Mempertahankan progres pelatihan menggunakan Autocheckpoint
Sebelumnya, saat TPU VM memerlukan pemeliharaan, prosedur akan segera dimulai, tanpa memberikan waktu bagi pengguna untuk melakukan tindakan yang mempertahankan progres seperti menyimpan titik pemeriksaan. Hal ini ditunjukkan dalam Gambar 1(a).
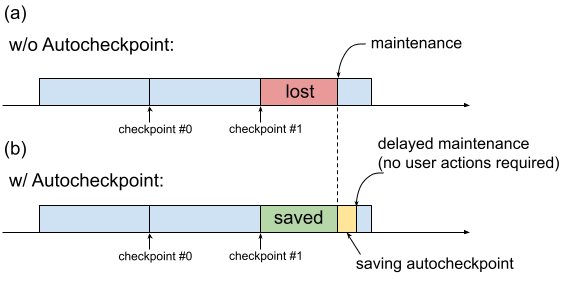
Gambar 1. Ilustrasi fitur Cek Poin Otomatis: (a) Tanpa Cek Poin Otomatis, progres pelatihan dari cek poin terakhir akan hilang saat ada acara pemeliharaan mendatang. (b) Dengan Checkpoint otomatis, progres pelatihan sejak checkpoint terakhir dapat dipertahankan saat ada peristiwa pemeliharaan mendatang.
Anda dapat menggunakan Autocheckpoint (Gambar 1(b)) untuk mempertahankan progres pelatihan dengan mengonfigurasi kode Anda untuk menyimpan titik pemeriksaan yang tidak terjadwal saat peristiwa pemeliharaan terjadi. Saat peristiwa pemeliharaan terjadi, progres sejak checkpoint terakhir akan otomatis disimpan. Fitur ini berfungsi pada slice tunggal dan Multislice.
Fitur Checkpoint Otomatis berfungsi dengan framework yang dapat merekam sinyal SIGTERM dan selanjutnya menyimpan checkpoint. Framework yang didukung meliputi:
Menggunakan Titik pemeriksaan otomatis
Fitur Checkpoint Otomatis dinonaktifkan secara default. Saat membuat
TPU atau meminta resource dalam antrean,
Anda dapat mengaktifkan Checkpoint Otomatis dengan menambahkan tanda --autocheckpoint-enabled saat menyediakan
TPU.
Dengan fitur ini diaktifkan, Cloud TPU
melakukan langkah-langkah berikut setelah menerima notifikasi peristiwa pemeliharaan:
- Menangkap sinyal SIGTERM yang dikirim ke proses menggunakan perangkat TPU
- Tunggu hingga proses keluar, atau 5 menit telah berlalu, mana saja yang lebih dulu
- Melakukan pemeliharaan pada slice yang terpengaruh
Infrastruktur yang digunakan oleh Autocheckpoint tidak bergantung pada framework ML. Framework ML apa pun dapat mendukung Autocheckpoint jika dapat merekam sinyal SIGTERM dan memulai proses pembuatan titik pemeriksaan.
Dalam kode aplikasi, Anda perlu mengaktifkan kemampuan Autocheckpoint yang disediakan oleh framework ML. Misalnya, di Pax, hal ini berarti mengaktifkan tanda command line saat meluncurkan pelatihan. Untuk mengetahui informasi selengkapnya, lihat panduan memulai Autocheckpoint dengan Pax. Di balik layar, framework menyimpan titik pemeriksaan yang tidak terjadwal saat sinyal SIGTERM diterima, dan VM TPU yang terpengaruh akan menjalani pemeliharaan saat TPU tidak lagi digunakan.
Panduan memulai: Checkpoint otomatis dengan MaxText
MaxText adalah LLM open source berperforma tinggi, dapat diskalakan secara arbitrer, dan telah diuji dengan baik yang ditulis dalam Python/JAX murni yang menargetkan Cloud TPU. MaxText berisi semua penyiapan yang diperlukan untuk menggunakan fitur Autocheckpoint.
File MaxText README
file menjelaskan
dua cara untuk menjalankan MaxText dalam skala besar:
- Menggunakan
multihost_runner.py, direkomendasikan untuk eksperimen - Menggunakan
multihost_job.py, direkomendasikan untuk produksi
Saat menggunakan multihost_runner.py, aktifkan Autocheckpoint dengan menetapkan
flag autocheckpoint-enabled saat menyediakan resource dalam antrean.
Saat menggunakan
multihost_job.py, aktifkan Autocheckpoint dengan menentukan
flag command line ENABLE_AUTOCHECKPOINT=true saat meluncurkan tugas.
Panduan memulai: Checkpoint otomatis dengan Pax pada satu slice
Bagian ini memberikan contoh cara menyiapkan dan menggunakan Autocheckpoint dengan Pax pada satu slice. Dengan penyiapan yang sesuai:
- Titik pemeriksaan akan disimpan saat peristiwa pemeliharaan terjadi.
- Cloud TPU akan melakukan pemeliharaan pada VM TPU yang terpengaruh setelah checkpoint disimpan.
- Setelah Cloud TPU menyelesaikan pemeliharaan, Anda dapat menggunakan VM TPU seperti biasa.
Gunakan flag
autocheckpoint-enabledsaat membuat VM TPU atau meminta resource dalam antrean.Contoh:
Menetapkan variabel lingkungan:
export PROJECT_ID=your-project-id export TPU_NAME=your-tpu-name export ZONE=zone-you-want-to-use export ACCELERATOR_TYPE=your-accelerator-type export RUNTIME_VERSION=tpu-ubuntu2204-base
Deskripsi variabel lingkungan
Variabel Deskripsi PROJECT_IDID project Google Cloud Anda. Gunakan project yang ada atau buat project baru. TPU_NAMENama TPU. ZONEZona tempat VM TPU akan dibuat. Untuk mengetahui informasi selengkapnya tentang zona yang didukung, lihat Region dan zona TPU. ACCELERATOR_TYPEJenis akselerator menentukan versi dan ukuran Cloud TPU yang ingin Anda buat. Untuk mengetahui informasi selengkapnya tentang jenis akselerator yang didukung untuk setiap versi TPU, lihat Versi TPU. RUNTIME_VERSIONVersi software Cloud TPU. Tetapkan project ID dan zona di konfigurasi aktif Anda:
gcloud config set project $PROJECT_ID gcloud config set compute/zone $ZONE
Buat TPU:
gcloud alpha compute tpus tpu-vm create $TPU_NAME \ --accelerator-type $ACCELERATOR_TYPE \ --version $RUNTIME_VERSION \ --autocheckpoint-enabled
Hubungkan ke TPU menggunakan SSH:
gcloud compute tpus tpu-vm ssh $TPU_NAMEMenginstal Pax pada satu slice
Fitur Autocheckpoint berfungsi di Pax versi 1.1.0 dan yang lebih baru. Di VM TPU, instal
jax[tpu]danpaxmlterbaru:pip install paxml && pip install jax[tpu] -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
Konfigurasi model
LmCloudSpmd2B. Sebelum menjalankan skrip pelatihan, ubahICI_MESH_SHAPEmenjadi[1, 8, 1]:@experiment_registry.register class LmCloudSpmd2B(LmCloudSpmd): """SPMD model with 2B params. Global batch size = 2 * 2 * 1 * 32 = 128 """ PERCORE_BATCH_SIZE = 8 NUM_LAYERS = 18 MODEL_DIMS = 3072 HIDDEN_DIMS = MODEL_DIMS * 4 CHECKPOINT_POLICY = layers.AutodiffCheckpointType.SAVE_NOTHING ICI_MESH_SHAPE = [1, 8, 1]
Luncurkan pelatihan dengan konfigurasi yang sesuai.
Contoh berikut menunjukkan cara mengonfigurasi model
LmCloudSpmd2Buntuk menyimpan titik pemeriksaan yang dipicu oleh Titik Pemeriksaan Otomatis ke bucket Cloud Storage. Ganti your-storage-bucket dengan nama bucket yang sudah ada, atau buat bucket baru.export JOB_LOG_DIR=gs://your-storage-bucket { python3 .local/lib/python3.10/site-packages/paxml/main.py \ --jax_fully_async_checkpoint=1 \ --exit_after_ondemand_checkpoint=1 \ --exp=tasks.lm.params.lm_cloud.LmCloudSpmd2B \ --job_log_dir=$JOB_LOG_DIR; } 2>&1 | tee pax_logs.txt
Perhatikan dua tanda yang diteruskan ke perintah:
jax_fully_async_checkpoint: Jika flag ini aktif,orbax.checkpoint.AsyncCheckpointerakan digunakan. ClassAsyncCheckpointerotomatis menyimpan titik pemeriksaan saat skrip pelatihan menerima sinyal SIGTERM.exit_after_ondemand_checkpoint: Jika tanda ini aktif, proses TPU akan keluar setelah Autocheckpoint berhasil disimpan, yang akan memicu pemeliharaan untuk segera dilakukan. Jika Anda tidak menggunakan tanda ini, pelatihan akan berlanjut setelah titik pemeriksaan disimpan dan Cloud TPU akan menunggu hingga terjadi waktu tunggu (5 menit) sebelum melakukan pemeliharaan yang diperlukan.
Titik pemeriksaan otomatis dengan Orbax
Fitur Cek Poin Otomatis tidak terbatas pada MaxText atau Pax. Framework apa pun yang dapat merekam sinyal SIGTERM dan memulai proses pembuatan titik pemeriksaan berfungsi dengan infrastruktur yang disediakan oleh Autocheckpoint. Orbax, namespace yang menyediakan library utilitas umum untuk pengguna JAX, menyediakan kemampuan ini.
Seperti yang dijelaskan dalam dokumentasi Orbax, kemampuan ini diaktifkan secara default untuk pengguna orbax.checkpoint.CheckpointManager. Metode save
yang dipanggil setelah setiap langkah secara otomatis memeriksa apakah acara pemeliharaan
akan segera terjadi, dan jika ya, menyimpan titik pemeriksaan meskipun nomor langkah
bukan kelipatan save_interval_steps.
Dokumentasi GitHub juga mengilustrasikan cara membuat pelatihan keluar setelah menyimpan Autocheckpoint, dengan modifikasi dalam kode pengguna.