Leistung auswerten
Document AI generiert Bewertungsmesswerte wie Precision und Recall, damit Sie die Vorhersageleistung Ihrer Prozessoren ermitteln können.
Diese Bewertungsmesswerte werden durch einen Vergleich der vom Prozessor zurückgegebenen Entitäten (Vorhersagen) mit den Annotationen in den Testdokumenten generiert. Wenn Ihr Prozessor kein Testset hat, müssen Sie zuerst ein Dataset erstellen und die Testdokumente labeln.
Bewertung ausführen
Eine Bewertung wird automatisch ausgeführt, wenn Sie eine Prozessorversion trainieren oder aktualisieren.
Sie können eine Bewertung auch manuell ausführen. Dies ist erforderlich, um aktualisierte Messwerte zu generieren, nachdem Sie das Testset geändert haben, oder wenn Sie eine vortrainierte Prozessorversion bewerten.
Web-UI
Rufen Sie in der Google Cloud Console die Seite Prozessoren auf und wählen Sie Ihren Prozessor aus.
Wählen Sie auf dem Tab Bewerten und testen die Version des Prozessors aus, die Sie bewerten möchten, und klicken Sie dann auf Neue Bewertung ausführen.
Nach Abschluss des Vorgangs enthält die Seite Bewertungsmesswerte für alle Labels und für jedes einzelne Label.
Python
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Python API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Ergebnisse einer Bewertung abrufen
Web-UI
Rufen Sie in der Google Cloud Console die Seite Prozessoren auf und wählen Sie Ihren Prozessor aus.
Wählen Sie auf dem Tab Bewerten und Testen die Version des Prozessors aus, für die Sie die Bewertung aufrufen möchten.
Nach Abschluss des Vorgangs enthält die Seite Bewertungsmesswerte für alle Labels und für jedes einzelne Label.
Python
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Python API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Alle Bewertungen für eine Prozessorversion auflisten
Python
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Python API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Bewertungsmesswerte für alle Labels
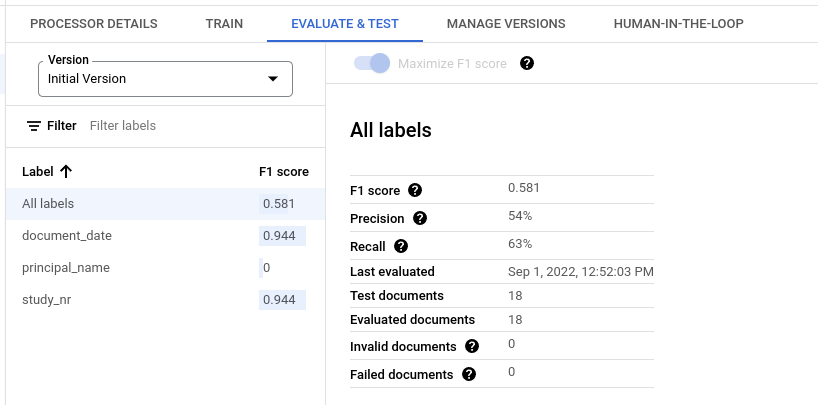
Messwerte für Alle Labels werden anhand der Anzahl der echt positiven, falsch positiven und falsch negativen Ergebnisse im Dataset für alle Labels berechnet. Sie werden also nach der Häufigkeit gewichtet, mit der die einzelnen Labels im Dataset vorkommen. Definitionen dieser Begriffe finden Sie unter Bewertungsmesswerte für einzelne Labels.
Präzision:Der Anteil der Vorhersagen, die mit den Anmerkungen im Testset übereinstimmen. Definiert als
True Positives / (True Positives + False Positives)Trefferquote:Der Anteil der Anmerkungen im Testsatz, die korrekt vorhergesagt wurden. Definiert als
True Positives / (True Positives + False Negatives)F1-Wert:Der harmonische Mittelwert von Precision und Recall. Er kombiniert Precision und Recall in einem einzelnen Messwert, wobei beide gleich gewichtet werden. Definiert als
2 * (Precision * Recall) / (Precision + Recall)
Bewertungsmesswerte für einzelne Labels
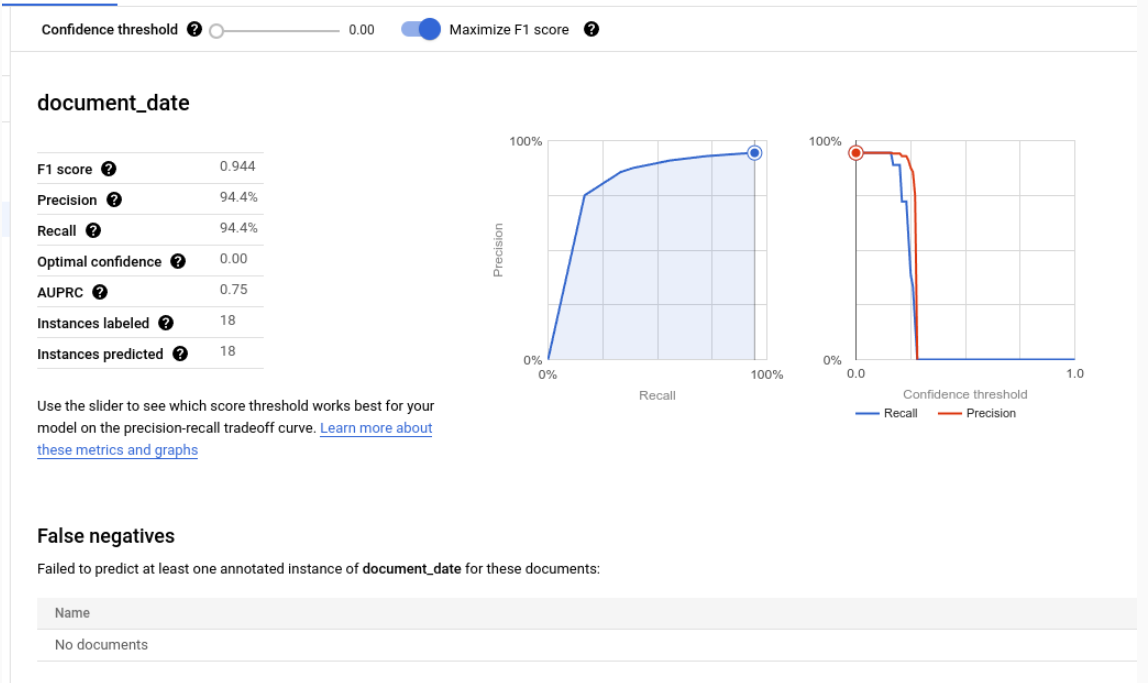
Richtig positive Ergebnisse:Die vorhergesagten Entitäten, die mit einer Annotation im Testdokument übereinstimmen. Weitere Informationen finden Sie unter Abgleichsverhalten.
Falsch positive Ergebnisse:Die vorhergesagten Entitäten, die mit keiner Annotation im Testdokument übereinstimmen.
Falsch negative Ergebnisse:Die Annotationen im Testdokument, die mit keiner der vorhergesagten Entitäten übereinstimmen.
- Falsch negative Ergebnisse (unterhalb Grenzwert): Die Anmerkungen im Testdokument, die mit einer vorhergesagten Einheit übereingestimmt hätten, aber der Konfidenzwert der vorhergesagten Einheit liegt unter dem angegebenen Konfidenzschwellenwert.
Konfidenzwert
Bei der Auswertungslogik werden alle Vorhersagen mit einem Konfidenzwert unter dem angegebenen Konfidenzschwellenwert ignoriert, auch wenn die Vorhersage richtig ist. Document AI bietet eine Liste mit Falsch negativen Ergebnissen (unter dem Grenzwert). Das sind die Anmerkungen, die eine Übereinstimmung hätten, wenn der Konfidenzgrenzwert niedriger wäre.
Document AI berechnet automatisch den optimalen Grenzwert, der den F1-Wert maximiert, und legt den Konfidenzgrenzwert standardmäßig auf diesen optimalen Wert fest.
Sie können den Konfidenzwert selbst festlegen, indem Sie den Schieberegler bewegen. Im Allgemeinen führt ein höherer Konfidenzschwellenwert zu Folgendem:
- höhere Precision, da die Vorhersagen mit höherer Wahrscheinlichkeit richtig sind.
- niedrigerer Recall, da es weniger Vorhersagen gibt.
Tabellarische Entitäten
Die Messwerte für ein übergeordnetes Label werden nicht durch direktes Mitteln der untergeordneten Messwerte berechnet, sondern durch Anwenden des Vertrauensschwellenwerts des übergeordneten Labels auf alle untergeordneten Labels und Aggregieren der Ergebnisse.
Der optimale Grenzwert für das übergeordnete Label ist der Konfidenzgrenzwert, der bei Anwendung auf alle untergeordneten Labels den maximalen F1-Wert für das übergeordnete Label ergibt.
Abgleichsverhalten
Eine vorhergesagte Entität stimmt mit einer Annotation überein, wenn:
- Der Typ der vorhergesagten Entität (
entity.type) stimmt mit dem Labelnamen der Annotation überein. - Der Wert der vorhergesagten Entität (
entity.mention_textoderentity.normalized_value.text) stimmt mit dem Textwert der Anmerkung überein, wobei Fuzzy Matching angewendet wird, falls es aktiviert ist.
Für den Abgleich werden nur Typ und Textwert verwendet. Andere Informationen wie Textanker und Begrenzungsrahmen (mit Ausnahme der unten beschriebenen tabellarischen Einheiten) werden nicht verwendet.
Labels mit einem oder mehreren Vorkommen
Labels mit einmaligem Vorkommen haben einen Wert pro Dokument (z. B. Rechnungs-ID), auch wenn dieser Wert mehrmals im selben Dokument annotiert wird (z. B. wenn die Rechnungs-ID auf jeder Seite desselben Dokuments erscheint). Auch wenn die mehreren Anmerkungen unterschiedlichen Text haben, werden sie als gleich betrachtet. Mit anderen Worten: Wenn eine vorhergesagte Entität mit einer der Anmerkungen übereinstimmt, wird sie als Übereinstimmung gezählt. Die zusätzlichen Anmerkungen gelten als doppelte Erwähnungen und werden nicht auf die Anzahl der richtig positiven, falsch positiven oder falsch negativen Ergebnisse angerechnet.
Labels mit mehreren Vorkommen können mehrere unterschiedliche Werte haben. Daher werden jede vorhergesagte Entität und Annotation separat berücksichtigt und abgeglichen. Wenn ein Dokument N Anmerkungen für ein Label mit mehreren Vorkommen enthält, kann es N Übereinstimmungen mit den vorhergesagten Elementen geben. Jede vorhergesagte Entität und Anmerkung wird unabhängig als richtig positiv, falsch positiv oder falsch negativ gezählt.
Ungenaue Übereinstimmung
Mit dem Schalter Ungefähre Übereinstimmung können Sie einige der Abgleichsregeln verschärfen oder lockern, um die Anzahl der Übereinstimmungen zu verringern oder zu erhöhen.
Ohne unscharfen Abgleich stimmt der String ABC beispielsweise aufgrund der Groß- und Kleinschreibung nicht mit abc überein. Mit ungenauer Übereinstimmung stimmen sie jedoch überein.
Wenn die ungenaue Übereinstimmung aktiviert ist, gelten die folgenden Regeländerungen:
Normalisierung von Leerräumen:Voran- und nachgestellte Leerräume werden entfernt und aufeinanderfolgende Leerräume (einschließlich Zeilenumbrüche) werden in einzelne Leerzeichen umgewandelt.
Entfernen von Satzzeichen am Anfang und Ende: Die folgenden Satzzeichen am Anfang und Ende werden entfernt:
!,.:;-"?|.Abgleich ohne Berücksichtigung der Groß-/Kleinschreibung:Alle Zeichen werden in Kleinbuchstaben umgewandelt.
Geldnormalisierung:Entfernen Sie für Labels mit dem Datentyp
moneydie führenden und nachgestellten Währungssymbole.
Tabellarische Entitäten
Übergeordnete Einheiten und Anmerkungen haben keine Textwerte und werden anhand der kombinierten Begrenzungsrahmen ihrer untergeordneten Elemente abgeglichen. Wenn es nur ein vorhergesagtes und ein annotiertes übergeordnetes Element gibt, werden sie automatisch zugeordnet, unabhängig von den Begrenzungsrahmen.
Sobald Eltern zugeordnet sind, werden ihre Kinder so zugeordnet, als wären sie nicht tabellarische Einheiten. Wenn Eltern nicht zugeordnet werden, versucht Document AI nicht, ihre Kinder zuzuordnen. Das bedeutet, dass untergeordnete Entitäten auch bei gleichem Textinhalt als falsch angesehen werden können, wenn ihre übergeordneten Entitäten nicht übereinstimmen.
Über- und untergeordnete Einheiten sind eine Vorschaufunktion und werden nur für Tabellen mit einer Verschachtelungsebene unterstützt.
Bewertungsmesswerte exportieren
Rufen Sie in der Google Cloud Console die Seite Prozessoren auf und wählen Sie Ihren Prozessor aus.
Klicken Sie auf dem Tab Bewerten und testen auf Messwerte herunterladen, um die Bewertungsstatistiken als JSON-Datei herunterzuladen.