Ce document explique comment l'équipe d'assistance Google Cloud et l'équipe d'ingénierie produit travaillent ensemble pour résoudre un incident et vous fournir des informations à ce sujet.
Le schéma suivant montre les responsabilités des équipes d'ingénierie et d'assistance produit.

Les sections suivantes expliquent ces responsabilités.
Détection
Google Cloud utilise une surveillance interne et synthétique pour détecter les incidents. Pour en savoir plus, consultez le chapitre 6 du manuel d'ingénierie en fiabilité des sites (SRE) sites.
Réponse initiale
Lorsqu'un incident est détecté, l'équipe Google Cloud Service Health gère les communications avec les clients. La notification initiale d'un incident est souvent sommaire, ne mentionnant généralement que le produit concerné. En effet, nous privilégions une notification rapide à l'apport de détails. Ces derniers peuvent être fournis dans les mises à jour ultérieures.
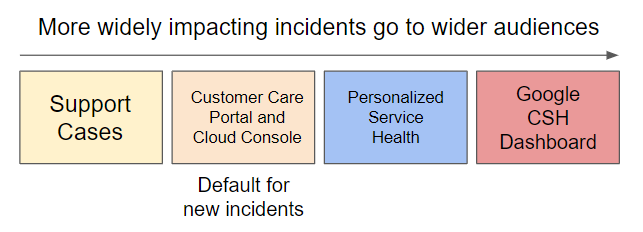
Différents canaux de communication sont utilisés en fonction de l'étendue et de la gravité d'un problème afin de vous fournir autant d'informations que possible, sans vous submerger de données qui ne vous concernent pas :
Examiner
Les ingénieurs produit sont chargés d'enquêter sur l'origine des incidents. La gestion des incidents est souvent assurée par des ingénieurs en fiabilité des sites, mais elle peut être confiée à des ingénieurs logiciels ou à d'autres spécialistes, en fonction de la situation et du produit. Pour en savoir plus, consultez le chapitre 12 du manuel d'ingénierie en fiabilité des sites.
Atténuation et correction
Un problème n'est considéré comme résolu que lorsque des modifications ont été apportées et que Google a la certitude qu'elles vont le régler définitivement. Par exemple, un rollback peut être effectué pour annuler une modification ayant déclenché un incident.
Tant qu'un incident est en cours, Service Health et l'équipe produit tentent d'atténuer le problème. Cela permet de réduire l'impact ou l'étendue d'un problème, par exemple en fournissant temporairement des ressources supplémentaires à un produit présentant une surcharge.
Si aucune mesure d'atténuation n'a été trouvée et si cela est possible, l'équipe Service Health découvre des solutions de contournement et les communique. Les solutions de contournement sont des étapes que vous pouvez suivre pour répondre au besoin sous-jacent en dépit de l'incident. Une solution de contournement peut par exemple consister à utiliser des paramètres différents pour un appel d'API afin d'éviter un chemin de code problématique.
suivi
Lorsqu'un incident est en cours, l'équipe Service Health fournit des informations régulières. lesquelles fournissent généralement les éléments suivants :
Davantage d'informations sur l'incident, par exemple les messages d'erreur, les zones ou régions concernées, les fonctionnalités affectées ou les pourcentages d'impact
L'avancement du processus d'atténuation, y compris les solutions de contournement
Le calendrier des communications, adapté à l'incident
Les changements d'état, par exemple lorsqu'un incident est résolu
Rétrospective
Tous les incidents font l'objet d'une analyse interne pour bien les comprendre et identifier les améliorations de fiabilité que Google peut apporter. Ces améliorations sont ensuite suivies et mises en place. Pour en savoir plus, consultez le chapitre 15 du manuel d'ingénierie en fiabilité des sites.
Rapport d'incident
Lorsque les incidents ont des conséquences très graves et très étendues, Google fournit des rapports d'incident décrivant les symptômes, l'impact, l'origine, les mesures correctives et la prévention future de ces derniers. Comme pour les rétrospectives, nous accordons une attention particulière aux mesures que nous prenons pour tirer les leçons du problème et améliorer la fiabilité. Chez Google, en rédigeant et en publiant des rétrospectives, nous faisons preuve de transparence et montrons que nous tenons à créer des produits stables pour nos clients.