Este documento explica como a equipe de suporte do Google Cloud e a equipe de engenharia de produtos trabalham juntas para resolver um incidente e fornecer atualizações.
O diagrama a seguir mostra as responsabilidades das equipes de engenharia de produtos e suporte.

As seções a seguir explicam essas responsabilidades.
Detecção
Google Cloud usa monitoramento interno e sintético para detectar incidentes. Para mais informações, consulte o capítulo 6 do manual de engenharia de confiabilidade do site.
Resposta inicial
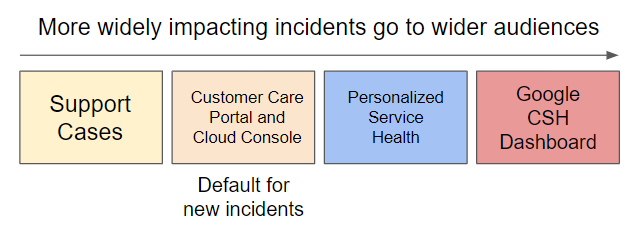
Quando um incidente é detectado, a equipe do Google Cloud Service Health gerencia as comunicações com os clientes. A notificação inicial de um incidente geralmente é esparsa e quase sempre é mencionado apenas o nome do produto em questão. Isso ocorre porque priorizamos notificações rápidas em vez de detalhes. Os detalhes serão fornecidos nas atualizações subsequentes.
Para fornecer o máximo de informações possível, sem sobrecarregar você com problemas que não atingem você, são usados diferentes canais de comunicação, dependendo do escopo e da gravidade de um problema:
Investigar
As equipes de engenharia de produto são responsáveis por investigar a causa raiz dos incidentes. O gerenciamento de incidentes geralmente é feito pelos engenheiros de confiabilidade do site, mas também é realizado por engenheiros de software ou outros profissionais, dependendo da situação e do produto. Para mais informações, consulte o Capítulo 12 do manual Engenharia de confiabilidade do site.
Mitigação e correção
Um problema é considerado corrigido somente quando o Google tiver certeza de que as alterações feitas terminarão com o impacto de uma vez por todas. Por exemplo, a correção reverte uma alteração que acionou um incidente.
Enquanto um incidente está em andamento, o Service Health e a equipe do produto tentam mitigar o problema. A mitigação ocorre quando for possível reduzir o impacto ou o escopo de um problema, por exemplo, ao fornecer temporariamente mais recursos a um produto sobrecarregado.
Se nenhuma mitigação for possível, a equipe Service Health encontrará e informará soluções alternativas. Soluções alternativas são as etapas que você executa para solucionar o problema subjacente, apesar do incidente. Uma exemplo de solução alternativa é o uso de configurações diferentes para uma chamada de API a fim de evitar um caminho de código problemático.
Acompanhar
Enquanto um incidente está em andamento, a equipe do Service Health fornece atualizações regulares. Normalmente, as atualizações fornecem o seguinte:
Mais informações sobre o incidente, como mensagens de erro, zonas ou regiões afetadas, quais recursos foram afetados ou o percentual de impacto.
O progresso da atenuação, incluindo quaisquer soluções alternativas.
Cronogramas de comunicação adaptados ao incidente.
Alterações no status, por exemplo, quando um incidente é corrigido.
Retrospectiva
Todos os incidentes passam por uma análise retrospectiva interna para entender completamente o incidente e identificar melhorias de confiabilidade que o Google pode fazer. Essas melhorias são acompanhadas e implementadas. Para mais informações, consulte o capítulo 15 do manual Engenharia de confiabilidade do site.
Relatórios de incidentes
Quando os incidentes têm um impacto muito amplo e grave, o Google fornece relatórios de incidentes que descrevem os sintomas, o impacto, a causa raiz, a correção e a prevenção futura de incidentes. Assim como nas retrospectivas, prestamos atenção especial às etapas adotadas para aprender com o problema e melhorar a confiabilidade. O objetivo do Google ao escrever e divulgar retrospectivas é ser transparente e demonstrar nosso compromisso em criar produtos estáveis para nossos clientes.