Conversational Insights lets you import conversations from Agent Assist to analyze them. This document walks you through the process of computing several important conversational metrics on imported Agent Assist data.
Prerequisites
Use Agent Assist to generate conversational data using either the smart reply or summarization features.
Enable Dialogflow runtime integration in Conversational Insights.
Export your data from Insights to BigQuery.
Trigger rate
Trigger rate describes how often a type of annotation appears in a conversation.
Sentence-level trigger rate
A sentence-level trigger rate applies to annotations that can appear at minimum once per sentence.
| Annotation Name | Annotation Type | Criteria |
|---|---|---|
| Article suggestion | 'ARTICLE_SUGGESTION' |
At least one SuggestArticles request is sent for each message in the conversation. |
| FAQ assist | 'FAQ' |
At least one SuggestFaqAnswers or AnalyzeContent request is sent for each message in the conversation. |
| Smart reply | 'SMART_REPLY' |
At least one SuggestSmartReplies or AnalyzeContent request is sent for each message in the conversation. |
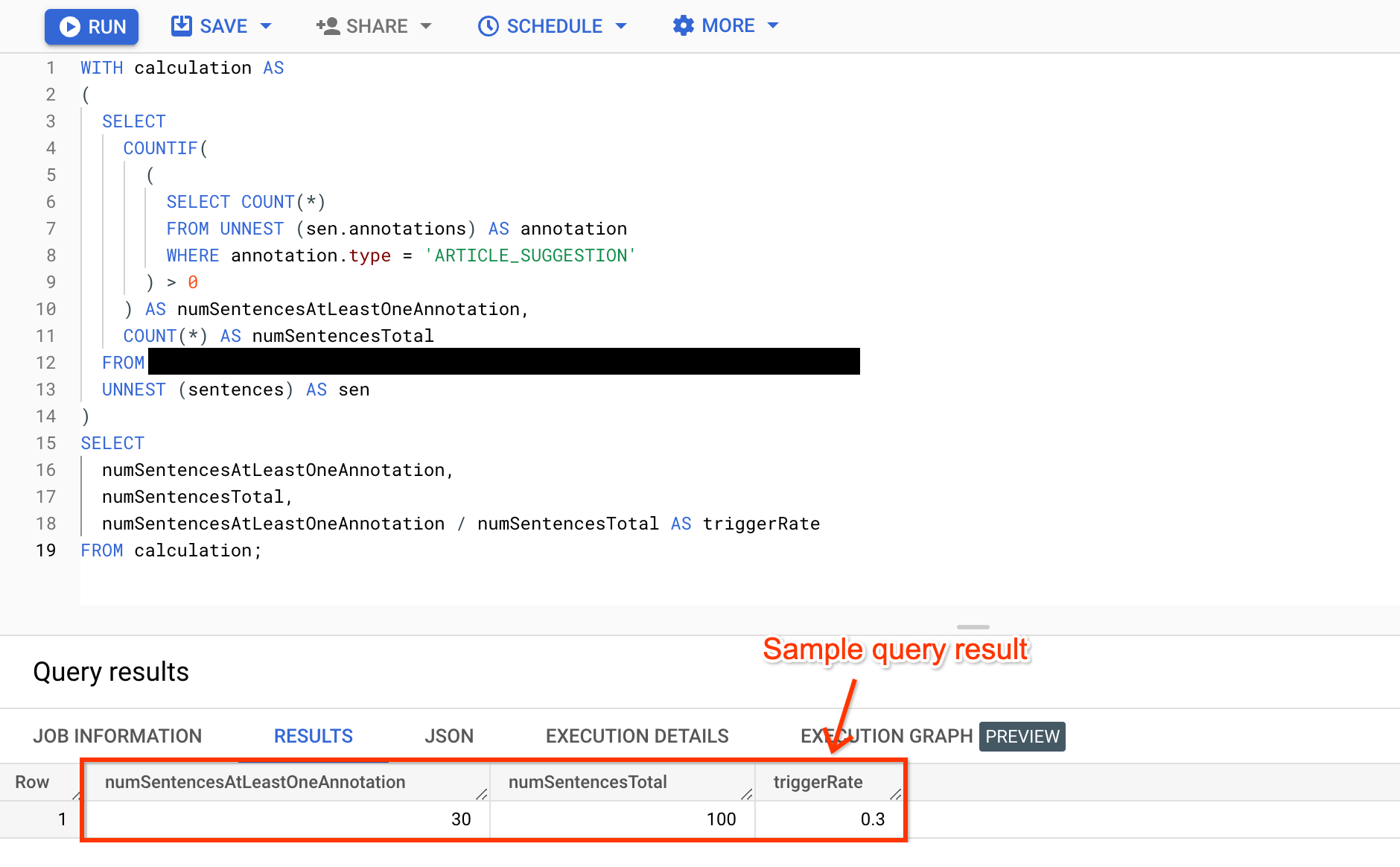
WITH calculation AS ( SELECT COUNTIF( ( SELECT COUNT(*) FROM UNNEST (sen.annotations) AS annotation WHERE annotation.type = 'ANNOTATION_TYPE' ) > 0 ) AS numSentencesAtLeastOneAnnotation, COUNT(*) AS numSentencesTotal FROM BIGQUERY_TABLE, UNNEST (sentences) AS sen ) SELECT numSentencesAtLeastOneAnnotation, numSentencesTotal, numSentencesAtLeastOneAnnotation / numSentencesTotal AS triggerRate FROM calculation;
Conversation-level trigger rate
A conversation-level trigger rate applies to annotations that can appear at most once per conversation.
| Annotation Name | Annotation Type | Criteria |
|---|
| Generative knowledge assist (GKA) | 'KNOWLEDGE_SEARCH' | At least one SearchKnowledge request is sent for each message in the conversation. |
| Proactive generative knowledge assist | 'KNOWLEDGE_SEARCH' | At least one SearchKnowledge or AnalyzeContent request is sent for each message in the conversation. |
| Summarization | 'CONVERSATION_SUMMARIZATION' | At least one SuggestConversationSummary request is sent for each conversation. |
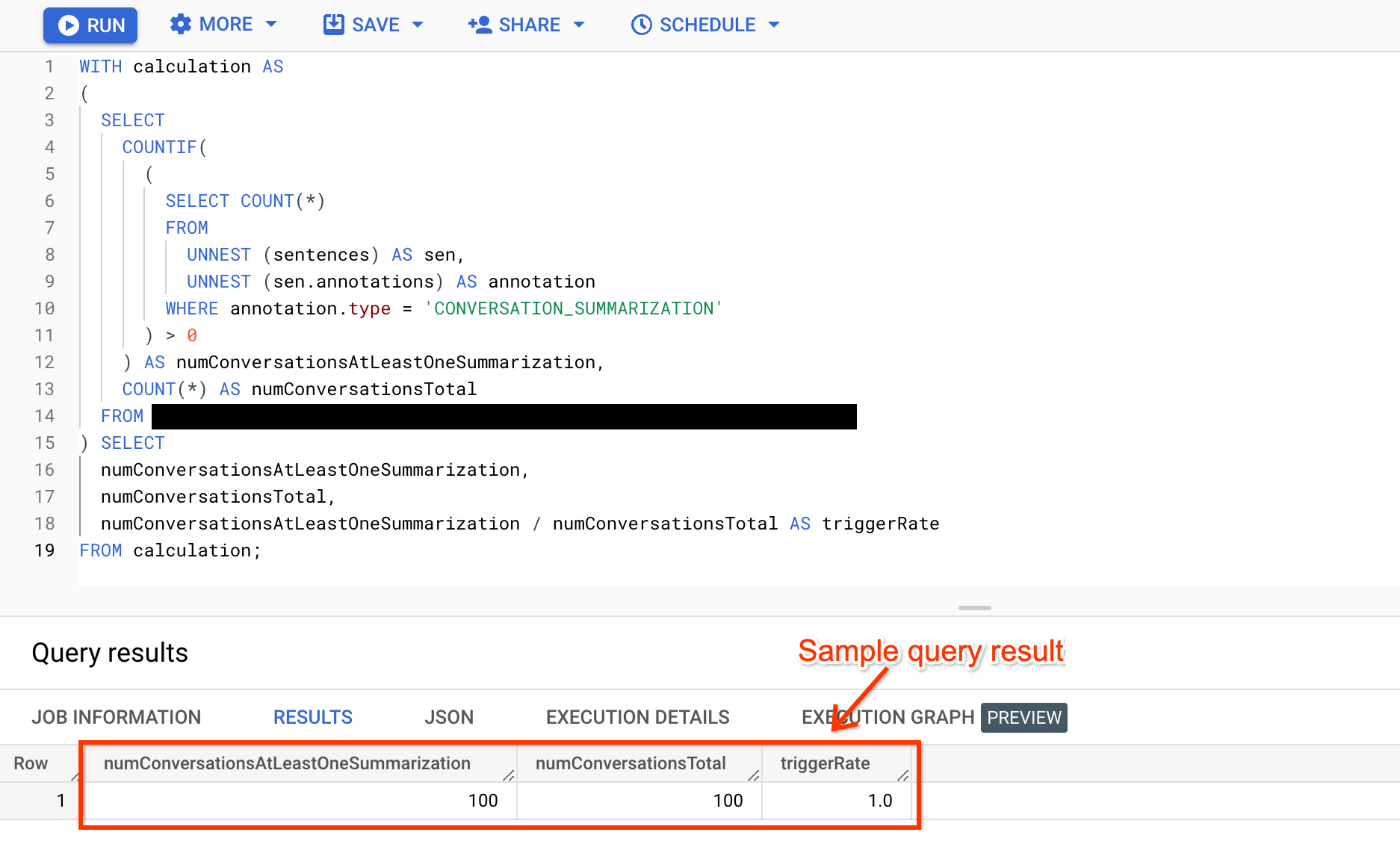
WITH calculation AS ( SELECT COUNTIF( ( SELECT COUNT(*) FROM UNNEST (sentences) AS sen, UNNEST (sen.annotations) AS annotation WHERE annotation.type = 'ANNOTATION_TYPE' ) > 0 ) AS numConversationsAtLeastOneAnnotation, COUNT(*) AS numConversationsTotal FROM BIGQUERY_TABLE ) SELECT numConversationsAtLeastOneAnnotation, numConversationsTotal, numConversationsAtLeastOneAnnotation / numConversationsTotal AS triggerRate FROM calculation;
Click-through rate
Click-through rate describes how often call agents click the annotations suggested to them.
Sentence-level click-through rate
A sentence-level click-through rate applies to annotations that call agents can click multiple times per sentence.
| Annotation Name | Annotation Type | Criteria |
|---|---|---|
| Article suggestion | 'ARTICLE_SUGGESTION' |
At least one SuggestArticles request is sent for each message in the conversation. |
| FAQ assist | 'FAQ' |
At least one SuggestFaqAnswers or AnalyzeContent request is sent for each message in the conversation. |
| Smart reply | 'SMART_REPLY' |
At least one SuggestSmartReplies or AnalyzeContent request is sent for each message in the conversation. |
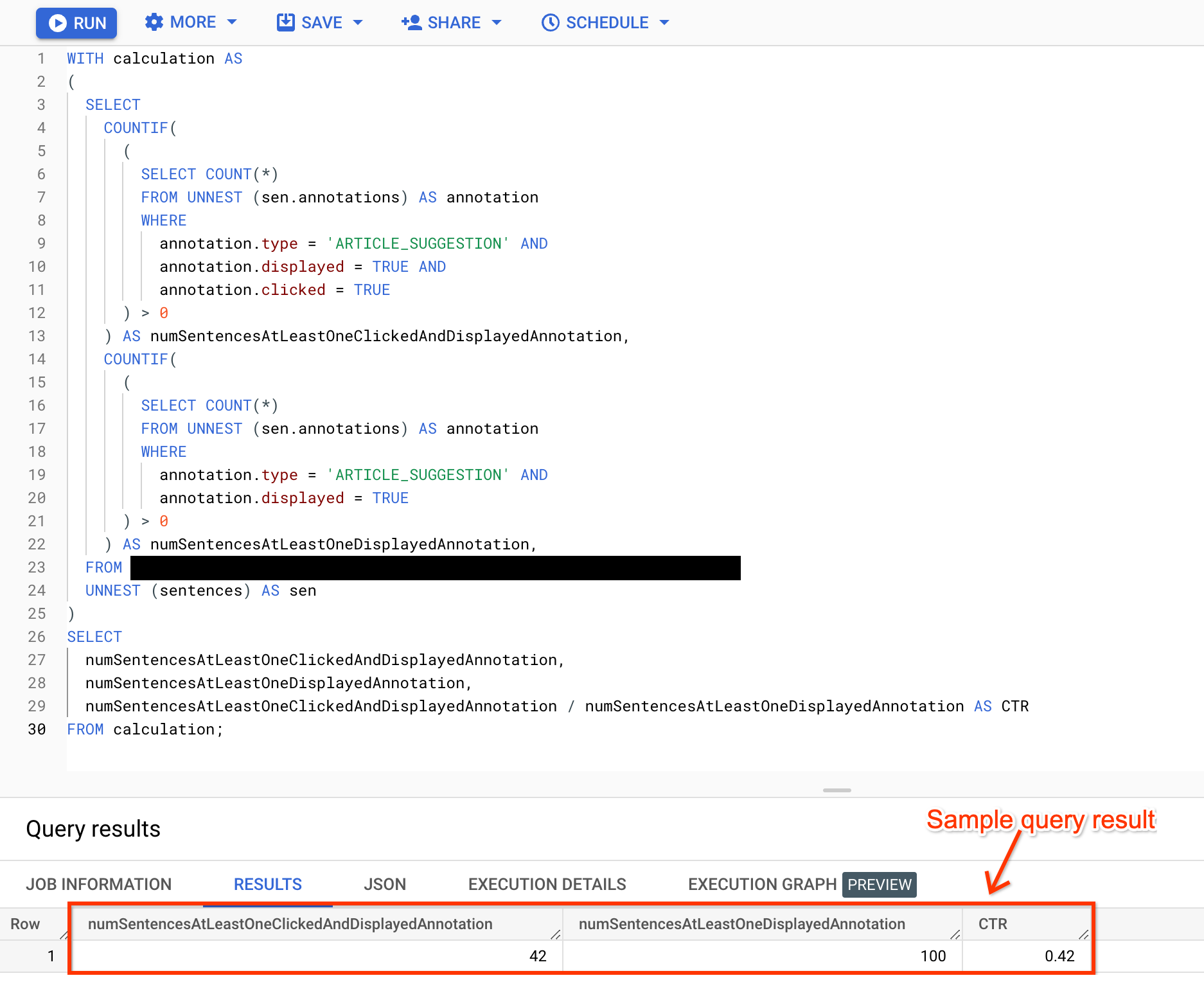
WITH calculation AS ( SELECT COUNTIF( ( SELECT COUNT(*) FROM UNNEST (sen.annotations) AS annotation WHERE annotation.type = 'ANNOTATION_TYPE' AND annotation.displayed = TRUE AND annotation.clicked = TRUE ) > 0 ) AS numSentencesAtLeastOneClickedAndDisplayedAnnotation, COUNTIF( ( SELECT COUNT(*) FROM UNNEST (sen.annotations) AS annotation WHERE annotation.type = 'ANNOTATION_TYPE' AND annotation.displayed = TRUE ) > 0 ) AS numSentencesAtLeastOneDisplayedAnnotation, FROM BIGQUERY_TABLE, UNNEST (sentences) AS sen ) SELECT numSentencesAtLeastOneClickedAndDisplayedAnnotation, numSentencesAtLeastOneDisplayedAnnotation, numSentencesAtLeastOneClickedAndDisplayedAnnotation / numSentencesAtLeastOneDisplayedAnnotation AS clickThroughRate FROM calculation;
Conversation-level click-through rate
A Conversation-level click-through rate applies to annotations that call agents can click multiple times per conversation. Call agents have to proactively send a request that creates a conversation-level annotation.
| Annotation Name | Annotation Type | Criteria |
|---|---|---|
| Generative knowledge assist (GKA) | 'KNOWLEDGE_SEARCH' |
At least one SearchKnowledge request is sent for each message in the conversation. |
| Proactive generative knowledge assist | 'KNOWLEDGE_SEARCH' |
At least one SearchKnowledge or AnalyzeContent request is sent for each message in the conversation. |
Feature-specific metrics
This section lists metrics that are specific to each feature.
Generative knowledge assist
Generative knowledge assist (GKA) provides answers to an agent's questions based on information in documents you provide. If the agent can't find an answer, GKA suggests a similar question to ask and provides the answer. This feature produces the following knowledge search metrics:
| Metric name | Definition | Calculation |
|---|---|---|
| Result count | Total number of answers provided to a single agent for all conversations. | |
| Agent query source ratio | Proportion of agent questions to the total number of questions. | Calculate the number of agent questions divided by the total number of questions. |
| Suggested query source ratio | Proportion of suggested questions to the total number of questions. | Calculate the number of suggested questions divided by the total number of questions. |
| URI click ratio | Proportion of answers where at least one URI was clicked to the total number of answers. | Calculate the number of answers for which an agent clicked the URI divided by the total number of answers. |
| Positive feedback ratio | Proportion of positive feedback about answers to the total number of answers. | Calculate the number of answers that received positive feedback divided by the total number of answers. |
| Negative feedback ratio | Proportion of negative feedback about answers to the total number of answers. | Calculate the number of answers that received negative feedback divided by the total number of answers. |
Proactive generative knowledge assist
Proactive generative knowledge assist suggests the questions based on the current conversation context and provides the answers based on information in documents you provide. Proactive generative knowledge assist requires no agent interaction. This feature produces the following knowledge assist metrics:
| Metric name | Definition | Calculation |
|---|---|---|
| Result count | Total number of suggestions provided to a single agent for all conversations. | |
| URI click ratio | Proportion of suggestions where at least one URI was clicked to the total number of suggestions provided. | Calculate the number of suggestions for which an agent clicked the URI divided by the total number of suggestions provided. |
| Positive feedback ratio | Proportion of positive feedback about suggestions to the total number of suggestions. | Calculate the number of suggestions that received positive feedback divided by the total number of suggestions. |
| Negative feedback ratio | Proportion of negative feedback about suggestions to the total number of suggestions. | Calculate the number of suggestions that received negative feedback divided by the total number of suggestions. |
Smart reply
This section lists metrics that are specific to smart reply.
Effective click-through rate (effective CTR)
The effective click-through rate is a more precise reflection of how often call agents click smart reply annotations than the regular click-through rate metric. The following query fetches each agent's response and the smart reply annotations that were made just for that agent's response and clicked by the agent. It then counts the number of occurrences where the agent drafted their response using smart reply suggestions, then divides this number by the total count of agent's responses.
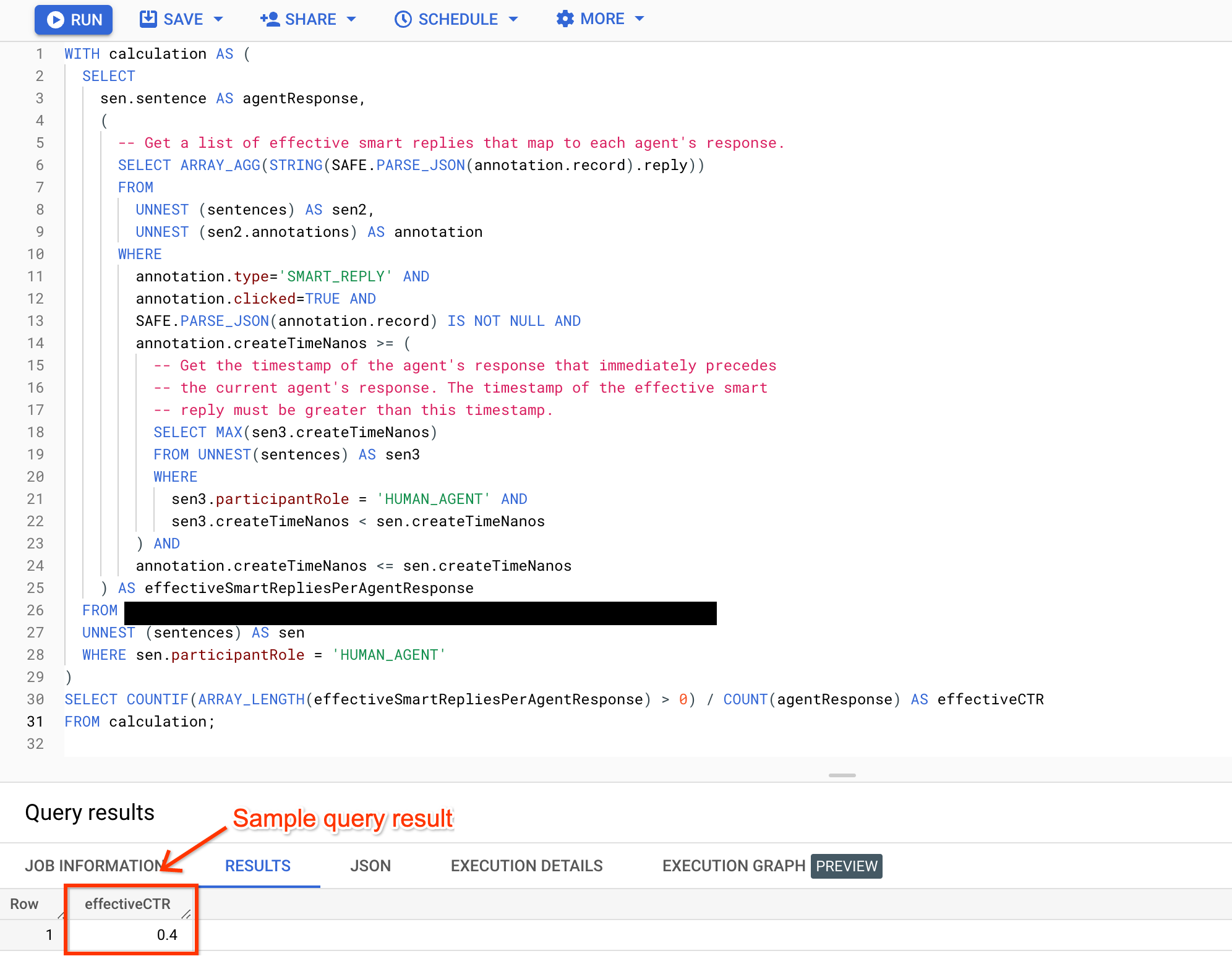
WITH calculation AS ( SELECT sen.sentence AS agentResponse, ( # Get a list of effective smart replies that map to each agent response. SELECT ARRAY_AGG(JSON_QUERY(PARSE_JSON(JSON_VALUE(annotation.annotationRecord)), "$.reply")) FROM UNNEST (sentences) AS sen2, UNNEST (sen2.annotations) AS annotation WHERE annotation.type='SMART_REPLY' AND annotation.clicked=TRUE AND annotation.annotationRecord IS NOT NULL AND annotation.createTimeNanos >= ( # Get the timestamp of the agent response that immediately precedes # the current agent response. The timestamp of the effective smart # reply must be greater than this timestamp. SELECT MAX(sen3.createTimeNanos) FROM UNNEST(sentences) AS sen3 WHERE sen3.participantRole = 'HUMAN_AGENT' AND sen3.createTimeNanos < sen.createTimeNanos ) AND annotation.createTimeNanos <= sen.createTimeNanos ) AS effectiveSmartRepliesPerAgentResponse FROM BIGQUERY_TABLE, UNNEST (sentences) AS sen WHERE sen.participantRole = 'HUMAN_AGENT' ) SELECT COUNTIF(ARRAY_LENGTH(effectiveSmartRepliesPerAgentResponse) > 0) / COUNT(agentResponse) AS effectiveCTR FROM calculation;
Edit rate
Agents can choose to either use suggested smart reply responses verbatim, or edit the responses before sending them to customers. Computing the edit rate of smart reply responses can show you how often the suggested replies are edited. The following query fetches each suggested smart reply and the agent's response that immediately follows that smart reply. It then counts the number of occurrences where the agent's response doesn't contain its corresponding smart reply, then divides this by the total smart reply count.
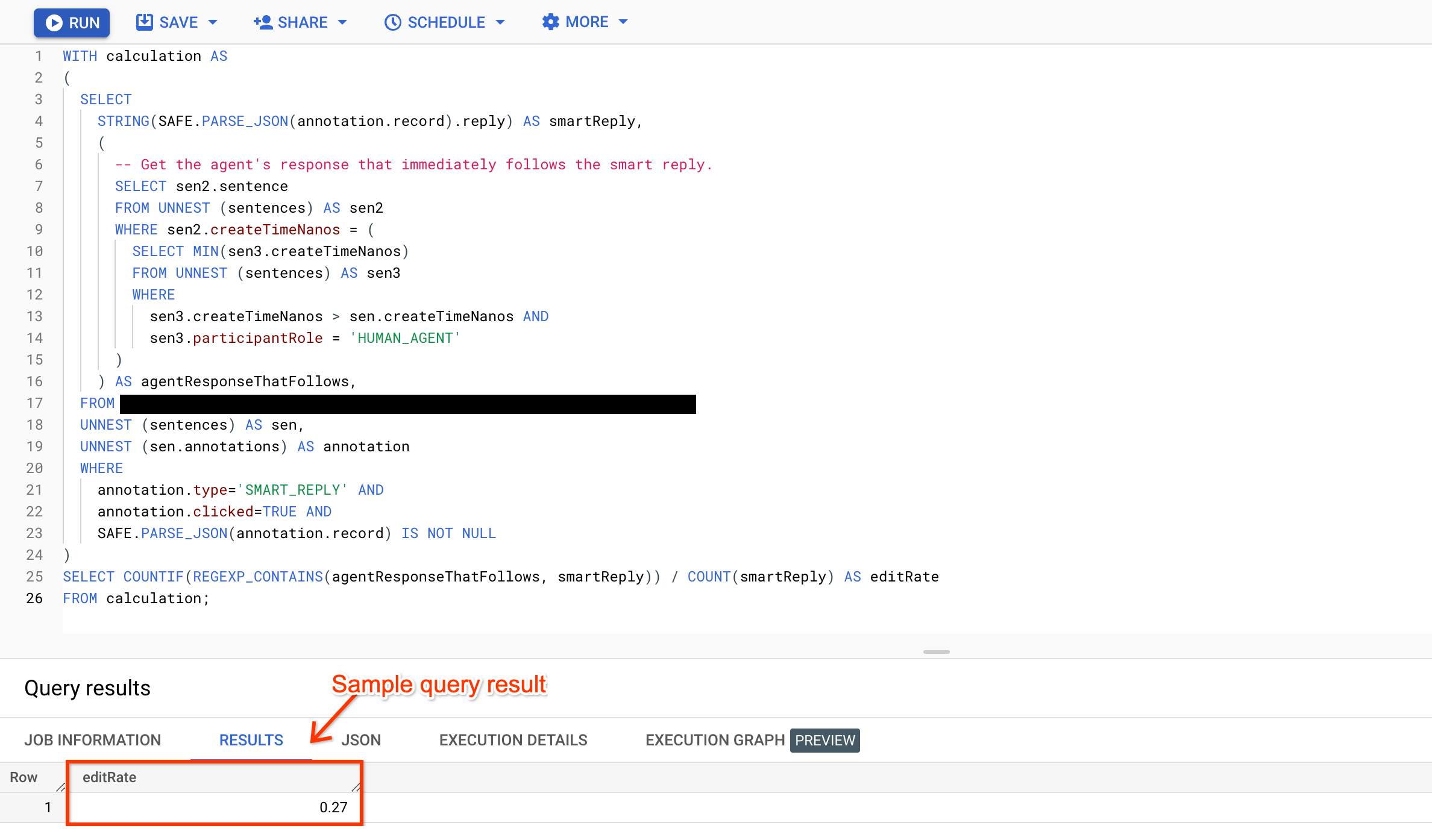
WITH calculation AS ( SELECT JSON_VALUE(PARSE_JSON(JSON_VALUE(annotation.annotationRecord), wide_number_mode=>'round'), "$.reply") AS smartReply, ( # Get the agent response that immediately follows the smart reply. SELECT sen2.sentence FROM UNNEST (sentences) AS sen2 WHERE sen2.createTimeNanos = ( SELECT MIN(sen3.createTimeNanos) FROM UNNEST (sentences) AS sen3 WHERE sen3.createTimeNanos > sen.createTimeNanos AND sen3.participantRole = 'HUMAN_AGENT' ) ) AS agentResponseThatFollows, FROM BIGQUERY_TABLE, UNNEST (sentences) AS sen, UNNEST (sen.annotations) AS annotation WHERE annotation.type='SMART_REPLY' AND annotation.clicked=TRUE AND annotation.annotationRecord IS NOT NULL ) SELECT COUNTIF(REGEXP_CONTAINS(agentResponseThatFollows, smartReply)) / COUNT(smartReply) AS editRate FROM calculation;
Summarization
This section lists metrics that are specific to summarization.
GENERATOR_SUGGESTION_RESULTtype will contain all generator results, including summaries.CONVERSATION_SUMMARIZATION_SUGGESTIONtype will contain legacy summaries.
Generator Summary
Sample query to access generator summary and agent edits to the summary as JSON:
SELECT IF (JSON_VALUE(annotation.annotationRecord) != '', JSON_QUERY(PARSE_JSON(JSON_VALUE(annotation.annotationRecord)), "$.generatorSuggestion.summarySuggestion"), NULL) AS generator_summary, IF (JSON_VALUE(annotation.detailedFeedback) != '', JSON_QUERY(PARSE_JSON(JSON_VALUE(annotation.detailedFeedback)), "$.summarizationFeedback.summaryText"), NULL) AS feedback, FROM BIGQUERY_TABLE AS c, UNNEST(c.sentences) AS sentences, UNNEST(sentences.annotations) AS annotation WHERE annotation.type = 'GENERATOR_SUGGESTION_RESULT' AND JSON_QUERY(PARSE_JSON(JSON_VALUE(annotation.annotationRecord)), "$.generatorSuggestion.summarySuggestion") IS NOT NULL LIMIT 10 ;
Edit distance
The edit distance of summarization is a measure of how much the agent-edited summaries differ from the suggested summaries. This metric correlates to the amount of time the agent spent editing the suggested summaries.
Query the summarizations and their revised summaries (if any).
Because call agents can submit summary revisions without setting the
clickedboolean totrue, query summarizations, regardless of theirclickedstatus. If the agent's summary is null, the agent didn't revise the suggested summary or the revised summary wasn't sent to Agent Assist using the preferred feedback route.Compare the suggested summaries with the agents' revised summaries using your preferred edit distance algorithms to compute the summarization edit distance. For example, Levenshtein distance with equal penalty for insertion, deletion, and substitution.
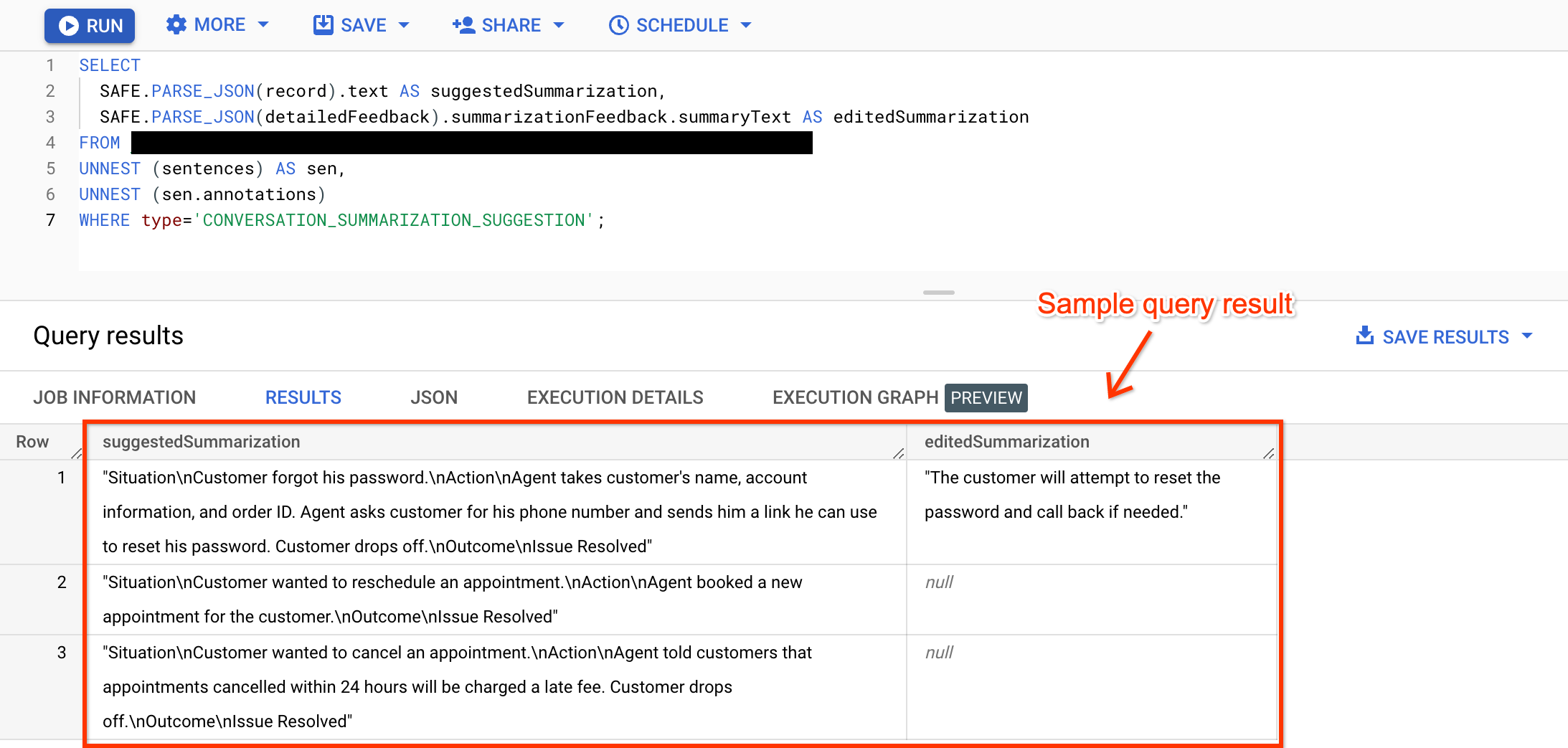
SELECT JSON_VALUE(PARSE_JSON(JSON_VALUE(annotation.annotationRecord)), "$.text") AS suggestedSummary, IF (JSON_VALUE(annotation.detailedFeedback) != '', JSON_QUERY(PARSE_JSON(JSON_VALUE(annotation.detailedFeedback)), "$.summarizationFeedback.summaryText"), NULL) AS feedback, FROM BIGQUERY_TABLE, UNNEST (sentences) AS sen, UNNEST (sen.annotations) as annotation WHERE type='CONVERSATION_SUMMARIZATION_SUGGESTION';
Edit rate
You can compute the edit rate for summarization by dividing the edit distance by the string length of the edited summary. This metric reflects how much of the summary was edited by the agent. This edit rate has no upper bound, but when the value is equal or greater than one, it means the generated summaries are bad and the feature should probably be disabled.
Edit percentage
The edit percentage is a measure of the percentage of the total number of suggested summaries that were edited by agents instead of being used verbatim. It's calculated as the number of agent-edited summaries divided by the number of suggested summaries. This metric is a good signal of model quality when the value is close to 0. But when it's close to 1, it doesn't necessarily mean the model quality is bad since the edit could be minor and it would still count as the suggested summary having been edited.
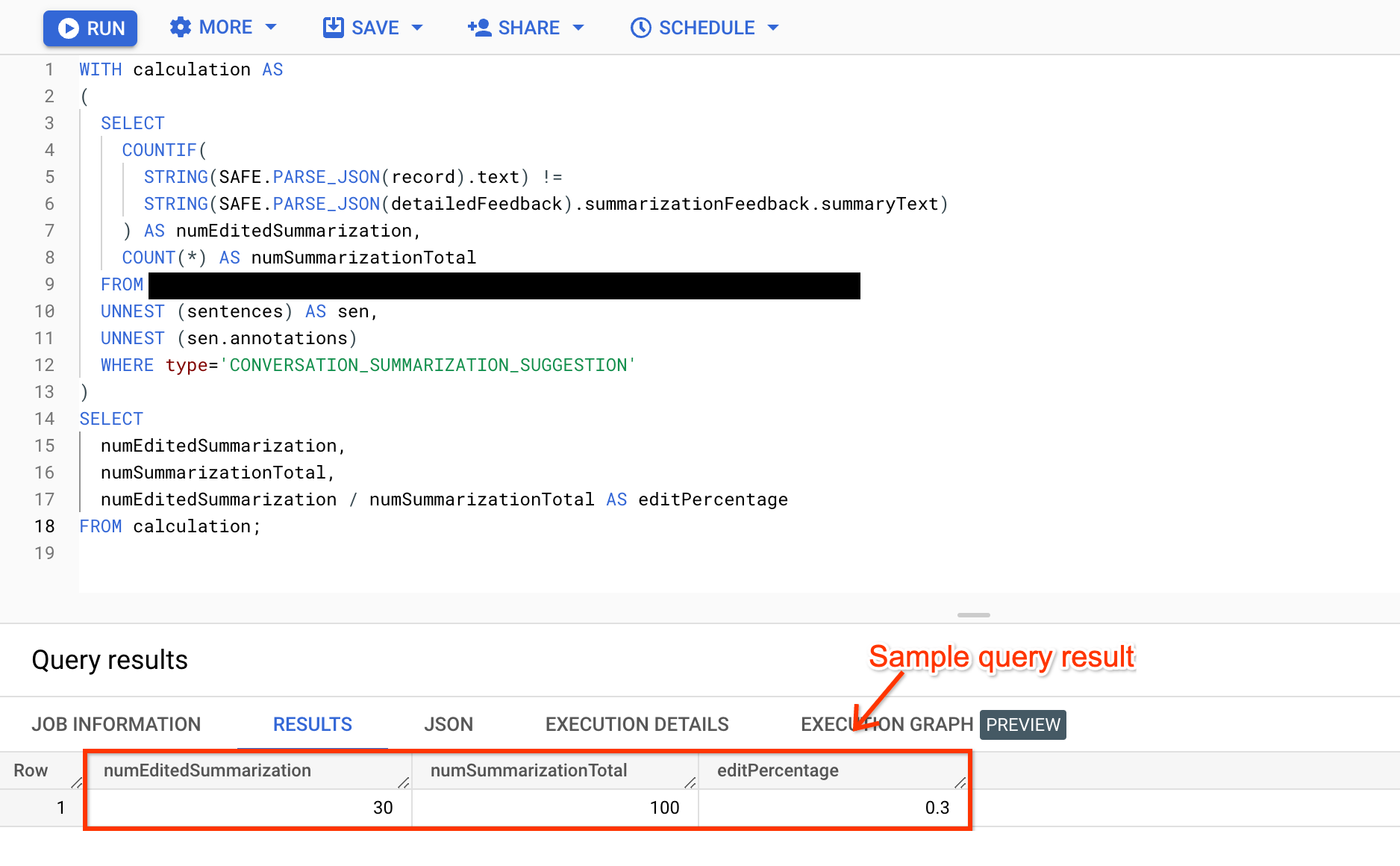
WITH summaryAndEdits AS ( SELECT JSON_VALUE(PARSE_JSON(JSON_VALUE(annotation.annotationRecord)), "$.text") AS suggestedSummary, IF (JSON_VALUE(annotation.detailedFeedback) != '', JSON_QUERY(PARSE_JSON(JSON_VALUE(annotation.detailedFeedback)), "$.summarizationFeedback.summaryText"), NULL) AS editedSummary, FROM BIGQUERY_TABLE, UNNEST (sentences) AS sen, UNNEST (sen.annotations) AS annotation WHERE type='CONVERSATION_SUMMARIZATION_SUGGESTION' ) SELECT countif (suggestedSummary IS NOT NULL) AS totalSummaries, countif (editedSummary IS NOT NULL) AS editedSummaries, countif (editedSummary IS NOT NULL) / countif (suggestedSummary IS NOT NULL) AS editRate FROM summaryAndEdits;