La maggior parte dei bilanciatori del carico utilizza un approccio di hashing round robin o basato sul flusso per distribuire il traffico. I bilanciatori del carico che utilizzano questo approccio possono avere difficoltà ad adattarsi quando la domanda di traffico supera la capacità di pubblicazione disponibile. Questo tutorial mostra come Cloud Load Balancing ottimizza la capacità della tua applicazione globale, con conseguente miglioramento dell'esperienza utente e riduzione dei costi rispetto alla maggior parte delle implementazioni di bilanciamento del carico.
Questo articolo fa parte di una serie di best practice per i prodotti Cloud Load Balancing. Questo tutorial è accompagnato da Ottimizzazioni della capacità delle applicazioni con il bilanciamento del carico globale, un articolo concettuale che spiega in modo più dettagliato i meccanismi di overflow del bilanciamento del carico globale. Per approfondire l'argomento della latenza, consulta Ottimizzazione della latenza delle applicazioni con Cloud Load Balancing.
Questo tutorial presuppone che tu abbia una certa esperienza con Compute Engine. Dovresti anche conoscere le nozioni di base sul bilanciatore del carico delle applicazioni esterno.
Obiettivi
In questo tutorial, configurerai un semplice server web che esegue un'applicazione che utilizza molta CPU e calcola gli insiemi di Mandelbrot. Inizia misurando la capacità di rete utilizzando strumenti di test del carico (siege e httperf). Poi, ridimensiona la rete su più istanze VM in una singola regione e misura il tempo di risposta sotto carico. Infine, scala la rete a più regioni utilizzando il bilanciamento del carico globale e poi misura il tempo di risposta del server sotto carico e confrontalo con il bilanciamento del carico a livello di singola regione. L'esecuzione di questa sequenza di test ti consente di vedere gli effetti positivi della gestione del carico interregionale di Cloud Load Balancing.
La velocità di comunicazione di rete di una tipica architettura server a tre livelli è solitamente limitata dalla velocità del server delle applicazioni o dalla capacità del database anziché dal carico della CPU sul server web. Dopo aver completato il tutorial, puoi utilizzare gli stessi strumenti di test del carico e le stesse impostazioni di capacità per ottimizzare il comportamento di bilanciamento del carico in un'applicazione reale.
Imparerai a:
- Scopri come utilizzare gli strumenti di test di carico (
siegeehttperf). - Determina la capacità di pubblicazione di una singola istanza VM.
- Misura gli effetti del sovraccarico con il bilanciamento del carico in una sola regione.
- Misura gli effetti del overflow in un'altra regione con il bilanciamento del carico globale.
Costi
Questo tutorial utilizza componenti fatturabili di Google Cloud, tra cui:
- Compute Engine
- Bilanciamento del carico e regole di forwarding
Utilizza il Calcolatore prezzi per generare una stima dei costi in base all'utilizzo previsto.
Prima di iniziare
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Configurazione dell'ambiente
In questa sezione configurerai le impostazioni del progetto, la rete VPC e le regole firewall di base necessarie per completare il tutorial.
Avviare un'istanza Cloud Shell
Apri Cloud Shell dalla Google Cloud console. Se non diversamente indicato, esegui il resto del tutorial da Cloud Shell.
Configura le impostazioni del progetto
Per semplificare l'esecuzione dei comandi gcloud, puoi impostare le proprietà in modo da non dover fornire opzioni per queste proprietà con ogni comando.
Imposta il progetto predefinito utilizzando l'ID progetto per
[PROJECT_ID]:gcloud config set project [PROJECT_ID]
Imposta la zona predefinita di Compute Engine utilizzando la zona che preferisci per
[ZONE]e poi impostala come variabile di ambiente per un utilizzo successivo:gcloud config set compute/zone [ZONE] export ZONE=[ZONE]
Crea e configura la rete VPC
Crea una rete VPC per i test:
gcloud compute networks create lb-testing --subnet-mode auto
Definisci una regola firewall per consentire il traffico interno:
gcloud compute firewall-rules create lb-testing-internal \ --network lb-testing --allow all --source-ranges 10.128.0.0/11Definisci una regola firewall per consentire al traffico SSH di comunicare con la rete VPC:
gcloud compute firewall-rules create lb-testing-ssh \ --network lb-testing --allow tcp:22 --source-ranges 0.0.0.0/0
Determinare la capacità di pubblicazione di una singola istanza VM
Per esaminare le caratteristiche di rendimento di un tipo di istanza VM, devi procedere nel seguente modo:
Configura un'istanza VM che gestisca il workload di esempio (l'istanza del server web).
Crea una seconda istanza VM nella stessa zona (l'istanza di test del carico).
Con la seconda istanza VM, misurerai le prestazioni utilizzando semplici strumenti di test di carico e misurazione delle prestazioni. Utilizzerai queste misurazioni più avanti nel tutorial per definire l'impostazione corretta della capacità di bilanciamento del carico per il gruppo di istanze.
La prima istanza VM utilizza uno script Python per creare un'attività che richiede un uso intensivo della CPU calcolando e visualizzando un'immagine di un insieme di Mandelbrot a ogni richiesta al percorso radice (/). Il risultato non viene memorizzato nella cache. Durante il tutorial, recupererai lo script Python dal repository GitHub utilizzato per questa soluzione.
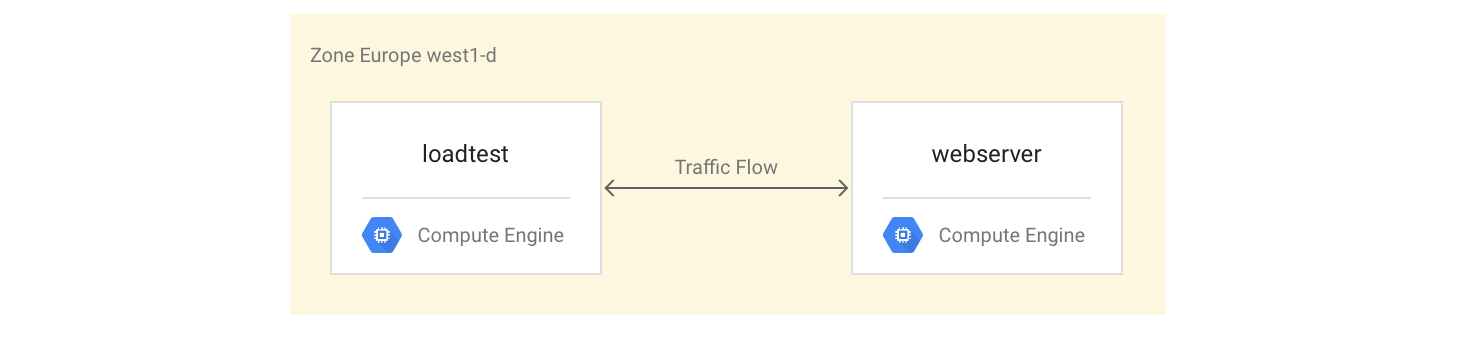
Configurazione delle istanze VM
Configura l'istanza VM
webservercome istanza VM a 4 core installando e avviando il server Mandelbrot:gcloud compute instances create webserver --machine-type n1-highcpu-4 \ --network=lb-testing --image-family=debian-12 \ --image-project=debian-cloud --tags=http-server \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'Crea una regola firewall per consentire l'accesso esterno all'istanza
webserverdalla tua macchina:gcloud compute firewall-rules create lb-testing-http \ --network lb-testing --allow tcp:80 --source-ranges 0.0.0.0/0 \ --target-tags http-serverOttieni l'indirizzo IP dell'istanza
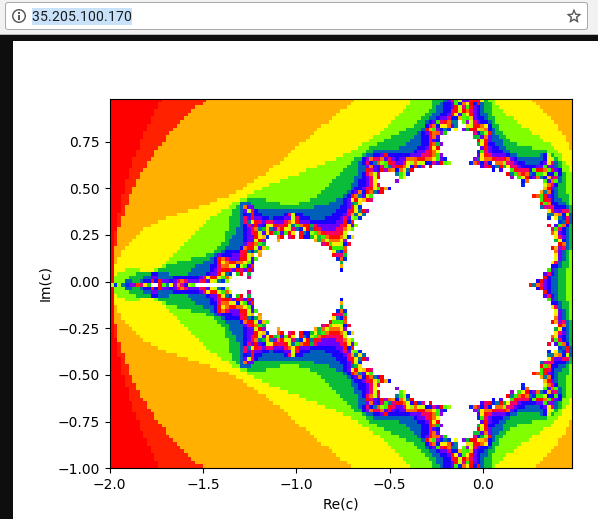
webserver:gcloud compute instances describe webserver \ --format "value(networkInterfaces[0].accessConfigs[0].natIP)"In un browser web, vai all'indirizzo IP restituito dal comando precedente. Viene visualizzato un insieme di Mandelbrot calcolato:
Crea l'istanza di test di carico:
gcloud compute instances create loadtest --machine-type n1-standard-1 \ --network=lb-testing --image-family=debian-12 \ --image-project=debian-cloud
Test delle istanze VM
Il passaggio successivo consiste nell'eseguire richieste per valutare le caratteristiche di rendimento dell'istanza VM di test di carico.
Utilizza il comando
sshper connetterti all'istanza VM di test di carico:gcloud compute ssh loadtest
Sull'istanza di test di carico, installa siege e httperf come strumenti di test di carico:
sudo apt-get install -y siege httperf
Lo strumento
siegeconsente di simulare le richieste di un numero specificato di utenti, effettuando richieste successive solo dopo che gli utenti hanno ricevuto una risposta. In questo modo ottieni informazioni dettagliate sulla capacità e sui tempi di risposta previsti per le applicazioni in un ambiente reale.Lo strumento
httperfconsente di inviare un numero specifico di richieste al secondo indipendentemente dal fatto che vengano ricevute risposte o errori. In questo modo puoi ottenere informazioni su come le applicazioni rispondono a un carico specifico.Misura il tempo impiegato per una semplice richiesta al server web:
curl -w "%{time_total}\n" -o /dev/#objectives_2 -s webserverRicevi una risposta come 0,395260. Ciò significa che il server ha impiegato 395 millisecondi (ms) per rispondere alla tua richiesta.
Utilizza il seguente comando per eseguire 20 richieste da 4 utenti in parallelo:
siege -c 4 -r 20 webserver
Vedi un output simile al seguente:
** SIEGE 4.0.2 ** Preparing 4 concurrent users for battle. The server is now under siege... Transactions: 80 hits Availability: 100.00 % Elapsed time: 14.45 secs Data transferred: 1.81 MB Response time: 0.52 secs Transaction rate: 5.05 trans/sec Throughput: 0.12 MB/sec Concurrency: 3.92 Successful transactions: 80 Failed transactions: 0 **Longest transaction: 0.70 Shortest transaction: 0.37 **
L'output è spiegato in dettaglio nel manuale di Siege, ma in questo esempio puoi vedere che i tempi di risposta variano tra 0,37 secondi e 0,7 secondi. In media, sono state elaborate 5,05 richieste al secondo. Questi dati aiutano a stimare la capacità di pubblicazione del sistema.
Esegui i seguenti comandi per convalidare i risultati utilizzando lo strumento di test di carico
httperf:httperf --server webserver --num-conns 500 --rate 4
Questo comando esegue 500 richieste alla velocità di 4 richieste al secondo, ovvero meno delle 5,05 transazioni al secondo completate da
siege.Vedi un output simile al seguente:
httperf --client=0/1 --server=webserver --port=80 --uri=/ --rate=4 --send-buffer=4096 --recv-buffer=16384 --num-conns=500 --num-calls=1 httperf: warning: open file limit > FD_SETSIZE; limiting max. # of open files to FD_SETSIZE Maximum connect burst length: 1 Total: connections 500 requests 500 replies 500 test-duration 125.333 s Connection rate: 4.0 conn/s (251.4 ms/conn, <=2 concurrent connections) **Connection time [ms]: min 369.6 avg 384.5 max 487.8 median 377.5 stddev 18.0 Connection time [ms]: connect 0.3** Connection length [replies/conn]: 1.000 Request rate: 4.0 req/s (251.4 ms/req) Request size [B]: 62.0 Reply rate [replies/s]: min 3.8 avg 4.0 max 4.0 stddev 0.1 (5 samples) Reply time [ms]: response 383.8 transfer 0.4 Reply size [B]: header 117.0 content 24051.0 footer 0.0 (total 24168.0) Reply status: 1xx=0 2xx=100 3xx=0 4xx=0 5xx=0 CPU time [s]: user 4.94 system 20.19 (user 19.6% system 80.3% total 99.9%) Net I/O: 94.1 KB/s (0.8*10^6 bps) Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
L'output è spiegato nel file README di httperf. Prendi nota della riga che inizia con
Connection time [ms], che mostra che le connessioni hanno richiesto un totale di tempo compreso tra 369,6 e 487,8 ms e hanno generato zero errori.Ripeti il test 3 volte, impostando l'opzione
ratesu 5, 7 e 10 richieste al secondo.I seguenti blocchi mostrano i comandi
httperfe il relativo output (mostrando solo le righe pertinenti con le informazioni sul tempo di connessione).Comando per 5 richieste al secondo:
httperf --server webserver --num-conns 500 --rate 5 2>&1| grep 'Errors\|ion time'
Risultati per 5 richieste al secondo:
Connection time [ms]: min 371.2 avg 381.1 max 447.7 median 378.5 stddev 7.2 Connection time [ms]: connect 0.2 Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
Comando per 7 richieste al secondo:
httperf --server webserver --num-conns 500 --rate 7 2>&1| grep 'Errors\|ion time'
Risultati per 7 richieste al secondo:
Connection time [ms]: min 373.4 avg 11075.5 max 60100.6 median 8481.5 stddev 10284.2 Connection time [ms]: connect 654.9 Errors: total 4 client-timo 0 socket-timo 0 connrefused 0 connreset 4 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
Comando per 10 richieste al secondo:
httperf --server webserver --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
Risultati per 10 richieste al secondo:
Connection time [ms]: min 374.3 avg 18335.6 max 65533.9 median 10052.5 stddev 16654.5 Connection time [ms]: connect 181.3 Errors: total 32 client-timo 0 socket-timo 0 connrefused 0 connreset 32 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
Esci dall'istanza
webserver:exit
Da queste misurazioni puoi concludere che il sistema ha una capacità di circa 5 richieste al secondo (RPS). A 5 richieste al secondo, l'istanza VM reagisce con una latenza paragonabile a 4 connessioni. Con 7 e 10 connessioni al secondo, il tempo di risposta medio aumenta drasticamente a oltre 10 secondi con più errori di connessione. In altre parole, qualsiasi valore superiore a 5 richieste al secondo causa rallentamenti significativi.
In un sistema più complesso, la capacità del server viene determinata in modo simile,
ma dipende molto dalla capacità di tutti i suoi componenti. Puoi utilizzare gli strumenti
siege e httperf insieme al monitoraggio del carico di CPU e I/O di tutti i
componenti (ad esempio, il server frontend, il server delle applicazioni e il
server di database) per identificare i colli di bottiglia. Ciò a sua volta può aiutarti ad attivare
la scalabilità ottimale per ogni componente.
Misurazione degli effetti del sovraccarico con un bilanciatore del carico a livello di regione
In questa sezione, esamini gli effetti del sovraccarico sui bilanciatori del carico a singola regione, come i tipici bilanciatori del carico utilizzati on-premise o il Google Cloud bilanciatore del carico di rete passthrough esterno. Puoi osservare questo effetto anche con un bilanciatore del carico HTTP(S) quando viene utilizzato per un deployment regionale (anziché globale).
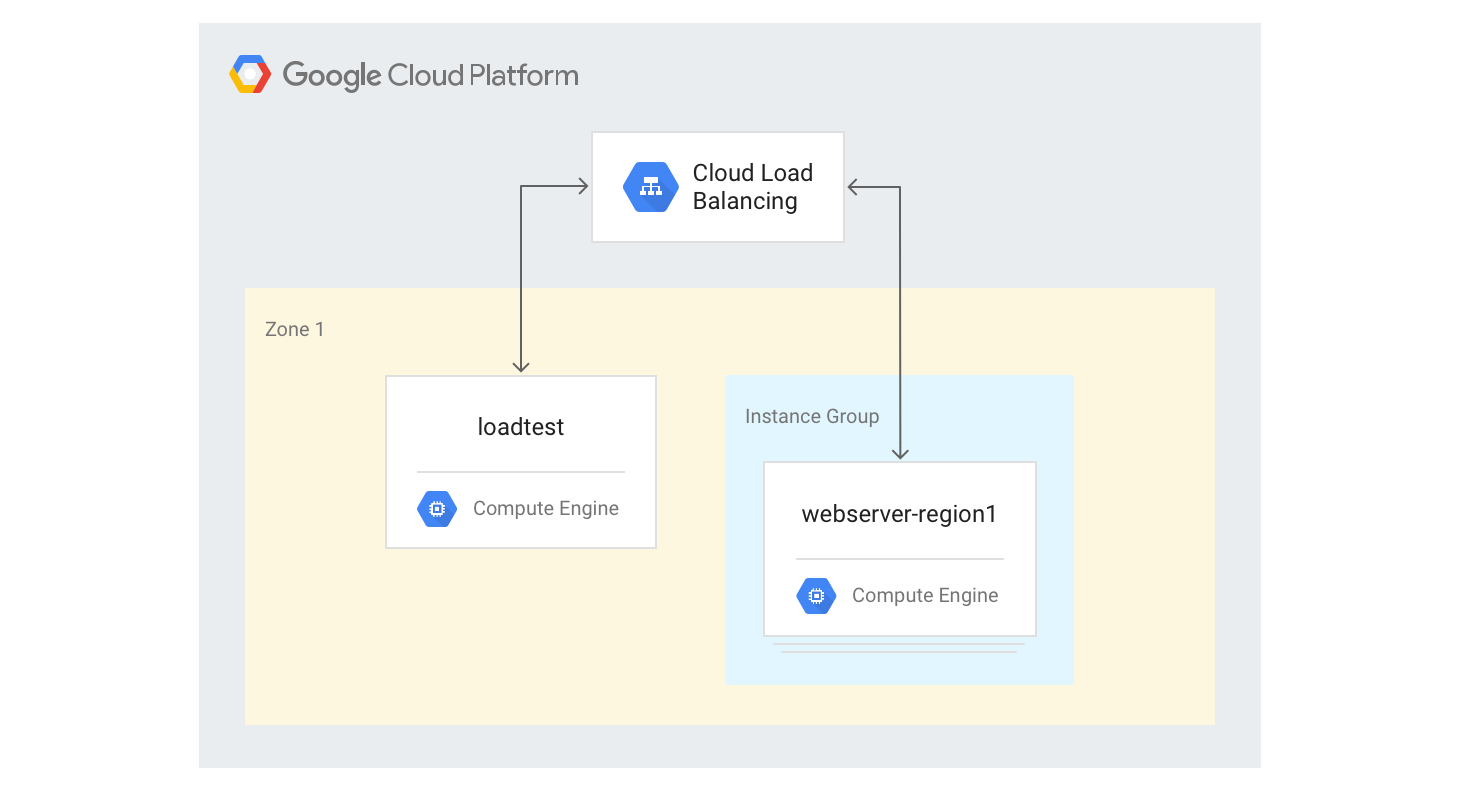
Creazione del bilanciatore del carico HTTP(S) a singola regione
I seguenti passaggi descrivono come creare un bilanciatore del carico HTTP(S) a singola regione con una dimensione fissa di 3 istanze VM.
Crea un modello di istanza per le istanze VM del server web utilizzando lo script di generazione di Mandelbrot in Python che hai utilizzato in precedenza. Esegui i seguenti comandi in Cloud Shell:
gcloud compute instance-templates create webservers \ --machine-type n1-highcpu-4 \ --image-family=debian-12 --image-project=debian-cloud \ --tags=http-server \ --network=lb-testing \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'Crea un gruppo di istanze gestite con 3 istanze basate sul modello del passaggio precedente:
gcloud compute instance-groups managed create webserver-region1 \ --size=3 --template=webserversCrea il controllo di integrità, il servizio di backend, la mappa URL, il proxy di destinazione e la regola di forwarding globale necessari per generare il bilanciamento del carico HTTP:
gcloud compute health-checks create http basic-check \ --request-path="/health-check" --check-interval=60s gcloud compute backend-services create web-service \ --health-checks basic-check --global gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE gcloud compute url-maps create web-map --default-service web-service gcloud compute target-http-proxies create web-proxy --url-map web-map gcloud compute forwarding-rules create web-rule --global \ --target-http-proxy web-proxy --ports 80Ottieni l'indirizzo IP della regola di forwarding:
gcloud compute forwarding-rules describe --global web-rule --format "value(IPAddress)"
L'output è l'indirizzo IP pubblico del bilanciatore del carico che hai creato.
In un browser, vai all'indirizzo IP restituito dal comando precedente. Dopo qualche minuto, vedrai la stessa immagine di Mandelbrot che hai visto in precedenza. Tuttavia, questa volta l'immagine viene pubblicata da una delle istanze VM nel gruppo appena creato.
Accedi al computer
loadtest:gcloud compute ssh loadtest
Nella riga di comando della macchina
loadtest, testa la risposta del server con diversi numeri di richieste al secondo (RPS). Assicurati di utilizzare valori RPS almeno nell'intervallo da 5 a 20.Ad esempio, il seguente comando genera 10 RPS. Sostituisci
[IP_address]con l'indirizzo IP del bilanciatore del carico di un passaggio precedente di questa procedura.httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
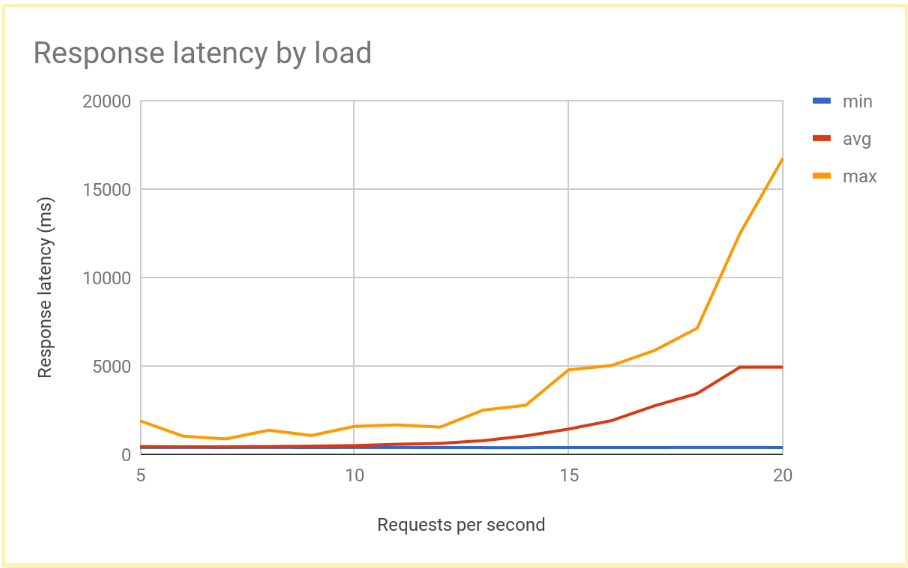
La latenza di risposta aumenta in modo significativo all'aumentare del numero di RPS oltre 12 o 13 RPS. Ecco una visualizzazione dei risultati tipici:
Esci dall'istanza VM
loadtest:exit
Queste prestazioni sono tipiche di un sistema con bilanciamento del carico a livello di regione. Man mano che il carico aumenta oltre la capacità di gestione, la latenza media e massima delle richieste aumenta notevolmente. Con 10 RPS, la latenza media delle richieste è vicina a 500 ms, ma con 20 RPS la latenza è di 5000 ms. La latenza è aumentata di dieci volte e l'esperienza utente peggiora rapidamente, portando all'abbandono degli utenti o ai timeout delle applicazioni o a entrambi.
Nella sezione successiva, aggiungerai una seconda regione alla topologia di bilanciamento del carico e confronterai l'impatto del failover cross-region sulla latenza dell'utente finale.
Misurare gli effetti di overflow in un'altra regione
Se utilizzi un'applicazione globale con un bilanciatore del carico delle applicazioni esterno e se hai backend di cui è stato eseguito il deployment in più regioni, quando si verifica un sovraccarico di capacità in una singola regione, il traffico viene automaticamente indirizzato a un'altra regione. Puoi convalidare questa operazione aggiungendo un secondo gruppo di istanze VM in un'altra regione alla configurazione che hai creato nella sezione precedente.
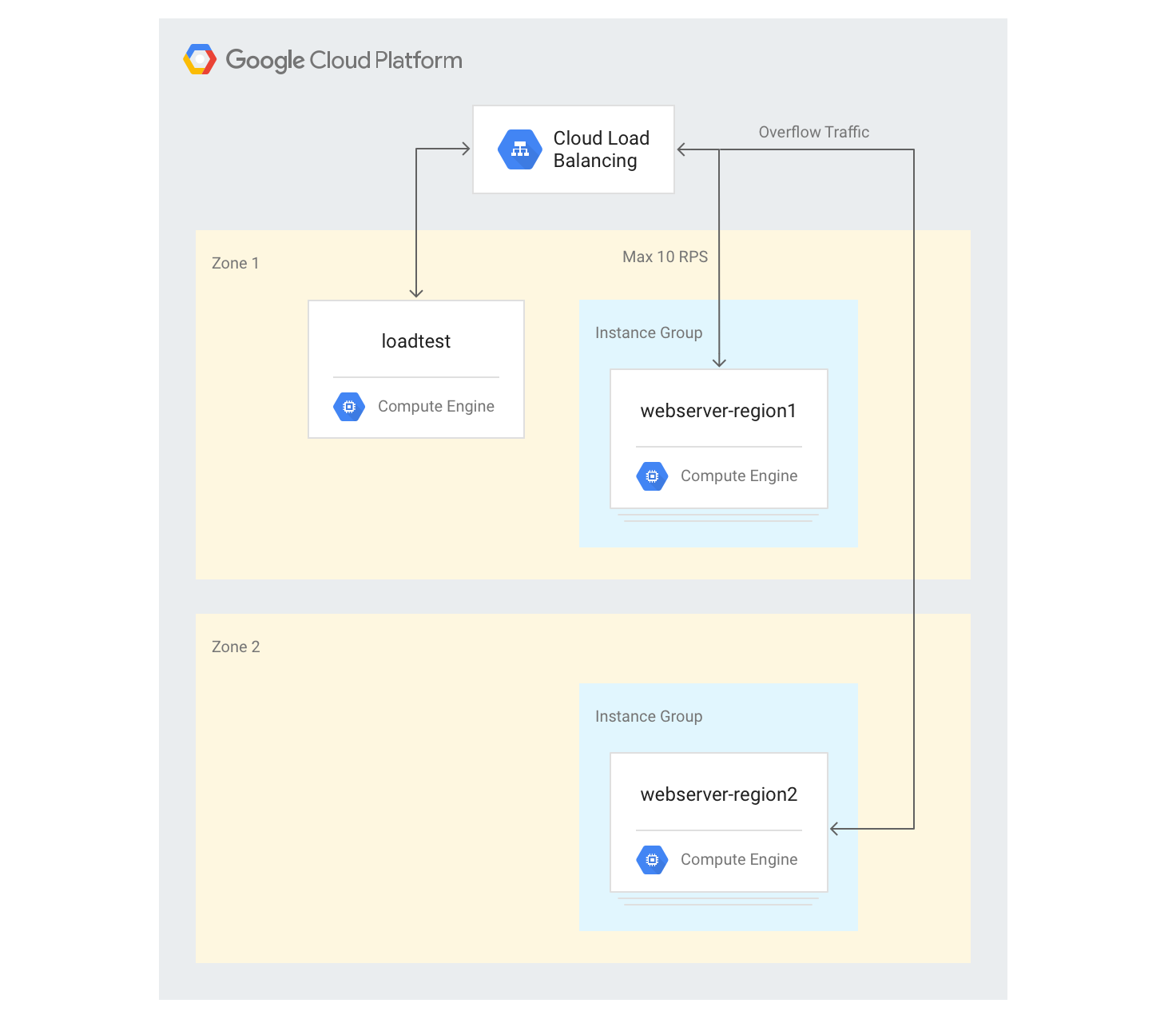
Creazione di server in più regioni
Nei passaggi successivi, aggiungerai un altro gruppo di backend in un'altra regione e assegnerai una capacità di 10 RPS per regione. Puoi quindi vedere come reagisce il bilanciamento del carico quando questo limite viene superato.
In Cloud Shell, scegli una zona in una regione diversa da quella predefinita e impostala come variabile di ambiente:
export ZONE2=[zone]
Crea un nuovo gruppo di istanze nella seconda regione con tre istanze VM:
gcloud compute instance-groups managed create webserver-region2 \ --size=3 --template=webservers --zone $ZONE2Aggiungi il gruppo di istanze al servizio di backend esistente con una capacità massima di 10 RPS:
gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region2 \ --instance-group-zone $ZONE2 --max-rate 10Modifica
max-ratea 10 RPS per il servizio di backend esistente:gcloud compute backend-services update-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE --max-rate 10Dopo l'avvio di tutte le istanze, accedi all'istanza VM
loadtest:gcloud compute ssh loadtest
Esegui 500 richieste a 10 RPS. Sostituisci
[IP_address]con l'indirizzo IP del bilanciatore del carico:httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'ion time'
Vengono visualizzati risultati simili ai seguenti:
Connection time [ms]: min 405.9 avg 584.7 max 1390.4 median 531.5 stddev 181.3 Connection time [ms]: connect 1.1
I risultati sono simili a quelli prodotti dal bilanciatore del carico regionale.
Poiché lo strumento di test esegue immediatamente un caricamento completo e non aumenta lentamente il carico come un'implementazione reale, devi ripetere il test un paio di volte affinché il meccanismo di overflow abbia effetto. Esegui 500 richieste 5 volte a 20 RPS. Sostituisci
[IP_address]con l'indirizzo IP del bilanciatore del carico.for a in \`seq 1 5\`; do httperf --server [IP_address] \ --num-conns 500 --rate 20 2>&1| grep 'ion time' ; doneVengono visualizzati risultati simili ai seguenti:
Connection time [ms]: min 426.7 avg 6396.8 max 13615.1 median 7351.5 stddev 3226.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 417.2 avg 3782.9 max 7979.5 median 3623.5 stddev 2479.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 411.6 avg 860.0 max 3971.2 median 705.5 stddev 492.9 Connection time [ms]: connect 0.7 Connection time [ms]: min 407.3 avg 700.8 max 1927.8 median 667.5 stddev 232.1 Connection time [ms]: connect 0.7 Connection time [ms]: min 410.8 avg 701.8 max 1612.3 median 669.5 stddev 209.0 Connection time [ms]: connect 0.8
Una volta stabilizzato il sistema, il tempo di risposta medio è di 400 ms a 10 RPS e aumenta solo a 700 ms a 20 RPS. Si tratta di un miglioramento enorme rispetto al ritardo di 5000 ms offerto da un bilanciamento del carico regionale, che si traduce in un'esperienza utente molto migliore.
Il seguente grafico mostra il tempo di risposta misurato in base a RPS utilizzando il bilanciamento del carico globale:
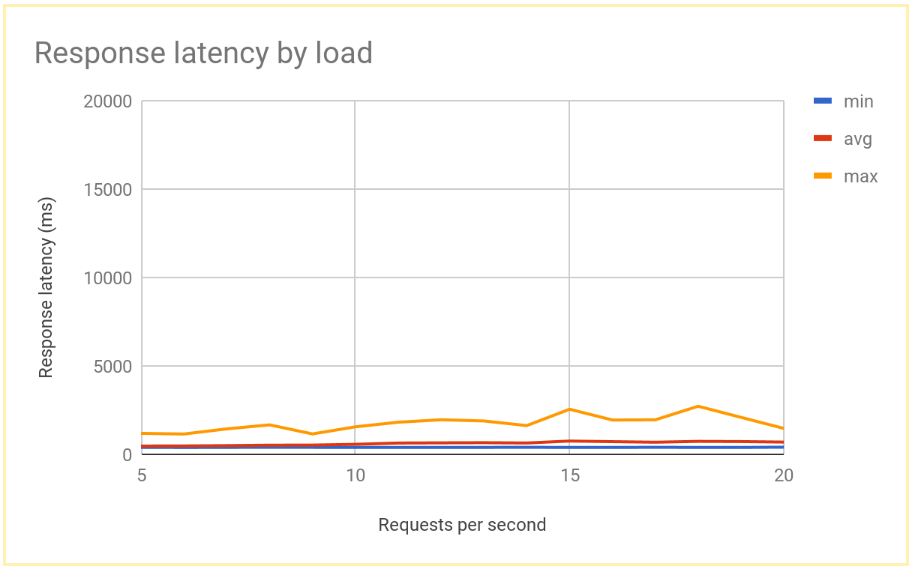
Confronto dei risultati del bilanciamento del carico regionale e globale
Una volta stabilita la capacità di un singolo nodo, puoi confrontare la latenza osservata dagli utenti finali in un deployment basato sulla regione con la latenza in un'architettura di bilanciamento del carico globale. Sebbene il numero di richieste in una singola regione sia inferiore alla capacità di pubblicazione totale in quella regione, entrambi i sistemi hanno una latenza simile per gli utenti finali, perché gli utenti vengono sempre reindirizzati alla regione più vicina.
Quando il carico di una regione supera la capacità di pubblicazione per quella regione, la latenza dell'utente finale varia in modo significativo tra le soluzioni:
Le soluzioni di bilanciamento del carico a livello di regione vengono sovraccaricate quando il traffico aumenta oltre la capacità, perché il traffico può fluire solo verso le istanze VM di backend sovraccariche. Sono inclusi i bilanciatori del carico on-premise tradizionali, i bilanciatori del carico di rete passthrough esterni su Google Cloude i bilanciatori del carico delle applicazioni esterni in una configurazione a singola regione (ad esempio, utilizzando il networking di livello Standard). Le latenze medie e massime delle richieste aumentano di oltre un fattore di 10, il che comporta esperienze utente scadenti che potrebbero a loro volta portare a un calo significativo degli utenti.
I bilanciatori del carico delle applicazioni esterni globali con backend in più regioni consentono al traffico di riversarsi nella regione più vicina con capacità di gestione disponibile. Ciò comporta un aumento misurabile ma relativamente basso della latenza dell'utente finale e offre un'esperienza utente molto migliore. Se la tua applicazione non è in grado di fare lo scale out in una regione abbastanza rapidamente, il bilanciatore del carico delle applicazioni esterno globale è l'opzione consigliata. Anche in caso di errore dell'intera regione dei server delle applicazioni utente, il traffico viene reindirizzato rapidamente ad altre regioni, contribuendo a evitare un'interruzione completa del servizio.
Esegui la pulizia
Elimina il progetto
Il modo più semplice per eliminare la fatturazione è eliminare il progetto creato per il tutorial.
Per eliminare il progetto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
Le pagine seguenti forniscono ulteriori informazioni e dettagli sulle opzioni di bilanciamento del carico di Google:
- Ottimizzazione della latenza delle applicazioni con Cloud Load Balancing
- Codelab Networking 101
- Bilanciatore del carico di rete passthrough esterno
- Bilanciatore del carico delle applicazioni esterno
- Bilanciatore del carico di rete proxy esterno