Connectors get data from Google and third-party data sources into Agentspace, storing it in dedicated data stores. This document provides an overview of these connectors. Centralizing your data in Agentspace enhances data accessibility, search functionality, and analytical capabilities.
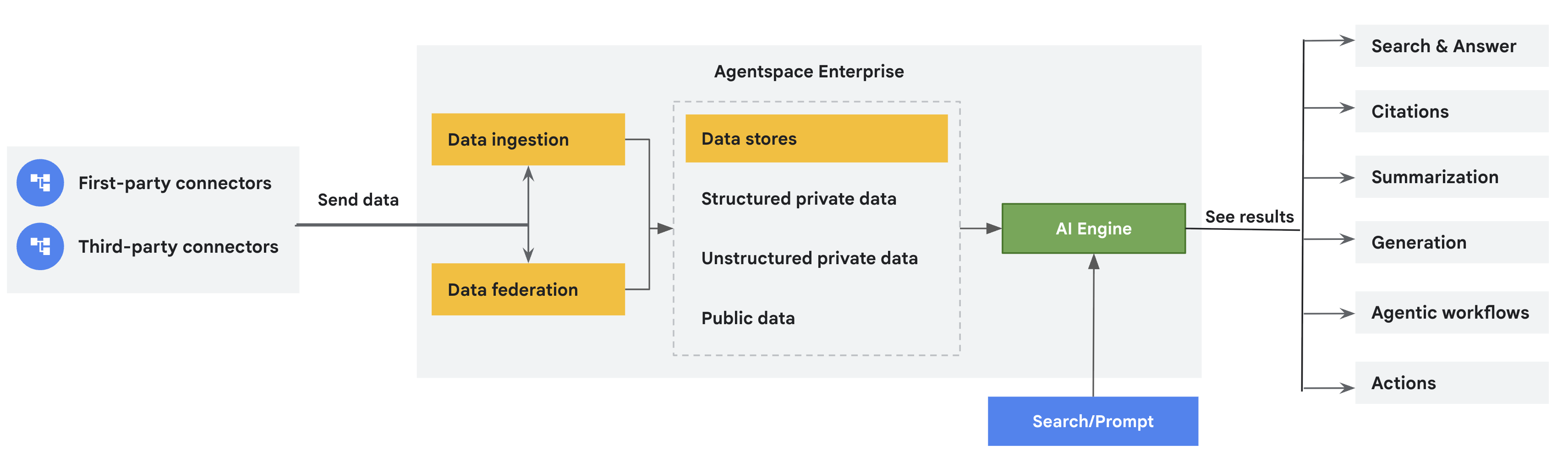
Connector and data store concepts
Data stores |
| Each data source supports a set of entity types. For example, Jira Cloud has entities such as issues, attachments, comments, and worklogs, which are unique to the data source. Agentspace creates a separate data store for each entity. Therefore, when you create a data store using the Google Cloud console, you get a collection of data stores representing these ingested data entities. |
Data federation versus ingestion (indexing) |
| Data federation directly retrieves information from the specified data source. Because data isn't copied into the Vertex AI Search index, you don't need to worry about data storage. However, because the data is not indexed, search quality might be lower. Data ingestion (indexing) copies data into the Vertex AI Search index. This can result in improved search quality. However, this process consumes more storage and time. |
Unstructured data |
| The supported data format is specific to the data source and the entity type. If the content in an entity is stored in an unstructured format — such as HTML, PDF, TXT, PPTX, or DOCX — an unstructured data store is created by Vertex AI Search. For more information and supported file types, see Unstructured search. |
Structured data |
| The supported data format is specific to the data source and the entity type. If the content in an entity is stored in a structured format, a structured data store is created by Vertex AI Search. For more information, see Structured search. |
Data schemas |
| The data schema defines the data structure. When you import structured data using Agentspace, the system auto-detects the schema. You can use the auto-detected schema or define the schema using the API. For more information, see Provide or auto-detect a schema. |
Data store regions |
| When ingesting data, you need to select the region where you want to store the data, such as global, the US, or the EU. For more information, see Agentspace Locations. Data stored in the US or EU regions require data encryption. The default encryption is with Google-owned and Google-managed encryption keys, but alternatively, you can use customer-managed encryption keys. |
Data syncs |
A data sync pulls and updates identity data (such as roles, permissions, and users) and entity data (such as data related to a specific data source) from the original data source. For more information, see Data sync types and schedules. |
Data sync types and schedules
A data sync captures entity data, identity data, or both, and updates the contents of the data store in Agentspace.
Sync types
Data stores in Agentspace use two essential types of data sync:
A full sync captures the entire state of the third-party app or service. This includes additions, updates, and deletions. A full sync replaces the existing contents of the data store.
An incremental sync periodically captures entity data that has been added or updated since the last sync. It does not sync identity data or deletions of entity data.
You can schedule a full sync separately for the following data types:
An entity sync captures data specific to the third-party data source. For example, a data store for a system like Jira can sync issues, worklogs, comments, and attachments. Entity syncs don't include identity information.
An identity sync captures data about user accounts associated with an ACL group.
Interaction between identity sync and full sync
To understand how an individual identity sync run works with a full sync run,
consider an example scenario including two pages: page_1, linked to an ACL
group group_1; and page_2, linked to an ACL group group_2.
An initial identity sync runs, and retrieves information about groups
group_1andgroup_2.Assume that
group_1contains useruser_1.Assume that
group_2contains useruser_2.
This identity sync establishes the following mapping:
user_1maps togroup_1.user_2maps togroup_2.
Alongside the identity sync, a full sync runs, fetching both
page_1andpage_2.This full sync establishes the following mapping:
user_1has access topage_1(viagroup_1).user_2has access topage_2(viagroup_2).
Sync schedules
For each data store, you can select a frequency for different sync types:
Full syncs of all identity data and entity data can be scheduled simultaneously for every 3 hours, 6 hours, 12 hours, 1 day, or 3 days.
Independent full syncs of all identity data, and independent full syncs of all entity data, can be scheduled separately using any of the following custom sync frequencies:
Entity data: Every 3 hours, 6 hours, 12 hours, 1 day, 3 days, 5 days, and every 7 days.
Identity data: Every 30 minutes, 1 hour, 3 hours, 6 hours, 12 hours, 1 day, 3 days, 5 days, and every 7 days.
Incremental syncs of updated or added entity data can be scheduled for every 3 hours, 6 hours, 12 hours, 1 day, 3 days, 5 days, or every 7 days. By default, an incremental sync is performed every 3 hours.
Frequency recommendations
Choose a data sync frequency that aligns with the volume of records fetched and the recommended queries per second (QPS).
The following table shows the typical number of records retrieved for one, three, five, and seven-day syncs. The actual number of records may vary depending on the data source and its configuration.
| QPS | Record volume for 1-day sync | Record volume for 3-day sync | Record volume for 5-day sync | Record volume for 7-day sync |
|---|---|---|---|---|
| 5 | 432k | 1.296M | 2.16M | 3M |
| 10 | 864k | 2.592M | 4.32M | 6M |
| 20 | 1.7M | 5.1M | 8.5M | 11.9M |
| 50 | 4.3M | 12.9M | 21.5M | 30.1M |
| 100 | 8.6M | 25.8M | 43M | 60.2M |
Pausing and resuming syncs
You can pause, and resume, both full syncs and incremental syncs:
When you pause a sync type, the data store cancels ongoing syncs of that type and stops scheduling new syncs of that type.
When you resume a sync type, the data store schedules the new sync based on the last scheduled sync time, but does not continue the previously interrupted sync.
For example, if you pause full sync while a full sync is occurring, the data store cancels that sync. If you later resume full sync, the data store automatically schedules a new full sync according to the full sync schedule.
Google data sources
You can connect to Google data sources, such as BigQuery, Spanner, and Google Drive.
Checklist for Google data sources
Before sending data to Agentspace, go through the following checklist:
Set up access control for your data source. For more information see, Identity and permissions.
Decide whether data should be federated or ingested (indexed).
Decide how often the data should be synced.
If you are using customer-managed encryption keys (CMEK), create multi-region keys. For more information, see Register single-region keys for third-party data sources.
If you have personally identifiable information (PII) and intend to use autocomplete for query suggestions, see protect against PII leaks.
Supported Google data sources
| Google Drive | Gmail | Google Calendar | People search |

|

|

|

|
Third party data sources
Third-party data stores ingest third-party application data into Agentspace.
Checklist for third-party data sources
Before connecting a third-party data source to Agentspace, go through the following checklist:
Specific scopes and permissions must be configured for certain data sources. An administrator of the third-party application must review the required credentials to connect a data source and set up authentication and permissions. For information about the specific scopes and permissions, see the respective third-party data source documentation.
Set up access control for your data store. For more information, see Identity and permissions
Decide whether data should be federated or ingested (indexed).
If data is ingested, make sure that resources aren't restricted for the user credential that you use to ingest data into the data source.
Decide how often the data should be synced.
If you are using customer-managed encryption keys (CMEK), create multi-region and single-region keys. For more information, see Register single-region keys for third-party data stores.
If you have personally identifiable information (PII) and intend to use autocomplete for query suggestions, see protect against PII leaks.
Supported third-party data sources
| Microsoft Entra ID | Microsoft OneDrive | Microsoft Outlook | Microsoft SharePoint |
|
|
|
|
|
| Jira Cloud | Confluence Cloud | ServiceNow | |
|
|
|
|