このドキュメントでは、 Google Cloud サポートチームとプロダクト エンジニアリング チームが協力してインシデントを解決し、お客様に最新情報をお知らせする方法について説明します。
次の図は、プロダクト エンジニアリング チームとサポートチームの責任を示しています。

以降のセクションでは、これらの責任について説明します。
検出
Google Cloud は、内部モニタリングと合成モニタリングを使用してインシデントを検出します。詳しくは、Google の書籍『Site Reliability Engineering』の第 6 章をご覧ください。
初期対応
インシデントが検出されると、 Google Cloud Service Health チームがお客様とのコミュニケーションを管理します。通常、インシデントの最初の通知には多くの情報は含まれません。該当するプロダクトのみが記載されていることもよくあります。これは、詳細よりも迅速な通知を優先しているためです。詳細は、以降のアップデートで提供できます。
お客様に影響のない問題で煩わせることなく、かつできるだけ多くの情報を提供するために、問題の範囲と重大度に応じて通信チャネルを使い分けています。
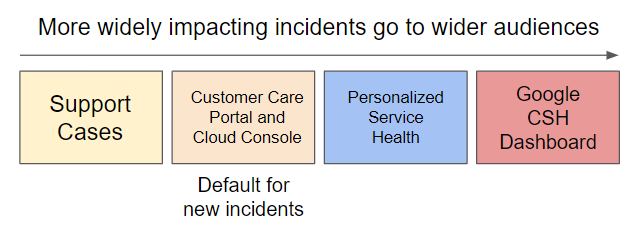
調査
インシデントの根本原因の調査は、プロダクト エンジニアリング チームが担当します。通常、インシデントの管理はサイト信頼性エンジニアが行いますが、状況とプロダクトによってはソフトウェア エンジニアや他の担当者が行うこともあります。詳しくは、Google の書籍『Site Reliability Engineering』の第 12 章をご覧ください。
緩和策と修正
問題が解決したとみなされるのは、Google が確信を持って行った変更により、問題の影響が完全になくなった場合のみです。たとえば、インシデントの原因となった変更をロールバックして解決する場合もあります。
インシデントが継続している間は、Service Health とプロダクト チームが問題の軽減を試みます。問題の軽減により、その影響や範囲を小さくできる可能性があります。たとえば、負荷によってパフォーマンスが低下しているプロダクトに一時的にリソースを追加するなどして問題を軽減します。
問題の軽減が見られない場合、可能であれば、サービス ヘルス チームが回避策を見つけて連絡します。回避策とは、インシデントがあっても基本的なニーズを満たすために講じることができる対策を指します。たとえば、問題のあるコードパスを避けるために API 呼び出しに異なる設定を使用するといった回避策があります。
フォローアップ
インシデントが継続している間は、Service Health チームが定期的に更新情報を提供します。通常は、次の情報が提供されます。
インシデントに関する詳細。エラー メッセージ、影響を受けるゾーン / リージョン、影響を受ける機能、影響の割合などです。
問題軽減に向けた進捗状況。これには回避策も含まれます。
連絡のタイムライン。インシデントに合わせて調整されます。
ステータスの変更。インシデントが解決された場合などにステータスが変更されます。
事後検証
インシデントを完全に把握し、信頼性の改善へ向けて Google がすべきことを明らかにするため、すべてのインシデントが社内で事後分析されます。事後分析によって特定された改善策が追跡および実装されます。詳しくは、Google の書籍『Site Reliability Engineering』の第 15 章をご覧ください。
インシデント報告
広範囲にわたり深刻な影響を与えるインシデントの場合、Google は、その症状、影響、根本原因、是正措置、今後のインシデント防止策をまとめたインシデント報告書をリリースします。事後検証と同様、問題から学び、信頼性を改善するために講じる措置に特に注意を払っています。Google が事後検証報告書を作成して公開する目的は、透明性を確保し、お客様に安定したプロダクトを提供するという Google の取り組みを示すことにあります。