Cette page explique comment estimer le coût du profilage des données BigQuery dans une organisation ou un dossier. Si vous souhaitez créer une estimation pour un projet, consultez Estimer le coût du profilage des données pour un seul projet.
Pour en savoir plus sur le profilage des données BigQuery, consultez Profils de données pour les données BigQuery.
Présentation
Avant de commencer à générer des profils de données, vous pouvez effectuer une estimation afin de déterminer le volume de données BigQuery dont vous disposez et le coût de leur profilage. Pour exécuter une estimation, vous devez en créer une.
Lorsque vous créez une estimation, vous spécifiez la ressource (organisation, dossier ou projet) contenant les données que vous souhaitez profiler. Vous pouvez définir des filtres pour affiner la sélection de données. Vous pouvez également définir des conditions qui doivent être remplies pour que Sensitive Data Protection profile une table. La protection des données sensibles base l'estimation sur la forme, la taille et le type des données au moment où vous la créez.
Chaque estimation inclut des détails tels que le nombre de tables correspondantes trouvées dans la ressource, la taille totale de toutes ces tables et le coût estimé du profilage de la ressource une fois et sur une base mensuelle.
Pour en savoir plus sur le calcul des tarifs, consultez Tarifs du profilage de données.
Estimation des tarifs
La création d'une estimation est gratuite.
Fidélisation
Chaque estimation est automatiquement supprimée au bout de 28 jours.
Limites
Si votre organisation ou votre dossier comporte un projet protégé par un périmètre de service VPC Service Controls, il est possible que Sensitive Data Protection sous-estime la quantité de données BigQuery dans votre ressource. Si vous avez des périmètres de service, créez une estimation pour chacun d&#périmètre de service;eux de manière indépendante.
Avant de commencer
Pour obtenir les autorisations nécessaires pour créer et gérer des estimations des coûts de profilage des données, demandez à votre administrateur de vous accorder le rôle IAM Administrateur DLP (roles/dlp.admin) sur l'organisation ou le dossier.
Pour en savoir plus sur l'attribution de rôles, consultez la page Gérer l'accès aux projets, aux dossiers et aux organisations.
Vous pouvez également obtenir les autorisations requises avec des rôles personnalisés ou d'autres rôles prédéfinis.
Créer une estimation
Accédez à la page Créer une estimation du profil de données.
Sélectionnez votre organisation.
Les sections suivantes fournissent plus d'informations sur les étapes de la page Créer une estimation du profil de données. À la fin de chaque section, cliquez sur Continuer.
Sélectionner la ressource à analyser
Effectuez l'une des opérations suivantes :- Pour créer une estimation pour une organisation, sélectionnez Analyser l'ensemble de l'organisation.
- Pour créer une estimation pour un dossier, sélectionnez Analyser le dossier sélectionné. Cliquez ensuite sur Parcourir et sélectionnez le dossier.
Renseigner les filtres et conditions
Vous pouvez ignorer cette section si vous souhaitez inclure toutes les tables BigQuery de l'organisation ou du dossier dans votre estimation.Dans cette section, vous allez créer des filtres pour spécifier certains sous-ensembles de vos données que vous souhaitez inclure dans l'estimation ou en exclure. Pour les sous-ensembles que vous incluez dans l'estimation, vous devez également spécifier les conditions qu'une table du sous-ensemble doit remplir pour être incluse dans l'estimation.
Pour définir des filtres et des conditions, procédez comme suit :
- Cliquez sur Ajouter des filtres et des conditions.
Dans la section Filtres, vous définissez un ou plusieurs filtres qui spécifient les tables incluses dans le champ d'application de l'estimation.
Indiquez au moins l'un des éléments suivants :
- ID de projet ou expression régulière spécifiant un ou plusieurs projets.
- ID d'un ensemble de données ou expression régulière spécifiant un ou plusieurs ensembles de données.
- ID de table ou expression régulière spécifiant une ou plusieurs tables.
Les expressions régulières doivent suivre la syntaxe RE2.
Par exemple, si vous souhaitez inclure toutes les tables d'un projet dans le filtre, spécifiez l'ID de ce projet et laissez les deux autres champs vides.
Pour ajouter d'autres filtres, cliquez sur Ajouter un filtre et répétez cette étape.
Si les sous-ensembles de données définis par vos filtres doivent être exclus de l'estimation, désactivez l'option Inclure les tables correspondantes dans mon estimation. Si vous désactivez cette option, les conditions décrites dans le reste de cette section sont masquées.
Facultatif : Dans la section Conditions, spécifiez les conditions que les tables correspondantes doivent remplir pour être incluses dans l'estimation. Si vous ignorez cette étape, la protection des données sensibles inclut toutes les tables compatibles qui correspondent à vos filtres, quels que soient leur taille et leur ancienneté.
Configurez les options suivantes :
Conditions minimales : pour exclure les petites tables ou les nouvelles tables de l'estimation, définissez un nombre minimal de lignes ou un âge minimal pour les tables.
Condition temporelle : activez la condition temporelle pour exclure les anciens tableaux. Sélectionnez ensuite une date et une heure. Toute table créée à cette date ou avant est exclue de l'estimation.
Par exemple, si vous définissez la condition temporelle sur 4/5/22, 23h59, Sensitive Data Protection exclut de l'estimation toutes les tables créées le 4 mai 2022 à 23h59 ou avant.
Tables à profiler : pour spécifier les types de tables à inclure dans l'estimation, sélectionnez Inclure uniquement les tables d'un ou de plusieurs types spécifiés. Sélectionnez ensuite les types de tables que vous souhaitez inclure.
Si vous n'activez pas cette condition ou si vous ne sélectionnez aucun type de table, la protection des données sensibles inclut toutes les tables compatibles dans l'estimation.
Supposons que vous ayez la configuration suivante :
Conditions minimales
- Nombre minimal de lignes : 10
- Durée minimale : 24 heures
Condition temporelle
- Timestamp : 04/05/2022, 23:59
Tables à profiler
L'option Inclure uniquement les tables d'un ou de plusieurs types spécifiés est sélectionnée. Dans la liste des types de tables, seule l'option Tables BigLake de profil est sélectionnée.
Dans ce cas, Sensitive Data Protection exclut toutes les tables créées le 4 mai 2022 à 23h59 ou avant. Parmi les tables créées après cette date et heure, la protection des données sensibles ne profile que les tables BigLake qui comportent 10 lignes ou qui ont au moins 24 heures.
Cliquez sur OK.
Si vous souhaitez ajouter d'autres filtres et conditions, cliquez sur Ajouter des filtres et des conditions, puis répétez les étapes précédentes.
Le dernier élément de la liste des filtres et des conditions est toujours celui intitulé Filtres et conditions par défaut. Ce paramètre par défaut est appliqué aux tables de la ressource sélectionnée (organisation ou dossier) qui ne correspondent à aucun des filtres ni à aucune des conditions que vous avez créés.
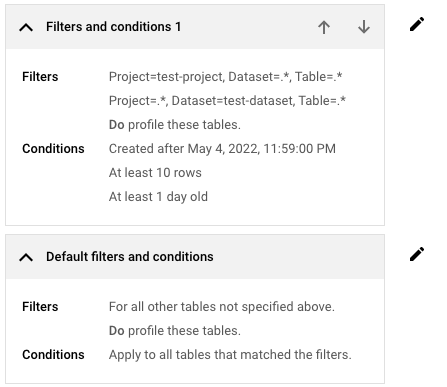
Si vous souhaitez ajuster les filtres et les conditions par défaut, cliquez sur Modifier les filtres et les conditions, puis ajustez les paramètres si nécessaire.
Gérer le conteneur et la facturation de l'agent de service
Dans cette section, vous spécifiez le projet à utiliser en tant que conteneur d'agent de service. Vous pouvez demander à la protection des données sensibles de créer automatiquement un projet, ou bien sélectionner un projet existant.
Que vous utilisiez un agent de service nouvellement créé ou que vous en réutilisiez un existant, assurez-vous qu'il dispose d'un accès en lecture aux données à profiler.
Créer automatiquement un projet
Si vous ne disposez pas des autorisations nécessaires pour créer un projet dans l'organisation, vous devez sélectionner un projet existant ou obtenir les autorisations requises. Pour en savoir plus sur les autorisations requises, consultez Rôles requis pour utiliser des profils de données au niveau de l'organisation ou des dossiers.
Pour créer automatiquement un projet à utiliser comme conteneur d'agent de service, procédez comme suit :
- Dans le champ Conteneur de l'agent de service, vérifiez l'ID de projet suggéré et modifiez-le si nécessaire.
- Cliquez sur Créer.
- Facultatif : Modifiez le nom du projet par défaut.
Sélectionnez le compte à facturer pour toutes les opérations facturables associées à ce nouveau projet, y compris les opérations non liées à la découverte.
Cliquez sur Créer.
Sensitive Data Protection crée le projet. L'agent de service de ce projet sera utilisé pour s'authentifier auprès de Sensitive Data Protection et d'autres API.
Sélectionner un projet existant
Pour sélectionner un projet existant comme conteneur d'agent de service, cliquez sur le champ Conteneur d'agent de service et sélectionnez le projet.
Définir l'emplacement de stockage de l'estimation
Dans la liste Emplacement de la ressource, sélectionnez la région dans laquelle vous souhaitez stocker cette estimation.
L'emplacement où vous choisissez de stocker votre estimation n'affecte pas les données à analyser. De plus, l'emplacement de stockage des profils de données n'est pas affecté. Vos données sont analysées dans la région dans laquelle elles sont stockées (telles que définies dans BigQuery). Pour en savoir plus, consultez la section Considérations relatives à la résidence des données.
Vérifiez vos paramètres, puis cliquez sur Créer.
Sensitive Data Protection crée l'estimation et l'ajoute à la liste des estimations. Il exécute ensuite l'estimation.
Selon la quantité de données contenues dans la ressource, l'estimation peut prendre jusqu'à 24 heures. En attendant, vous pouvez fermer la page "Sensitive Data Protection" et revenir plus tard. Une notification s'affiche dans la console Google Cloud lorsque l'estimation est prête.
Afficher une estimation
Accédez à la liste des estimations.
Cliquez sur l'estimation que vous souhaitez afficher. L'estimation contient les éléments suivants :
- Nombre de tables dans la ressource, moins celles que vous avez exclues à l'aide de filtres et de conditions.
- Quantité totale de données correspondant aux tables.
- Nombre d'unités d'abonnement requises pour profiler cette quantité de données chaque mois.
- Le coût de la découverte initiale, qui correspond au coût approximatif du profilage des tables trouvées. Cette estimation n'est basée que sur un instantané des données actuelles et ne tient pas compte de la croissance de vos données au cours d'une période donnée.
- Estimations de coûts supplémentaires pour le profilage des tables datant de moins de 6, 12 ou 24 mois. Ces estimations supplémentaires sont fournies pour vous montrer comment limiter davantage la couverture de vos données peut vous aider à contrôler le coût du profilage de vos données.
- Coût mensuel estimé du profilage de vos données, en supposant que votre utilisation de BigQuery chaque mois est la même que celle de ce mois-ci.
- Graphique montrant la croissance de votre BigQuery au fil du temps.
- Les détails de configuration que vous avez définis.
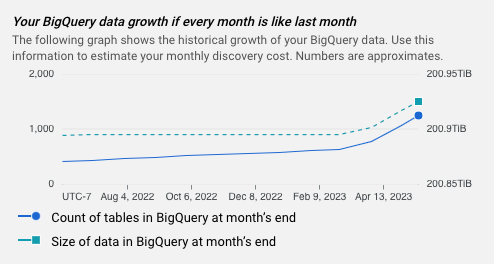
Graphique des estimations
Chaque estimation inclut un graphique qui montre l'historique de la croissance de vos données BigQuery. Vous pouvez utiliser ces informations pour estimer votre coût de profilage des données mensuel.
Étapes suivantes
- En savoir plus sur les tarifs du profilage de données
- En savoir plus sur les profils de données pour les données BigQuery
- Découvrez comment profiler les données d'une organisation ou d'un dossier.
- Découvrez comment profiler des données dans un seul projet.