The response to a processing request contains a Document
object that holds everything known about the processed document, including all
of the structured information that Document AI was able to extract.
This page explains the layout of the Document object by providing sample documents,
and then mapping aspects of OCR results to the specific elements of the Document object JSON.
It also provides client libraries
code samples and Document AI Toolbox SDK code samples.
These code samples use online processing, but the Document object parsing works
the same for batch processing.
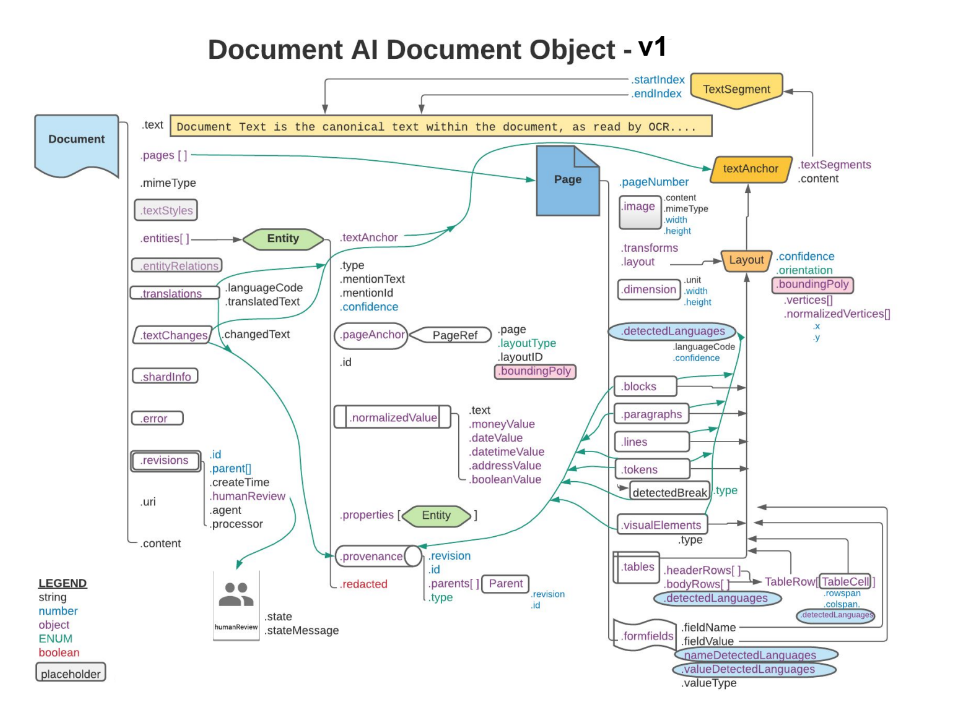
The orange and blue rectangles and arrows represent that at least one field of
the connected objects is .layout or detectedLanguage, respectively. The
diagram uses crow's foot
notation.
Use a JSON viewer or editing utility specifically designed to expand or collapse elements. Reviewing raw JSON in a plain text utility is inefficient.
Text, layout, and quality scores
Here's a sample text document:

Here's the full document object as returned by the Enterprise Document OCR processor:
This OCR output is also always included in Document AI processor output, since OCR is run by the processors. It uses the existing OCR data, which is why you can enter such JSON data using the inline document option into Document AI processors.
image=None, # all our samples pass this var
mime_type="application/json",
inline_document=document_response # pass OCR output to CDE input - undocumented
Here are some of the important fields:
Raw text
The text field contains the text that is recognized by Document AI.
This text doesn't contain any layout structure other than spaces, tabs, and
line feeds. This is the only field that stores a document's textual
information and serves as the source of truth of the document's text. Other
fields can refer to parts of the text field by position (startIndex and endIndex).
{
text: "Sample Document\nHeading 1\nLorem ipsum dolor sit amet, ..."
}
Page size and languages
Each page in the document object corresponds to a
physical page from the sample document. The sample JSON output contains one
page because is a single PNG image.
{
"pages:" [
{
"pageNumber": 1,
"dimension": {
"width": 679.0,
"height": 460.0,
"unit": "pixels"
},
}
]
}
- The
pages[].detectedLanguages[]field contains the languages found on a given page, along with the confidence score.
{
"pages": [
{
"detectedLanguages": [
{
"confidence": 0.98009938,
"languageCode": "en"
},
{
"confidence": 0.01990064,
"languageCode": "und"
}
]
}
]
}
OCR data
Document AI OCR detects text with various granularity or organization in the page, such as the text blocks, paragraphs, tokens and symbols (symbol level is optional, if configured to output symbol level data). These are all members of the page object.
Every element has a corresponding layout that
describes its position and text. Non-text visual elements
(such as checkboxes) are also at the page level.
{
"pages": [
{
"paragraphs": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "16"
}
]
},
"confidence": 0.9939527,
"boundingPoly": {
"vertices": [ ... ],
"normalizedVertices": [ ... ]
},
"orientation": "PAGE_UP"
}
}
]
}
]
}
The raw text is referred to in the textAnchor
object which is indexed into the main text string with startIndex and endIndex.
For
boundingPoly, the top-left corner of the page is the origin(0,0). Positive X values are to the right, and positive Y values are down.The
verticesobject uses the same coordinates as the original image, whereasnormalizedVerticesare in the range[0,1]. There is a transformation matrix that indicates the measures deskewing and other attributes of the normalization of the image.
- To draw the
boundingPoly, draw line segments from one vertex to the next. Then, close the polygon by drawing a line segment from the last vertex back to the first. The orientation element of the layout indicates whether the text has been rotated relative to the page.
To help you visualize the document's structure, the following images draw bounding
polygons for page.paragraphs,
page.lines, page.tokens.
Paragraphs

Lines

Tokens

Blocks

The Enterprise Document OCR processor can perform quality assessment of a document based on its readability.
- You must set the field
processOptions.ocrConfig.enableImageQualityScorestotrueto get this data in the API response.
This quality assessment is a quality score in [0, 1], where 1 means perfect quality.
The quality score is returned in the Page.imageQualityScores field.
All detected defects are listed as quality/defect_* and sorted in descending
order by confidence value.
Here's a PDF that is too dark and blurry to comfortably read:
Here's the document quality information as returned by the Enterprise Document OCR processor:
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Code samples
The following code samples demonstrate how to send a processing request and then read and print the fields to the terminal:
Java
For more information, see the Document AI Java API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
For more information, see the Document AI Node.js API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Python
For more information, see the Document AI Python API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Forms and tables
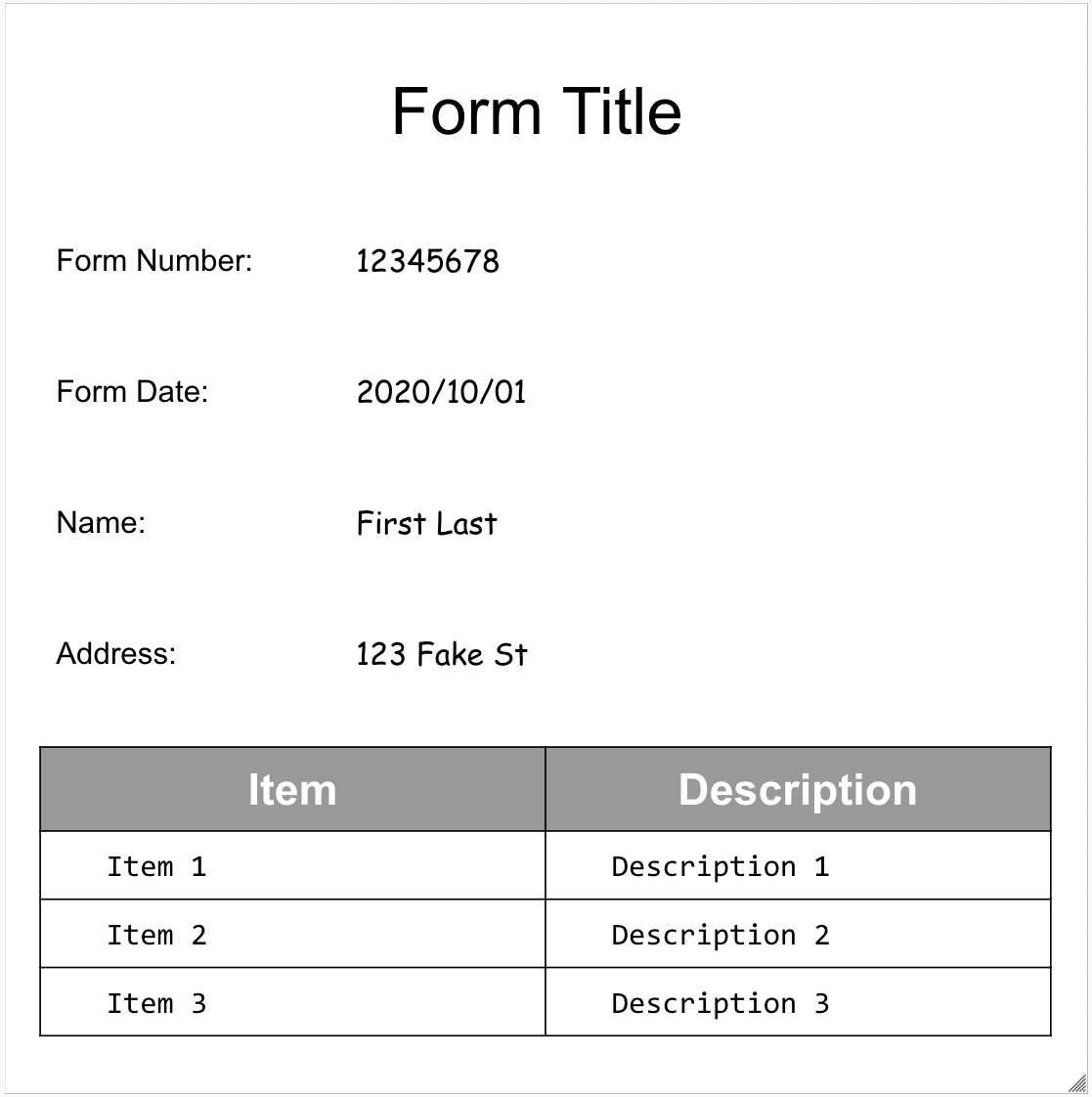
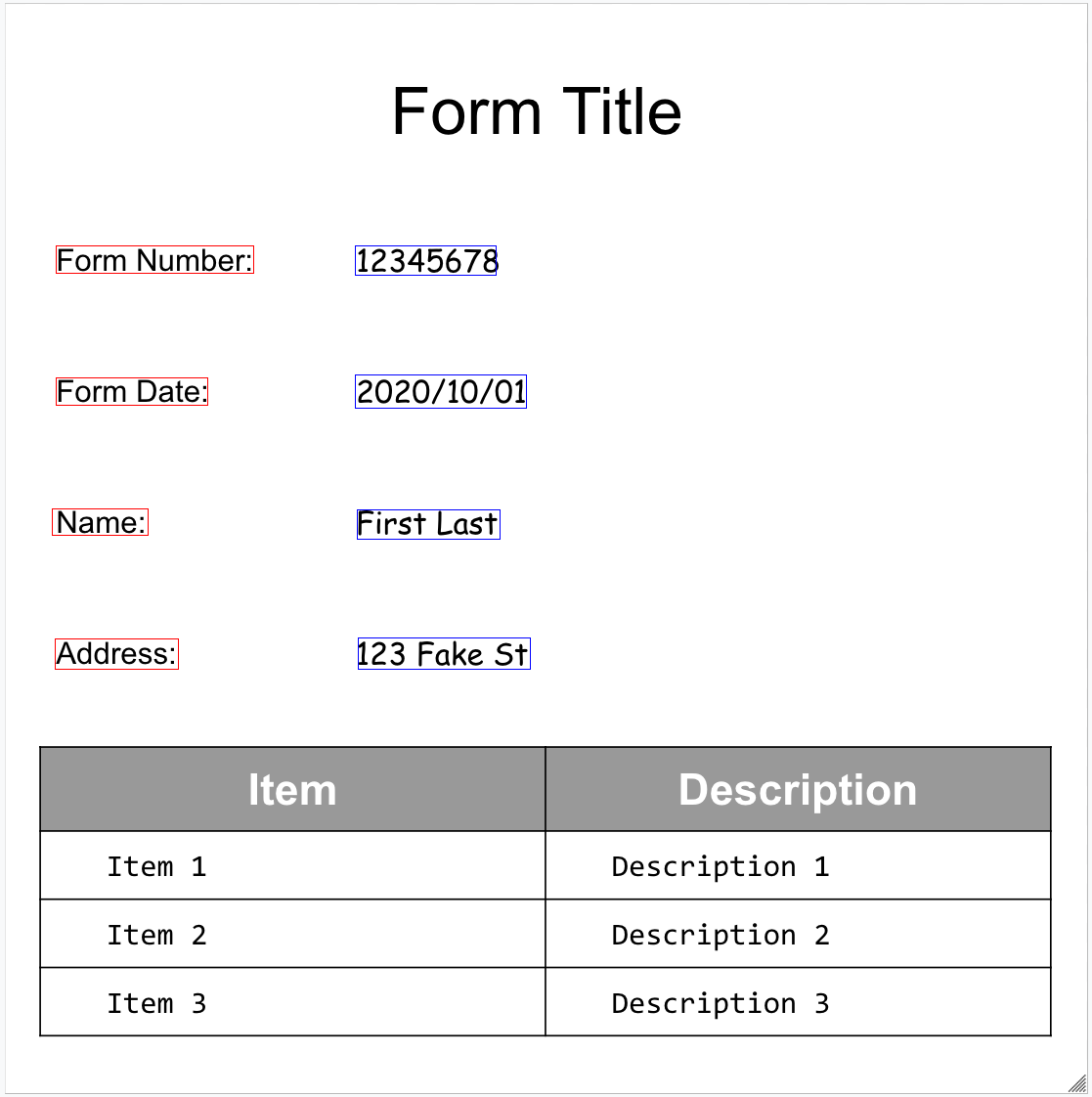
Here's our sample form:
Here's the full document object as returned by the Form Parser:
Here are some of the important fields:
The Form Parser is able to detect FormFields
in the page. Each form field has a name and value. These are also called
key-value pairs (KVP). Note that KVP are different from (schema) entities in
other extractors:
Entity names are configured. The keys in KVPs are literally what the key text is on the document.
{
"pages:" [
{
"formFields": [
{
"fieldName": { ... },
"fieldValue": { ... }
}
]
}
]
}
- Document AI can also detect
Tablesin the page.
{
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
The table extraction within Form Parser only recognizes conventional tables,
those without cells that span rows or columns. So rowSpan and colSpan are always 1.
Starting with processor version
pretrained-form-parser-v2.0-2022-11-10, Form Parser can also recognize generic entities. For more information, see Form Parser.To help you visualize the document's structure, the following images draw bounding polygons for
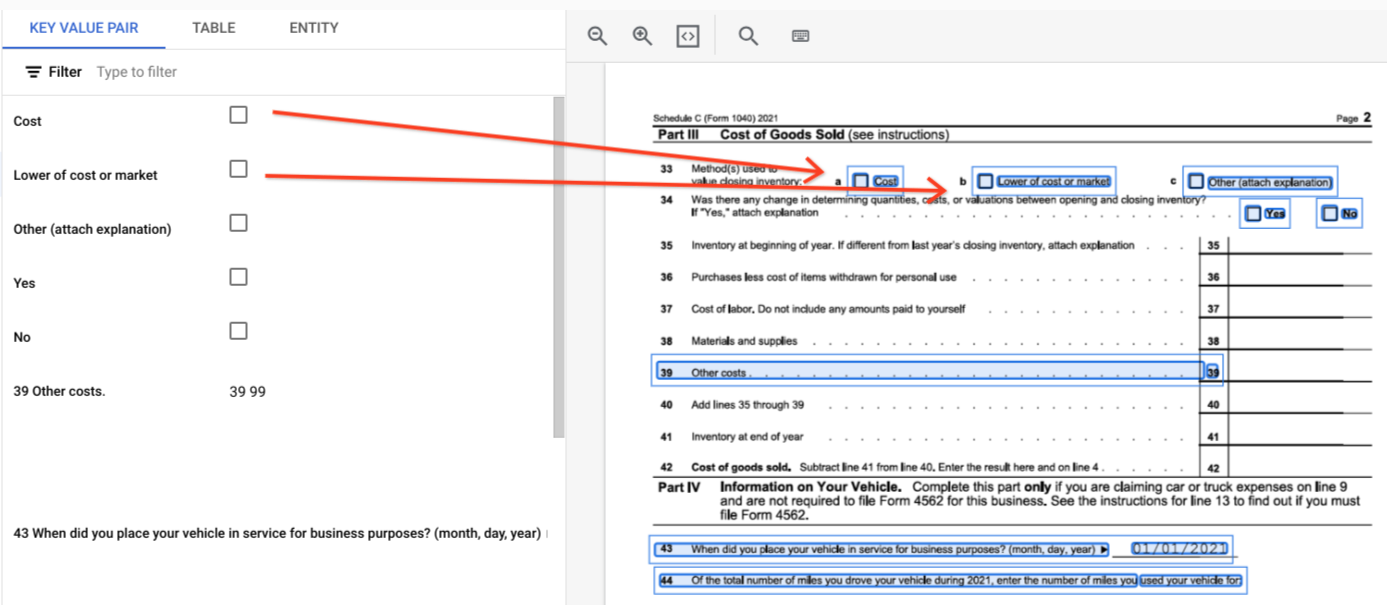
page.formFieldsandpage.tables.Checkboxes in tables. Form Parser is able to digitize checkboxes from images and PDFs as KVPs. Providing an example of checkbox digitization as a key-value pair.
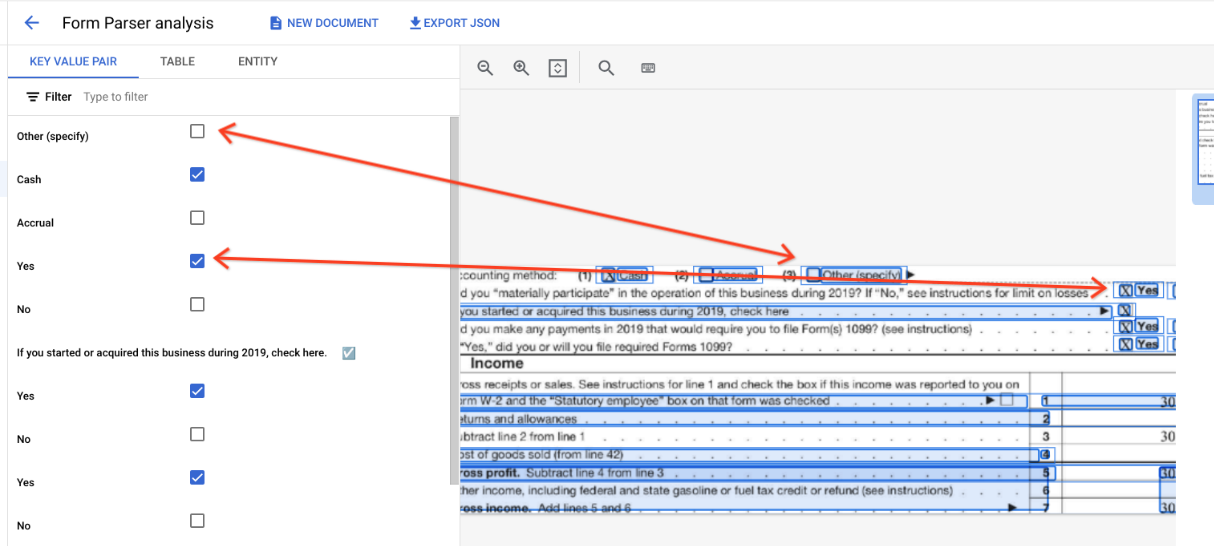
Outside of tables, checkboxes are represented as visual elements within Form Parser. Highlighting the square boxes having checkmarks over the UI and unicode ✓ in the JSON.
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
In tables, checkboxes appear as Unicode characters like ✓ (checked) or ☐ (unchecked).
The filled checkboxes have the value as filled_checkbox:
under pages > x > formFields > x > fieldValue > valueType.. The unchecked
checkboxes have the value as unfilled_checkbox.
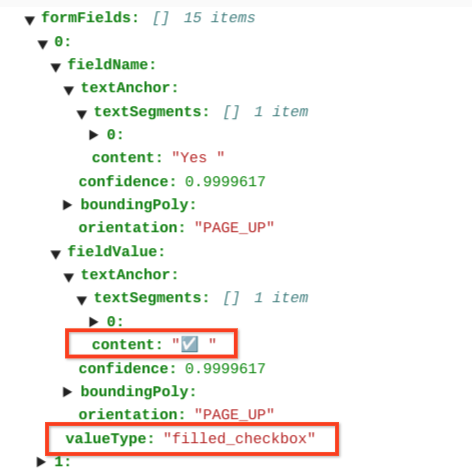
The content fields show the checkbox content value as highlighted ✓ at
path pages>formFields>x>fieldValue>textAnchor>content.
To help you visualize the document's structure, the following images draw bounding
polygons for page.formFields and page.tables.
Form Fields
Tables
Code samples
The following code samples demonstrate how to send a processing request and then read and print the fields to the terminal:
Java
For more information, see the Document AI Java API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
For more information, see the Document AI Node.js API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Python
For more information, see the Document AI Python API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Entities, nested entities, and normalized values
Many of the specialized processors extract structured data that is grounded to a
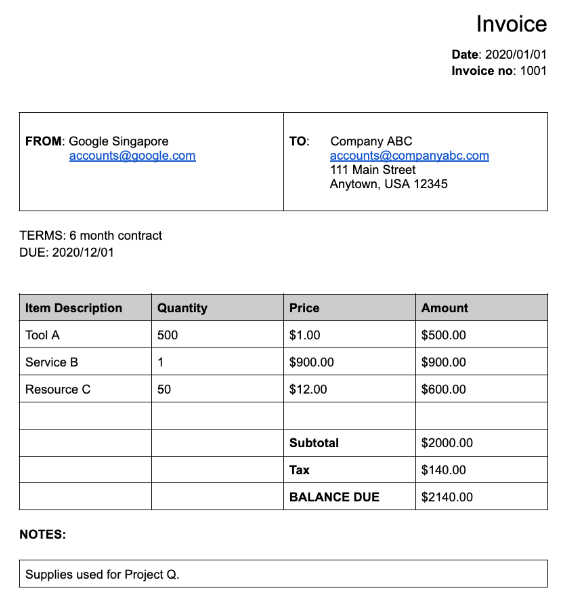
well-defined schema. For example, the Invoice parser
detects specific fields such as invoice_date and supplier_name. Here's a
sample invoice:
Here's the full document object as returned by the Invoice parser:
Here are some of the important parts of the document object:
Detected fields:
Entitiescontains the fields that the processor was able to detect, for example, theinvoice_date:{ "entities": [ { "textAnchor": { "textSegments": [ { "startIndex": "14", "endIndex": "24" } ], "content": "2020/01/01" }, "type": "invoice_date", "confidence": 0.9938466, "pageAnchor": { ... }, "id": "2", "normalizedValue": { "text": "2020-01-01", "dateValue": { "year": 2020, "month": 1, "day": 1 } } } ] }For certain fields, the processor also normalizes the value. In this example, the date has been normalized from
2020/01/01to2020-01-01.Normalization: For many specific supported fields, the processor also normalizes the value and also returns an
entity. ThenormalizedValuefield is added to the raw extracted field obtained through thetextAnchorof each entity. So it normalizes the literal text, often breaking up the text value into subfields. For example, a date like September 1st, 2024 would be represented as:
normalizedValue": {
"text": "2020-09-01",
"dateValue": {
"year": 2024,
"month": 9,
"day": 1
}
In this example, the date has been normalized from 2020/01/01 to 2020-01-01, a standardized format to reduce postprocessing and enable conversion to the chosen format.
Addresses are also often normalized, which breaks down the elements of the address
into individual fields. Numbers are normalized by having an integer or floating
point number as the normalizedValue.
- Enrichment: Certain processors and fields also support enrichment.
For example, the original
supplier_namein the documentGoogle Singaporehas been normalized against the Enterprise Knowledge Graph toGoogle Asia Pacific, Singapore. Also notice that because the Enterprise Knowledge Graph contains information about Google, Document AI infers thesupplier_addresseven though it wasn't present in the sample document.
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "supplier_name",
"confidence": 0.39170802,
"pageAnchor": { ... },
"id": "12",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
},
{
"type": "supplier_address",
"id": "17",
"normalizedValue": {
"text": "70 Pasir Panjang Rd #03-71 Mapletree Business City II Singapore 117371",
"addressValue": {
"regionCode": "SG",
"languageCode": "en-US",
"postalCode": "117371",
"addressLines": [
"70 Pasir Panjang Rd",
"#03-71 Mapletree Business City II"
]
}
}
}
]
}
Nested fields: Nested schema (fields) can be created by first declaring an entity as a parent, then creating child entities under the parent. The parsing response for the parent includes the child fields in the
propertieselement of the parent field. In the following example,line_itemis a parent field that has two child fields:line_item/descriptionandline_item/quantity.{ "entities": [ { "textAnchor": { ... }, "type": "line_item", "confidence": 1.0, "pageAnchor": { ... }, "id": "19", "properties": [ { "textAnchor": { "textSegments": [ ... ], "content": "Tool A" }, "type": "line_item/description", "confidence": 0.3461604, "pageAnchor": { ... }, "id": "20" }, { "textAnchor": { "textSegments": [ ... ], "content": "500" }, "type": "line_item/quantity", "confidence": 0.8077843, "pageAnchor": { ... }, "id": "21", "normalizedValue": { "text": "500" } } ] } ] }
The following parsers do follow it:
- Extract (Custom Extractor)
- Legacy
- Bank statement parser
- Expense parser
- Invoice Parser
- PaySlip parser
- W2 Parser
Code samples
The following code samples demonstrate how to send a processing request and then read and print the fields from a specialized processor to the terminal:
Java
For more information, see the Document AI Java API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
For more information, see the Document AI Node.js API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Python
For more information, see the Document AI Python API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Custom Document Extractor
The Custom Document Extractor processor can extract custom entities from documents which don't have a pretrained processor available. This can be accomplished through training a custom model or by using Generative AI Foundation Models to extract named entities without any training. For more information, refer to Create a Custom Document Extractor in the console.
- If you train a custom model, the processor can be used in exactly the same way as a pretrained entity extraction processor.
- If you use a foundation model, you can create a processor version to extract specific entities for every request, or you can configure it on a per-request basis.
For information about the output structure, refer to Entities, nested entities, and normalized values.
Code samples
If you are using a custom model or created a processor version using a foundation model, then use the entity extraction code samples.
The following code sample demonstrates how to configure specific entities for a foundation model Custom Document Extractor on a per-request basis and print the extracted entities:
Python
For more information, see the Document AI Python API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Summarization
The Summarizer processor uses Generative AI Foundation Models to summarize the extracted text from a document. The length and format of the response can be customized in the following ways:
- Length
BRIEF: A brief summary of one or two sentencesMODERATE: A paragraph-length summaryCOMPREHENSIVE: The longest option available
- Format
You can either create a processor version for a specific length and format, or you can configure it on a per-request basis.
The summarized text appears in Document.entities.normalizedValue.text. You can find a full sample output JSON file in Sample processor output.
For more information, refer to Build a document summarizer in the console.
Code samples
The following code sample demonstrates how to configure a specific length and format in a processing request and print the summarized text:
Python
For more information, see the Document AI Python API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Splitting and classification
Here's a composite 10-page PDF that contains different types of documents and forms:
Here's the full document object as returned by the lending document splitter and classifier:
Each document that is detected by the splitter is represented by an
entity. For example:
{
"entities": [
{
"textAnchor": {
"textSegments": [
{
"startIndex": "13936",
"endIndex": "21108"
}
]
},
"type": "1040se_2020",
"confidence": 0.76257163,
"pageAnchor": {
"pageRefs": [
{
"page": "6"
},
{
"page": "7"
}
]
}
}
]
}
Entity.pageAnchorindicates that this document is 2 pages long. Note thatpageRefs[].pageis zero-based and is the index into thedocument.pages[]field.Entity.typespecifies that this document is a 1040 Schedule SE form. For a full list of document types that can be identified, see Document types identified in the processor documentation.
For more information, see Document splitters behavior.
Code samples
Splitters identify page boundaries, but don't actually split the input document for you. You can use Document AI Toolbox to physically split a PDF file by using the page boundaries. The following code samples print the page ranges without splitting the PDF:
Java
For more information, see the Document AI Java API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
For more information, see the Document AI Node.js API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Python
For more information, see the Document AI Python API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Document.
Python
For more information, see the Document AI Python API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Document AI Toolbox
Document AI Toolbox is an SDK for Python that provides utility
functions for managing, manipulating, and extracting information from the document response.
It creates a "wrapped" document object from a processed document response from JSON files in
Cloud Storage, local JSON files, or output directly from the process_document()
method.
It can perform the following actions:
- Combine fragmented
DocumentJSON files from Batch Processing into a single "wrapped" document. - Export shards as a unified
Document. -
Get
Documentoutput from: - Access text from
Pages,Lines,Paragraphs,FormFields, andTableswithout handlingLayoutinformation. - Search for a
Pagescontaining a target string or matching a regular expression. - Search for
FormFieldsby name. - Search for
Entitiesby type. - Convert
Tablesto a Pandas Dataframe or CSV. - Insert
EntitiesandFormFieldsinto a BigQuery table. - Split a PDF file based on output from a Splitter/Classifier processor.
- Extract image
EntitiesfromDocumentbounding boxes. -
Convert
Documentsto and from commonly used formats:- Cloud Vision API
AnnotateFileResponse - hOCR
- Third-party document processing formats
- Cloud Vision API
- Create batches of documents for processing from a Cloud Storage folder.
Code Samples
The following code samples demonstrate how to use Document AI Toolbox.