이 문서는 Document AI 사용에 대한 기본 개념을 설명하는 가이드입니다. 다른 문서 또는 빠른 시작으로 이동하기 전에 이 페이지를 읽어야 합니다.
문서 처리 워크플로 자동화
전 세계 기업은 정보를 저장하고 전달하기 위해 문서에 크게 의존합니다. 이 정보는 유용하게 사용하려면 디지털화해야 하는 경우가 많습니다. 하지만 이는 일반적으로 시간이 많이 소요되는 수동 프로세스를 통해 이루어집니다.
예를 들면 다음과 같습니다.
- e-Reader용 도서 디지털화
- 의사 사무실에서 의료 접수 양식을 처리합니다.
- 영수증 및 인보이스를 파싱하여 경비 보고서의 유효성을 검사합니다.
- ID 카드를 기반으로 신원을 인증합니다.
- 대출 승인을 위해 세금 양식에서 소득 정보를 추출합니다.
- 주요 비즈니스 계약 조건에 대한 계약을 이해합니다.
이러한 각 워크플로에는 문서에서 원시 텍스트를 가져온 다음 필요한 데이터 (필드 또는 항목)에 해당하는 특정 텍스트를 추출하는 작업이 포함됩니다. 하지만 각 문서 유형의 구조와 레이아웃은 다르며 필드 패턴은 특정 사용 사례에 따라 다릅니다.
Document AI 구성요소
Document AI는 문서에서 비정형 데이터를 가져와서 데이터베이스에 적합한 특정 필드와 같은 정형 데이터로 변환하는 문서 처리 및 이해 플랫폼으로, 데이터의 이해, 분석, 사용을 쉽게 만들어 줍니다.
Document AI는 전문적인 머신러닝 지식 없이 확장 가능한 엔드 투 엔드 클라우드 기반 문서 처리 애플리케이션을 만드는 데 도움이 되도록 생성형 AI를 사용하여 Vertex AI 내의 제품 위에 구축됩니다.
Document AI를 사용하면 다음 작업을 할 수 있습니다.
- OCR을 사용하여 문서를 디지털화하여 텍스트, 레이아웃, 다양한 부가기능(예: 이미지 품질 감지(가독성용), 기울기 보정(완전 자동))을 가져옵니다.
- 문서 파일에서 텍스트 및 레이아웃 정보를 추출하고 항목을 정규화합니다.
- 구조화된 양식과 일반 테이블에서 키-값 쌍 (kvp)을 식별합니다. 예를 들어
Name: Jill Smith은 KVP입니다. - 문서 유형을 분류하여 추출 및 저장과 같은 다운스트림 프로세스를 실행합니다.
- 문서를 유형별로 분할하고 분류합니다. 예를 들어 실제 문서가 여러 개 있는 PDF 파일이 있습니다.
- 자동 라벨링, 스키마 관리, 문서 및 예측 검토와 같은 데이터 세트 관리 기능을 사용하여 미세 조정 및 모델 평가에 사용할 데이터 세트를 준비합니다.
- Cloud Storage, BigQuery, Vertex AI Search와 같은 제품과 통합하여 문서와 메타데이터를 저장, 검색, 정리, 관리, 분석할 수 있습니다.
이 다이어그램은 Document AI에서 지원하는 모든 주요 문서 처리 단계와 각 단계가 서로 연결되는 방식을 보여줍니다.
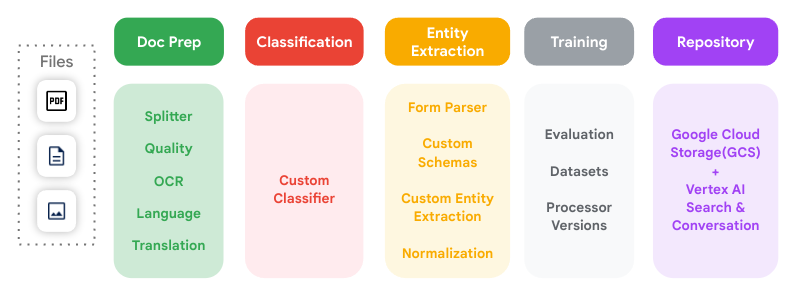
프로세서
Document AI 프로세서는 문서 파일과 문서 처리 및 이해 작업을 실행하는 머신러닝 모델 사이에 있습니다. 문서를 분류, 분할, 파싱 또는 분석하는 데 사용할 수 있습니다.
각 Google Cloud 프로젝트는 자체 프로세서 인스턴스를 만들어야 합니다.
프로세서는 다음 카테고리 중 하나에 속합니다.
- 디지털화: OCR
- 추출: 맞춤 추출기, 양식 파서, 레이아웃 파서, 사전 학습된 파서
- 분류: 맞춤 분류기 및 맞춤 분할기
Document AI에 사용할 수 있는 모든 프로세서 유형에 관한 정보는 전체 프로세서 및 세부정보 목록을 참고하세요.
어떤 프로세서를 사용해야 하나요?
특정 애플리케이션에 사용할 프로세서 유형을 결정하려면 다음 일반 가이드라인을 참고하세요.
| 카테고리 | 사용 사례 | 프로세서 유형 |
|---|---|---|
| 디지털화 | 문서에서 텍스트 및 레이아웃 정보를 추출합니다. | Enterprise Document OCR |
| 문서의 스캔된 이미지 품질 (가독성)을 분석합니다. | 이미지 품질 분석 이 사용 설정된 Enterprise Document OCR | |
| 맞춤 프로세서 기준을 충족하지 않는 맞춤 문서에서 항목을 추출합니다. | ||
| 추출 | 문서의 구조화된 양식에서 표 또는 kvp를 추출합니다. | 양식 파서 |
| 문서에서 텍스트, 표, 목록과 같은 요소를 추출하고 컨텍스트 인식 청크를 반환합니다. | 레이아웃 파서 | |
| 맞춤 프로세서 기준을 충족하는 맞춤 문서에서 항목을 추출합니다. | 맞춤 추출기 만들기 | |
| 특정 문서 유형에서 항목을 추출합니다. | 사전 학습된 프로세서 (업트레이닝하여 품질을 개선) | |
| 분류 | 문서를 분류합니다. | 맞춤 분류기 만들기 |
| 문서 분할 | 맞춤 분할기 만들기 |
이 다이어그램은 각 사용 사례에 가장 적합한 프로세서를 결정하는 데 도움이 됩니다.
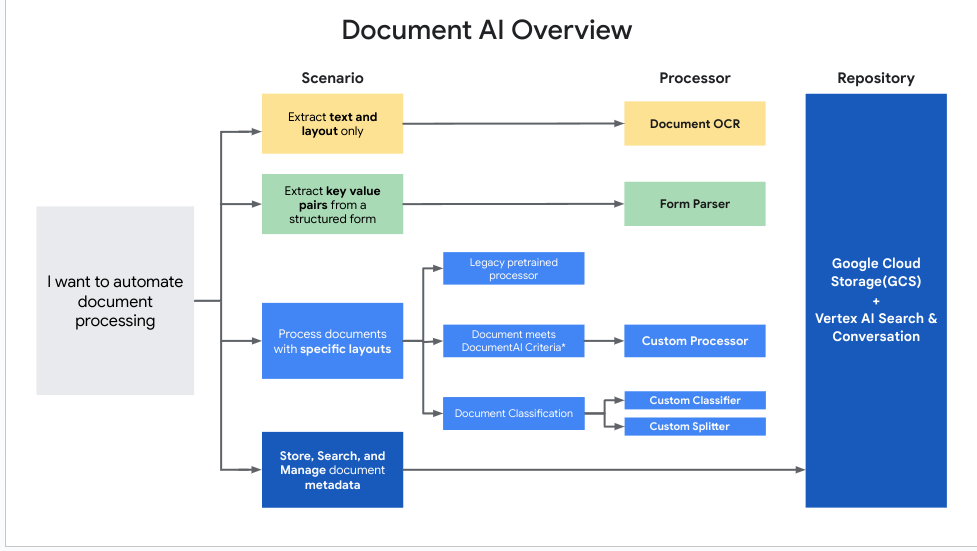
Document AI 프로세서 사용
Document AI를 사용하여 문서 처리를 시작하는 주요 단계는 다음과 같습니다.
사용 사례에 적합한 프로세서를 선택합니다.
- 각 프로세서에 관한 전체 정보는 전체 프로세서 및 세부정보 목록을 참고하세요.
Google Cloud 콘솔 또는 Document AI API를 사용하여 프로세서 만들기
Document AI는 문서를 전송할 수 있는 예측 엔드포인트를 만듭니다.
자세한 내용은 프로세서 만들기를 참고하세요.
처음부터 학습 및 테스트 데이터를 사용하여 프로세서를 학습시키거나 기존 프로세서 위에 새 (사전 학습된) 프로세서 버전을 업트레이닝합니다.
- 자세한 내용은 트레이닝 프로세서를 참고하세요.
처리를 위해 문서를 보냅니다.