Auf dieser Seite wird gezeigt, wie Sie einen Nutzercluster für Google Distributed Cloud konfigurieren, sodass benutzerdefinierte Logs und Messwerte aus Nutzeranwendungen an Cloud Logging und Cloud Monitoring gesendet werden. Die Messwerte aus Nutzeranwendungen werden mit Google Cloud Managed Service for Prometheus erfasst.
Managed Service for Prometheus für Nutzeranwendungen aktivieren
Die Konfiguration für Managed Service for Prometheus wird in einem Stackdriver-Objekt namens stackdriver gespeichert.
Öffnen Sie das Objekt
stackdriverzum Bearbeiten:kubectl --kubeconfig=USER_CLUSTER_KUBECONFIG --namespace kube-system edit stackdriver stackdriver
Ersetzen Sie USER_CLUSTER_KUBECONFIG durch den Pfad der kubeconfig-Datei des Nutzerclusters.
Legen Sie unter
specden WertenableGMPForApplicationsauftruefest:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: ... clusterName: ... clusterLocation: ... proxyConfigSecretName: ... enableGMPForApplications: true enableVPC: ... optimizedMetrics: trueSchließen Sie die bearbeitete Datei. Dadurch werden von Google verwaltete Prometheus-Komponenten (GMP) im Cluster ausgeführt.
Prüfen Sie die Komponenten mit dem folgenden Befehl:
kubectl --kubeconfig=USER_CLUSTER_KUBECONFIG --namespace gmp-system get pods
Die Ausgabe dieses Befehls sieht wie folgt aus:
NAME READY STATUS RESTARTS AGE collector-abcde 2/2 Running 1 (5d18h ago) 5d18h collector-fghij 2/2 Running 1 (5d18h ago) 5d18h collector-klmno 2/2 Running 1 (5d18h ago) 5d18h gmp-operator-68d49656fc-abcde 1/1 Running 0 5d18h rule-evaluator-7c686485fc-fghij 2/2 Running 1 (5d18h ago) 5d18h
Managed Service for Prometheus unterstützt die Regelauswertung und Benachrichtigungen. Informationen zum Einrichten der Regelauswertung finden Sie unter Regelauswertung.
Beispielanwendung ausführen
In diesem Abschnitt erstellen Sie eine Anwendung, die Prometheus-Messwerte ausgibt, und verwenden von Google verwaltete Prometheus, um die Messwerte zu erfassen. Weitere Informationen finden Sie unter Google Cloud Managed Service for Prometheus.
Beispielanwendung bereitstellen
Erstellen Sie den Namespace
gmp-testfür Ressourcen, die Sie als Teil der Beispielanwendung erstellen:kubectl --kubeconfig=USER_CLUSTER_KUBECONFIG create ns gmp-test
Der verwaltete Dienst stellt ein Manifest für eine Beispielanwendung bereit, die Prometheus-Messwerte am
metrics-Port ausgibt. Die Anwendung verwendet drei Replikate.Führen Sie den folgenden Befehl aus, um die Beispielanwendung bereitzustellen:
kubectl --kubeconfig USER_CLUSTER_KUBECONFIG -n gmp-test apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.4.1/examples/example-app.yaml
PodMonitoring-Ressource konfigurieren
Zur Aufnahme der von der Beispielanwendung ausgegebenen Messwertdaten verwenden Sie Ziel-Scraping. Der verwaltete Dienst verwendet zum Konfigurieren von Ziel-Extraktion und Messwert-Aufnahme benutzerdefinierte PodMonitoring-Ressourcen (CRs). Sie können Ihre vorhandenen Prometheus-Operator-Ressourcen in PodMonitoring-CRs konvertieren.
Eine PodMonitoring-CR scrapt Ziele nur in dem Namespace, in dem die CR bereitgestellt wird. Wenn Sie Ziele in mehreren Namespaces scrapen möchten, stellen Sie in jedem Namespace dieselbe PodMonitoring-CR bereit. Mit dem folgenden Befehl können Sie prüfen, ob die PodMonitoring-Ressource im gewünschten Namespace installiert ist:
kubectl --kubeconfig USER_CLUSTER_KUBECONFIG get podmonitoring -A
Eine Referenzdokumentation zu allen CRs für Managed Service for Prometheus finden Sie in der Referenz zu prometheus-engine/doc/api.
Das folgende Manifest definiert die PodMonitoring-Ressource prom-example im Namespace gmp-test. Die Ressource findet alle Pods im Namespace mit dem Label app mit dem Wert prom-example. Die übereinstimmenden Pods werden an einem Port mit dem Namen metrics alle 30 Sekunden über den /metrics-HTTP-Pfad extrahiert.
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: prom-example
spec:
selector:
matchLabels:
app: prom-example
endpoints:
- port: metrics
interval: 30s
Führen Sie folgenden Befehl aus, um diese Ressource anzuwenden:
kubectl --kubeconfig USER_CLUSTER_KUBECONFIG -n gmp-test apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.4.1/examples/pod-monitoring.yaml
Managed Service for Prometheus extrahiert jetzt übereinstimmende Pods.
Messwertdaten abfragen
Am einfachsten können Sie prüfen, ob Ihre Prometheus-Daten exportiert werden, indem Sie PromQL-Abfragen im Metrics Explorer in der Google Cloud Console verwenden.
So führen Sie eine PromQL-Abfrage aus:
Rufen Sie in der Google Cloud Console die Seite Monitoring auf oder klicken Sie auf die folgende Schaltfläche:
Wählen Sie im Navigationsbereich
 Metrics Explorer aus.
Metrics Explorer aus.Geben Sie mit der Prometheus-Abfragesprache (PromQL) die Daten an, die im Diagramm dargestellt werden sollen:
Wählen Sie in der Symbolleiste des Bereichs Messwert auswählen die Option Code-Editor aus.
Wählen Sie im Menü Sprache die Ein/Aus-Schaltfläche PromQL aus. Die Sprachumschaltung befindet sich unten im Bereich Code-Editor.
Geben Sie eine Abfrage in den Abfrageeditor ein. Wenn Sie beispielsweise die durchschnittliche Anzahl der Sekunden, die die CPUs in den einzelnen Modi in der letzten Stunde verbracht haben, grafisch darstellen möchten, verwenden Sie die folgende Abfrage:
avg(rate(kubernetes_io:anthos_container_cpu_usage_seconds_total {monitored_resource="k8s_node"}[1h]))
Weitere Informationen zur Verwendung von PromQL finden Sie unter PromQL in Cloud Monitoring.
Der folgende Screenshot zeigt ein Diagramm mit dem Messwert anthos_container_cpu_usage_seconds_total:
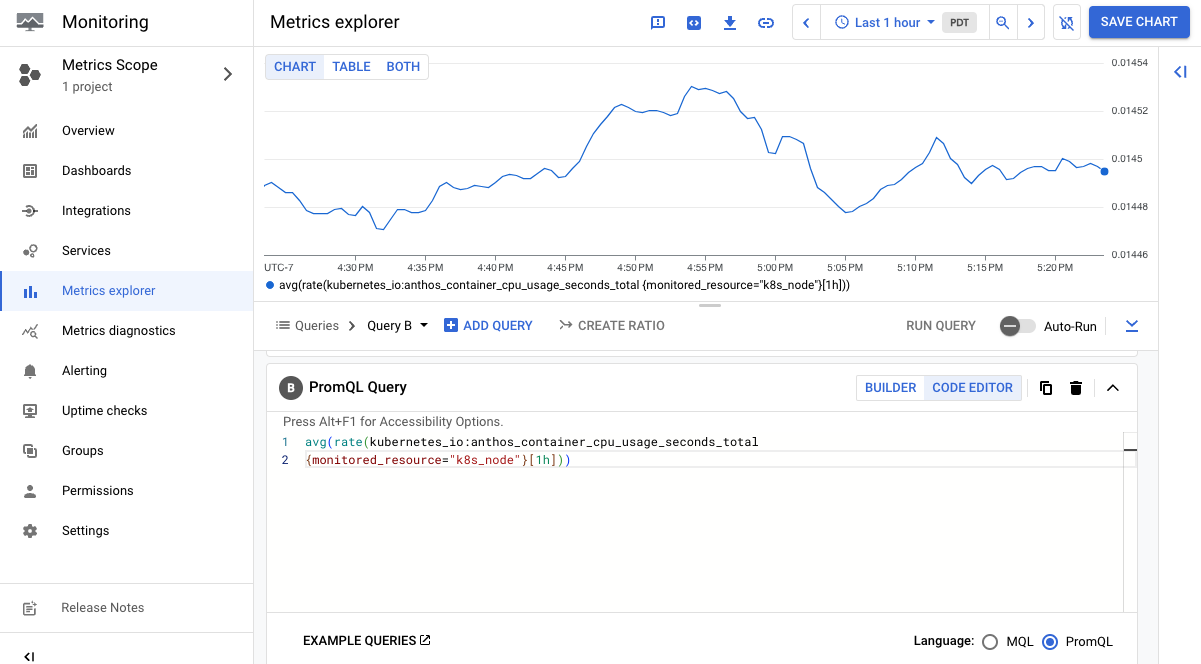
Wenn Sie viele Daten erfassen, können Sie exportierte Messwerte filtern, um die Kosten niedrig zu halten.
Cloud Logging für Nutzeranwendungen aktivieren
Die Konfiguration für Logging wird in einem Stackdriver-Objekt namens Stackdriver gespeichert.
Öffnen Sie das Objekt
stackdriverzum Bearbeiten:kubectl --kubeconfig=USER_CLUSTER_KUBECONFIG --namespace kube-system edit stackdriver stackdriver
Ersetzen Sie USER_CLUSTER_KUBECONFIG durch den Pfad der kubeconfig-Datei des Nutzerclusters.
Legen Sie unter
specden WertenableCloudLoggingForApplicationsauftruefest:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: ... clusterName: ... clusterLocation: ... proxyConfigSecretName: ... enableCloudLoggingForApplications: true enableVPC: ... optimizedMetrics: trueSchließen Sie die bearbeitete Datei.
Beispielanwendung ausführen
In diesem Abschnitt erstellen Sie eine Anwendung, die benutzerdefinierte Logs schreibt.
Speichern Sie das folgende Deployment-Manifest in eine Datei mit dem Namen
my-app.yaml.apiVersion: apps/v1 kind: Deployment metadata: name: "monitoring-example" namespace: "default" labels: app: "monitoring-example" spec: replicas: 1 selector: matchLabels: app: "monitoring-example" template: metadata: labels: app: "monitoring-example" spec: containers: - image: gcr.io/google-samples/prometheus-dummy-exporter:latest name: prometheus-example-exporter imagePullPolicy: Always command: - /bin/sh - -c - ./prometheus-dummy-exporter --metric-name=example_monitoring_up --metric-value=1 --port=9090 resources: requests: cpu: 100mErstellen Sie das Deployment:
kubectl --kubeconfig USER_CLUSTER_KUBECONFIG apply -f my-app.yaml
Anwendungslogs ansehen
Console
Rufen Sie in der Google Cloud Console den Log-Explorer auf.
Klicken Sie auf Ressource. Wählen Sie unter ALL_RESOURCE_TYPES die Option
Kubernetes Containeraus.Wählen Sie unter CLUSTER_NAME den Namen Ihres Nutzerclusters aus.
Wählen Sie unter NAMESPACE_NAME die Option
defaultaus.Klicken Sie auf Hinzufügen und dann auf Abfrage ausführen.
Unter Abfrageergebnisse sehen Sie die Logeinträge des Deployment
monitoring-example. Beispiel:{ "textPayload": "2020/11/14 01:24:24 Starting to listen on :9090\n", "insertId": "1oa4vhg3qfxidt", "resource": { "type": "k8s_container", "labels": { "pod_name": "monitoring-example-7685d96496-xqfsf", "cluster_name": ..., "namespace_name": "default", "project_id": ..., "location": "us-west1", "container_name": "prometheus-example-exporter" } }, "timestamp": "2020-11-14T01:24:24.358600252Z", "labels": { "k8s-pod/pod-template-hash": "7685d96496", "k8s-pod/app": "monitoring-example" }, "logName": "projects/.../logs/stdout", "receiveTimestamp": "2020-11-14T01:24:39.562864735Z" }
gcloud
Führen Sie folgenden Befehl aus:
gcloud logging read 'resource.labels.project_id="PROJECT_ID" AND \ resource.type="k8s_container" AND resource.labels.namespace_name="default"'Ersetzen Sie PROJECT_ID durch die ID Ihres Logging-Monitoring-Projekts.
In der Ausgabe sehen Sie die Logeinträge des Deployments
monitoring-example. Beispiel:insertId: 1oa4vhg3qfxidt labels: k8s-pod/app: monitoring-example k8s- pod/pod-template-hash: 7685d96496 logName: projects/.../logs/stdout receiveTimestamp: '2020-11-14T01:24:39.562864735Z' resource: labels: cluster_name: ... container_name: prometheus-example-exporter location: us-west1 namespace_name: default pod_name: monitoring-example-7685d96496-xqfsf project_id: ... type: k8s_container textPayload: | 2020/11/14 01:24:24 Starting to listen on :9090 timestamp: '2020-11-14T01:24:24.358600252Z'
Anwendungslogs filtern
Durch das Filtern von Anwendungslogs können die Abrechnung für das Anwendungs-Logging und der Netzwerkverkehr vom Cluster zu Cloud Logging reduziert werden. Ab Google Distributed Cloud-Release 1.15.0 können Sie Anwendungslogs nach den folgenden Kriterien filtern, wenn enableCloudLoggingForApplications auf true festgelegt ist:
- Pod-Labels (
podLabelSelectors) - Namespaces (
namespaces) - Reguläre Ausdrücke für Protokollinhalte (
contentRegexes)
Google Distributed Cloud sendet nur die Filterergebnisse an Cloud Logging.
Anwendungslogfilter definieren
Die Konfiguration für Logging wird in einem Stackdriver-Objekt namens stackdriver angegeben.
Öffnen Sie das Objekt
stackdriverzum Bearbeiten:kubectl --kubeconfig USER_CLUSTER_KUBECONFIG --namespace kube-system \ edit stackdriver stackdriverErsetzen Sie USER_CLUSTER_KUBECONFIG durch den Pfad der kubeconfig-Datei des Nutzerclusters.
Fügen Sie dem
speceinenappLogFilter-Abschnitt hinzu:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: enableCloudLoggingForApplications: true projectID: ... clusterName: ... clusterLocation: ... appLogFilter: keepLogRules: - namespaces: - prod ruleName: include-prod-logs dropLogRules: - podLabelSelectors: - disableGCPLogging=yes ruleName: drop-logsSpeichern und schließen Sie die bearbeitete Datei.
Optional: Wenn Sie
podLabelSelectorsverwenden, starten Sie dasstackdriver-log-forwarder-DaemonSet neu, damit Ihre Änderungen so schnell wie möglich wirksam werden:kubectl --kubeconfig USER_CLUSTER_KUBECONFIG --namespace kube-system \ rollout restart daemonset stackdriver-log-forwarderNormalerweise werden
podLabelSelectorsnach 10 Minuten wirksam. Wenn Sie das DaemonSetstackdriver-log-forwarderneu starten, werden die Änderungen schneller wirksam.
Beispiel: Nur ERROR- oder WARN-Logs im Namespace prod einbeziehen
Das folgende Beispiel veranschaulicht, wie ein Anwendungslogfilter funktioniert. Sie definieren einen Filter, der einen Namespace (prod), einen regulären Ausdruck (.*(ERROR|WARN).*) und ein Pod-Label (disableGCPLogging=yes) verwendet. Um zu prüfen, ob der Filter funktioniert, führen Sie dann einen Pod im Namespace prod aus, um diese Filterbedingungen zu testen.
So definieren und testen Sie einen Anwendungs-Log-Filter:
Geben Sie im Stackdriver-Objekt einen Anwendungs-Log-Filter an:
Im folgenden
appLogFilter-Beispiel werden nurERROR- oderWARN-Logs improd-Namespace beibehalten. Alle Logs für Pods mit dem LabeldisableGCPLogging=yeswerden verworfen:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: ... appLogFilter: keepLogRules: - namespaces: - prod contentRegexes: - ".*(ERROR|WARN).*" ruleName: include-prod-logs dropLogRules: - podLabelSelectors: - disableGCPLogging=yes # kubectl label pods pod disableGCPLogging=yes ruleName: drop-logs ...Pod im Namespace
prodbereitstellen und ein Script ausführen, dasERRORundINFO-Logeinträge generiert:kubectl --kubeconfig USER_CLUSTER_KUBECONFIG run pod1 \ --image gcr.io/cloud-marketplace-containers/google/debian10:latest \ --namespace prod --restart Never --command -- \ /bin/sh -c "while true; do echo 'ERROR is 404\\nINFO is not 404' && sleep 1; done"Die gefilterten Logs sollten nur die
ERROR-Einträge enthalten, nicht dieINFO-Einträge.Fügen Sie dem Pod das Label
disableGCPLogging=yeshinzu:kubectl --kubeconfig USER_CLUSTER_KUBECONFIG label pods pod1 \ --namespace prod disableGCPLogging=yesDas gefilterte Log sollte keine Einträge für den
pod1-Pod mehr enthalten.
API-Definition für Anwendungs-Log-Filter
Die Definition für den Anwendungs-Log-Filter wird in der benutzerdefinierten Ressourcendefinition des Stackdrivers angegeben.
Führen Sie den folgenden Befehl aus, um die benutzerdefinierte Ressourcendefinition für Stackdriver abzurufen:
kubectl --kubeconfig USER_CLUSTER_KUBECONFIG get crd stackdrivers.addons.gke.io \
--namespace kube-system -o yaml