meridian im Rahmen einer Data Foundation-Bereitstellung bereitgestellt werden soll. |
k9.Meridian.salesDataSourceType
|
Die Quelle der Verkaufsdaten. | - | Wählen Sie zwischen BYOD, SAP und OracleEBS aus.
|
k9.Meridian.salesDatasetID
|
Die ID Ihres Verkaufsdatensatzes. | - | Die ID Ihres Verkaufsdatensatzes. Variiert je nach zugehöriger Cortex Data Foundation-Konfiguration. |
k9.Meridian.deploymentType
|
Gibt an, ob es sich bei der Bereitstellung um eine vollständige oder inkrementelle Bereitstellung handelt. | - | Wählen Sie zwischen initial und incremental aus.
|
k9.Meridian.defaultNotebookFile
|
Jupyter-Notebook-Datei. | meridian_cortex_marketing.ipynb
|
Der Name der Notebook-Datei im Ordner notebooks in Cloud Storage.
|
k9.Meridian.defaultConfigFile
|
Die Konfigurationsdatei zum Ausführen des Notebooks. | cortex_meridian_config.json
|
Sie enthält die Cortex for Meridian-Konfiguration, die beim Ausführen des Notebooks verwendet wird.
Sie muss sich im Ordner configuration in Cloud Storage befinden.
|
k9.Meridian.gcsBucketNameSuffix
|
Das Suffix des Cortex for Meridian Cloud Storage-Bucket. | cortex-meridian
|
Der vollständige Name des Buckets ist standardmäßig {PROJECT_ID}-cortex-meridian. |
k9.Meridian.workflow.template
|
Die Vorlage für den Workflow. | create_notebook_execution_run.yaml
|
Die Vorlage zum Erstellen des Workflows. Der Workflow wird zum Starten der Ausführung eines Notebooks verwendet. |
k9.Meridian.workflow.name
|
Der Name des Workflows. | cortex-meridian-execute-notebook
|
Der Name, der im Google Cloud -Portal für den Workflow angezeigt wird. |
k9.Meridian.workflow.region
|
Die Bereitstellungsregion für den Workflow. | us-central1
|
Die Bereitstellungsregion für den Workflow. In der Regel wird dieselbe wie für den Rest Ihrer Bereitstellung ausgewählt. |
k9.Meridian.runnerServiceAccount
|
Der Name des Dienstkontos für Cortex für Meridian. | cortex-meridian-colab-runner
|
Der Name des Dienstkontos, das zum Ausführen des Workflows und der Colab Enterprise-Ausführungen verwendet wird. |
k9.Meridian.colabEnterprise.region
|
Die Bereitstellungsregion für die Colab Enterprise-Ausführungen. | us-central1
|
Die Bereitstellungsregion für die Colab Enterprise-Ausführungen. In der Regel wird dieselbe wie für den Rest Ihrer Bereitstellung ausgewählt. |
k9.Meridian.colabEnterprise.runtimeTemplateName
|
Name der Colab Enterprise-Laufzeitvorlage. | cortex-meridian-template
|
Name der Colab Enterprise-Laufzeitvorlage. |
k9.Meridian.colabEnterprise.runtimeMachine_type
|
Maschinentyp für die Laufzeit des Enterprise-Colab-Notebooks. | n1-highmem-32
|
Maschinentyp für die Laufzeit des Enterprise-Colab-Notebooks. |
k9.Meridian.colabEnterprise.runtimeAcceleratorCoreCount
|
Anzahl der Kerne. | 1
|
Anzahl der GPU-Beschleunigerkerne für die Laufzeit von Enterprise-Colab-Notebooks. |
k9.Meridian.colabEnterprise.runtimeAcceleratorType
|
Beschleunigertyp für die Laufzeit des Enterprise-Colab-Notebooks. | NVIDIA_TESLA_T4
|
Der GPU-Typ. |
k9.Meridian.colabEnterprise.executionName
|
Der Name der Ausführung für die Laufzeit des Enterprise-Colab-Notebooks. | cortex-meridian-execution
|
Der Name, der in der Weboberfläche von Colab Enterprise – Ausführungen angezeigt wird. |
k9.Meridian.colabEnterprise.notebookRunLogsFolder
|
Name des Ordners für die Laufzeitausführungen. | notebook-run-logs
|
Bei der Ausführung von Colab-Notebooks werden hier Logs und Ausführungskopien des Notebooks gespeichert. |
Workflow
Workflows dienen als primäre Schnittstelle zum Starten von Cortex for Meridian-Ausführungen. Ein Standardworkflow namens cortex-meridian-execute-notebook wird als Teil von Cortex für Meridian bereitgestellt.
Notebook-Ausführung
So starten Sie eine neue Ausführung von Cortex for Meridian:
- Rufen Sie das
cortex-meridian-execute-notebook-Notebook in Workflows auf. - Klicken Sie auf Ausführen, um eine neue Ausführung zu starten.
- Lassen Sie das Eingabefeld bei den ersten Ausführungen leer, um die Standardkonfiguration zu verwenden, die in der Konfigurationsdatei
cortex_meridian_config.jsonin Cloud Storage gespeichert ist. - Klicken Sie noch einmal auf Ausführen, um fortzufahren.
Nach kurzer Zeit wird der Status der Workflow-Ausführung angezeigt:
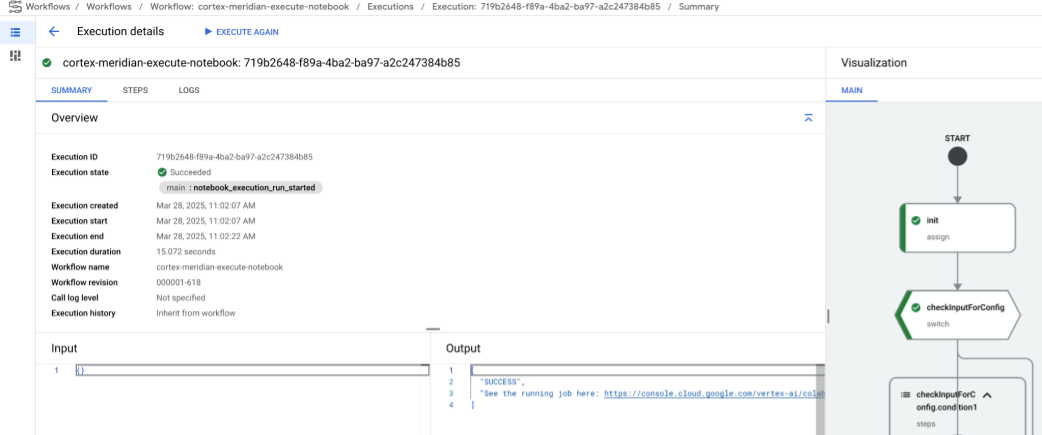
Abbildung 10. Beispiel für Ausführungsdetails. Verfolgen Sie den Fortschritt der Notebook-Ausführung in Colab Enterprise.
Workflowschritte
Der cortex-meridian-execute-notebook-Workflow umfasst die folgenden Schritte:
| Step | Teilschritt | Beschreibung |
init
|
-
|
Parameter initialisieren |
checkInputForConfig
|
-
|
Prüfen Sie, ob eine neue Config-JSON als Workflow-Eingabe bereitgestellt wurde. |
logBackupConfigFileName
|
Protokolliert den Dateinamen der Sicherungskonfiguration. | |
backupConfigFile
|
Sichert die Konfigurationsdatei in Cloud Storage. | |
logBackupResult
|
Protokolliert das Ergebnis des Aufrufs der Cloud Storage API. | |
updateGCSConfigFile
|
Aktualisieren Sie die Konfigurationsdatei in Cloud Storage mit den neuen Werten. | |
pre_notebook_execution
|
-
|
Dieser Schritt ist standardmäßig leer. Sie können es anpassen. Dazu gehören beispielsweise das Laden von Daten oder andere relevante Schritte, die vor der Ausführung des Notebooks erforderlich sind. Weitere Informationen finden Sie unter Workflows – Übersicht und Workflow-Connectors. |
create_notebook_execution_run
|
-
|
Erstellen Sie die Ausführung des Colab Enterprise-Notebooks über ein Shell-Skript in Cloud Build. |
notebook_execution_run_started
|
-
|
Gibt das Vervollständigungsergebnis aus. |
Meridian-Ausführungsworkflow anpassen
Sie können die Ausführung von Meridian anpassen, indem Sie eine eigene JSON-Konfigurationsdatei im Eingabefeld „Workflows“ angeben:
- Geben Sie das vollständige JSON der geänderten Konfiguration in das Eingabefeld ein.
- Der Workflow wird dann:
- Ersetzen Sie die vorhandene Datei
cortex_meridian_config.jsonin Cloud Storage durch den bereitgestellten JSON-Code. - Erstellen Sie im Verzeichnis
Cloud Storage/configurationeine Sicherung der ursprünglichen Konfigurationsdatei. - Der Name der Sicherungsdatei hat das Format
cortex_meridian_config_workflow_backup_workflow_execution_id.json, wobei workflow_execution_id eine eindeutige Kennung für die aktuelle Workflowausführung ist (z. B.cortex_meridian_config_workflow_backup_3e3a5290-fac0-4d51-be5a-19b55b2545de.json).
- Ersetzen Sie die vorhandene Datei
Übersicht über Jupyter-Notebooks
Die Kernfunktion zum Laden von Eingabedaten zum Ausführen des Meridian-Modells wird vom Python-Notebook meridian_cortex_marketing.ipynb übernommen, das sich im Ordner notebooks Ihres Cloud Storage-Bucket befindet.
Der Ausführungsablauf des Notebooks besteht aus den folgenden Schritten:
- Installiert die erforderlichen Pakete (einschließlich Meridian) und importiert die erforderlichen Bibliotheken.
- Hilfsfunktionen für die Interaktion mit Cloud Storage und BigQuery laden.
- Ruft die Konfiguration für die Ausführung aus der
configuration/cortex_meridian_config.json-Datei in Cloud Storage ab. - Cortex Framework-Daten aus der Ansicht „Cortex Framework Data Foundation“ in BigQuery laden.
- Konfigurieren Sie die Meridian-Modellspezifikation und ordnen Sie die Datenmodelle der Cortex Framework Data Foundation für Marketing und Vertrieb dem Meridian-Modelleingabeschema zu.
- Führt die Meridian-Stichprobenerhebung aus und generiert einen zusammenfassenden Bericht, der in Cloud Storage (
/reporting) gespeichert wird. - Führen Sie den Budget-Optimizer für das Standardszenario aus und geben Sie den Zusammenfassungsbericht in Cloud Storage aus (
/reporting). - Modell in Cloud Storage speichern (
/models). - CSV-Ergebnisse in Cloud Storage speichern (
/csv). - Erstellen Sie einen Übersichtsbericht und speichern Sie ihn in Cloud Storage (
/reporting).
Notebook für die manuelle Ausführung und Bearbeitung importieren
Wenn Sie das Notebook anpassen oder manuell ausführen möchten, importieren Sie es aus Cloud Storage:
- Rufen Sie Colab Enterprise auf.
- Klicken Sie auf Meine Notebooks.
- Klicken Sie auf Importieren.
- Wählen Sie Cloud Storage als Importquelle aus und wählen Sie das Notebook aus Cloud Storage aus.
- Klicken Sie auf Importieren.
Das Notebook wird geladen und geöffnet.
Ergebnisse von Notebook-Ausführungen
Wenn Sie die Ergebnisse eines Notebook-Laufs ansehen möchten, öffnen Sie eine vollständige Kopie des Notebooks mit allen Zellausgaben:
- Rufen Sie in Colab Enterprise Ausführungen auf.
- Wählen Sie im Drop-down-Menü die gewünschte Region aus.
- Klicken Sie neben dem Notebook-Lauf, für den Sie Ergebnisse aufrufen möchten, auf Ergebnis anzeigen.
- In Colab Enterprise wird das Ergebnis des Notebook-Laufs in einem neuen Tab geöffnet.
- Klicken Sie auf den neuen Tab, um das Ergebnis aufzurufen.
Laufzeitvorlage
Google Cloud In Colab Enterprise werden Laufzeitvorlagen verwendet, um vorkonfigurierte Ausführungsumgebungen zu definieren. Eine vordefinierte Laufzeitvorlage, die für die Ausführung des Meridian-Notebooks geeignet ist, ist in der Cortex for Meridian-Bereitstellung enthalten. Diese Vorlage wird automatisch verwendet, um Laufzeitumgebungen für die Ausführung von Notebooks zu erstellen.
Bei Bedarf können Sie manuell zusätzliche Laufzeitvorlagen erstellen.