Cette page décrit le service de découverte des données sensibles. Ce service vous aide à déterminer l'emplacement des données sensibles et à haut risque dans votre organisation.
Présentation
Le service de découverte vous permet de protéger les données au sein de votre organisation en identifiant l'emplacement des données sensibles et à haut risque. Lorsque vous créez une configuration d'analyse de découverte, Sensitive Data Protection analyse vos ressources pour identifier les données à profiler. Il génère ensuite des profils de vos données. Tant que la configuration de la découverte est active, Sensitive Data Protection profile automatiquement les données que vous ajoutez et modifiez. Vous pouvez générer des profils de données pour l'ensemble de l'organisation, des dossiers individuels et des projets individuels.
Chaque profil de données est un ensemble d'insights et de métadonnées que le service de découverte collecte en analysant une ressource compatible. Les insights incluent les infoTypes prévus, ainsi que les niveaux de risque et de sensibilité des données calculés pour vos données. Utilisez ces informations afin de prendre des décisions avisées pour la protection, le partage et l'utilisation de vos données.
Les profils de données sont générés avec différents niveaux de détail. Par exemple, lorsque vous profilez des données BigQuery, des profils sont générés au niveau du projet, de la table et de la colonne.
L'image suivante montre une liste de profils de données au niveau des colonnes. Cliquez sur l'image pour l'agrandir.

Pour obtenir la liste des insights et des métadonnées inclus dans chaque profil de données, consultez la documentation de référence sur les métriques.
Pour en savoir plus sur la hiérarchie des ressources Google Cloud , consultez Hiérarchie des ressources.
Génération de profils de données
Pour commencer à générer des profils de données, vous devez créer une configuration d'analyse de découverte (également appelée configuration de profil de données). Cette configuration d'analyse vous permet de définir le champ d'application de l'opération de découverte et le type de données que vous souhaitez profiler. Dans la configuration de l'analyse, vous pouvez définir des filtres pour spécifier les sous-ensembles de données que vous souhaitez profiler ou ignorer. Vous pouvez également définir le calendrier de profilage.
Lors de la création d'une configuration d'analyse, vous définissez également le modèle d'inspection à utiliser. Le modèle d'inspection vous permet de spécifier les types de données sensibles (également appelés infoTypes) que Sensitive Data Protection doit rechercher.
Lorsque Sensitive Data Protection crée des profils de données, il analyse vos données en se basant sur votre configuration d'analyse et votre modèle d'inspection.
La protection des données sensibles reprofile les données comme décrit dans Fréquence de génération du profil de données. Vous pouvez personnaliser la fréquence de profilage dans la configuration d'analyse en créant une programmation. Pour forcer le service de découverte à reprofiler vos données, consultez Forcer une opération de reprofilage.
Types de découvertes
Cette section décrit les types d'opérations de découverte que vous pouvez effectuer et les ressources de données compatibles.
Détection pour BigQuery et BigLake
Lorsque vous profilez des données BigQuery, des profils de données sont générés au niveau du projet, de la table et de la colonne. Après avoir profilé une table BigQuery, vous pouvez examiner plus en détail les résultats en effectuant une inspection approfondie.
Sensitive Data Protection profile les tables compatibles avec l'API BigQuery Storage Read, y compris les suivantes :
- Tables BigQuery standards
- Instantanés de table
- Tables BigLake stockées dans Cloud Storage
Les éléments suivants ne sont pas acceptés :
- Tables BigQuery Omni.
- Tables dont la taille des données sérialisées des lignes individuelles dépasse la taille maximale des données sérialisées acceptée par l'API BigQuery Storage Read (128 Mo).
- Tables externes autres que BigLake, comme Google Sheets.
Pour savoir comment profiler des données BigQuery, consultez les ressources suivantes :
- Profiler les données BigQuery dans un seul projet
- Profiler les données BigQuery dans une organisation ou un dossier
Pour en savoir plus sur BigQuery, consultez la documentation BigQuery.
Discovery pour Cloud SQL
Lorsque vous profilez des données Cloud SQL, des profils de données sont générés au niveau du projet, de la table et de la colonne. Avant de pouvoir lancer la découverte, vous devez fournir les informations de connexion pour chaque instance Cloud SQL à profiler.
Pour savoir comment profiler les données Cloud SQL, consultez les ressources suivantes :
- Profiler les données Cloud SQL dans un seul projet
- Profiler les données Cloud SQL dans une organisation ou un dossier
Pour en savoir plus sur Cloud SQL, consultez la documentation.
Découverte pour Cloud Storage
Lorsque vous profilez des données Cloud Storage, des profils de données sont générés au niveau du bucket. La protection des données sensibles regroupe les fichiers détectés dans des clusters de fichiers et fournit un récapitulatif pour chaque cluster.
Pour savoir comment profiler les données Cloud Storage, consultez les ressources suivantes :
- Profiler les données Cloud Storage dans un seul projet
- Profiler les données Cloud Storage dans une organisation ou un dossier
Pour en savoir plus sur Cloud Storage, consultez la documentation Cloud Storage.
Discovery pour Vertex AI
Lorsque vous profilez un ensemble de données Vertex AI, Sensitive Data Protection génère un profil de données de fichier ou un profil de données de table, selon l'emplacement de vos données d'entraînement : Cloud Storage ou BigQuery.
Pour en savoir plus, consultez les ressources suivantes :
- Détection des données sensibles pour Vertex AI
- Profiler les données Vertex AI dans un seul projet
- Profiler les données Vertex AI dans une organisation ou un dossier
Pour en savoir plus sur Vertex AI, consultez la documentation sur Vertex AI.
Découverte pour les autres fournisseurs de services cloud
Lorsque vous profilez des données S3, des profils de données sont générés au niveau du bucket. Lorsque vous profilez des données Azure Blob Storage, des profils de données sont générés au niveau du conteneur.
Dans les deux cas, Sensitive Data Protection regroupe les fichiers détectés dans des clusters de fichiers et fournit un récapitulatif pour chaque cluster.
Pour en savoir plus, consultez les ressources suivantes :
Variables d'environnement Cloud Run
Le service de découverte peut détecter la présence de secrets dans les variables d'environnement des fonctions Cloud Run et des révisions de service Cloud Run, et envoyer les résultats à Security Command Center. Aucun profil de données n'est généré.
Pour en savoir plus, consultez Signaler les secrets dans les variables d'environnement à Security Command Center.
Rôles requis pour configurer et afficher des profils de données
Les sections suivantes répertorient les rôles utilisateur requis pour chaque type d'utilisation. Selon la configuration de votre organisation, vous pouvez décider de demander à différentes personnes d'effectuer différentes tâches. Par exemple, la personne qui configure les profils de données peut être différente de la personne qui en assure le suivi régulier.
Rôles requis pour utiliser des profils de données au niveau de l'organisation ou des dossiers
Ces rôles vous permettent de configurer et d'afficher des profils de données au niveau de l'organisation ou du dossier.
Assurez-vous que ces rôles sont attribués aux personnes appropriées au niveau de l'organisation. Votre administrateur Google Cloud peut également créer des rôles personnalisés qui ne disposent que des autorisations pertinentes.
| Objectif | Rôle prédéfini | Autorisations pertinentes |
|---|---|---|
| Créer une configuration d'analyse de découverte et afficher des profils de données | Administrateur DLP (roles/dlp.admin) |
|
| Créez un projet à utiliser comme conteneur d'agent de service1. | Créateur de projet (roles/resourcemanager.projectCreator) |
|
| Accorder l'accès à la découverte2 | Choisissez l'une des options suivantes :
|
|
| Afficher les profils de données (lecture seule) | Lecteur de profils de données DLP (roles/dlp.dataProfilesReader) |
|
Lecteur DLP (roles/dlp.reader) |
|
1 Si vous ne disposez pas du rôle Créateur de projet (roles/resourcemanager.projectCreator), vous pouvez quand même créer une configuration d'analyse, mais le conteneur d'agent de service que vous utilisez doit être un projet existant.
2 Si vous ne disposez pas du rôle Administrateur de l'organisation (roles/resourcemanager.organizationAdmin) ni du rôle Administrateur de sécurité (roles/iam.securityAdmin), vous pouvez quand même créer une configuration d'analyse. Une fois que vous avez créé la configuration d'analyse, un membre de votre organisation disposant de l'un de ces rôles doit accorder l'accès à la découverte à l'agent de service.
Rôles requis pour utiliser des profils de données au niveau du projet
Ces rôles vous permettent de configurer et d'afficher des profils de données au niveau du projet.
Assurez-vous que ces rôles sont attribués aux personnes appropriées au niveau du projet. Votre administrateur Google Cloud peut également créer des rôles personnalisés qui ne disposent que des autorisations pertinentes.
| Objectif | Rôle prédéfini | Autorisations pertinentes |
|---|---|---|
| Configurer et afficher des profils de données | Administrateur DLP (roles/dlp.admin) |
|
| Afficher les profils de données (lecture seule) | Lecteur de profils de données DLP (roles/dlp.dataProfilesReader) |
|
Lecteur DLP (roles/dlp.reader) |
|
Configuration de l'analyse de découverte
Une configuration d'analyse de découverte (parfois appelée configuration de découverte ou configuration d'analyse) spécifie la manière dont Sensitive Data Protection doit profiler vos données. Il inclut les paramètres suivants :
- Champ d'application (organisation, dossier ou projet) de l'opération de découverte
- Type de ressource à profiler
- Modèles d'inspection à utiliser
- Fréquence d'analyse
- Sous-ensembles de données spécifiques à inclure ou à exclure de la découverte
- Les actions que vous souhaitez que Sensitive Data Protection effectue après la découverte (par exemple, les services Google Cloud auxquels publier les profils)
- Agent de service à utiliser pour les opérations de découverte
Pour savoir comment créer une configuration d'analyse de découverte, consultez les pages suivantes :
Découverte des données BigQuery
Découverte des données Cloud SQL
Découverte des données Cloud Storage
Découverte des données Vertex AI
Signaler les secrets dans les variables d'environnement Cloud Run à Security Command Center (aucun profil généré)
Étendues de la configuration d'analyse
Vous pouvez créer une configuration d'analyse aux niveaux suivants :
- Organisation
- Dossier
- Projet
- Ressource de données unique
Au niveau de l'organisation et du dossier, si deux configurations d'analyse actives ou plus ont le même projet dans leur champ d'application, Sensitive Data Protection détermine quelle configuration d'analyse peut générer des profils pour ce projet. Pour en savoir plus, consultez la section Remplacer les configurations d'analyse sur cette page.
Une configuration d'analyse au niveau du projet peut toujours profiler le projet cible et n'entre pas en concurrence avec les autres configurations au niveau du dossier ou de l'organisation parent.
Une configuration d'analyse à ressource unique est conçue pour vous aider à explorer et à tester le profilage sur une seule ressource de données.
Emplacement de la configuration d'analyse
La première fois que vous créez une configuration d'analyse, vous spécifiez l'emplacement où vous souhaitez que Sensitive Data Protection la stocke. Toutes les configurations d'analyse ultérieures que vous créez sont stockées dans cette même région.
Par exemple, si vous créez une configuration d'analyse pour le dossier A et que vous la stockez dans la région us-west1, toute configuration d'analyse que vous créez ultérieurement pour une autre ressource est également stockée dans cette région.
Les métadonnées sur les données à profiler sont copiées dans la même région que vos configurations d'analyse, mais les données elles-mêmes ne sont ni déplacées ni copiées. Pour en savoir plus, consultez Considérations relatives à la résidence des données.
Modèle d'inspection
Un modèle d'inspection spécifie les types d'informations (ou infoTypes) que Sensitive Data Protection recherche lors de l'analyse de vos données. Ici, vous combinez des infoTypes intégrés et des infoTypes personnalisés facultatifs.
Vous pouvez également fournir un niveau de probabilité pour affiner ce que la protection des données sensibles considère comme une correspondance. Vous pouvez ajouter des ensembles de règles pour exclure les résultats indésirables ou inclure des résultats supplémentaires.
Par défaut, si vous modifiez un modèle d'inspection utilisé par votre configuration d'analyse, les modifications ne sont appliquées qu'aux analyses futures. Votre action n'entraîne pas une opération de re-profilage de vos données.
Si vous souhaitez que les modifications apportées au modèle d'inspection déclenchent des opérations de reprofilage sur les données concernées, ajoutez ou mettez à jour une planification dans la configuration de votre analyse, puis activez l'option permettant de reprofiler les données lorsque le modèle d'inspection est modifié. Pour en savoir plus, consultez Fréquence de génération des profils de données.
Vous devez disposer d'un modèle d'inspection dans chaque région où vous avez des données à profiler. Si vous souhaitez utiliser un seul modèle pour plusieurs régions, vous pouvez utiliser un modèle stocké dans la région global. Si des règles d'administration vous empêchent de créer un modèle d'inspection dans la région global, vous devez définir un modèle d'inspection dédié pour chaque région. Pour en savoir plus, consultez Considérations relatives à la résidence des données.
Les modèles d'inspection constituent un composant essentiel de la plate-forme Sensitive Data Protection. Les profils de données utilisent les mêmes modèles d'inspection que ceux utilisables dans tous les services Sensitive Data Protection. Pour en savoir plus sur les modèles d'inspection, consultez la page Modèles.
Conteneur d'agent de service et agent de service
Lorsque vous créez une configuration d'analyse pour votre organisation ou pour un dossier, la protection des données sensibles nécessite de fournir un conteneur d'agent de service. Un conteneur d'agent de service est un projet Google Cloud que Sensitive Data Protection utilise pour suivre les frais facturés liés aux opérations de profilage au niveau de l'organisation et des dossiers.
Le conteneur d'agent de service contient un agent de service, que la protection des données sensibles utilise pour profiler les données en votre nom. Vous avez besoin d'un agent de service pour vous authentifier auprès de Sensitive Data Protection et d'autres API. Votre agent de service doit disposer de toutes les autorisations requises pour accéder à vos données et les profiler. L'ID de l'agent de service est au format suivant :
service-PROJECT_NUMBER@dlp-api.iam.gserviceaccount.com
Ici, PROJECT_NUMBER est l'identifiant numérique du conteneur de l'agent de service.
Lorsque vous définissez le conteneur de l'agent de service, vous pouvez choisir un projet existant. Si le projet que vous sélectionnez contient un agent de service, Sensitive Data Protection lui accorde les autorisations IAM requises. Si le projet ne possède pas d'agent de service, Sensitive Data Protection en crée un et lui accorde automatiquement des autorisations de profilage des données.
Vous pouvez également demander à la protection des données sensibles de créer automatiquement le conteneur et l'agent de service. La protection des données sensibles accorde automatiquement des autorisations de profilage des données à l'agent de service.
Dans les deux cas, si la protection des données sensibles ne parvient pas à accorder à votre agent de service l'accès au profilage de données, une erreur s'affiche lorsque vous affichez les détails de la configuration d'analyse.
Pour les configurations d'analyse au niveau du projet, vous n'avez pas besoin d'un conteneur d'agent de service. Le projet que vous profilez joue le rôle de conteneur de l'agent de service. Pour exécuter des opérations de profilage, la protection des données sensibles utilise l'agent de service propre à ce projet.
Accès au profilage des données au niveau de l'organisation ou du dossier
Lorsque vous configurez le profilage au niveau de l'organisation ou du dossier, Sensitive Data Protection tente automatiquement d'accorder l'accès au profilage des données à votre agent de service. Toutefois, si vous ne disposez pas des autorisations permettant d'attribuer des rôles IAM, Sensitive Data Protection ne peut pas effectuer cette action en votre nom. Une personne disposant de ces autorisations dans votre organisation, telle qu'un administrateur Google Cloud , doit accorder l'accès au profilage des données à votre agent de service.
Fréquence de génération des profils de données
Une fois que vous avez créé une configuration d'analyse de découverte pour une ressource donnée, Sensitive Data Protection effectue une analyse initiale en profilant les données dans le champ d'application de votre configuration d'analyse.
Une fois l'analyse initiale terminée, Sensitive Data Protection surveille en permanence la ressource profilée. Les données ajoutées à la ressource sont automatiquement profilées peu de temps après leur ajout.
Fréquence de reprofilage par défaut
La fréquence de reprofilage par défaut diffère selon le type de découverte de la configuration de votre analyse :
- Profilage BigQuery : pour chaque table, attendez 30 jours, puis profilez-la à nouveau si le schéma, les lignes de la table ou le modèle d'inspection ont été modifiés.
- Profilage Cloud SQL : pour chaque table, attendez 30 jours, puis reprofilez-la si le schéma ou le modèle d'inspection ont été modifiés.
- Profilage Vertex AI : pour chaque ensemble de données, attendez 30 jours, puis reprofilez l'ensemble de données si le modèle d'inspection a été modifié.
Profilage du stockage de fichiers : pour chaque stockage de fichiers dans Google Cloud ou dans d'autres clouds, attendez 30 jours, puis reprofilez le stockage de fichiers si le modèle d'inspection a été modifié.
La protection des données sensibles utilise le terme magasin de fichiers pour désigner un bucket ou un conteneur de stockage de fichiers.
Personnaliser la fréquence de reprofilage
Dans votre configuration d'analyse, vous pouvez personnaliser la fréquence de re-profilage en créant une ou plusieurs planifications pour différents sous-ensembles de vos données.
Les fréquences de re-profilage suivantes sont disponibles :
- Ne pas reprofiler : ne jamais reprofiler après la génération des profils initiaux.
- Reprofiler tous les jours : attendez 24 heures avant de reprofiler.
- Reprofiler toutes les semaines : attendez sept jours avant de reprofiler.
- Reprofiler tous les mois : attendez 30 jours avant de reprofiler.
Reprofilage planifié
Dans votre configuration d'analyse, vous pouvez spécifier si un sous-ensemble de données doit être reprofilé régulièrement, que les données aient été modifiées ou non. La fréquence que vous définissez spécifie le temps qui doit s'écouler entre les opérations de profilage. Par exemple, si vous définissez la fréquence sur "hebdomadaire", Sensitive Data Protection profile une ressource de données sept jours après son dernier profilage.
Reprofilage lors de la mise à jour
Dans la configuration de l'analyse, vous pouvez spécifier les événements pouvant déclencher des opérations de re-profilage. Les mises à jour des modèles d'inspection en sont un exemple.
Lorsque vous sélectionnez ces événements, le calendrier que vous définissez spécifie le temps maximal pendant lequel la protection des données sensibles attend que des mises à jour s'accumulent avant de reprofiler vos données. Si aucune modification applicable (comme des modifications de schéma ou de modèle d'inspection) n'est apportée au cours de la période spécifiée, aucune donnée n'est reprofilée. Lors de la prochaine modification applicable, les données concernées sont reprofilées dès que possible, en fonction de divers facteurs (tels que la capacité machine disponible ou les unités d'abonnement achetées). Sensitive Data Protection attend alors que les mises à jour s'accumulent à nouveau selon la planification que vous avez définie.
Par exemple, supposons que votre configuration d'analyse soit définie pour reprofiler mensuellement en cas de modification du schéma. Les profils de données ont été créés le jour 0. Aucune modification de schéma n'a lieu d'ici le 30e jour. Par conséquent, aucune donnée n'est reprofilée. Le 35e jour, la première modification du schéma a lieu. Sensitive Data Protection reprofile les données mises à jour lors de la prochaine opportunité. Le système attend ensuite 30 jours supplémentaires pour que les mises à jour du schéma s'accumulent avant de reprofiler les données mises à jour.
Une fois le re-profilage lancé, l'opération peut prendre jusqu'à 24 heures. Si le retard dure plus de 24 heures et que vous êtes en mode de tarification par abonnement, vérifiez si vous disposez d'une capacité restante pour le mois.
Pour obtenir des exemples, consultez la section Exemples de tarification du profilage des données.
Pour forcer le service de découverte à reprofiler vos données, consultez Forcer une opération de reprofilage.
Profiler les performances
Le temps nécessaire pour profiler vos données varie en fonction de plusieurs facteurs, y compris, mais sans s'y limiter :
- Nombre de ressources de données profilées
- Tailles des ressources de données
- Pour les tableaux, le nombre de colonnes
- Pour les tableaux, les types de données dans les colonnes
Par conséquent, les performances de Sensitive Data Protection lors d'une tâche d'inspection ou de profilage passée ne sont pas indicatives de ses performances lors de futures tâches de profilage.
Conservation des profils de données
La protection des données sensibles conserve la dernière version d'un profil de données pendant 13 mois. Lorsque Sensitive Data Protection reprofile une ressource de données, le système remplace les profils existants de cette ressource par de nouveaux.
Dans les exemples de scénarios suivants, supposons que la fréquence de profilage par défaut pour BigQuery est en vigueur :
Le 1er janvier, la protection des données sensibles profile la table A. La table A ne change pas pendant plus d'un an et n'est donc pas profilée à nouveau. Dans ce cas, la protection des données sensibles conserve les profils de données de la table A pendant 13 mois avant de les supprimer.
Le 1er janvier, la protection des données sensibles profile la table A. Au cours du mois, un membre de votre organisation met à jour le schéma de cette table. En raison de cette modification, le mois suivant, la protection des données sensibles reprofile automatiquement la table A. Les profils de données nouvellement générés écrasent ceux créés en janvier.
Pour en savoir plus sur la manière dont Sensitive Data Protection facture le profilage des données, consultez Tarifs de la détection.
Si vous souhaitez conserver indéfiniment les profils de données ou garder une trace des modifications qu'ils subissent, envisagez d'enregistrer les profils de données dans BigQuery lorsque vous configurez le profilage. Vous choisissez l'ensemble de données BigQuery dans lequel enregistrer les profils, et vous contrôlez la règle d'expiration de table pour cet ensemble de données.
Remplacer les configurations d'analyse
Vous ne pouvez créer qu'une seule configuration d'analyse pour chaque combinaison de champ d'application et de type de découverte. Par exemple, vous ne pouvez créer qu'une seule configuration d'analyse au niveau de l'organisation pour le profilage des données BigQuery et une seule configuration d'analyse au niveau de l'organisation pour la découverte des secrets. De même, vous ne pouvez créer qu'une seule configuration d'analyse au niveau du projet pour le profilage des données BigQuery et une seule configuration d'analyse au niveau du projet pour la découverte des secrets.
Si deux configurations d'analyse actives ou plus ont le même projet et le même type de découverte dans leur champ d'application, les règles suivantes s'appliquent :
- Parmi les configurations d'analyse au niveau de l'organisation et du dossier, celle la plus proche du projet pourra exécuter la découverte pour ce projet. Cette règle s'applique même si une configuration d'analyse au niveau du projet avec le même type de découverte existe également.
- La protection des données sensibles traite les configurations d'analyse au niveau du projet indépendamment des configurations au niveau de l'organisation et du dossier. Une configuration d'analyse que vous créez au niveau du projet ne peut pas remplacer une configuration que vous créez pour un dossier ou une organisation parent.
Prenons l'exemple suivant, qui présente trois configurations d'analyse actives. Supposons que toutes ces configurations d'analyse concernent le profilage des données BigQuery.
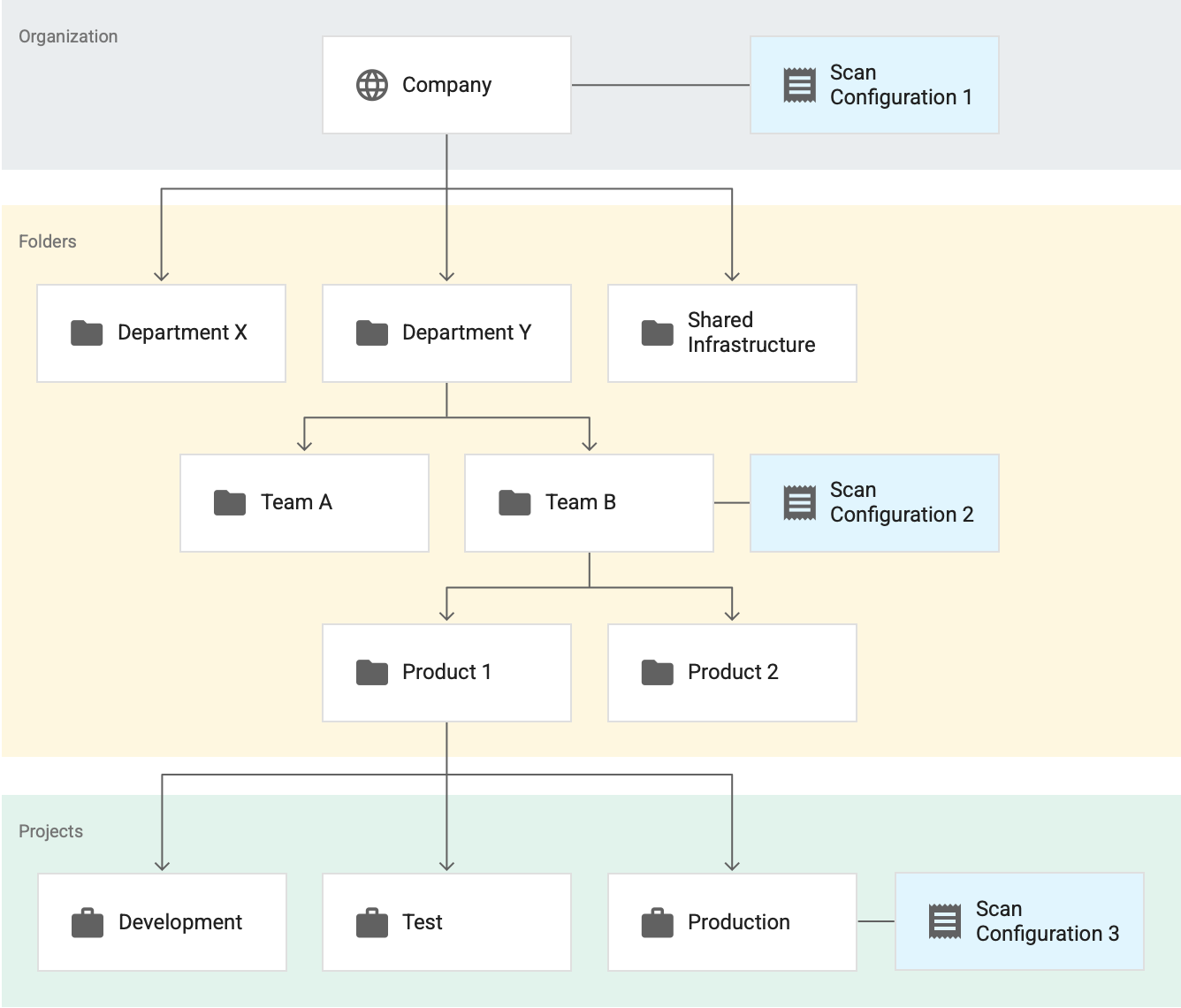
Ici, la Configuration d'analyse 1 s'applique à l'ensemble de l'organisation, la Configuration d'analyse 2 s'applique au dossier Équipe B et la Configuration d'analyse 3 s'applique au projet Production. Dans cet exemple :
- Sensitive Data Protection profile toutes les tables des projets qui ne se trouvent pas dans le dossier Équipe B en se basant sur la Configuration d'analyse 1.
- La protection des données sensibles profile toutes les tables des projets du dossier Équipe B, y compris celles du projet Production, en se basant sur la Configuration d'analyse 2.
- Sensitive Data Protection profile toutes les tables du projet Production en se basant sur la Configuration d'analyse 3.
Dans cet exemple, Sensitive Data Protection génère deux ensembles de profils pour le projet Production, un pour chacune des configurations d'analyse suivantes :
- Configuration d'analyse 2
- Configuration d'analyse 3
Cependant, même s'il existe deux ensembles de profils pour un même projet, ils ne sont pas tous regroupés dans votre tableau de bord. Vous ne voyez que les profils générés dans la ressource (organisation, dossier ou projet) et la région que vous consultez.
Pour en savoir plus sur la hiérarchie des ressources de Google Cloud, consultez Hiérarchie des ressources.
Instantanés de profils de données
Chaque profil de données inclut un instantané de la configuration d'analyse et du modèle d'inspection utilisé pour la générer. Vous pouvez utiliser cet instantané pour vérifier les paramètres que vous avez utilisés pour générer un profil de données spécifique.
Points à prendre en compte concernant la résidence des données
Les considérations relatives à la résidence des données diffèrent selon que vous analysez des donnéesGoogle Cloud ou des données provenant d'autres fournisseurs de cloud.
Points à prendre en compte concernant la résidence des données Google Cloud
Cette section ne s'applique qu'à la découverte des données sensibles pour les ressources Google Cloud. Pour en savoir plus sur la résidence des données concernant les ressources provenant d'autres fournisseurs de services cloud, consultez la section Considérations relatives à la résidence des données pour les données provenant d'autres fournisseurs de services cloud sur cette page.
La protection des données sensibles est conçue pour être compatible avec la résidence des données. Si vous devez respecter les exigences de résidence des données, tenez compte des points suivants :
Modèles d'inspection régionaux
Cette section ne s'applique qu'à la découverte des données sensibles pour les ressources Google Cloud. Pour en savoir plus sur la résidence des données concernant les ressources provenant d'autres fournisseurs de services cloud, consultez la section Considérations relatives à la résidence des données pour les données provenant d'autres fournisseurs de services cloud sur cette page.
Sensitive Data Protection traite vos données dans la région où elles sont stockées. Autrement dit, vos données ne quittent pas leur région actuelle.
En outre, un modèle d'inspection ne peut être utilisé que pour profiler des données résidant dans la même région que ce modèle. Par exemple, si vous configurez la découverte pour qu'elle utilise un modèle d'inspection stocké dans la région us-west1, Sensitive Data Protection ne peut profiler que les données de cette région.
Vous pouvez définir un modèle d'inspection dédié pour chaque région dans laquelle vous disposez de données.
Si vous fournissez un modèle d'inspection stocké dans la région global, Sensitive Data Protection l'utilise pour les données des régions sans modèle d'inspection dédié.
Le tableau suivant fournit des exemples de scénarios :
| Scénario | Compatibilité |
|---|---|
Analyse de données situées dans la région us à l'aide d'un modèle d'inspection situé dans la région us. |
Compatible |
Analyse de données situées dans la région global à l'aide d'un modèle d'inspection situé dans la région us. |
Incompatible |
Analyse de données situées dans la région us à l'aide d'un modèle d'inspection situé dans la région global. |
Compatible |
Analyse de données situées dans la région us à l'aide d'un modèle d'inspection situé dans la région us-east1. |
Incompatible |
Analyse de données situées dans la région us-east1 à l'aide d'un modèle d'inspection situé dans la région us. |
Incompatible |
Analyse de données situées dans la région us à l'aide d'un modèle d'inspection situé dans la région asia. |
Incompatible |
Configuration du profil de données
Cette section ne s'applique qu'à la découverte des données sensibles pour les ressources Google Cloud. Pour en savoir plus sur la résidence des données concernant les ressources provenant d'autres fournisseurs de services cloud, consultez la section Considérations relatives à la résidence des données pour les données provenant d'autres fournisseurs de services cloud sur cette page.
Lorsque Sensitive Data Protection crée des profils de données, il prend un instantané de votre configuration d'analyse et de votre modèle d'inspection qu'il stocke dans chaque profil de données de table ou profil de données de magasin de fichiers.
Si vous configurez la découverte pour qu'elle utilise un modèle d'inspection de la région global, Sensitive Data Protection copie ce modèle dans chaque région contenant des données à profiler. De même, il copie la configuration d'analyse dans ces régions.
Prenons l'exemple suivant : le projet A contient la table 1. La table 1 se trouve dans la région us-west1, la configuration d'analyse se trouve dans la région us-west2 et le modèle d'inspection se trouve dans la région global.
Lorsque Sensitive Data Protection analyse le projet A, il crée les profils de données pour la table 1 et les stocke dans la région us-west1. Le profil de données de table de la table 1 contient des copies de la configuration d'analyse et du modèle d'inspection utilisé dans l'opération de profilage.
Si vous ne souhaitez pas que votre modèle d'inspection soit copié dans d'autres régions, ne configurez pas la protection des données sensibles pour analyser les données dans ces régions.
Stockage régional des profils de données
Cette section ne s'applique qu'à la découverte des données sensibles pour les ressources Google Cloud. Pour en savoir plus sur la résidence des données concernant les ressources provenant d'autres fournisseurs de services cloud, consultez la section Considérations relatives à la résidence des données pour les données provenant d'autres fournisseurs de services cloud sur cette page.
La protection des données sensibles traite vos données dans la région ou la zone multirégionale où elles se trouvent, et stocke les profils de données générés dans la même région ou zone multirégionale.
Pour afficher les profils de données dans la console Google Cloud , vous devez d'abord sélectionner la région dans laquelle ils résident. Si vous disposez de données dans plusieurs régions, vous devez changer de région pour afficher chaque ensemble de profils.
Régions non compatibles
Cette section ne s'applique qu'à la découverte des données sensibles pour les ressources Google Cloud. Pour en savoir plus sur la résidence des données concernant les ressources provenant d'autres fournisseurs de services cloud, consultez la section Considérations relatives à la résidence des données pour les données provenant d'autres fournisseurs de services cloud sur cette page.
Si vous disposez de données dans une région non compatible avec Sensitive Data Protection, le service de découverte ignore ces ressources de données et affiche une erreur lorsque vous affichez les profils de données.
Emplacements multirégionaux
Sensitive Data Protection considère une zone multirégionale comme une région, et non comme un ensemble de régions. Par exemple, l'emplacement multirégional us et l'emplacement us-west1 sont considérés comme deux régions distinctes pour ce qui est de la résidence des données.
Ressources zonales
La protection des données sensibles est un service régional et multirégional. Elle ne fait pas la distinction entre les zones. Pour une ressource zonale compatible, comme une instance Cloud SQL, les données sont traitées dans leur région actuelle, mais pas nécessairement dans leur zone actuelle. Par exemple, si une instance Cloud SQL est stockée dans la zone us-central1-a, Sensitive Data Protection traite et stocke les profils de données dans la région us-central1.
Pour obtenir des informations générales sur les emplacements Google Cloud , consultez Zones géographiques et régions.
Points à prendre en compte concernant la résidence des données provenant d'autres fournisseurs de services cloud
Tenez compte des points suivants lorsque vous prévoyez de profiler des données provenant d'autres fournisseurs de services cloud :
- Les profils de données sont stockés avec la configuration de l'analyse de découverte. En revanche, lorsque vous profilez des données Google Cloud , les profils sont stockés dans la même région que les données à profiler.
- Si vous stockez votre modèle d'inspection dans la région
global, une copie en mémoire de ce modèle est lue dans la région où vous stockez la configuration d'analyse de découverte. - Vos données ne sont pas modifiées. Une copie en mémoire de vos données est lue dans la région où vous stockez la configuration de l'analyse de découverte. Toutefois, Sensitive Data Protection ne fournit aucune garantie concernant le chemin emprunté par les données une fois qu'elles ont atteint l'Internet public. Les données sont chiffrées avec SSL.
Conformité
Pour en savoir plus sur la manière dont la protection des données sensibles gère vos données et vous aide à répondre aux exigences de conformité, consultez la page Sécurité des données.
Étapes suivantes
Lisez l'article du blog "Identité et sécurité" Gestion automatique des risques liés aux données pour BigQuery avec la protection des données sensibles.
Découvrez comment estimer le coût du profilage de données.
Découvrez comment profiler des données au niveau de l'organisation, du dossier ou du projet.
Découvrez comment la protection des données sensibles calcule les niveaux de risque et de sensibilité des données lors du profilage de vos données.
Découvrez comment corriger les résultats de la découverte.
Découvrez comment résoudre les problèmes liés au profileur de données.