Cloud TPU 多切片概览
Cloud TPU 多切片是一项全栈性能扩缩技术,可让训练作业在单个切片中或在多个 Pod 中的切片上使用多个 TPU 切片,并采用标准数据并行处理。使用 TPU v4 芯片时,这意味着训练作业可以在单次运行中使用超过 4096 个芯片。对于需要的芯片数少于 4096 个的训练作业,单个切片可以提供最佳性能。不过,多个较小的切片更容易获得,因此当将多切片与较小的切片搭配使用时,启动时间会更短。
在多切片配置中部署时,每个切片中的 TPU 芯片通过芯片间互连 (ICI) 进行通信。不同切片中的 TPU 芯片通过将数据传输到 CPU(主机)来进行通信,而 CPU 又会通过数据中心网络 (DCN) 传输数据。如需详细了解如何使用多切片进行扩容,请参阅如何使用多切片将 AI 训练扩容到多达数万个 Cloud TPU 芯片。
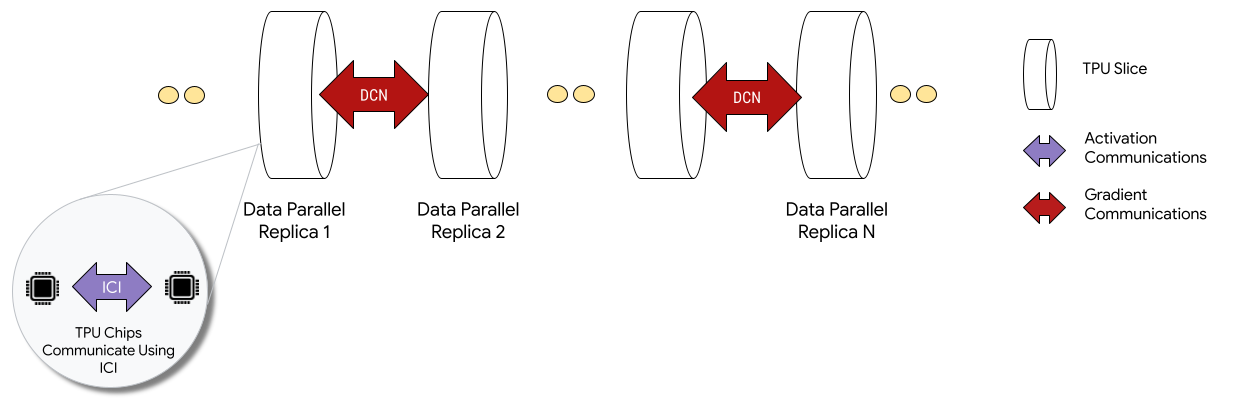
开发者无需编写代码即可实现芯片间 DCN 通信。XLA 编译器会为您生成该代码,并将通信与计算重叠,以实现最佳性能。
概念
- 加速器类型
- 构成多切片的每个 TPU 切片的形状。多切片请求中的每个切片都采用相同的加速器类型。加速器类型由 TPU 类型(v4 或更高版本)和紧随其后的 TensorCore 数量组成。例如,
v5litepod-128指定一个具有 128 个 TensorCore 的 TPU v5e。 - 自动修复
- 当切片遇到维护事件、抢占或硬件故障时,Cloud TPU 会创建新的切片。如果资源不足以创建新的切片,则在有可用硬件之前,创建操作将不会完成。创建新的切片后,多切片环境中的所有其他切片都会重启,以便继续训练。通过正确配置的启动脚本,训练脚本无需用户干预即可自动重新启动,并从最新的检查点加载和恢复。
- 数据中心网络 (DCN)
- 延迟时间较长、吞吐量较低的网络(与 ICI 相比),用于在多切片配置中连接 TPU 切片。
- Gang 调度
- 同时预配所有 TPU 切片时,保证所有切片都成功预配或都未成功预配。
- 芯片间互连
- 用于在 TPU Pod 内连接 TPU 的高速、低延迟内部链接。
- 多切片
- 两个或更多个可通过 DCN 进行通信的 TPU 芯片切片。
- 节点
- 在多切片上下文中,节点是指单个 TPU 切片。多切片中的每个 TPU 切片都有一个节点 ID。
- 启动脚本
- 每次启动或重新启动虚拟机时运行的标准 Compute Engine 启动脚本。对于多切片,该值在 QR 创建请求中指定。如需详细了解 Cloud TPU 启动脚本,请参阅管理 TPU 资源。
- Tensor
- 一种数据结构,用于在机器学习模型中表示多维数据。
- Cloud TPU 容量的类型
您可以使用不同类型的容量创建 TPU(请参阅 TPU 定价方式中的“使用选项”部分):
预留:如需使用预留,您必须与 Google 签订预留协议。创建资源时,请使用
--reserved标志。Spot:使用 Spot 虚拟机定位抢占式配额。系统可能会抢占您的资源,以便为更高优先级作业的请求留出空间。创建资源时,请使用
--spot标志。按需:定位按需配额,无需预留且不会被抢占。TPU 请求将排入 Cloud TPU 提供的按需配额队列,但无法保证有可用的资源。默认处于选中状态,无需标志。
开始使用
-
-
In the API Console, activate Cloud Shell.
At the bottom of the API Console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
ici_data_parallelismici_fsdp_parallelismici_tensor_parallelism设置环境:
$ gcloud auth login $ export QR_ID=your-queued-resource-id $ export TPU_NAME=your-tpu-name $ export PROJECT=your-project-name $ export ZONE=us-central1-a $ export NETWORK_NAME=your-network-name $ export SUBNETWORK_NAME=your-subnetwork-name $ export RUNTIME_VERSION=v2-alpha-tpuv5-lite $ export ACCELERATOR_TYPE=v5litepod-16 $ export EXAMPLE_TAG_1=your-tag-1 $ export EXAMPLE_TAG_2=your-tag-2 $ export SLICE_COUNT=4 $ export STARTUP_SCRIPT='#!/bin/bash\n'
变量说明
输入 说明 QR_ID 已排队的资源的用户分配 ID。 TPU_NAME 用户分配的 TPU 名称。 项目 Google Cloud 项目名称 ZONE 指定要在其中创建资源的可用区。 NETWORK_NAME VPC 网络的名称。 SUBNETWORK_NAME VPC 网络中子网的名称 RUNTIME_VERSION Cloud TPU 软件版本。 ACCELERATOR_TYPE v4-16 EXAMPLE_TAG_1、EXAMPLE_TAG_2 … 用于标识网络防火墙的有效来源或目标的标记。 SLICE_COUNT 切片数量。最多只能有 256 个切片。 STARTUP_SCRIPT 如果您指定了启动脚本,该脚本会在 TPU 切片预配或重启时运行。 为
gcloud创建 SSH 密钥。我们建议您将密码留空(运行以下命令后,按两次 Enter 键)。如果系统提示google_compute_engine文件已存在,请替换现有版本。$ ssh-keygen -f ~/.ssh/google_compute_engine
预配 TPU:
gcloud
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-id=${TPU_NAME} \ --zone=${ZONE} \ [--reserved |--spot]
Google Cloud CLI 不支持所有创建 QR 选项,例如标记。如需了解详情,请参阅创建 QR。
控制台
在 Google API 控制台中,前往 TPU 页面:
点击创建 TPU。
在名称字段中,输入 TPU 的名称。
在可用区框中,选择您要在其中创建 TPU 的可用区。
在 TPU 类型框中,选择加速器类型。加速器类型用于指定您要创建的 Cloud TPU 的版本和大小。如需详细了解每个 TPU 版本支持的加速器类型,请参阅 TPU 版本。
在 TPU 软件版本框中,选择软件版本。创建 Cloud TPU 虚拟机时,TPU 软件版本用于指定要安装的 TPU 运行时的版本。如需了解详情,请参阅 TPU 软件版本。
点击启用排队切换开关。
在已排队资源的名称字段中,输入已排队的资源请求的名称。
点击创建以创建已排队的资源请求。
等待已排队的资源处于
ACTIVE状态,这表示工作器节点处于READY状态。已排队的资源预配开始后,可能需要一到五分钟才能完成,具体取决于已排队资源的大小。您可以使用 gcloud CLI 或 Google API 控制台来检查已排队的资源请求的状态:gcloud
$ gcloud compute tpus queued-resources \ list --filter=${QR_ID} --zone=${ZONE}
控制台
在 Google API 控制台中,前往 TPU 页面:
点击已排队的资源标签页。
点击已排队的资源请求的名称。
使用 SSH 连接到 TPU 虚拟机:
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} --zone=${ZONE}
将 MaxText(包含
shardings.py)克隆到 TPU 虚拟机:$ git clone https://github.com/AI-Hypercomputer/maxtext && cd maxtext
安装 Python 3.10:
$ sudo apt-get update $ sudo apt install python3.10 $ sudo apt install python3.10-venv
创建并激活虚拟环境:
$ python3 -m venv your-venv-name $ source your-venv-name/bin/activate
在 MaxText 仓库目录中,运行设置脚本以在 TPU 切片上安装 JAX 和其他依赖项。运行设置脚本需要几分钟时间。
$ bash setup.sh
运行以下命令以在 TPU 切片上运行
shardings.py。$ python3 -m pedagogical_examples.shardings \ --ici_fsdp_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
您可以在日志中查看结果。TPU 应每秒达到大约 260 TFLOP 的性能,或者 FLOPS 利用率高达 90% 以上!在本例中,我们选择了 TPU 高带宽内存 (HBM) 中可容纳的大致最大批次。
您可以随意探索 ICI 之外的其他分片策略,例如,您可以尝试以下组合:
$ python3 -m pedagogical_examples.shardings \ --ici_tensor_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
完成后,删除已排队的资源和 TPU 切片。您应在设置切片的环境中运行这些清理步骤(先运行
exit以退出 SSH 会话)。删除操作需要两到五分钟才能完成。如果您使用的是 gcloud CLI,则可以在后台运行此命令并使用可选的--async标志。gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --force (--async)
控制台
在 Google API 控制台中,前往 TPU 页面:
点击已排队的资源标签页。
选中已排队的资源请求旁边的复选框。
点击 删除。
- dcn_data_parallelism
- dcn_fsdp_parallelism
- dcn_tensor_parallelism
在运行程序机器上克隆 MaxText:
$ git clone https://github.com/AI-Hypercomputer/maxtext
进入仓库目录。
$ cd maxtext
为
gcloud创建 SSH 密钥,我们建议您将密码留空(运行以下命令后,按两次 Enter 键)。如果系统提示google_compute_engine文件已存在,请选择不保留现有版本。$ ssh-keygen -f ~/.ssh/google_compute_engine
添加一个环境变量以将 TPU 切片数设置为
2。$ export SLICE_COUNT=2
使用
queued-resources create命令或 Google API 控制台创建多切片环境。gcloud
以下命令展示了如何创建 v5e 多切片 TPU。如需使用其他 TPU 版本,请指定其他
accelerator-type和runtime-version。$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-count=${SLICE_COUNT} \ --node-prefix=${TPU_NAME} \ --zone=${ZONE} \ [--reserved|--spot]
控制台
在 Google API 控制台中,前往 TPU 页面:
点击创建 TPU。
在名称字段中,输入 TPU 的名称。
在可用区框中,选择您要在其中创建 TPU 的可用区。
在 TPU 类型框中,选择加速器类型。加速器类型用于指定您要创建的 Cloud TPU 的版本和大小。只有 Cloud TPU v4 及更高的 TPU 版本支持多切片。如需详细了解 TPU 版本,请参阅 TPU 版本。
在 TPU 软件版本框中,选择软件版本。创建 Cloud TPU 虚拟机时,TPU 软件版本用于指定要安装在 TPU 虚拟机上的 TPU 运行时的版本。如需了解详情,请参阅 TPU 软件版本。
点击启用排队切换开关。
在已排队资源的名称字段中,输入已排队的资源请求的名称。
点击将此项设置为多切片 TPU 复选框。
在切片数字段中,输入要创建的切片数。
点击创建以创建已排队的资源请求。
已排队的资源预配开始后,最长可能需要五分钟才能完成,具体取决于已排队资源的大小。等待已排队的资源处于
ACTIVE状态。您可以使用 gcloud CLI 或 Google API 控制台来检查已排队的资源请求的状态:gcloud
$ gcloud compute tpus queued-resources list \ --filter=${QR_ID} --zone=${ZONE} --project=${PROJECT}
此命令应会生成如下所示的输出:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central2-b 4 v5litepod-16 ACTIVE ...
控制台
在 Google API 控制台中,前往 TPU 页面:
点击已排队的资源标签页。
点击已排队的资源请求的名称。
如果 QR 处于
WAITING_FOR_RESOURCES或PROVISIONING状态超过 15 分钟,请与您的 Google Cloud 客户代表联系。安装依赖项。
$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="bash setup.sh"
使用
multihost_runner.py在每个工作器上运行shardings.py。$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="python3 -m pedagogical_examples.shardings \ --dcn_data_parallelism ${SLICE_COUNT} \ --ici_fsdp_parallelism 16 \ --batch_size 131072 \ --embedding_dimension 2048"
您会在日志文件中看到每秒大约 230 TFLOP 的性能。
如需详细了解如何配置并行处理,请参阅使用 DCN 并行处理和
shardings.py进行多切片分片。完成后,清理 TPU 和已排队的资源。删除操作需要两到五分钟才能完成。如果您使用的是 gcloud CLI,则可以在后台运行此命令并使用可选的
--async标志。- 创建网格时,使用 jax.experimental.mesh_utils.create_hybrid_device_mesh,而不是 jax.experimental.mesh_utils.create_device_mesh。
- 使用实验运行程序脚本
multihost_runner.py - 使用生产运行程序脚本
multihost_job.py - 使用手动方法
使用以下命令创建已排队的资源请求:
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --project=${PROJECT} \ --zone=${ZONE} \ --node-count=${SLICE_COUNT} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --network=${NETWORK_NAME} \ --subnetwork=${SUBNETWORK_NAME} \ --tags=${EXAMPLE_TAG_1},${EXAMPLE_TAG_2} \ --metadata=startup-script="${STARTUP_SCRIPT}" \ [--reserved|--spot]
创建名为
queued-resource-req.json的文件,并将以下 JSON 复制到其中:{ "guaranteed": { "reserved": true }, "tpu": { "node_spec": [ { "parent": "projects/your-project-number/locations/your-zone", "node": { "accelerator_type": "accelerator-type", "runtime_version": "tpu-vm-runtime-version", "network_config": { "network": "your-network-name", "subnetwork": "your-subnetwork-name", "enable_external_ips": true }, "tags" : ["example-tag-1"] "metadata": { "startup-script": "your-startup-script" } }, "multi_node_params": { "node_count": slice-count, "node_id_prefix": "your-queued-resource-id" } } ] } }
替换以下值:
- your-project-number - 您的 Google Cloud 项目编号
- your-zone - 您要在其中创建已排队的资源的可用区
- accelerator-type - 单个切片的版本和大小。只有 Cloud TPU v4 及更高的 TPU 版本支持多切片。
- tpu-vm-runtime-version - 您要使用的 TPU 虚拟机运行时版本。
- your-network-name -(可选)将已排队的资源附加到的网络
- your-subnetwork-name -(可选)将已排队的资源附加到的子网
- example-tag-1 -(可选)任意标记字符串
- your-startup-script - 在分配已排队的资源时运行的启动脚本
- slice-count - 多切片环境中的 TPU 切片数量
- your-queued-resource-id - 已排队的资源的用户提供 ID
如需了解详情,请参阅 REST Queued Resource API 文档,以了解所有可用选项。
如需使用 Spot 容量,请进行以下替换:
"guaranteed": { "reserved": true }-"spot": {}移除该行以使用默认的按需容量。
提交包含 JSON 载荷的已排队的资源创建请求:
$ curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d @queuedresourcereq.json \ https://tpu.googleapis.com/v2alpha1/projects/your-project-id/locations/your-zone/queuedResources\?queued_resource_id\=your-queued-resource-id
替换以下值:
- your-project-id - 您的 Google Cloud 项目 ID
- your-zone - 您要在其中创建已排队的资源的可用区
- your-queued-resource-id - 已排队的资源的用户提供 ID
在 Google API 控制台中,前往 TPU 页面:
点击创建 TPU。
在名称字段中,输入 TPU 的名称。
在可用区框中,选择您要在其中创建 TPU 的可用区。
在 TPU 类型框中,选择加速器类型。加速器类型用于指定您要创建的 Cloud TPU 的版本和大小。只有 Cloud TPU v4 及更高的 TPU 版本支持多切片。如需详细了解每个 TPU 版本支持的加速器类型,请参阅 TPU 版本。
在 TPU 软件版本框中,选择软件版本。创建 Cloud TPU 虚拟机时,TPU 软件版本用于指定要安装的 TPU 运行时的版本。如需了解详情,请参阅 TPU 软件版本。
点击启用排队切换开关。
在已排队资源的名称字段中,输入已排队的资源请求的名称。
点击将此项设置为多切片 TPU 复选框。
在切片数字段中,输入要创建的切片数。
点击创建以创建已排队的资源请求。
在 Google API 控制台中,前往 TPU 页面:
点击已排队的资源标签页。
点击已排队的资源请求的名称。
在 Google API 控制台中,前往 TPU 页面:
点击已排队的资源标签页。
在 Google API 控制台中,前往 TPU 页面:
点击已排队的资源标签页。
选中已排队的资源请求旁边的复选框。
点击 删除。
- B 是批次大小(以 token 为单位)
- P 是参数数量
- 这会导致“流水线气泡”,其中芯片处于空闲状态,因为它们正在等待数据。
- 它需要进行微批处理,这会降低有效批次大小、算术强度,并最终降低模型 FLOP 利用率。
如需使用多切片,您的 TPU 资源必须作为已排队的资源进行管理。
入门示例
本教程使用 MaxText GitHub 代码库中的代码。MaxText 是一种高性能、可任意扩缩、开源且经过充分测试的基本 LLM,采用 Python 和 Jax 编写。MaxText 旨在能够在 Cloud TPU 上高效训练。
shardings.py 中的代码旨在帮助您开始尝试使用不同的并行处理选项。例如,数据并行处理、完全分片数据并行处理 (FSDP) 和张量并行处理。代码可从单切片环境扩容到多切片环境。
ICI 并行处理
ICI 是指用于连接单个切片中的 TPU 的高速互连。ICI 分片对应于切片内的分片。shardings.py 提供三个 ICI 并行处理参数:
您为这些参数指定的值决定了每个并行处理方法的分片数。
这些输入必须受到限制,以便 ici_data_parallelism * ici_fsdp_parallelism * ici_tensor_parallelism 等于切片中的芯片数。
下表展示了 v4-8 中可用的四个芯片的 ICI 并行处理的示例用户输入:
| ici_data_parallelism | ici_fsdp_parallelism | ici_tensor_parallelism | |
| 四向 FSDP | 1 | 4 | 1 |
| 四向张量并行处理 | 1 | 1 | 4 |
| 双向 FSDP + 双向张量并行处理 | 1 | 2 | 2 |
请注意,在大多数情况下,ici_data_parallelism 应保留为 1,因为 ICI 网络足够快,几乎总是优先使用 FSDP 而不是数据并行处理。
此示例假定您熟悉如何在单个 TPU 切片上运行代码,例如使用 JAX 在 Cloud TPU 虚拟机上运行计算。此示例展示了如何在单个切片上运行 shardings.py。
使用 DCN 并行处理进行多切片分片
shardings.py 脚本接受三个用于指定 DCN 并行处理的参数,这些参数对应于每种数据并行处理类型的分片数:
这些参数的值必须受到限制,以便 dcn_data_parallelism * dcn_fsdp_parallelism * dcn_tensor_parallelism 等于切片数。
例如,对于两个切片,请使用 --dcn_data_parallelism = 2。
| dcn_data_parallelism | dcn_fsdp_parallelism | dcn_tensor_parallelism | 切片数 | |
| 双向数据并行处理 | 2 | 1 | 1 | 2 |
dcn_tensor_parallelism 应始终设置为 1,因为 DCN 不适合此类分片。对于 v4 芯片上的典型 LLM 工作负载,dcn_fsdp_parallelism 也应设置为 1,因此 dcn_data_parallelism 应设置为切片数,但这取决于应用。
随着切片数量的增加(假设您保持切片大小和每个切片的批次不变),数据并行处理量也会增加。
在多切片环境中运行 shardings.py
您可以在多切片环境中使用 multihost_runner.py 运行 shardings.py,也可以在每个 TPU 虚拟机上运行 shardings.py。在这里,我们使用 multihost_runner.py。以下步骤与 MaxText 仓库中的使用入门:对多个切片进行快速实验中的步骤非常相似,只不过这里我们运行的是 shardings.py,而不是 train.py 中更复杂的 LLM。
multihost_runner.py 工具针对快速实验进行了优化,可重复使用相同的 TPU。由于 multihost_runner.py 脚本依赖于长期有效的 SSH 连接,因此我们不建议将其用于任何长时间运行的作业。如果您想运行较长时间的作业(例如数小时或数天),我们建议您使用 multihost_job.py。
在本教程中,我们使用“运行程序”一词来表示运行 multihost_runner.py 脚本的机器。我们使用“工作器”一词来表示构成切片的 TPU 虚拟机。您可以在本地机器上或与切片位于同一项目中的任何 Compute Engine 虚拟机上运行 multihost_runner.py。不支持在工作器上运行 multihost_runner.py。
multihost_runner.py 会自动使用 SSH 连接到 TPU 工作器。
在此示例中,您将在两个 v5e-16 切片(总共 4 个虚拟机和 16 个 TPU 芯片)上运行 shardings.py。您可以修改此示例,以便在更多 TPU 上运行。
设置环境
将工作负载扩容到多切片
在多切片环境中运行模型之前,请进行以下代码更改:
在迁移到多切片时,这些应该是唯一需要进行的代码更改。为了实现高性能,DCN 需要映射到数据并行、完全分片数据并行或流水线并行轴。如需详细了解性能注意事项和分片策略,请参阅使用多切片进行分片以实现最佳性能。
如需验证您的代码是否可以访问所有设备,您可以声明 len(jax.devices()) 等于多切片环境中的芯片数量。例如,如果您使用 v4-16 的四个切片,每个切片有八个芯片,总共四个切片,因此 len(jax.devices()) 应返回 32。
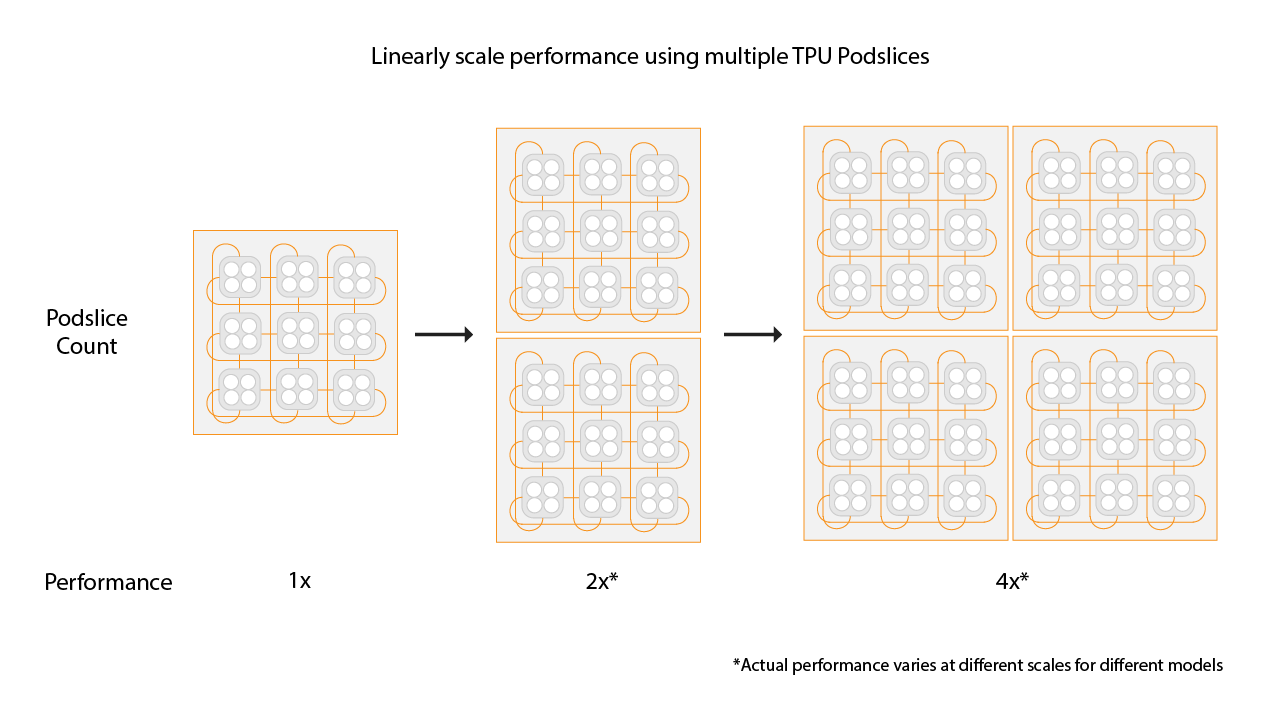
为多切片环境选择切片大小
如需实现线性加速,请添加与现有切片大小相同的新切片。例如,如果您使用 v4-512 切片,则通过添加第二个 v4-512 切片并将全局批次大小加倍,多切片的性能大约会翻倍。如需了解详情,请参阅使用多切片进行分片以实现最佳性能。
在多个切片上运行作业
您可以通过以下三种不同的方法在多切片环境中运行自定义工作负载:
实验运行程序脚本
multihost_runner.py 脚本会将代码分发到现有的多切片环境,并在每个主机上运行您的命令、复制回日志,以及跟踪每个命令的错误状态。MaxText 自述文件中记录了 multihost_runner.py 脚本。
由于 multihost_runner.py 会保持持久性 SSH 连接,因此它仅适用于规模适中且运行时间相对较短的实验。您可以根据自己的工作负载和硬件配置调整 multihost_runner.py 教程中的步骤。
生产运行程序脚本
对于需要针对硬件故障和其他抢占的恢复能力的生产作业,最好直接与 Create Queued Resource API 集成。使用 multihost_job.py 作为工作示例,该示例使用适当的启动脚本来触发 Created Queued Resource API 调用,以运行训练并在抢占时恢复。MaxText 自述文件中记录了 multihost_job.py 脚本。
由于 multihost_job.py 必须为每次运行预配资源,因此其迭代周期不如 multihost_runner.py 快。
手动方法
我们建议您使用或调整 multihost_runner.py 或 multihost_job.py,以在多切片配置中运行自定义工作负载。不过,如果您希望直接使用 QR 命令来配置和管理环境,请参阅管理多切片环境。
管理多切片环境
如需在不使用 MaxText 仓库中提供的工具的情况下手动预配和管理 QR,请参阅以下部分。
创建已排队的资源
gcloud
请先确保您拥有相应的配额,然后再选择 --reserved、--spot 或默认按需配额。如需了解配额类型,请参阅配额政策。
curl
响应应如下所示:
{ "name": "projects/<your-project-id>/locations/<your-zone>/operations/operation-<your-qr-guid>", "metadata": { "@type": "type.googleapis.com/google.cloud.common.OperationMetadata", "createTime": "2023-11-01T00:17:05.742546311Z", "target": "projects/<your-project-id>/locations/<your-zone>/queuedResources/<your-qa-id>", "verb": "create", "cancelRequested": false, "apiVersion": "v2alpha1" }, "done": false }
在 name 属性的字符串值末尾使用 GUID 值来获取有关已排队的资源请求的信息。
控制台
检索已排队的资源的状态
gcloud
$ gcloud compute tpus queued-resources describe ${QR_ID} --zone=${ZONE}
对于处于 ACTIVE 状态的已排队资源,输出如下所示:
...
state:
state: ACTIVE
...
curl
$ curl -X GET -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://tpu.googleapis.com/v2/projects/your-project-id/locations/your-zone/queuedResources/${YOUR_QR_ID}
对于处于 ACTIVE 状态的已排队资源,输出如下所示:
{
"name": your-queued-res,
"tpu": {
"nodeSpec": [
{
... // node 1
},
{
... // node 2
},
...
]
},
...
"state": "ACTIVE"
}
控制台
预配 TPU 后,您还可以前往 TPU 页面,找到您的 TPU,然后点击相应的已排队资源请求的名称,以查看有关已排队的资源请求的详细信息。
在极少数情况下,您可能会发现已排队的资源处于 FAILED 状态,而某些切片处于 ACTIVE 状态。如果出现这种情况,请删除已创建的资源,然后过几分钟再重试,或与Google Cloud 支持团队联系。
SSH 和安装依赖项
在 TPU 切片上运行 JAX 代码介绍了如何在单个切片中使用 SSH 连接到 TPU 虚拟机。如需通过 SSH 连接到多切片环境中的所有 TPU 虚拟机并安装依赖项,请使用以下 gcloud 命令:
$ gcloud compute tpus queued-resources ssh ${QR_ID} \ --zone=${ZONE} \ --node=all \ --worker=all \ --command="command-to-run" \ --batch-size=4
此 gcloud 命令会使用 SSH 将指定的命令发送到 QR 中的所有工作器和节点。该命令会分批发送,每批 4 个,同时发送。当前批次完成执行时,系统会发送下一批命令。如果其中某个命令失败,则处理会停止,并且不会再发送其他批次。如需了解详情,请参阅已排队的资源 API 参考文档。如果您使用的切片数量超过本地计算机的线程限制(也称为批处理限制),您将遇到死锁。例如,假设本地机器上的批处理限制为 64。如果您尝试在超过 64 个切片(例如 100 个)上运行训练脚本,则 SSH 命令会将切片拆分为批次。该命令会对第一批次 64 个切片运行训练脚本,并等待脚本运行完毕,然后再对剩余批次 36 个切片运行脚本。不过,在其余 36 个切片开始运行脚本之前,第一个批次的 64 个切片无法完成,从而导致死锁。
为避免这种情况,您可以通过将“&”符号 (&) 附加到使用 --command 标志指定的脚本命令,在每个虚拟机上后台运行训练脚本。执行此操作后,在第一批切片上启动训练脚本后,控制权会立即返回到 SSH 命令。然后,SSH 命令可以开始在剩余批次 36 个切片上运行训练脚本。在后台运行命令时,您需要适当地管道传输 stdout 和 stderr 流。如需在同一 QR 中提高并行度,您可以使用 --node 参数选择特定切片。
网络设置
请按照以下步骤操作,确保 TPU 切片可以相互通信。在每个切片上安装 JAX。如需了解详情,请参阅在 TPU 切片上运行 JAX 代码。声明 len(jax.devices()) 等于多切片环境中的芯片数量。为此,请在每个切片上运行以下命令:
$ python3 -c 'import jax; print(jax.devices())'
如果您在 v4-16 的四个切片上运行此代码,每个切片有八个芯片,共四个切片,因此 jax.devices() 应总共返回 32 个芯片(设备)。
列出已排队的资源
gcloud
您可以使用 queued-resources list 命令查看已排队的资源的状态:
$ gcloud compute tpus queued-resources list --zone=${ZONE}
输出类似于以下内容:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central1-a 4 v5litepod-16 ACTIVE ...
控制台
在预配的环境中启动作业
您可以通过 SSH 连接到每个切片中的所有主机,并在所有主机上运行以下命令,以手动运行工作负载。
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --zone=${ZONE} \ --worker=all \ --command="command-to-run"
重置 QR
ResetQueuedResource API 可用于重置 ACTIVE QR 中的所有虚拟机。重置虚拟机会强制清除机器的内存,并将虚拟机重置为初始状态。本地存储的所有数据都将保持不变,重置后会调用启动脚本。如果您想重启所有 TPU,ResetQueuedResource API 会非常有用。例如,当训练卡住时,重置所有虚拟机比调试更容易。
所有虚拟机的重置操作会并行执行,ResetQueuedResource 操作需要一到两分钟才能完成。如需调用该 API,请使用以下命令:
$ gcloud compute tpus queued-resources reset ${QR_ID} --zone=${ZONE}
删除已排队的资源
如需在训练会话结束时释放资源,请删除已排队的资源。删除操作需要两到五分钟才能完成。如果您使用的是 gcloud CLI,则可以在后台运行此命令并使用可选的 --async 标志。
gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --zone=${ZONE} --force [--async]
控制台
自动故障恢复
发生中断时,多切片会免人为干预地修复受影响的切片,并在之后重置所有切片。受影响的切片会被替换为新切片,而其余健康状况良好的切片会被重置。如果没有可用容量来分配替换切片,则训练会停止。
如需在中断后自动恢复训练,您必须指定一个启动脚本来检查并加载上次保存的检查点。每当重新分配切片或重置虚拟机时,系统都会自动运行启动脚本。您可以在发送到创建 QR 请求 API 的 JSON 载荷中指定启动脚本。
借助以下启动脚本(在创建 QR 中使用),您可以自动从故障中恢复,并在 MaxText 训练期间从存储在 Cloud Storage 存储桶中的检查点恢复训练:
{
"tpu": {
"node_spec": [
{
...
"metadata": {
"startup-script": "#! /bin/bash \n pwd \n runuser -l user1 -c 'cd /home/user1/MaxText && python3 -m MaxText.train MaxText/configs/base.yml run_name=run_test_failure_recovery dcn_data_parallelism=4 ici_fsdp_parallelism=8 steps=10000 save_period=10 base_output_directory='gs://user1-us-central2'' EOF"
}
...
}
]
}
}
请先克隆 MaxText 仓库,然后再尝试此操作。
性能分析和调试
在单切片和多切片环境中,性能分析是一样的。如需了解详情,请参阅分析 JAX 程序。
优化培训
以下部分介绍了如何优化多切片训练。
使用多切片进行分片以实现最佳性能
为了在多切片环境中实现最佳性能,需要考虑如何在多个切片上进行分片。通常有三种选择(数据并行处理、完全分片数据并行处理和流水线并行处理)。我们不建议跨模型维度(有时称为张量并行处理)进行分片激活,因为这需要过多的切片间带宽。对于所有这些策略,您都可以在切片中保留过去行之有效的分片策略。
我们建议从纯数据并行处理开始。使用完全分片的数据并行处理有助于释放内存用量。缺点是,切片之间的通信会使用 DCN 网络,这会降低工作负载速度。仅在必要时根据批次大小使用流水线并行处理(如下文所分析)。
何时使用数据并行处理
如果您的工作负载运行良好,但您希望通过跨多个切片扩容来提升其性能,则纯数据并行处理将非常适用。
为了在多个切片中实现强大的扩缩能力,在 DCN 上执行 all-reduce 所需的时间必须少于执行反向传递所需的时间。DCN 用于切片之间的通信,是工作负载吞吐量的限制因素。
每个 v4 TPU 芯片的峰值性能为每秒 275 * 1012 FLOPS。
每个 TPU 主机都有四个芯片,每个主机的最大网络带宽为 50 Gbps。
这意味着算术强度为 4 * 275 * 1012 FLOPS / 50 Gbps = 22000 FLOPS / 位。
您的模型将针对每个步骤中的每个参数使用 32 位到 64 位 DCN 带宽。如果您使用两个切片,则模型将使用 32 位 DCN 带宽。如果您使用多个分片,编译器将执行完全 shuffle all-reduce 操作,并且您将为每个步骤的每个参数使用最多 64 位 DCN 带宽。每个参数所需的 FLOPS 数因模型而异。具体而言,对于基于 Transformer 的语言模型,正向和反向传递所需的 FLOPS 数大约为 6 * B * P,其中:
每个参数的 FLOPS 数为 6 * B,而反向传递期间每个参数的 FLOPS 数为 4 * B。
为了确保在多个切片之间实现强大的扩缩能力,请确保操作强度超过 TPU 硬件的算术强度。如需计算操作强度,请将反向传递期间每个参数的 FLOPS 数除以每个步骤每个参数的网络带宽(以位为单位):Operational Intensity = FLOPSbackwards_pass / DCN bandwidth
因此,对于基于 Transformer 的语言模型,如果您使用的是两个切片:Operational intensity = 4 * B / 32
如果您使用的是两个以上的切片:Operational intensity = 4 * B/64
这表明,对于基于 Transformer 的语言模型,最小批次大小应介于 176k 到 352k 之间。由于 DCN 网络可能会暂时丢弃数据包,因此最好保持较大的误差余量,仅在每个 Pod 的批次大小至少为 350k(两个 Pod)到 700k(多个 Pod)时部署数据并行处理。
对于其他模型架构,您需要估算每个切片的反向传递运行时(使用性能分析器对其进行计时或统计 FLOP 数)。然后,您可以将其与预期的运行时间进行比较,以便在 DCN 上全部缩减,并准确估算数据并行处理是否适合您。
何时使用完全分片数据并行处理 (FSDP)
完全分片数据并行处理 (FSDP) 将数据并行处理(将数据分片到各个节点)与将权重分片到各个节点相结合。对于正向和反向传递中的每个操作,系统都会收集所有权重,以便每个切片都具有所需的权重。梯度在产生时会进行 reduce-scatter,而不是使用 all-reduce 同步梯度。这样,每个切片只会获取其负责的权重对应的梯度。
与数据并行处理类似,FSDP 需要按切片数量线性扩缩全局批次大小。随着切片数量的增加,FSDP 会降低内存压力。这是因为每个切片的权重和优化器状态数量会减少,但这样做会导致网络流量增加,并且由于集合延迟,阻塞的可能性也会增加。
在实践中,如果您要增加每个切片的批次,存储更多激活以最大限度地减少反向传递期间的重实体化,或增加神经网络中的参数数量,则跨切片 FSDP 是最佳选择。
FSDP 中的 all-gather 和 all-reduce 操作与 DP 中的类似,因此您可以按照上一部分中所述的方式确定 FSDP 工作负载是否受 DCN 性能的限制。
何时使用流水线并行处理
当使用其他并行策略实现高性能时,流水线并行处理会变得相关,这些并行策略要求全局批次大小大于首选批次大小上限。借助流水线并行处理,构成流水线的切片可以“共享”一个批次。不过,流水线并行处理有两个重大缺点:
只有在其他并行处理策略需要过大的全局批次大小时,才应使用流水线并行处理。在尝试流水线并行处理之前,不妨先进行实验,以便从经验上了解在实现高性能 FSDP 所需的批次大小下,每个样本的收敛速度是否会变慢。FSDP 往往能实现更高的模型 FLOP 利用率,但如果每个样本的收敛速度随着批次大小的增加而减慢,流水线并行处理可能仍然是更好的选择。大多数工作负载可以容忍足够大的批次大小,以免无法从流水线并行处理中受益,但您的工作负载可能有所不同。
如果需要流水线并行处理,我们建议将其与数据并行处理或 FSDP 结合使用。这样,您就可以最大限度地缩短流水线深度,同时增加每个流水线的批次大小,直到 DCN 延迟时间对吞吐量的影响变小。具体而言,如果您有 N 个切片,请考虑深度为 2 且数据并行度为 N/2 副本的流水线,然后考虑深度为 4 且数据并行度为 N/4 副本的流水线,以相同的方式继续,直到每个流水线的批次足够大,以便 DCN 集合可以隐藏在反向传递中的算术背后。这将最大限度地减少流水线并行性带来的速度下降,同时允许您扩容到超出全局批次大小限制的范围。
多切片最佳实践
以下部分介绍了多切片训练的最佳实践。
数据加载
在训练期间,我们会反复从数据集中加载批量数据,以馈送给模型。为了避免 TPU 缺少工作,请务必使用高效的异步数据加载器,将批次分片到多个主机。MaxText 中当前的数据加载器会让每个主机加载相同数量的示例子集。此解决方案适用于文本,但需要在模型中进行重新分片。此外,MaxText 尚未提供确定性快照功能,该功能可让数据迭代器在抢占之前和之后加载相同的数据。
检查点
Orbax 检查点库提供了用于将 JAX PyTree 检查点到本地存储空间或 Google Cloud 存储空间的原语。我们在 checkpointing.py 中提供了一个参考集成,其中包含对 MaxText 的同步检查点。
受支持的配置
以下部分介绍了多切片支持的切片形状、编排、框架和并行处理。
形状
所有切片必须具有相同的形状(例如,相同的 AcceleratorType)。不支持异构切片形状。
编排
GKE 支持编排。如需了解详情,请参阅 GKE 中的 TPU。
框架
多切片仅支持 JAX 和 PyTorch 工作负载。
最大并行数量
我们建议用户使用数据并行处理测试多切片。如需详细了解如何使用多切片实现流水线并行处理,请与您的Google Cloud 客户代表联系。
支持与反馈
欢迎您提供反馈!如需分享反馈或请求支持,请使用 Cloud TPU 支持或反馈表单与我们联系。