本文档介绍了 Google Cloud 支持团队和产品工程团队如何协同解决突发事件并为您提供最新动态。
下图显示了产品工程团队和支持团队的职责。

以下部分介绍了这些职责。
检测
Google Cloud 使用内部监控和合成监控来检测突发事件。 如需了解详情,请参阅《站点可靠性工程》一书的第 6 章。
初步回应
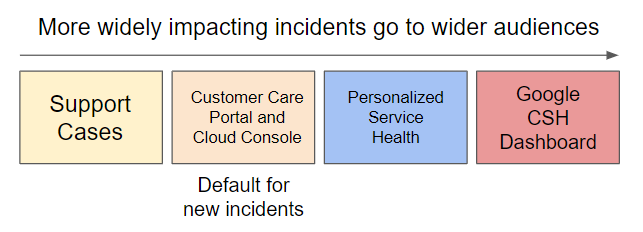
检测到突发事件时, Google Cloud Service Health 团队会管理与客户的沟通。突发事件的初始通知通常很短,一般只提及有问题的产品。这是因为我们优先考虑快速通知,而不是细节。具体细节可以在后续更新中提供。
为了向您提供尽可能多的信息,并且不让您忙于应付对您没有影响的问题,应根据问题的范围和严重程度使用不同的沟通渠道:
调查
产品工程团队负责调查突发事件的根本原因。突发事件管理通常由网站可靠性工程师完成,但可能由软件工程师或其他人来完成,这取决于具体情况和产品。如需了解详情,请参阅《网站可靠性工程》一书的第 12 章。
缓解和修正
仅当 Google 确信所做更改将永远结束影响时,才会认为问题“已解决”。例如,这种解决操作可能会回滚触发过突发事件的更改。
当突发事件正在进行时,Service Health 和产品团队会尝试“缓解”此问题。缓解是指可以减少问题的影响或范围,例如通过临时为过载的产品提供其他资源。
如果没有找到缓解措施,则 Service Health 团队会尽可能找到解决方法并解决。解决方法是您在解决突发事件发生后的潜在需求时可以采取的步骤。解决方法可能对 API 调用使用不同的设置,以避开出现问题的代码路径。
后续跟进
当突发事件正在发生时,Service Health 团队会定期更新相关情况,更新通常会提供:
有关突发事件的更多信息,例如错误消息、受影响的地区或区域,受影响的功能或影响百分比。
缓解问题的进展,包括任何解决方法。
根据突发事件量身定制的沟通时间表。
状态变化,例如突发事件已解决。
回顾
Google 会针对所有突发事件在内部执行事后分析,以便全面了解突发事件,并确定 Google 可作出的可靠性改进。然后跟踪和实施这些改进。如需了解详情,请参阅《站点可靠性工程》一书的第 15 章。
突发事件报告
如果突发事件具有非常广泛且严重的影响,Google 会提供突发事件报告,其中概述了事件的症状、影响、根本原因、补救措施以及未来的预防。对于回顾,我们特别注意我们所采取的了解问题和提高可靠性的步骤。Google 在撰写和发布回顾时秉承透明的原则,这体现了我们致力于为客户构建稳定产品的承诺。