En este tutorial se describe cómo configurar y realizar una búsqueda vectorial en AlloyDB para PostgreSQL con la consola. Google Cloud Los ejemplos se incluyen para mostrar las funciones de búsqueda vectorial y solo tienen fines de demostración.
Para obtener información sobre cómo usar la búsqueda de vectores filtrada para acotar las búsquedas de similitud, consulta Búsqueda de vectores filtrada en AlloyDB para PostgreSQL.
Para saber cómo realizar una búsqueda de vectores con las incrustaciones de Vertex AI, consulta Primeros pasos con las incrustaciones de vectores en AlloyDB AI.
Objetivos
- Crea un clúster y una instancia principal de AlloyDB.
- Conéctate a tu base de datos e instala las extensiones necesarias.
- Crea una tabla de
producty otra deproduct inventory. - Inserta datos en las tablas
productyproduct inventory, y realiza una búsqueda de vectores básica. - Crea un índice de ScaNN en la tabla de productos.
- Realiza una búsqueda vectorial sencilla.
- Realiza una búsqueda vectorial compleja con un filtro y una unión.
Costes
En este documento, se utilizan los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costes basada en el uso previsto,
utiliza la calculadora de precios.
Cuando termines las tareas que se describen en este documento, puedes evitar que se te siga facturando eliminando los recursos que has creado. Para obtener más información, consulta la sección Limpiar.
Antes de empezar
Habilitar la facturación y las APIs necesarias
En la Google Cloud consola, ve a la página Clusters.
Comprueba que la facturación esté habilitada en tu Google Cloud proyecto.
Habilita las APIs de Cloud necesarias para crear una instancia de AlloyDB para PostgreSQL y conectarte a ella.
- En el paso Confirmar proyecto, haz clic en Siguiente para confirmar el nombre del proyecto que vas a modificar.
En el paso Habilitar APIs, haz clic en Habilitar para habilitar lo siguiente:
- API de AlloyDB
- API de Compute Engine
- API Service Networking
- API de Vertex AI
Crear un clúster y una instancia principal de AlloyDB
En la Google Cloud consola, ve a la página Clusters.
Haz clic en Crear clúster.
En ID de clúster, introduzca
my-cluster.Introduce una contraseña. Anota esta contraseña, ya que la usarás en este tutorial.
Selecciona una región (por ejemplo,
us-central1 (Iowa)).Selecciona la red predeterminada.
Si tienes una conexión de acceso privado, ve al siguiente paso. De lo contrario, haz clic en Configurar conexión y sigue estos pasos:
- En Asignar intervalo de IP, haga clic en Usar un intervalo de direcciones IP asignado automáticamente.
- Haz clic en Continuar y, a continuación, en Crear conexión.
En Disponibilidad por zona, selecciona Una sola zona.
Selecciona el tipo de máquina
2 vCPU,16 GB.En Conectividad, seleccione Habilitar IP pública.
Haz clic en Crear clúster. AlloyDB puede tardar varios minutos en crear el clúster y mostrarlo en la página Resumen del clúster principal.
En Instancias de tu clúster, despliega el panel Conectividad. Anota el URI de conexión, ya que lo usarás en este tutorial.
El URI de conexión tiene el formato
projects/<var>PROJECT_ID</var>/locations/<var>REGION_ID</var>/clusters/my-cluster/instances/my-cluster-primary.
Conceder permiso de usuario de Vertex AI al agente de servicio de AlloyDB
Para habilitar AlloyDB para que use modelos de inserción de texto de Vertex AI, debes añadir permisos de usuario de Vertex AI al agente de servicio de AlloyDB del proyecto en el que se encuentren tu clúster y tu instancia.
Para obtener más información sobre cómo añadir los permisos, consulta Conceder permiso de usuario de Vertex AI al agente de servicio de AlloyDB.
Conectarse a una base de datos con un navegador web
En la Google Cloud consola, ve a la página Clusters.
En la columna Nombre del recurso, haz clic en el nombre de tu clúster,
my-cluster.En el panel de navegación, haga clic en AlloyDB Studio.
En la página Iniciar sesión en AlloyDB Studio, sigue estos pasos:
- Selecciona la base de datos
postgres. - Selecciona el usuario
postgres. - Introduce la contraseña que has creado en Crear un clúster y su instancia principal.
- Haz clic en Autenticar. En el panel Explorador se muestra una lista de los objetos de la base de datos
postgres.
- Selecciona la base de datos
Abre una pestaña nueva haciendo clic en + Nueva pestaña del editor de SQL o en + Nueva pestaña.
Instalar las extensiones necesarias
Ejecuta la siguiente consulta para instalar las extensiones vector y alloydb_scann:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Insertar datos de productos y de inventario de productos, y realizar una búsqueda de vectores básica
Ejecuta la siguiente instrucción para crear una tabla
productque haga lo siguiente:- Almacena información básica del producto.
- Incluye una columna de vector
embeddingque calcula y almacena un vector de inserción para la descripción de cada producto.
CREATE TABLE product ( id INT PRIMARY KEY, name VARCHAR(255) NOT NULL, description TEXT, category VARCHAR(255), color VARCHAR(255), embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005', description)) STORED );Si es necesario, puedes usar el Explorador de registros para ver los registros y solucionar errores.
Ejecute la siguiente consulta para crear una tabla
product_inventoryque almacene información sobre el inventario disponible y los precios correspondientes. En este tutorial, se usan las tablasproduct_inventoryyproductpara ejecutar consultas de búsqueda de vectores complejas.CREATE TABLE product_inventory ( id INT PRIMARY KEY, product_id INT REFERENCES product(id), inventory INT, price DECIMAL(10,2) );Ejecuta la siguiente consulta para insertar datos de producto en la tabla
product:INSERT INTO product (id, name, description,category, color) VALUES (1, 'Stuffed Elephant', 'Soft plush elephant with floppy ears.', 'Plush Toys', 'Gray'), (2, 'Remote Control Airplane', 'Easy-to-fly remote control airplane.', 'Vehicles', 'Red'), (3, 'Wooden Train Set', 'Classic wooden train set with tracks and trains.', 'Vehicles', 'Multicolor'), (4, 'Kids Tool Set', 'Toy tool set with realistic tools.', 'Pretend Play', 'Multicolor'), (5, 'Play Food Set', 'Set of realistic play food items.', 'Pretend Play', 'Multicolor'), (6, 'Magnetic Tiles', 'Set of colorful magnetic tiles for building.', 'Construction Toys', 'Multicolor'), (7, 'Kids Microscope', 'Microscope for kids with different magnification levels.', 'Educational Toys', 'White'), (8, 'Telescope for Kids', 'Telescope designed for kids to explore the night sky.', 'Educational Toys', 'Blue'), (9, 'Coding Robot', 'Robot that teaches kids basic coding concepts.', 'Educational Toys', 'White'), (10, 'Kids Camera', 'Durable camera for kids to take pictures and videos.', 'Electronics', 'Pink'), (11, 'Walkie Talkies', 'Set of walkie talkies for kids to communicate.', 'Electronics', 'Blue'), (12, 'Karaoke Machine', 'Karaoke machine with built-in microphone and speaker.', 'Electronics', 'Black'), (13, 'Kids Drum Set', 'Drum set designed for kids with adjustable height.', 'Musical Instruments', 'Blue'), (14, 'Kids Guitar', 'Acoustic guitar for kids with nylon strings.', 'Musical Instruments', 'Brown'), (15, 'Kids Keyboard', 'Electronic keyboard with different instrument sounds.', 'Musical Instruments', 'Black'), (16, 'Art Easel', 'Double-sided art easel with chalkboard and whiteboard.', 'Arts & Crafts', 'White'), (17, 'Finger Paints', 'Set of non-toxic finger paints for kids.', 'Arts & Crafts', 'Multicolor'), (18, 'Modeling Clay', 'Set of colorful modeling clay.', 'Arts & Crafts', 'Multicolor'), (19, 'Watercolor Paint Set', 'Watercolor paint set with brushes and palette.', 'Arts & Crafts', 'Multicolor'), (20, 'Beading Kit', 'Kit for making bracelets and necklaces with beads.', 'Arts & Crafts', 'Multicolor'), (21, '3D Puzzle', '3D puzzle of a famous landmark.', 'Puzzles', 'Multicolor'), (22, 'Race Car Track Set', 'Race car track set with cars and accessories.', 'Vehicles', 'Multicolor'), (23, 'RC Monster Truck', 'Remote control monster truck with oversized tires.', 'Vehicles', 'Green'), (24, 'Train Track Expansion Set', 'Expansion set for wooden train tracks.', 'Vehicles', 'Multicolor');Opcional: Ejecuta la siguiente consulta para verificar que los datos se han insertado en la tabla
product:SELECT * FROM product;Ejecute la siguiente consulta para insertar datos de inventario en la tabla
product_inventory:INSERT INTO product_inventory (id, product_id, inventory, price) VALUES (1, 1, 9, 13.09), (2, 2, 40, 79.82), (3, 3, 34, 52.49), (4, 4, 9, 12.03), (5, 5, 36, 71.29), (6, 6, 10, 51.49), (7, 7, 7, 37.35), (8, 8, 6, 10.87), (9, 9, 7, 42.47), (10, 10, 3, 24.35), (11, 11, 4, 10.20), (12, 12, 47, 74.57), (13, 13, 5, 28.54), (14, 14, 11, 25.58), (15, 15, 21, 69.84), (16, 16, 6, 47.73), (17, 17, 26, 81.00), (18, 18, 11, 91.60), (19, 19, 8, 78.53), (20, 20, 43, 84.33), (21, 21, 46, 90.01), (22, 22, 6, 49.82), (23, 23, 37, 50.20), (24, 24, 27, 99.27);Ejecuta la siguiente consulta de búsqueda de vectores para encontrar productos similares a la palabra
music. Esto significa que, aunque la palabramusicno se mencione explícitamente en la descripción del producto, el resultado muestra productos que son relevantes para la consulta:SELECT * FROM product ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector LIMIT 3;El resultado de la consulta es el siguiente:
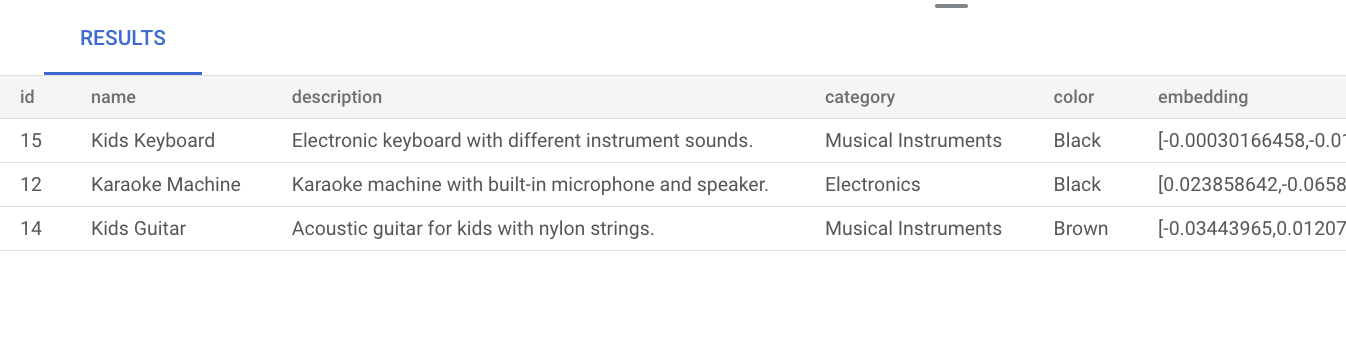
Si realizas una búsqueda vectorial básica sin crear un índice, se usará la búsqueda de vecinos más cercanos exactos (KNN), que proporciona un recuerdo eficiente. A gran escala, usar KNN puede afectar al rendimiento. Para mejorar el rendimiento de las consultas, te recomendamos que uses el índice ScaNN para la búsqueda de vecinos más cercanos aproximados (ANN), que proporciona un alto nivel de recuperación con latencias bajas.
Si no creas un índice, AlloyDB usará de forma predeterminada la búsqueda del vecino más cercano exacto (KNN).
Para obtener más información sobre cómo usar ScaNN a gran escala, consulta Primeros pasos con las incrustaciones de vectores en AlloyDB AI.
Crear un índice de ScaNN en la tabla de productos
Ejecuta la siguiente consulta para crear un índice product_index ScaNN en la tabla product:
CREATE INDEX product_index ON product
USING scann (embedding cosine)
WITH (num_leaves=5);
El parámetro num_leaves indica el número de nodos hoja con los que el índice basado en árbol crea el índice. Para obtener más información sobre cómo ajustar este parámetro, consulta Ajustar el rendimiento de las consultas vectoriales.
Hacer una búsqueda vectorial
Ejecuta la siguiente consulta de búsqueda de vectores para encontrar productos similares a la consulta en lenguaje natural music. Aunque la palabra music no se incluye en la descripción del producto, el resultado muestra productos relevantes para la consulta:
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
Los resultados de la consulta son los siguientes:

El parámetro de consulta scann.num_leaves_to_search controla el número de nodos hoja que se buscan durante una búsqueda de similitud. Los valores de los parámetros num_leaves y scann.num_leaves_to_search ayudan a conseguir un equilibrio entre el rendimiento y el recuerdo.
Realizar una búsqueda vectorial que use un filtro y una combinación
Puedes ejecutar consultas de búsqueda de vectores filtradas de forma eficiente incluso cuando usas el índice ScaNN. Ejecuta la siguiente consulta de búsqueda vectorial compleja, que devuelve resultados relevantes que cumplen las condiciones de la consulta, incluso con filtros:
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product p
JOIN product_inventory pi ON p.id = pi.product_id
WHERE pi.price < 80.00
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
Acelerar la búsqueda vectorial filtrada
Puede usar el motor columnar para mejorar el rendimiento de las búsquedas de similitud vectorial, en concreto las búsquedas de los k vecinos más cercanos (KNN), cuando se combina con un filtrado de predicados altamente selectivo (por ejemplo, mediante LIKE) en bases de datos. En esta sección, usarás la extensión vector y la extensión AlloyDB
google_columnar_engine.
Las mejoras de rendimiento se deben a la eficiencia integrada del motor de columnas
al analizar grandes conjuntos de datos y aplicar filtros, como los predicados LIKE, junto con su capacidad de prefiltrar filas mediante la compatibilidad con vectores.
Esta función reduce el número de subconjuntos de datos necesarios para los cálculos posteriores de distancia vectorial KNN y ayuda a optimizar las consultas analíticas complejas que implican filtrado estándar y búsqueda vectorial.
Para comparar el tiempo de ejecución de una búsqueda de vectores de KNN filtrada por un LIKEpredicado antes y después de habilitar el motor columnar, sigue estos pasos:
Habilita la extensión
vectorpara admitir tipos de datos vectoriales y operaciones. Ejecuta las siguientes instrucciones para crear una tabla de ejemplo (items) con un ID, una descripción de texto y una columna de inserción de vector de 512 dimensiones.CREATE EXTENSION IF NOT EXISTS vector; CREATE TABLE items ( id SERIAL PRIMARY KEY, description TEXT, embedding VECTOR(512) );Rellena los datos ejecutando las siguientes instrucciones para insertar 1 millón de filas en la tabla de ejemplo
items.-- Simplified example of inserting matching (~0.1%) and non-matching data INSERT INTO items (description, embedding) SELECT CASE WHEN g % 1000 = 0 THEN 'product_' || md5(random()::text) || '_common' -- ~0.1% match ELSE 'generic_item_' || g || '_' || md5(random()::text) -- ~99.9% don't match END, random_vector(512) -- Assumes random_vector function exists FROM generate_series(1, 999999) g;Mide el rendimiento de referencia de la búsqueda de similitud de vectores sin el motor de columnas.
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;Para habilitar el motor columnar y la compatibilidad con vectores, ejecuta el siguiente comando en la CLI de Google Cloud. Para usar gcloud CLI, puedes instalar e inicializar gcloud CLI.
gcloud beta alloydb instances update INSTANCE_ID \ --cluster=CLUSTER_ID \ --region=REGION_ID \ --project=PROJECT_ID \ --database-flags=google_columnar_engine.enabled=on,google_columnar_engine.enable_vector_support=onAñada la tabla
itemsal buscador columnar:SELECT google_columnar_engine_add('items');Mide el rendimiento de la búsqueda de similitud de vectores con el motor columnar. Vuelve a ejecutar la consulta que ya habías ejecutado para medir el rendimiento de referencia.
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;Para comprobar si la consulta se ha ejecutado con el motor columnar, ejecuta el siguiente comando:
explain (analyze) SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;
Limpieza
En la Google Cloud consola, ve a la página Clusters.
En la columna Nombre del recurso, haz clic en el nombre de tu clúster,
my-cluster.Haz clic en delete Eliminar clúster.
En Eliminar clúster my-cluster, introduce
my-clusterpara confirmar que quieres eliminar el clúster.Haz clic en Eliminar.
Si has creado una conexión privada al crear un clúster, ve a la página Redes de la consola Google Cloud y haz clic en Eliminar red de VPC.
Siguientes pasos
- Consulta casos prácticos reales de búsqueda vectorial.
- Empieza a usar las incrustaciones de vectores con AlloyDB AI.
- Consulta cómo crear aplicaciones de IA generativa con AlloyDB AI.
- Crea un índice de ScaNN.
- Ajusta tus índices de ScaNN.
- Consulta cómo crear un asistente de compras inteligente con AlloyDB, pgvector y la gestión de endpoints de modelos.
- Soluciona los errores con el Explorador de registros.