對預先訓練的處理器展開進階訓練
如果想提高預先訓練處理器的準確率,可以使用應付憑據剖析器進行進階訓練。您可以從預先建立的模型開始著手,然後使用您的資料進行訓練,然後新增自訂欄位。應付憑據格式非常多元,因此運用自己的應付憑據資料來對一般應付憑據剖析器進行進階訓練,不僅能提高特定格式的剖析準確率,而且還能讓剖析器擷取預先訓練模型不支援的其他欄位。系統會提供範例資料,但您可以按照相同的程序使用自己的資料。
如要直接在 Google Cloud 控制台按照逐步指南操作,請按一下「Guide me」(逐步引導):
事前準備
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 按一下 Google Cloud 控制台導覽選單中的「Document AI」,然後選取「Processor Gallery」(處理器庫)。
在「Processor Gallery」(處理器庫) 中
搜尋 「Invoice Parser」(應付憑據剖析器),然後選取「Create」(建立)。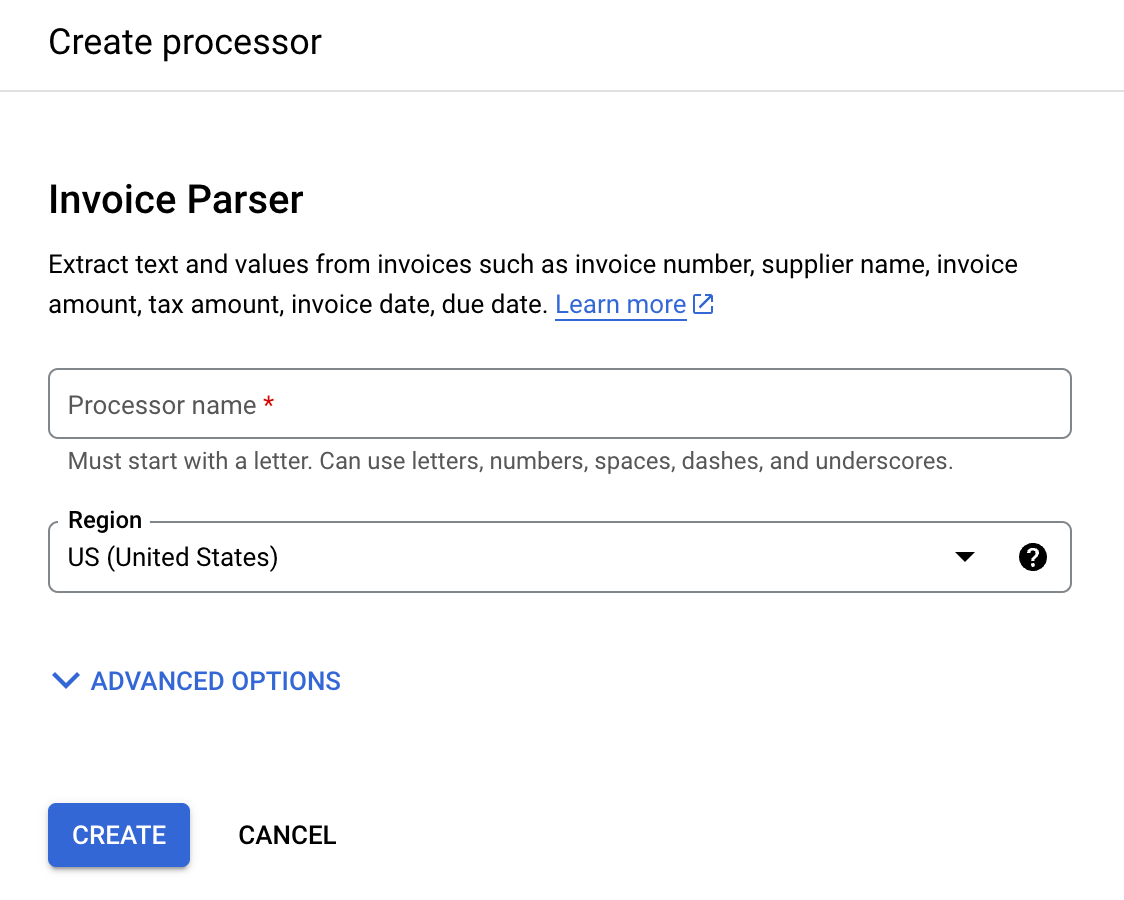
輸入處理器名稱,例如
invoice-parser-for-uptraining。請選取最接近您所在位置的區域。
選取 [Create] (建立)。系統會隨即顯示「Processor Details」(處理器詳細資料) 分頁。
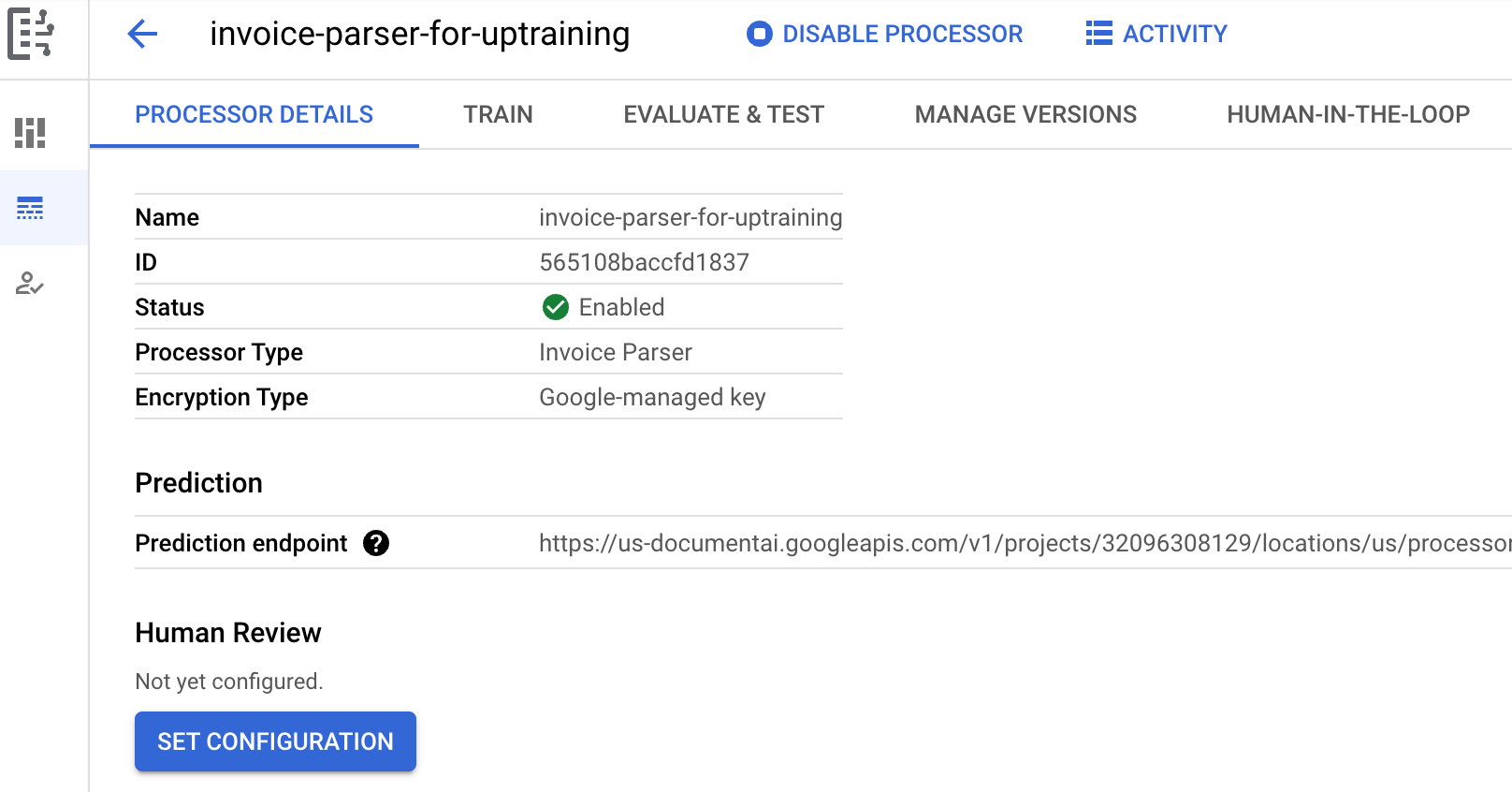
前往處理器的
「Train」(訓練) 分頁。選取
「Set dataset location」(設定資料集位置) 。 系統會提示您選取或建立空白的 Cloud Storage bucket 或資料夾。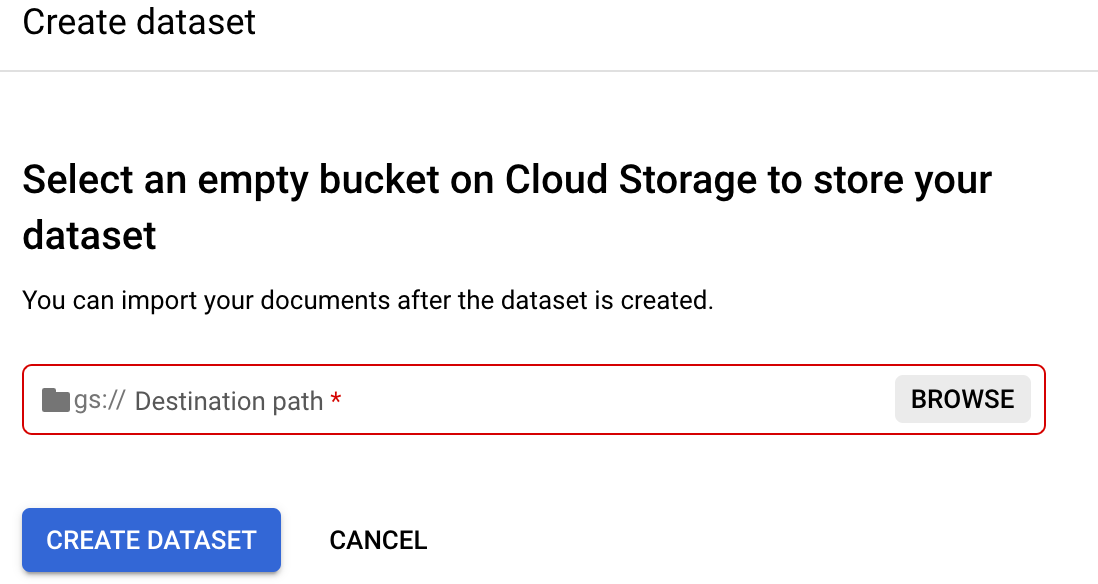
選取
「Browse」(瀏覽) ,開啟「Select folder」(選取資料夾)。選取
「Create a new bucket」(建立新 bucket) ,然後按照提示新建 bucket。如要進一步瞭解如何建立 Cloud Storage 值區,請參閱「Cloud Storage 值區」。注意:bucket 是頂層儲存空間實體,您可以在其中建立巢狀結構的資料夾。您也可以視需要在現有值區中建立及選取空白資料夾,而非建立及選取值區。請參閱「模擬資料夾」。
建立 bucket 後,畫面上會顯示該 bucket 的「Select folder」(選取資料夾) 頁面。
在值區的「Select folder」(選取資料夾) 頁面中,選取對話方塊底部的
「Select」(選取) 。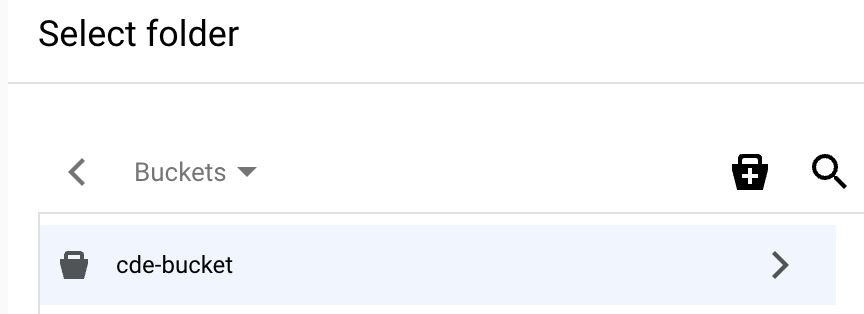
確定系統已在「destination path」(目的地路徑) 中填入您選取的值區名稱。選取
「Create dataset」(建立資料集) 。 資料集最多可能需要幾分鐘才能完成。
直接進行訓練:跳至匯入預先標記的資料。 請改用工具手動標記欄位,並將文件新增至訓練資料,而非匯入範例文件。
手動標記文件並新增至訓練集:繼續匯入範例文件以進行手動標籤,並完成相關操作說明,再進行訓練。
在「Train」(訓練) 分頁中,點選
「Import documents」(匯入文件) 。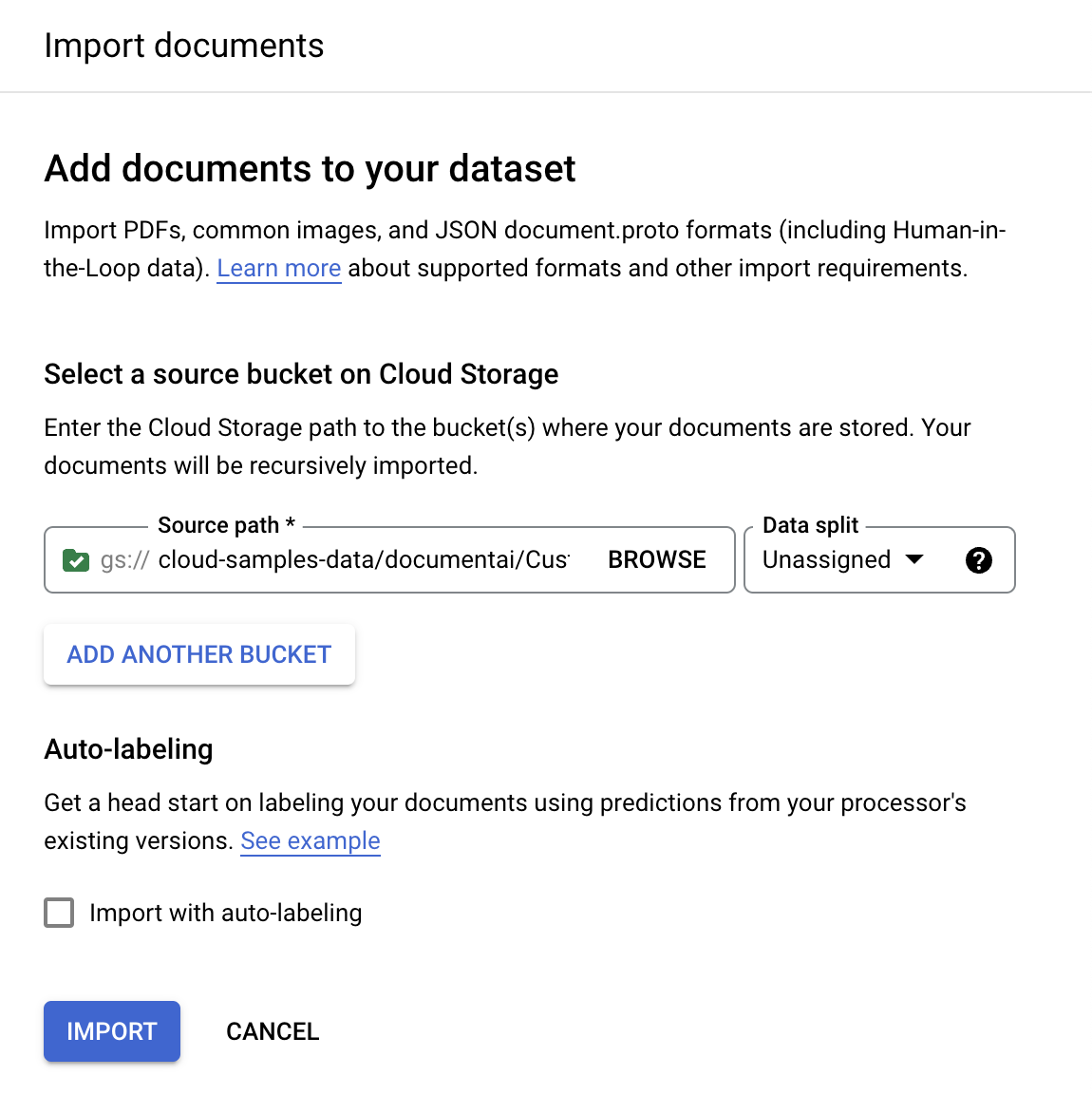
就這個範例而言,請在
「Source path」(來源路徑) 中輸入這個值區名稱,這樣就會直接連結至某份文件。cloud-samples-data/documentai/codelabs/uptraining/pdfs在「Data split」(資料分割)部分選取「Unassigned」(未指派) 。這個資料夾中的文件不會指派給測試集或訓練集。將「Import with auto-labeling」(使用自動加上標籤功能匯入) 保留為未勾選的狀態。
選取「Import」(匯入)。 Document AI 會將值區中的文件讀取到資料集,但不會修改匯入 bucket,也不會在匯入完成後從 bucket 讀取資料。
在「Train」(訓練) 分頁中,點選左下方的
「Edit Schema」(編輯結構定義) 。系統隨即會開啟「Manage labels」(管理標籤) 頁面。如要停用未使用的標籤,請找出未出現在下列清單中的欄位,然後勾選這些欄位對應的
核取方塊 ,接著點選「Disable」(停用)。下列欄位應維持啟用狀態:invoice_date line_item amount description receiver_address receiver_name supplier_address supplier_name total_amount注意:無法刪除標籤。您可以改為停用任何不需使用的標籤。
標籤完成後,請點選
「Save」(儲存) 。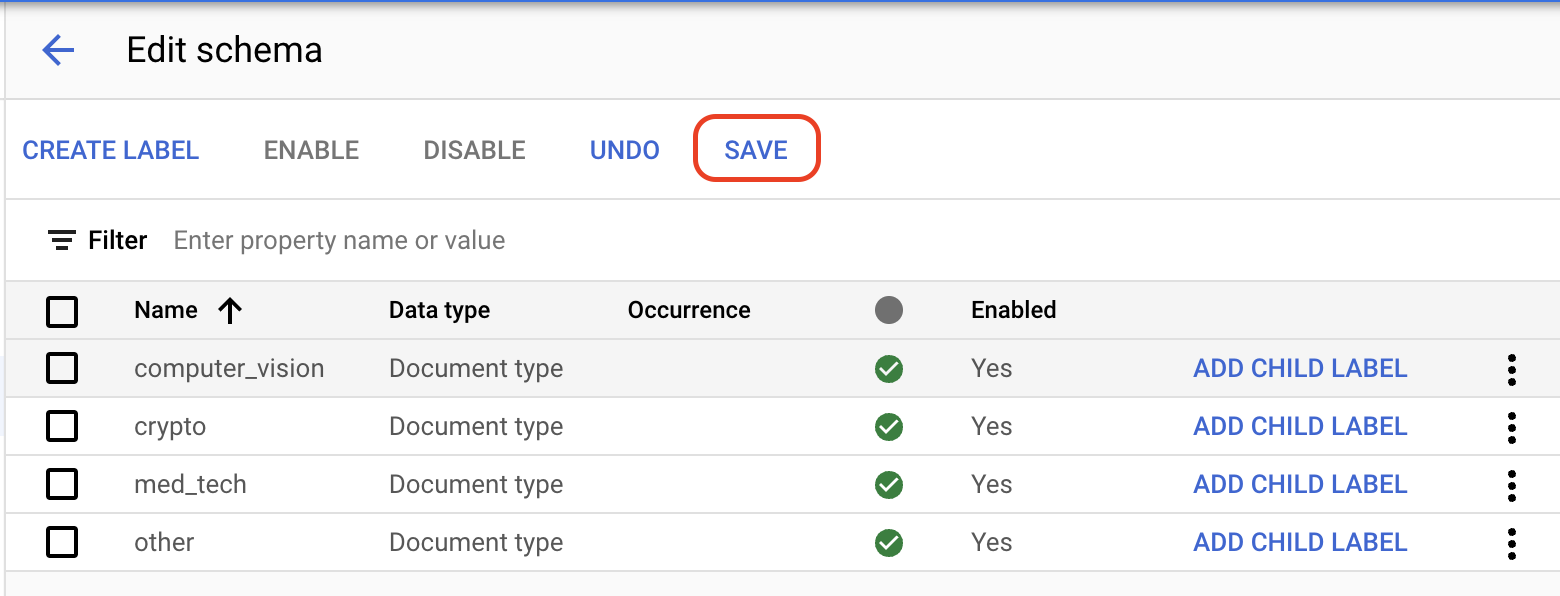
點選
返回箭頭 ,回到「Train」(訓練) 頁面。回到「Train」(訓練) 分頁,然後點選
某個文件 ,即可開啟「Label management」(標籤管理) 控制台。接下來,請根據您要加註的值,在左側面板中點選與該值相對應的結構定義標籤,然後套用標籤。
依預設使用
「Bounding box」(定界框) 工具,如有多行值,則使用「Select text」(選取文字) 工具,選取內容並套用標籤。比方說,在這份應付憑據中,應該為「麥克威廉國際管道公司」一詞指派
supplier_name標籤。您可以使用文字篩選器搜尋標籤名稱。注意:「Select text」(選取文字) 工具不適用於所有文字值,因此請視需要使用「Bounding box」(定界框)。您也可以使用「Bounding box」(定界框) 工具,選取非文字欄位 (例如核取方塊)。
檢查偵測到的文字值,以確保該值與文件中的正確文字相符。
選取與標籤對應的文字時,請務必只加入相關的文字。例如,如果是
invoice_id標籤,應避免加入通常位於數值前面的#等字元。也不要加入貨幣符號 (例如$)。- 請務必為實體的所有執行個體加上註解。舉例來說,
supplier_name或invoice_id可能會在文件中多次出現,但每個例項都必須加上註解。
- 請務必為實體的所有執行個體加上註解。舉例來說,
針對要加上標籤的每個欄位重複以上步驟。
完成文件註解後,請點選
「Mark as Labeled」(標示為已加上標籤) 。在「Train」(訓練) 分頁中,左側面板上會顯示有 1 份文件已加上標籤。
在「Train」(訓練) 分頁中,勾選
「Select All」(全選) 核取方塊。在
「Assign to Set」(指派給資料集) 清單中,選取「Training」(訓練)。點選
「Import documents」(匯入文件) 。在
「Source path」(來源路徑) 中輸入下列路徑。這個值區包含以 Document JSON 格式預先加上標籤的文件。cloud-samples-data/documentai/Custom/Invoices/JSON在「Data split」(資料分割) 清單中,選取「Auto-split」(自動分割)。這樣系統就會自動將文件分割為 80% 給訓練集和 20% 給測試集。取消勾選「Import with auto-labeling」(使用自動加上標籤功能匯入)。
選取「Import」(匯入)。 匯入作業可能需要幾分鐘才能完成。匯入完成後,請在「Train」(訓練) 分頁中找到文件。
在「Train」(訓練) 頁面上,按一下
「Import documents」(匯入文件) 。複製及貼上下列 Cloud Storage 路徑。這個目錄包含五個未加上標籤的應付憑據 PDF。在「Data split」(資料分割) 下拉式清單中選取「Training」(訓練)。
cloud-samples-data/documentai/Custom/Invoices/PDF_Unlabeled在「Auto-labeling」(自動加上標籤) 專區中,勾選
「Import with auto-labeling」(使用自動加上標籤功能匯入) 核取方塊。選取現有的處理器版本來為文件加上標籤。
- 例如:
pretrained-invoice-v1.3-2022-07-15
- 例如:
點選「Import」(匯入),然後等待系統匯入文件。您可以先離開這個頁面,稍後再返回查看。
- 完成後,文件就會顯示「Train」(訓練) 頁面的「Auto-labeled」(已自動加上標籤) 專區中。
如未將自動加上標籤的文件標示為已加上標籤,則無法將該文件用於訓練或測試。如要查看已自動加上標籤的文件,請前往
「Auto-labeled」(已自動加上標籤) 區段。選取第一份文件即可進入標籤控制台。
確認標籤正確無誤。如果不正確,請進行調整。
完成後,請選取
「Mark as Labeled」(標示為已加上標籤) 。為每個自動加上標籤的文件重複執行標籤驗證,然後再回到「Train」(訓練) 頁面使用資料進行訓練。
點選
「Uptrain New Version」(進階訓練新的版本) 。在
「Version name」(版本名稱) 欄位中輸入這個處理器版本的名稱,例如invoice-uptrain-1。(選用) 點選「View Label Stats」(查看標籤統計資料) 即可看到文件標籤的相關資訊。這有助於您確定涵蓋範圍。接著點選「Close」(關閉) ,返回訓練設定頁面。
點選
「Start training」(開始訓練) 您可以在右側面板中確認狀態。系統隨即會開啟「Dataset management」(資料集管理) 頁面。您可以在右側查看訓練狀態。視資料集大小而定,訓練作業可能需要數小時才會完成。您可以先離開這個頁面,稍後再返回查看。
訓練完成後,請前往
「Manage Versions」(管理版本) 分頁。您可以查看剛才訓練的版本詳細資料。找到您要部署的版本,點選右側的
三個垂直圓點 ,然後選取「Deploy version」(部署版本)。在彈出式視窗中選取
「Deploy」(部署) 。部署需要幾分鐘才會完成。
部署作業完成後,請前往
「Evaluate & Test」(評估與測試) 分頁。在這個頁面中,您可以查看整份文件和個別標籤的評估指標,包括 F1 分數、精確度和召回率。如要進一步瞭解評估和統計資料,請參閱「評估處理器」。
下載未加入先前訓練或測試的文件,以便用於評估處理器版本。如果您是使用自己的資料,則可使用專為這個用途保留下來的文件。
點選
「Upload Test Document」(上傳測試文件) ,然後選取剛才下載的文件。系統會開啟「Invoice Parser analytics」(應付憑據剖析器分析) 頁面。畫面輸出內容會顯示文件分類的精細程度。
您也可以針對其他測試集或處理器版本重新執行評估作業。
在 Google Cloud 控制台導覽選單中,依序選取「Document AI」和「My Processors」(我的處理器)。
找到要刪除的處理器,然後點選該列中的
「More actions」(更多動作) 。選取「Delete processor」(刪除處理器),輸入處理器名稱,然後再次選取「Delete」(刪除) 來確認操作。
建立處理器
為資料集建立 Cloud Storage 值區
如要訓練這個新處理器,您必須建立具有訓練和測試資料的資料集,以協助處理器識別您要擷取的實體。
這個資料集需要新的 Cloud Storage 值區。請勿使用目前儲存文件的 bucket。
匯入範例文件以進行手動標籤
接下來,請將應付憑據 PDF 檔案範例匯入資料集。您可以為這份文件中的欄位加上標籤,以利之後執行進階訓練程序。
在本指南中,我們會提供代表性檔案做為範例文件。
匯入文件時,可以選擇在匯入時就將文件指派至訓練集或測試集,也可以等到之後再指派。
如要刪除已匯入的文件,請在「Train」(訓練) 分頁中選取這些文件,然後點選「Delete」(刪除)。
如要進一步瞭解如何準備資料以進行匯入,請參閱資料準備指南。
定義處理器結構定義
您的資料集可能不含應付憑據剖析器支援的所有標籤。
若是如此,您必須先將未使用的標籤標示為 Inactive,才能展開訓練。此外,您也可以新增一或多個自訂標籤,再展開進階訓練。
為文件加上標籤
在文件中選取文字及套用標籤的程序稱為「註解」。
以下是含有對應文字的完整標籤範例。
| 標籤名稱 | Text |
|---|---|
supplier_name |
麥克威廉國際管道公司 |
supplier_address |
14368 Pipeline Ave Chino, CA 91710 |
invoice_id |
10001 |
due_date |
2020-01-02 |
line_item/description |
連接管 |
line_item/quantity |
9 |
line_item/unit_price |
74.43 |
line_item/amount |
669.87 |
line_item/description |
聚氯乙烯管 (12 英寸) |
line_item/quantity |
7 |
line_item/unit_price |
15.90 |
line_item/amount |
111.30 |
line_item/description |
銅管 |
line_item/quantity |
7 |
line_item/unit_price |
91.20 |
line_item/amount |
638.40 |
net_amount |
1,419.57 |
total_tax_amount |
113.57 |
total_amount |
1,533.14 |
currency |
$ |
將加註的文件指派給訓練集
為這份範例文件加上標籤後,現在已可將其指派給訓練集。
左側面板中會顯示有 1 份文件已指派給訓練集。
將預先加上標籤的資料匯入訓練集和測試集
如要使用 Document AI 進階訓練,訓練集和測試集中至少都必須要有 10 個文件,每個組合中的每個標籤至少都要有 10 個例項。
建議您每個組合至少加入 50 份文件,每個標籤包含 50 個例項,以獲得最佳成效。訓練資料越多,準確率通常就會越高。
在這份指南中,系統會提供預先加上標籤的資料。如果您是處理自有專案,則必須決定如何為資料加上標籤。詳情請參閱「標籤選項」。
選用:自動為新匯入的文件加上標籤
針對特定處理器匯入未加上標籤的文件時,如果該處理器是現有的已部署版本,您便可使用自動加上標籤功能節省標籤作業時間。
訓練處理器
匯入訓練和測試資料後,現在已可訓練處理器。由於訓練可能需要數小時,因此在開始訓練之前,請務必先確認您已使用適當的資料和標籤完成處理器設定。
部署處理器版本
評估及測試處理器
使用處理器
您已成功建立應付憑據剖析器處理器並完成進階訓練。
您可以管理自訂訓練的處理器版本 (例如淘汰舊處理器並遷移至新處理器),就像其他處理器版本一樣。詳情請參閱「管理處理器版本」。
您可以傳送處理要求至自訂處理器,然後比照其他實體擷取處理器以同樣的方式處理回應。
清除所用資源
如要避免系統向您的 Google Cloud 帳戶收取本頁所用資源的費用,請按照下列步驟操作。
如要避免產生不必要的 Google Cloud 費用,請透過 Google Cloud console刪除不需要的處理器和專案。
如果您特地為了學習 Document AI 而建立新專案,但已不再需要,請[刪除專案][delete-project]。
如果您使用現有的 Google Cloud 專案,請刪除稍早建立的資源,以免系統向您的帳戶收取費用。