처리 요청에 대한 응답에는 Document AI가 추출할 수 있었던 모든 구조화된 정보를 비롯해 처리된 문서에 대해 알려진 모든 정보를 담고 있는 Document 객체가 포함됩니다.
이 페이지에서는 샘플 문서를 제공한 다음 OCR 결과의 측면을 Document 객체 JSON의 특정 요소에 매핑하여 Document 객체의 레이아웃을 설명합니다.
클라이언트 라이브러리 코드 샘플과 Document AI Toolbox SDK 코드 샘플도 제공합니다.
이 코드 샘플은 온라인 처리를 사용하지만 Document 객체 파싱은 일괄 처리에서도 동일하게 작동합니다.
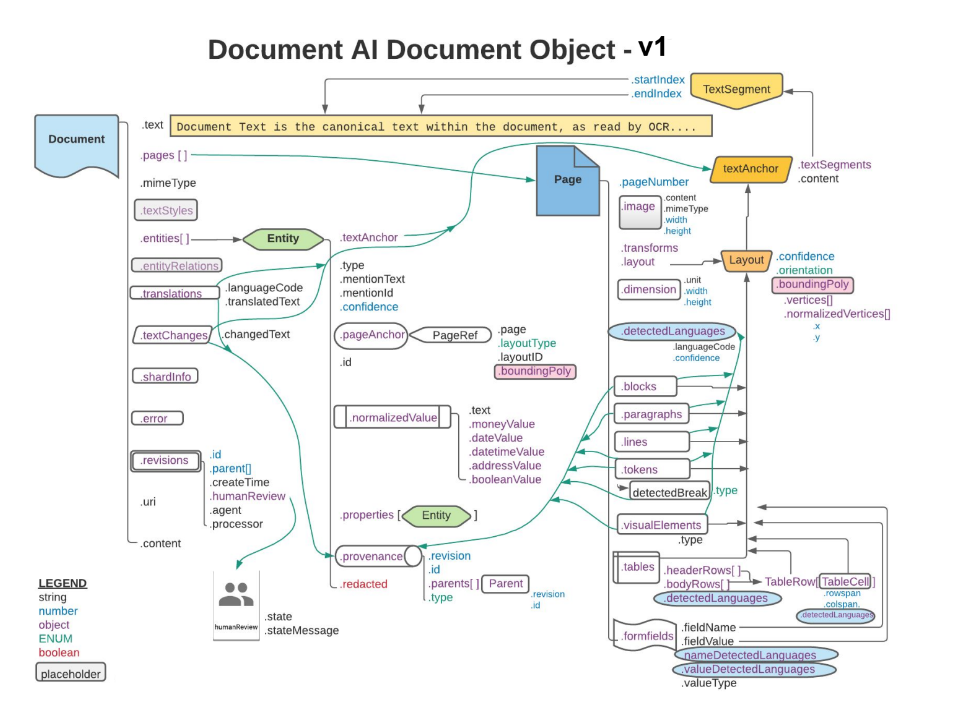
주황색 및 파란색 사각형과 화살표는 연결된 객체의 필드 중 하나 이상이 각각 .layout 또는 detectedLanguage임을 나타냅니다. 다이어그램은 까마귀 발 표기법을 사용합니다.
요소를 펼치거나 접도록 특별히 설계된 JSON 뷰어 또는 편집 유틸리티를 사용합니다. 일반 텍스트 유틸리티에서 원시 JSON을 검토하는 것은 비효율적입니다.
텍스트, 레이아웃, 품질 점수
다음은 샘플 텍스트 문서입니다.

다음은 Enterprise Document OCR 프로세서에서 반환된 전체 문서 객체입니다.
OCR은 프로세서에 의해 실행되므로 이 OCR 출력은 항상 Document AI 프로세서 출력에 포함됩니다. 기존 OCR 데이터를 사용하므로 인라인 문서 옵션을 사용하여 Document AI 프로세서에 이러한 JSON 데이터를 입력할 수 있습니다.
image=None, # all our samples pass this var
mime_type="application/json",
inline_document=document_response # pass OCR output to CDE input - undocumented
다음은 몇 가지 중요한 필드입니다.
원시 텍스트
text 필드에는 Document AI에서 인식한 텍스트가 포함됩니다.
이 텍스트에는 공백, 탭, 줄 바꿈을 제외한 레이아웃 구조가 포함되어 있지 않습니다. 이 필드는 문서의 텍스트 정보를 저장하고 문서 텍스트의 정보 소스 역할을 하는 유일한 필드입니다. 다른 필드는 위치 (startIndex 및 endIndex)로 텍스트 필드의 일부를 참조할 수 있습니다.
{
text: "Sample Document\nHeading 1\nLorem ipsum dolor sit amet, ..."
}
페이지 크기 및 언어
문서 객체의 각 page은 샘플 문서의 실제 페이지에 해당합니다. 샘플 JSON 출력에는 단일 PNG 이미지이므로 한 페이지가 포함됩니다.
{
"pages:" [
{
"pageNumber": 1,
"dimension": {
"width": 679.0,
"height": 460.0,
"unit": "pixels"
},
}
]
}
pages[].detectedLanguages[]필드에는 특정 페이지에서 발견된 언어와 신뢰도 점수가 포함됩니다.
{
"pages": [
{
"detectedLanguages": [
{
"confidence": 0.98009938,
"languageCode": "en"
},
{
"confidence": 0.01990064,
"languageCode": "und"
}
]
}
]
}
OCR 데이터
Document AI OCR은 텍스트 블록, 단락, 토큰, 기호 (기호 수준 데이터를 출력하도록 구성된 경우 기호 수준은 선택사항) 등 페이지의 다양한 세분성 또는 조직으로 텍스트를 감지합니다. 이들은 모두 페이지 객체의 멤버입니다.
모든 요소에는 위치와 텍스트를 설명하는 layout가 있습니다. 비텍스트 시각적 요소(예: 체크박스)도 페이지 수준에 있습니다.
{
"pages": [
{
"paragraphs": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "16"
}
]
},
"confidence": 0.9939527,
"boundingPoly": {
"vertices": [ ... ],
"normalizedVertices": [ ... ]
},
"orientation": "PAGE_UP"
}
}
]
}
]
}
원시 텍스트는 startIndex 및 endIndex로 기본 텍스트 문자열에 색인이 지정된 textAnchor 객체에서 참조됩니다.
boundingPoly의 경우 페이지의 왼쪽 상단이 원점(0,0)입니다. 양수 X 값은 오른쪽, 양수 Y 값은 아래쪽입니다.vertices객체는 원본 이미지와 동일한 좌표를 사용하는 반면normalizedVertices은[0,1]범위에 있습니다. 이미지의 기울기 보정 및 기타 정규화 속성을 나타내는 변환 행렬이 있습니다.
boundingPoly를 그리려면 한 꼭지점에서 다음 꼭지점까지 선분을 그립니다. 그런 다음 마지막 꼭짓점에서 첫 번째 꼭짓점으로 선 세그먼트를 그려 다각형을 닫습니다. 레이아웃의 orientation 요소는 텍스트가 페이지를 기준으로 회전되었는지 여부를 나타냅니다.
문서의 구조를 시각화할 수 있도록 다음 이미지에서는 page.paragraphs, page.lines, page.tokens의 경계 다각형을 그립니다.
단락

선

토큰

블록

Enterprise Document OCR 프로세서는 가독성을 기반으로 문서의 품질을 평가할 수 있습니다.
- API 응답에서 이 데이터를 가져오려면
processOptions.ocrConfig.enableImageQualityScores필드를true로 설정해야 합니다.
이 품질 평가는 [0, 1]의 품질평가점수이며 1는 완벽한 품질을 의미합니다.
품질 점수는 Page.imageQualityScores 필드에 반환됩니다.
감지된 모든 결함은 quality/defect_*로 표시되고 신뢰도 값을 기준으로 내림차순으로 정렬됩니다.
다음은 너무 어둡고 흐려서 편안하게 읽을 수 없는 PDF입니다.
다음은 Enterprise Document OCR 프로세서에서 반환하는 문서 품질 정보입니다.
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
코드 샘플
다음 코드 샘플은 처리 요청을 전송한 후 필드를 읽고 터미널에 출력하는 방법을 보여줍니다.
Java
자세한 내용은 Document AI Java API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Node.js
자세한 내용은 Document AI Node.js API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Python
자세한 내용은 Document AI Python API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
양식 및 표
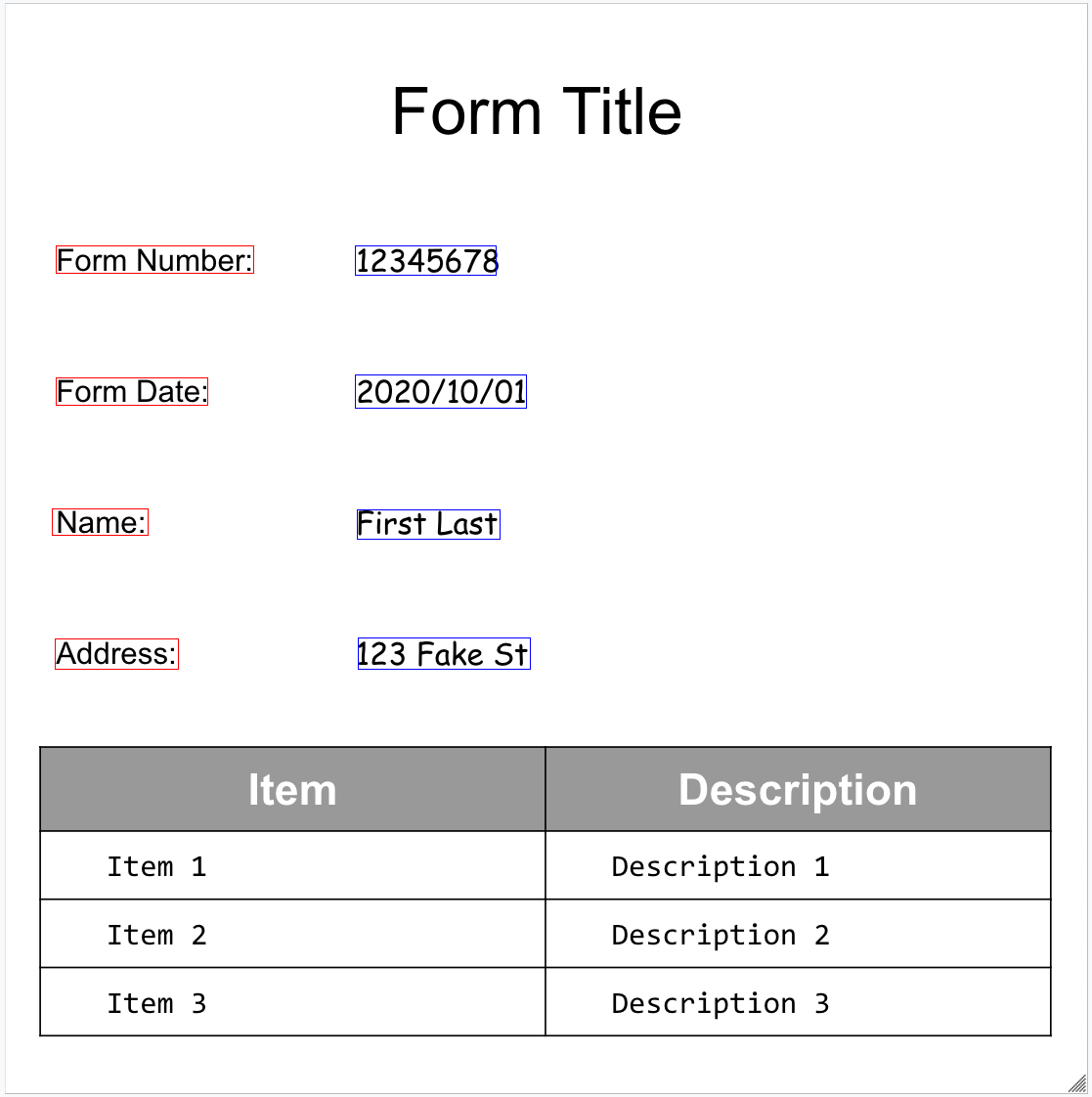
다음은 샘플 양식입니다.
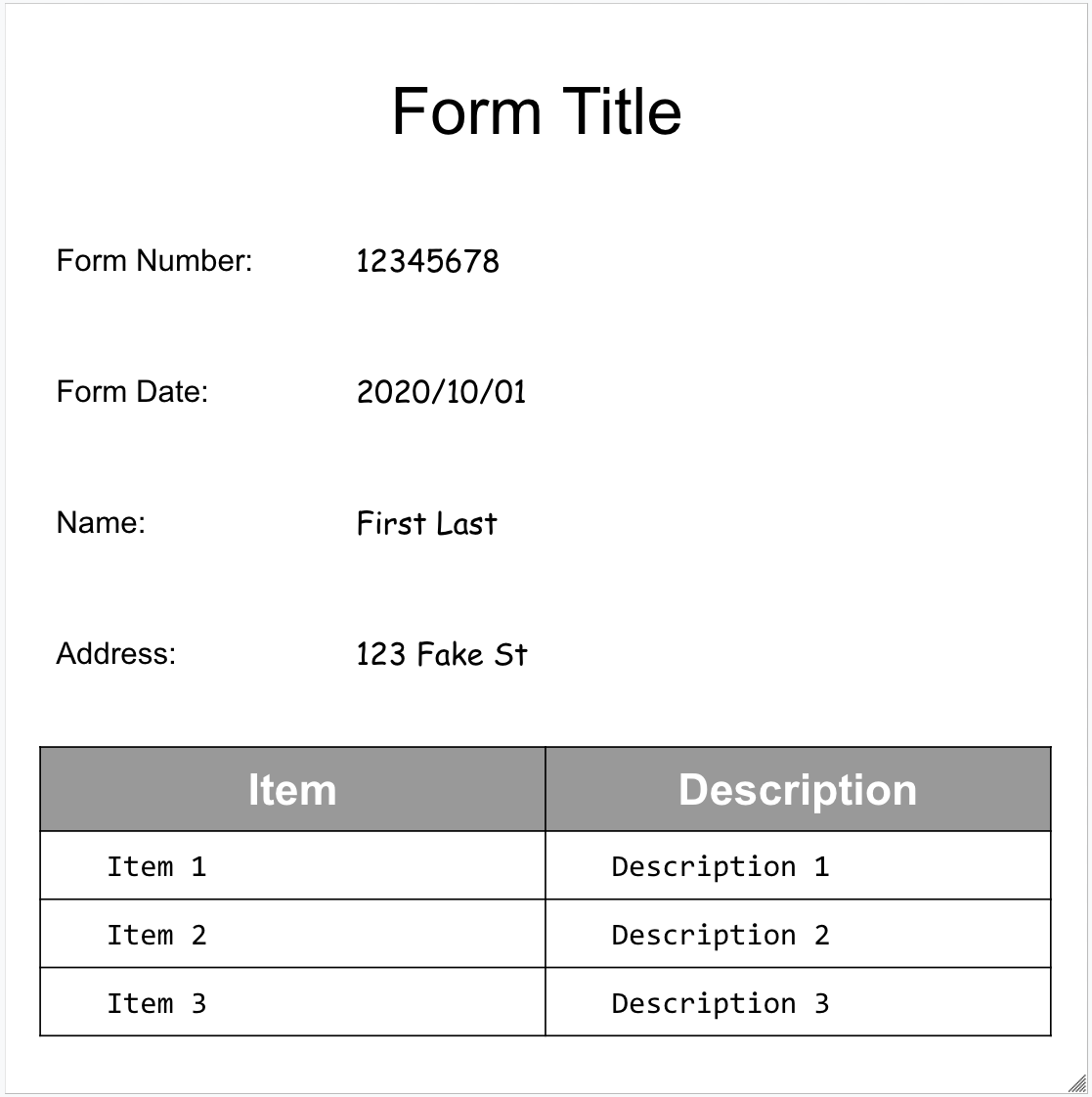
다음은 양식 파서에서 반환된 전체 문서 객체입니다.
다음은 몇 가지 중요한 필드입니다.
양식 파서는 페이지에서 FormFields을 감지할 수 있습니다. 각 양식 필드에는 이름과 값이 있습니다. 이를 키-값 쌍 (KVP)이라고도 합니다. KVP는 다른 추출기의 (스키마) 항목과 다릅니다.
엔티티 이름이 구성됩니다. KVP의 키는 문서의 키 텍스트와 동일합니다.
{
"pages:" [
{
"formFields": [
{
"fieldName": { ... },
"fieldValue": { ... }
}
]
}
]
}
- Document AI는 페이지에서
Tables도 감지할 수 있습니다.
{
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
양식 파서 내의 표 추출은 행이나 열에 걸쳐 있는 셀이 없는 기존 표만 인식합니다. 따라서 rowSpan와 colSpan은 항상 1입니다.
프로세서 버전
pretrained-form-parser-v2.0-2022-11-10부터 양식 파서는 일반 항목도 인식할 수 있습니다. 자세한 내용은 양식 파서를 참고하세요.문서의 구조를 시각화할 수 있도록 다음 이미지에서는
page.formFields및page.tables의 경계 다각형을 그립니다.표의 체크박스 양식 파서는 이미지와 PDF의 체크박스를 KVP로 디지털화할 수 있습니다. 체크박스 디지털화의 예를 키-값 쌍으로 제공합니다.
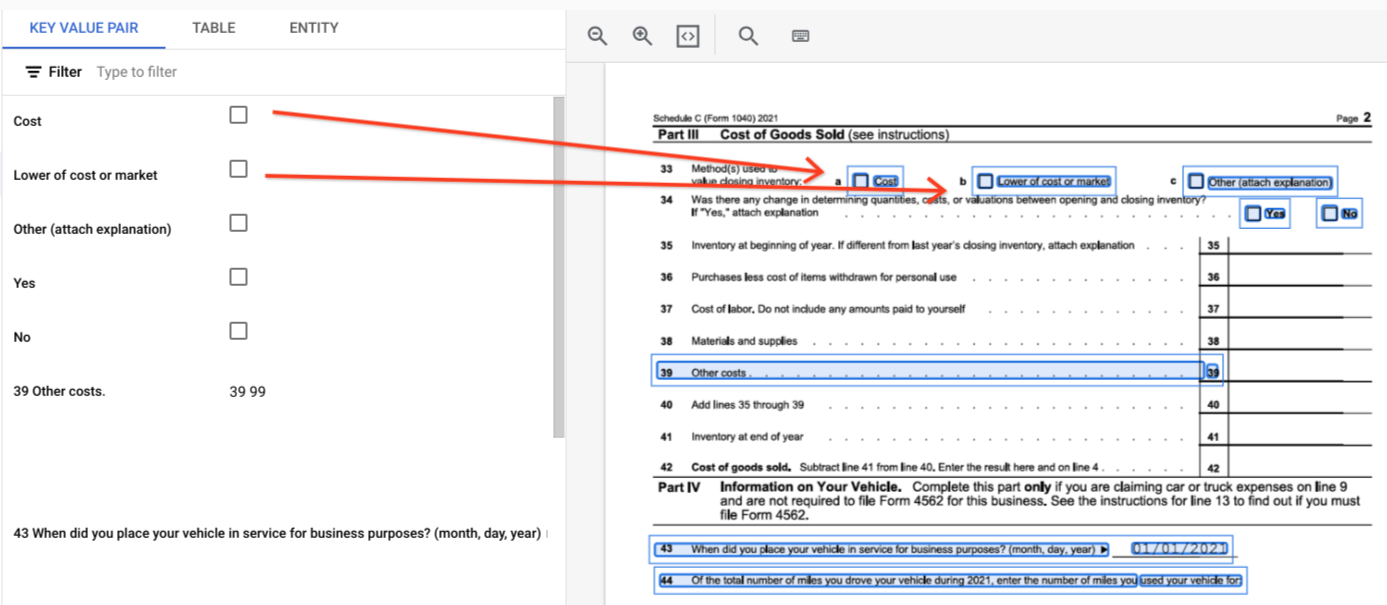
표 외부에서 체크박스는 양식 파서 내에서 시각적 요소로 표시됩니다. UI의 체크표시가 있는 정사각형 상자와 JSON의 유니코드 ✓를 강조 표시합니다.
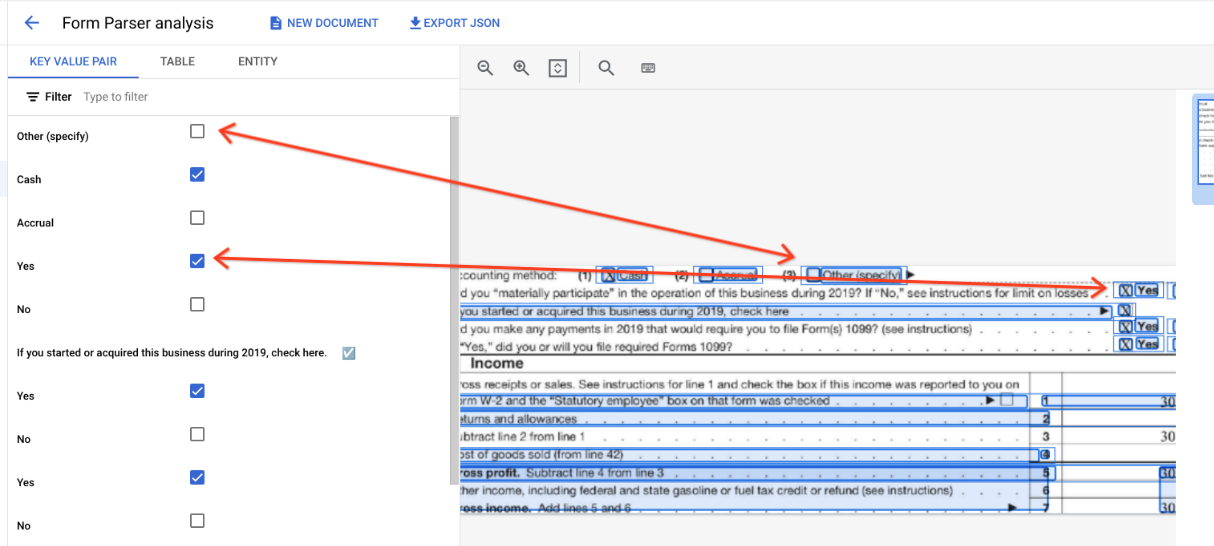
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
표에서 체크박스는 ✓ (선택됨) 또는 ☐ (선택 해제됨)과 같은 유니코드 문자로 표시됩니다.
채워진 체크박스의 값은 filled_checkbox입니다(under pages > x > formFields > x > fieldValue > valueType.). 선택되지 않은 체크박스의 값은 unfilled_checkbox입니다.
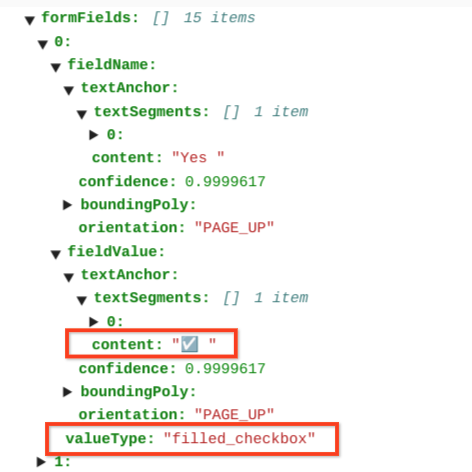
콘텐츠 필드에는 pages>formFields>x>fieldValue>textAnchor>content 경로에서 강조 표시된 ✓로 체크박스 콘텐츠 값이 표시됩니다.
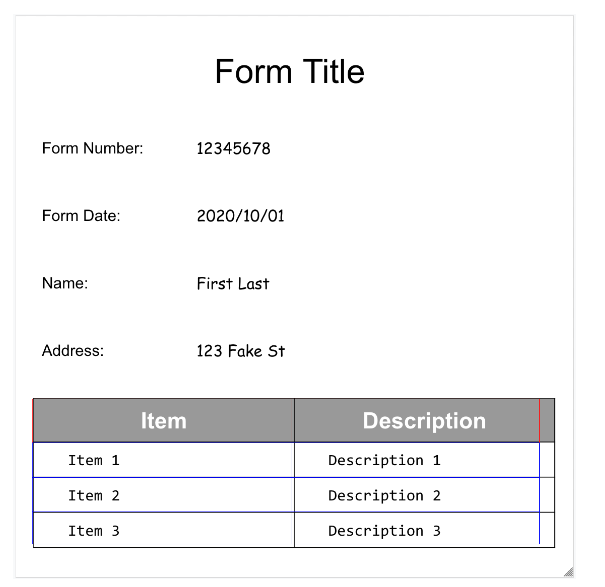
문서의 구조를 시각화하는 데 도움이 되도록 다음 이미지에서는 page.formFields 및 page.tables의 경계 다각형을 그립니다.
양식 입력란
테이블
코드 샘플
다음 코드 샘플은 처리 요청을 전송한 후 필드를 읽고 터미널에 출력하는 방법을 보여줍니다.
Java
자세한 내용은 Document AI Java API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Node.js
자세한 내용은 Document AI Node.js API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Python
자세한 내용은 Document AI Python API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
항목, 중첩된 항목, 정규화된 값
많은 전문 프로세서는 잘 정의된 스키마에 기반한 구조화된 데이터를 추출합니다. 예를 들어 인보이스 파서는 invoice_date 및 supplier_name과 같은 특정 필드를 감지합니다. 다음은 샘플 인보이스입니다.
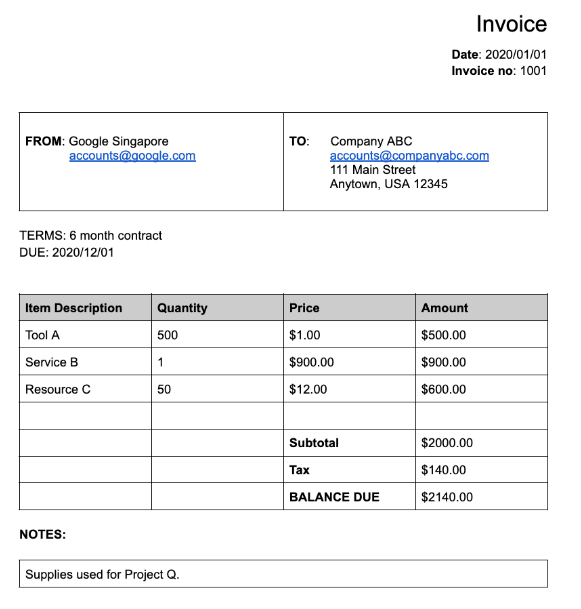
인보이스 파서에서 반환된 전체 문서 객체는 다음과 같습니다.
다음은 문서 객체의 중요한 부분입니다.
감지된 필드:
Entities에는 프로세서가 감지할 수 있는 필드가 포함됩니다(예:invoice_date).{ "entities": [ { "textAnchor": { "textSegments": [ { "startIndex": "14", "endIndex": "24" } ], "content": "2020/01/01" }, "type": "invoice_date", "confidence": 0.9938466, "pageAnchor": { ... }, "id": "2", "normalizedValue": { "text": "2020-01-01", "dateValue": { "year": 2020, "month": 1, "day": 1 } } } ] }특정 필드의 경우 프로세서가 값을 정규화하기도 합니다. 이 예시에서는 날짜가
2020/01/01에서2020-01-01로 정규화되었습니다.정규화: 지원되는 많은 특정 필드의 경우 프로세서가 값을 정규화하고
entity도 반환합니다.normalizedValue필드가 각 항목의textAnchor을 통해 획득한 원시 추출 필드에 추가됩니다. 따라서 리터럴 텍스트를 정규화하여 텍스트 값을 하위 필드로 분할하는 경우가 많습니다. 예를 들어 2024년 9월 1일과 같은 날짜는 다음과 같이 표시됩니다.
normalizedValue": {
"text": "2020-09-01",
"dateValue": {
"year": 2024,
"month": 9,
"day": 1
}
이 예에서 날짜는 2020/01/01에서 2020-01-01로 정규화되었습니다. 이는 후처리를 줄이고 선택한 형식으로 변환할 수 있는 표준화된 형식입니다.
주소는 정규화되는 경우가 많으며, 이 경우 주소의 요소가 개별 필드로 분류됩니다. 숫자는 정수 또는 부동 소수점 숫자를 normalizedValue로 사용하여 정규화됩니다.
- 보강: 특정 프로세서와 필드는 보강도 지원합니다.
예를 들어 문서
Google Singapore의 원래supplier_name가 Enterprise Knowledge Graph에 대해Google Asia Pacific, Singapore로 정규화되었습니다. 또한 Enterprise Knowledge Graph에는 Google에 관한 정보가 포함되어 있으므로 샘플 문서에 없더라도 Document AI가supplier_address를 추론합니다.
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "supplier_name",
"confidence": 0.39170802,
"pageAnchor": { ... },
"id": "12",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
},
{
"type": "supplier_address",
"id": "17",
"normalizedValue": {
"text": "70 Pasir Panjang Rd #03-71 Mapletree Business City II Singapore 117371",
"addressValue": {
"regionCode": "SG",
"languageCode": "en-US",
"postalCode": "117371",
"addressLines": [
"70 Pasir Panjang Rd",
"#03-71 Mapletree Business City II"
]
}
}
}
]
}
중첩 필드: 먼저 항목을 상위로 선언한 다음 상위 아래에 하위 항목을 만들어 중첩 스키마 (필드)를 만들 수 있습니다. 상위 요소의 파싱 응답에는 상위 요소 필드의
properties요소에 하위 필드가 포함됩니다. 다음 예에서line_item은line_item/description및line_item/quantity이라는 두 개의 하위 필드가 있는 상위 필드입니다.{ "entities": [ { "textAnchor": { ... }, "type": "line_item", "confidence": 1.0, "pageAnchor": { ... }, "id": "19", "properties": [ { "textAnchor": { "textSegments": [ ... ], "content": "Tool A" }, "type": "line_item/description", "confidence": 0.3461604, "pageAnchor": { ... }, "id": "20" }, { "textAnchor": { "textSegments": [ ... ], "content": "500" }, "type": "line_item/quantity", "confidence": 0.8077843, "pageAnchor": { ... }, "id": "21", "normalizedValue": { "text": "500" } } ] } ] }
다음 파서는 이를 따릅니다.
- 추출 (맞춤 추출기)
- 기존
- 은행 명세서 파서
- 지출 파서
- 인보이스 파서
- PaySlip 파서
- W2 파서
코드 샘플
다음 코드 샘플은 처리 요청을 전송한 다음 전문 프로세서에서 필드를 읽어 터미널에 인쇄하는 방법을 보여줍니다.
Java
자세한 내용은 Document AI Java API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Node.js
자세한 내용은 Document AI Node.js API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Python
자세한 내용은 Document AI Python API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
커스텀 문서 추출기
커스텀 문서 추출기 프로세서는 선행 학습된 프로세서를 사용할 수 없는 문서에서 커스텀 항목을 추출할 수 있습니다. 이는 맞춤 모델을 학습시키거나 생성형 AI 파운데이션 모델을 사용하여 학습 없이 명명된 엔티티를 추출하여 달성할 수 있습니다. 자세한 내용은 콘솔에서 맞춤 문서 추출기 만들기를 참고하세요.
- 커스텀 모델을 학습시키는 경우 선행 학습된 항목 추출 프로세서와 정확히 동일한 방식으로 프로세서를 사용할 수 있습니다.
- 파운데이션 모델을 사용하는 경우 프로세서 버전을 만들어 요청마다 특정 항목을 추출하거나 요청별로 구성할 수 있습니다.
출력 구조에 대한 자세한 내용은 엔티티, 중첩된 엔티티, 정규화된 값을 참고하세요.
코드 샘플
커스텀 모델을 사용하거나 파운데이션 모델을 사용하여 프로세서 버전을 만든 경우 항목 추출 코드 샘플을 사용하세요.
다음 코드 샘플은 요청별로 기본 모델 맞춤 문서 추출기의 특정 항목을 구성하고 추출된 항목을 출력하는 방법을 보여줍니다.
Python
자세한 내용은 Document AI Python API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
요약
요약기 프로세서는 생성형 AI 파운데이션 모델을 사용하여 문서에서 추출한 텍스트를 요약합니다. 다음과 같은 방법으로 대답의 길이와 형식을 맞춤설정할 수 있습니다.
- 길이
BRIEF: 한두 문장으로 된 간단한 요약MODERATE: 단락 길이 요약COMPREHENSIVE: 사용 가능한 가장 긴 옵션
- 형식
특정 길이와 형식의 프로세서 버전을 만들거나 요청별로 구성할 수 있습니다.
요약된 텍스트가 Document.entities.normalizedValue.text에 표시됩니다. 전체 샘플 출력 JSON 파일은 샘플 프로세서 출력에서 확인할 수 있습니다.
자세한 내용은 콘솔에서 문서 요약 도구 빌드를 참고하세요.
코드 샘플
다음 코드 샘플은 처리 요청에서 특정 길이와 형식을 구성하고 요약된 텍스트를 출력하는 방법을 보여줍니다.
Python
자세한 내용은 Document AI Python API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
분할 및 분류
다음은 다양한 유형의 문서와 양식이 포함된 10페이지짜리 PDF입니다.
대출 문서 분할기 및 분류 기준에서 반환하는 전체 문서 객체는 다음과 같습니다.
스플리터에 의해 감지된 각 문서는 entity로 표시됩니다. 예를 들면 다음과 같습니다.
{
"entities": [
{
"textAnchor": {
"textSegments": [
{
"startIndex": "13936",
"endIndex": "21108"
}
]
},
"type": "1040se_2020",
"confidence": 0.76257163,
"pageAnchor": {
"pageRefs": [
{
"page": "6"
},
{
"page": "7"
}
]
}
}
]
}
Entity.pageAnchor은 이 문서가 2페이지임을 나타냅니다.pageRefs[].page는 0부터 시작하며document.pages[]필드의 색인입니다.
입니다.Entity.type은 이 문서가 1040 Schedule SE 양식임을 지정합니다. 식별할 수 있는 문서 유형의 전체 목록은 프로세서 문서의 식별된 문서 유형을 참고하세요.
자세한 내용은 문서 분할기 동작을 참고하세요.
코드 샘플
분할기는 페이지 경계를 식별하지만 입력 문서를 실제로 분할하지는 않습니다. Document AI 도구 상자를 사용하여 페이지 경계를 기준으로 PDF 파일을 물리적으로 분할할 수 있습니다. 다음 코드 샘플은 PDF를 분할하지 않고 페이지 범위를 인쇄합니다.
Java
자세한 내용은 Document AI Java API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Node.js
자세한 내용은 Document AI Node.js API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Python
자세한 내용은 Document AI Python API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Document의 페이지 경계를 사용하여 PDF 파일을 분할합니다.
Python
자세한 내용은 Document AI Python API 참조 문서를 참고하세요.
Document AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Document AI 도구 상자
Document AI Toolbox는 문서 응답에서 정보를 관리, 조작, 추출하는 유틸리티 함수를 제공하는 Python용 SDK입니다.
Cloud Storage의 JSON 파일, 로컬 JSON 파일 또는 process_document() 메서드에서 직접 출력된 처리된 문서 응답에서 '래핑된' 문서 객체를 만듭니다.
다음 작업을 실행할 수 있습니다.
- 일괄 처리에서 조각화된
DocumentJSON 파일을 단일 '래핑된' 문서로 결합합니다. - 샤드를 통합된
Document으로 내보냅니다. -
다음에서
Document출력을 가져옵니다. Layout정보를 처리하지 않고Pages,Lines,Paragraphs,FormFields,Tables의 텍스트에 액세스합니다.- 타겟 문자열을 포함하거나 정규 표현식과 일치하는
Pages을 검색합니다. - 이름으로
FormFields을 검색합니다. - 유형별로
Entities을 검색합니다. Tables를 Pandas DataFrame 또는 CSV로 변환합니다.Entities및FormFields를 BigQuery 테이블에 삽입합니다.- Splitter/Classifier 프로세서의 출력을 기반으로 PDF 파일을 분할합니다.
Document경계 상자에서 이미지Entities를 추출합니다.-
Documents을 일반적으로 사용되는 형식으로 변환하거나 일반적으로 사용되는 형식에서Documents으로 변환합니다.- Cloud Vision API
AnnotateFileResponse - hOCR
- 서드 파티 문서 처리 형식
- Cloud Vision API
- Cloud Storage 폴더에서 처리할 문서의 일괄 처리를 만듭니다.
코드 샘플
다음 코드 샘플은 Document AI Toolbox를 사용하는 방법을 보여줍니다.