Document AI vous permet d'entraîner de nouvelles versions de processeur à l'aide de vos propres données d'entraînement et d'évaluer la qualité de votre version de processeur par rapport à vos propres données de test.
Cela est utile lorsque vous souhaitez utiliser un processeur personnalisé. Il existe un processeur Document AI pour votre type de document, mais vous pouvez en surentraîner une version personnalisée pour répondre à vos besoins.
L'entraînement et l'évaluation sont généralement effectués en parallèle pour obtenir une version de processeur utilisable et de haute qualité.
Document AI
Document AI vous permet de créer votre propre extracteur personnalisé, qui extrait des entités à partir de documents d'un type particulier (par exemple, les éléments d'un menu ou le nom et les coordonnées d'un candidat à partir d'un CV).
Contrairement aux autres processeurs, les processeurs personnalisés ne sont fournis avec aucune version de processeur préentraînée. Ils ne peuvent donc traiter aucun document tant que vous n'avez pas entraîné une version à partir de zéro.
Pour commencer à utiliser Document AI, consultez Créer votre propre processeur personnalisé.
Surentraîner un processeur
Vous pouvez mettre à jour les nouvelles versions de processeurs pour améliorer la précision de vos données, extraire des champs personnalisés supplémentaires de vos documents et ajouter la prise en charge de nouvelles langues.
L'entraînement ascendant fonctionne en appliquant le transfert d'apprentissage sur les versions de processeurs pré-entraînés de Google et nécessite généralement moins de données que l'entraînement à partir de zéro.
Pour commencer, consultez Entraîner un processeur préentraîné.
Processeurs compatibles
Tous les processeurs spécialisés ne sont pas compatibles avec l'entraînement de la mise à l'échelle. Voici les processeurs qui prennent en charge l'entraînement de la mise à l'échelle.
Remarques et recommandations concernant les données
La qualité et la quantité de vos données déterminent la qualité de l'entraînement, de l'entraînement supplémentaire et de l'évaluation.
L'obtention d'un ensemble de documents représentatifs et réels, ainsi que la fourniture d'un nombre suffisant de libellés de haute qualité sont souvent les étapes les plus longues et les plus gourmandes en ressources du processus.
Nombre de documents
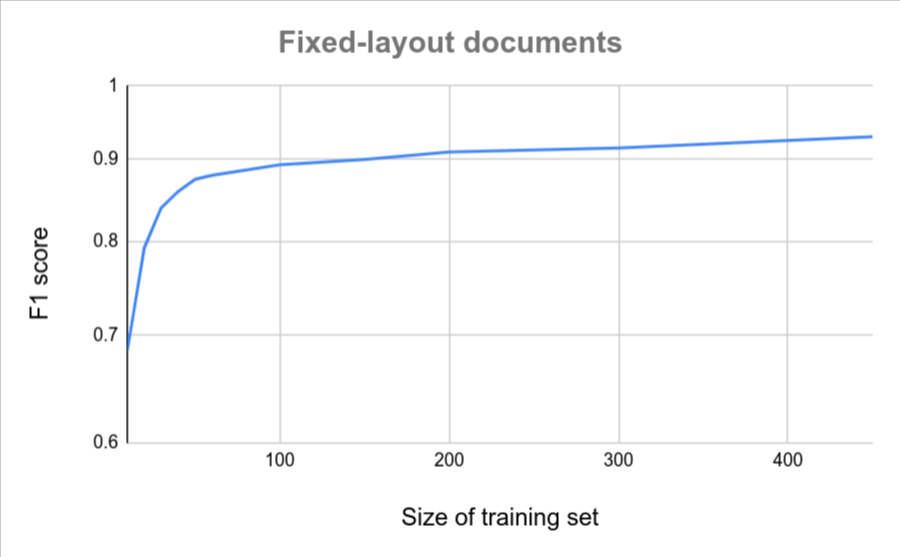
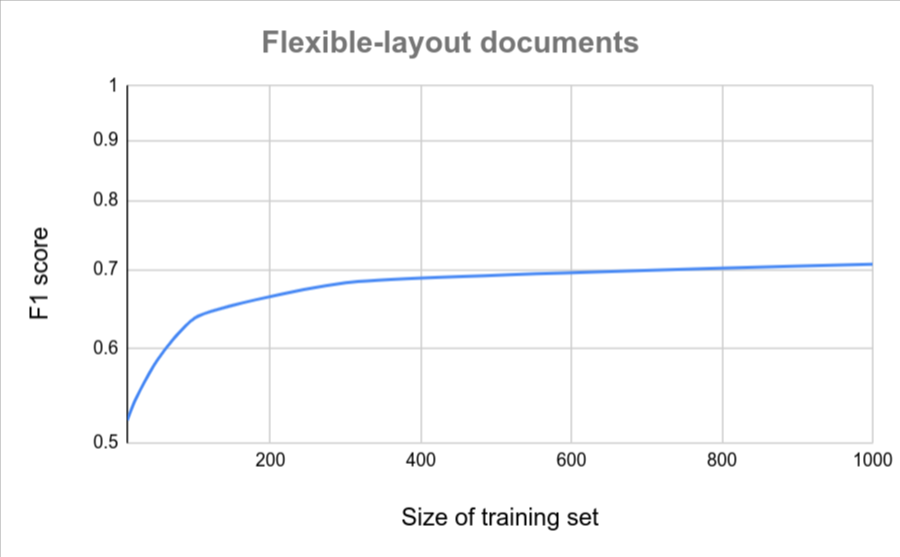
Si vos documents ont tous un format similaire (par exemple, un formulaire fixe avec très peu de variations), vous aurez besoin de moins de documents pour obtenir un résultat précis. Plus la variation est élevée, plus vous devez fournir de documents.
Les graphiques suivants fournissent une estimation approximative du nombre de documents requis pour qu'un extracteur de documents personnalisés atteigne un score de qualité donné.
| Faible variation | Forte variation |
|---|---|
 |
 |
Étiquetage des données
Examinez vos options pour étiqueter les documents et assurez-vous de disposer de suffisamment de ressources pour annoter les documents de votre ensemble de données.
Entraîner des modèles
Les processeurs d'extraction personnalisés peuvent utiliser différents types de modèles en fonction du cas d'utilisation spécifique et des données d'entraînement disponibles.
- Modèle personnalisé : modèle utilisant des données d'entraînement étiquetées.
- Basés sur un modèle : documents avec une mise en page fixe.
- Basés sur un modèle : documents avec une mise en page variable.
- Modèle d'IA générative : basé sur des modèles de fondation pré-entraînés qui nécessitent un entraînement supplémentaire minimal.
Le tableau suivant illustre les cas d'utilisation correspondant à chaque type de modèle.
| Modèle personnalisé | IA générative | ||
|---|---|---|---|
| Basé sur un modèle | Basé sur le modèle | ||
| Variation de la mise en page | Aucun | Faible à moyen | Élevée |
| Quantité de texte libre (par exemple, les paragraphes d'un contrat) | Faible | Faibles | Élevée |
| Quantité de données d'entraînement requise | Faible | Élevée | Faible |
| Précision avec des données d'entraînement limitées | Supérieure | Inférieur | Supérieure |
Découvrez comment affiner un processeur avec des descriptions de propriétés.
Quand utiliser un autre processeur
Voici quelques cas où vous pourriez envisager d'autres options que Document AI Workbench ou adapter votre workflow.
- Certains formats d'entrée basés sur du texte (.txt, .html, .docx, .md, etc.) ne sont pas compatibles avec Document AI Workbench. Envisagez d'autres offres de traitement du langage prédéfinies ou personnalisées dans Google Cloud, comme l'API Cloud Natural Language.
- Le schéma de l'extracteur de documents personnalisés accepte jusqu'à 150 libellés d'entités. Si votre logique métier nécessite plus de 150 entités dans la définition du schéma, envisagez d'entraîner plusieurs processeurs, chacun ciblant un sous-ensemble d'entités.
Entraîner un processeur
En partant du principe que vous avez déjà créé un processeur compatible avec l'entraînement ou le surentraînement et étiqueté votre ensemble de données, vous pouvez entraîner une nouvelle version du processeur à partir de zéro. Vous pouvez également surentraîner une nouvelle version du processeur à partir d'une version existante.
Entraîner la version du processeur
UI Web
Dans la console Google Cloud , accédez à l'onglet Entraînement de votre outil de traitement.
Cliquez sur Modifier le schéma pour ouvrir la page Gérer les libellés. Vérifiez les libellés du processeur.
Les libellés activés au moment de l'entraînement déterminent les entités extraites par la nouvelle version de votre processeur. Si un libellé est inactif dans le schéma, la version du processeur ne l'extrait pas, même si les documents sont libellés.
Dans l'onglet Entraînement, cliquez sur Afficher les statistiques des libellés et vérifiez votre ensemble de test et d'entraînement. Les documents étiquetés automatiquement, sans étiquette ou non attribués sont exclus de l'entraînement et de l'évaluation.
Cliquez sur Entraîner une nouvelle version.
Le nom de la version définit le champ
namedeprocessorVersion.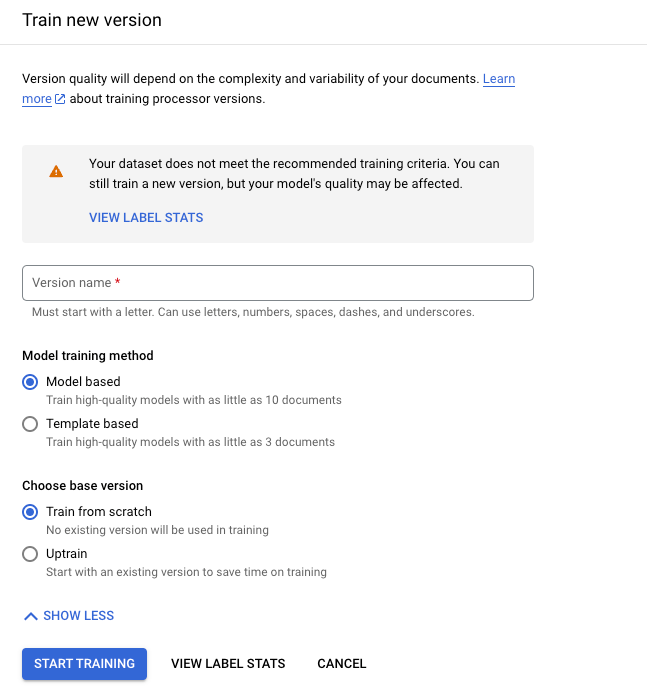
Cliquez sur Démarrer l'entraînement et attendez que votre nouvelle version de processeur soit entraînée et évaluée.
Vous pouvez surveiller la progression de l'entraînement dans l'onglet Gérer les versions :
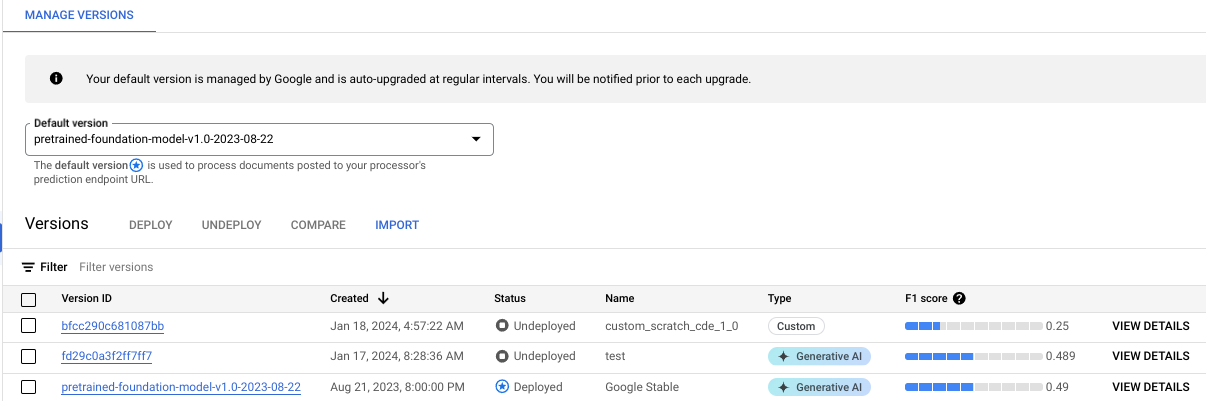
Cliquez sur l'onglet Évaluer et tester pour voir les performances de votre nouvelle version du processeur sur l'ensemble de données de test. Pour en savoir plus, consultez Évaluer la version de l'outil de traitement.
Python
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Python.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Déployer et utiliser la version de l'outil de traitement
Vous pouvez déployer et gérer les versions de votre outil de traitement comme n'importe quelle autre version. Pour en savoir plus, consultez Gérer les versions de l'outil de traitement.
Une fois le déploiement effectué, vous pouvez envoyer une requête de traitement à votre outil de traitement personnalisé.
Désactiver ou supprimer un processeur
Si vous ne souhaitez plus utiliser un processeur, vous pouvez le désactiver ou le supprimer. Si vous désactivez un processeur, vous pouvez le réactiver. Si vous supprimez un processeur, vous ne pourrez pas le récupérer.
Dans le panneau Document AI à gauche, cliquez sur Mes processeurs.
Cliquez sur les points verticaux à droite du nom du processeur. Cliquez sur Désactiver le processeur ou Supprimer le processeur.
Pour en savoir plus, consultez Gérer les versions de l'outil de traitement.
Chiffrement des données d'entraînement
Les données d'entraînement Document AI sont enregistrées dans Cloud Storage et peuvent être chiffrées avec des clés de chiffrement gérées par le client si nécessaire.
Suppression des données d'entraînement
Une fois une tâche d'entraînement Document AI terminée, toutes les données d'entraînement enregistrées dans Cloud Storage expirent après une période de conservation de deux jours. Les activités de suppression de données ultérieures respectent le processus décrit dans Suppression des données sur Google Cloud.
Tarifs
L'entraînement et l'entraînement avancé ne sont pas payants. Vous payez l'hébergement et la prédiction. Pour en savoir plus, consultez Tarifs de Document AI.