En esta página, se brinda una descripción general de la configuración de alta disponibilidad (HA) para las instancias de Cloud SQL. A fin de configurar una instancia nueva para HA, o a modo de habilitar HA en una instancia existente, consulta la sección sobre habilitar o inhabilitar la alta disponibilidad en una instancia.
Descripción general de la configuración de HA
El propósito de una configuración de HA es reducir el tiempo de inactividad cuando una zona o una instancia deja de estar disponible. Esto puede suceder durante una interrupción zonal o cuando hay un problema de hardware. Con la HA, tus datos siguen estando disponibles para aplicaciones cliente.
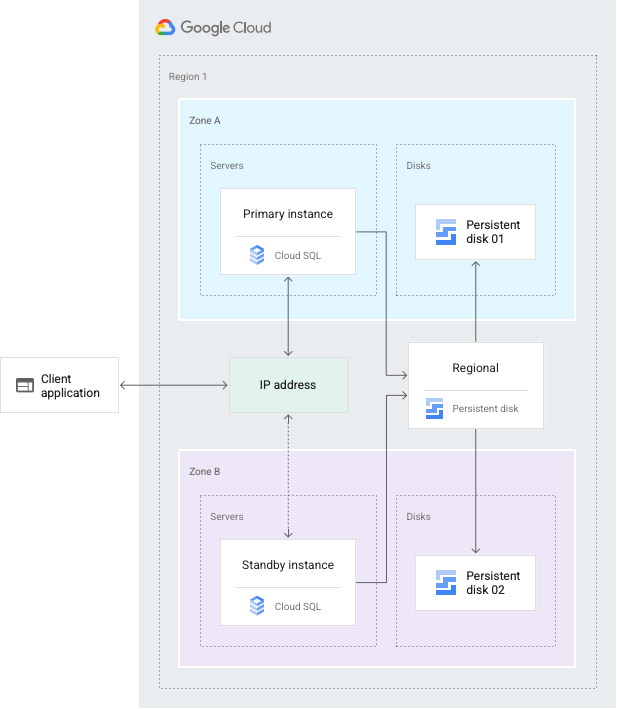
La configuración de HA proporciona redundancia de datos. Una instancia de Cloud SQL configurada para HA también se llama instancia regional y tiene una zona primaria y secundaria dentro de la región configurada*. Dentro de una instancia regional, la configuración se compone de una instancia primaria y una instancia en espera. A través de la replicación síncrona a los discos persistentes de cada zona, todas las operaciones de escritura realizadas en la instancia principal se replican en los discos de ambas zonas antes de que una transacción se informe como confirmada. En caso de una falla en una instancia o una zona, la instancia en espera se convierte en la instancia principal nueva. Luego, los usuarios se redirigen a la nueva instancia principal. Este proceso se denomina conmutación por error.
Después de una conmutación por error, la instancia que recibió la conmutación por error sigue siendo la instancia principal, incluso después de que la instancia original vuelva a estar en línea. Una vez que la zona o instancia que experimentó una interrupción vuelva a estar disponible, la instancia principal original se destruye y se vuelve a crear. Luego, se convierte en la nueva instancia en espera. Si ocurre una conmutación por error en el futuro, la nueva instancia principal se conmutará por error a la instancia original en la zona original.
Si necesitas tener la instancia principal en la zona que tuvo la interrupción, puedes realizar una conmutación por recuperación. Una conmutación por recuperación realiza los mismos pasos que la conmutación por error, solo en la dirección opuesta, para redirigir el tráfico de vuelta a la instancia original. Para realizar una conmutación por recuperación, usa el procedimiento de Inicia la conmutación por error.
La asistencia de disco persistente regional para la configuración de HA de Cloud SQL que tiene al menos una CPU dedicada tiene una cobertura completa del Acuerdo de Nivel de Servicio (ANS). Una instancia configurada con HA cuesta el doble que una instancia independiente. Este precio incluye CPU, RAM y almacenamiento. Para obtener más información, consulta la página de precios.
* Para obtener más información sobre las consideraciones específicas de la región, consulta Geografía y regiones.
Réplicas de lectura
Si la disponibilidad es un elemento de consideración para tus réplicas de lectura, puedes habilitar la HA en las réplicas. Cuando asciendes esa réplica para que se convierta en una instancia principal, ya está configurada como una instancia con alta disponibilidad.
Durante una interrupción zonal, el tráfico se detiene para leer réplicas en esa zona. Después de que la zona vuelva a estar disponible, todas las réplicas de lectura en la zona reanudan la replicación desde la instancia principal. Si las réplicas de lectura no se encuentran en una zona que experimenta una interrupción, se conectan a la instancia en espera cuando se convierte en la instancia principal.
Como práctica recomendada, considera colocar algunas de tus réplicas de lectura en una zona diferente a la de las instancias principal y en espera. Por ejemplo, si tienes una instancia principal en la zona A y una instancia en espera en la zona B, coloca una réplica de lectura en la zona C para mejorar tu confiabilidad. Esta práctica garantiza que las réplicas de lectura sigan funcionando incluso si la zona de la instancia principal falla. También debes agregar la lógica empresarial en la aplicación cliente para enviar lecturas a la instancia principal cuando las réplicas de lectura no están disponibles.
Nota: La instancia en espera no se puede usar para solicitudes de lectura. Esto difiere de la configuración de HA heredada de Cloud SQL para MySQL.
Descripción general de la conmutación por error
Si una instancia configurada con HA deja de responder, de modo automático, Cloud SQL cambia y entrega los datos desde la instancia independiente. Para ver si ocurrió una conmutación por error, revisa tu historial de conmutación por error del registro de operaciones.
Obtén más información para compilar consultas en el Explorador de registros. Si necesitas información más detallada sobre una operación, como el usuario que realizó la operación, debes habilitar el registro de auditoría.
Haz clic en las pestañas para ver cómo afecta la conmutación por error a tu instancia.
Normal

Conmutación por error

Posconmutación por error

Conmutación por recuperación
Proceso
El proceso siguiente ocurre de esta manera:
Falla la instancia principal o la zona.
Cada segundo, el sistema de señal de monitoreo de funcionamiento detecta si la instancia principal está en buen estado. Si no se detectan varias señales de monitoreo por funcionamiento, se inicia la conmutación por error.
Ahora, la instancia independiente entrega los datos hasta la reconexión.
A través de una dirección IP estática compartida con la instancia principal, la instancia independiente, ahora, entrega los datos desde la zona secundaria.
Requisitos
Para que Cloud SQL permita una conmutación por error, la configuración debe cumplir con estos requisitos:
- La instancia principal debe estar en un estado operativo normal (no detenido, en mantenimiento ni en medio de una operación de instancia de Cloud SQL de larga duración, como una operación de copia de seguridad).
- La zona secundaria y la instancia en espera deben estar en buen estado. Cuando la instancia en espera no responde, se bloquean las operaciones de conmutación por error. Después de que Cloud SQL repara la instancia en espera y la zona secundaria está disponible, Cloud SQL permite la conmutación por error.
Copia de seguridad y restablecimiento
Las copias de seguridad automáticas y la recuperación de un momento determinado deben estar habilitadas para las instancias de alta disponibilidad, sin incluir las réplicas de lectura.
Opciones de recuperación para instancias independientes
Cloud SQL no recupera automáticamente las instancias independientes de una interrupción zonal. Para restablecer una instancia que no está configurada para alta disponibilidad en una zona en buen estado, debes restablecer manualmente las instancias zonales. Puedes recuperar manualmente una instancia independiente de una interrupción zonal con una de las siguientes opciones:
Realiza una recuperación de un momento determinado en la instancia a una instancia nueva que crees. Para usar esta opción, debes haber habilitado la PITR en la instancia zonal antes de la interrupción zonal. Los registros de transacciones de la instancia deben almacenarse en Cloud Storage. Si los registros de transacciones se almacenan en el disco, puedes cambiarlos a Cloud Storage. Para usar esta opción, sigue los pasos que se indican en Realiza PITR en una instancia no disponible.
Si la instancia tiene una réplica de lectura en una zona diferente, puedes promover esa réplica de lectura para reemplazar la instancia independiente que está experimentando la interrupción zonal. Para usar esta opción, sigue los pasos que se indican en Cómo promover una réplica.
Para ambas opciones, se aplican las siguientes consideraciones:
Es posible que algunas transacciones recientes confirmadas en la instancia principal no aparezcan en la instancia recién recuperada. El intervalo de tiempo en el que se pueden haber perdido transacciones es el objetivo de punto de recuperación (RPO).
- En el caso de la recuperación con PITR, el RPO suele ser de cinco minutos o menos.
- En el caso de la promoción de réplicas de lectura, el RPO varía según la carga de trabajo de la base de datos. Para obtener más información sobre cómo supervisar y reducir el retraso de replicación, consulta Retraso de replicación.
Después de realizar cualquiera de las opciones de restablecimiento, debes volver a configurar los clientes de las instancias que experimentan la interrupción zonal, ya que las instancias recuperadas tendrán diferentes direcciones IP y nombres de conexión.
Instancias y aplicaciones
No existe ninguna diferencia en trabajar con instancias con o sin HA, por lo que tu aplicación no necesita estar configurada de ningún modo en particular. Cuando ocurre una conmutación por error, las conexiones existentes a la instancia principal y a las réplicas de lectura se encuentran cerradas y tardarán unos 60 segundos para que se restablezcan las conexiones a la instancia principal. Tu aplicación se reconecta con la misma string de conexión o dirección IP, por lo tanto, no necesitas actualizar tu aplicación después de una conmutación por error.
Para ver con exactitud cómo la conmutación por error afecta tus aplicaciones, inicia la conmutación por error de forma manual.
Tiempo de inactividad por mantenimiento
Los eventos de mantenimiento afectan a las instancias principales configuradas con HA de la misma manera que otras instancias. Es posible que las instancias principales estén inactivas durante un período breve. Para obtener más información sobre cómo el mantenimiento afecta las instancias de HA, consulta Cómo funciona el mantenimiento. A fin de minimizar el impacto en el servicio, cambia la configuración de mantenimiento para controlar cuándo se produce el tiempo de inactividad.
Rendimiento
El rendimiento del disco persistente regional depende de muchos factores. Es posible que se reduzcan las operaciones de entrada y salida por segundo (IOPS) con el disco persistente regional en comparación con el disco persistente zonal. En particular, observa el tamaño del tipo de instancia de VM, y la entrada y salida de tu carga de trabajo. Otra métrica que debes tener en cuenta es que la latencia del disco persistente regional que tiene unidades de estado sólido (SSD) es superior a la de un disco persistente que tiene una SSD. Esto implica que, si tu carga de trabajo no es una de transmisión y es sensible a la latencia, no puede alcanzar el límite de IOPS, ya que un disco persistente regional con SSD tiene una latencia mayor que un disco persistente zonal con SSD. Esto se debe a la replicación síncrona de los datos en varias zonas involucradas en un disco persistente regional para proporcionar varias copias de datos en las zonas de una región.
Opción heredada de alta disponibilidad de MySQL
En el proceso heredado para agregar alta disponibilidad a las instancias de MySQL, se usa una réplica de conmutación por error. La funcionalidad heredada no está disponible en la Google Cloud consola. Consulta Configuración heredada: Crea una nueva instancia configurada para alta disponibilidad o Configuración heredada: Configura una instancia existente para alta disponibilidad.
¿Qué sigue?
- Habilita e inhabilita la alta disponibilidad en una instancia.
- Inicia la conmutación por error.
- Aprende a administrar las conexiones de tu base de datos.
- Aprende sobre regiones y zonas en Cloud SQL.