Crea un clúster de Dataproc con bibliotecas cliente
El siguiente código de muestra indica cómo usar las bibliotecas cliente de Cloud para crear un clúster de Dataproc, ejecutar un trabajo en el clúster y, luego, borrar el clúster.
También puedes realizar estas tareas con las siguientes herramientas:
- Solicitudes de la API de REST en la Guía de inicio rápido sobre el uso del Explorador de API
- la consola de Google Cloud en Crea un clúster de Dataproc mediante la consola de Google Cloud
- Google Cloud CLI en Crea un clúster de Dataproc con Google Cloud CLI
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Ejecuta el código
Prueba la explicación: Haz clic en Open in Cloud Shell para ejecutar una explicación de las bibliotecas cliente de Cloud de Python que crea un clúster, ejecuta un trabajo de PySpark y, luego, borra el clúster.
Go
- Instala la biblioteca cliente Para obtener más información, consulta la documentación sobre cómo configurar tu entorno de desarrollo.
- Configura la autenticación
- Clona y ejecuta el código de muestra de GitHub.
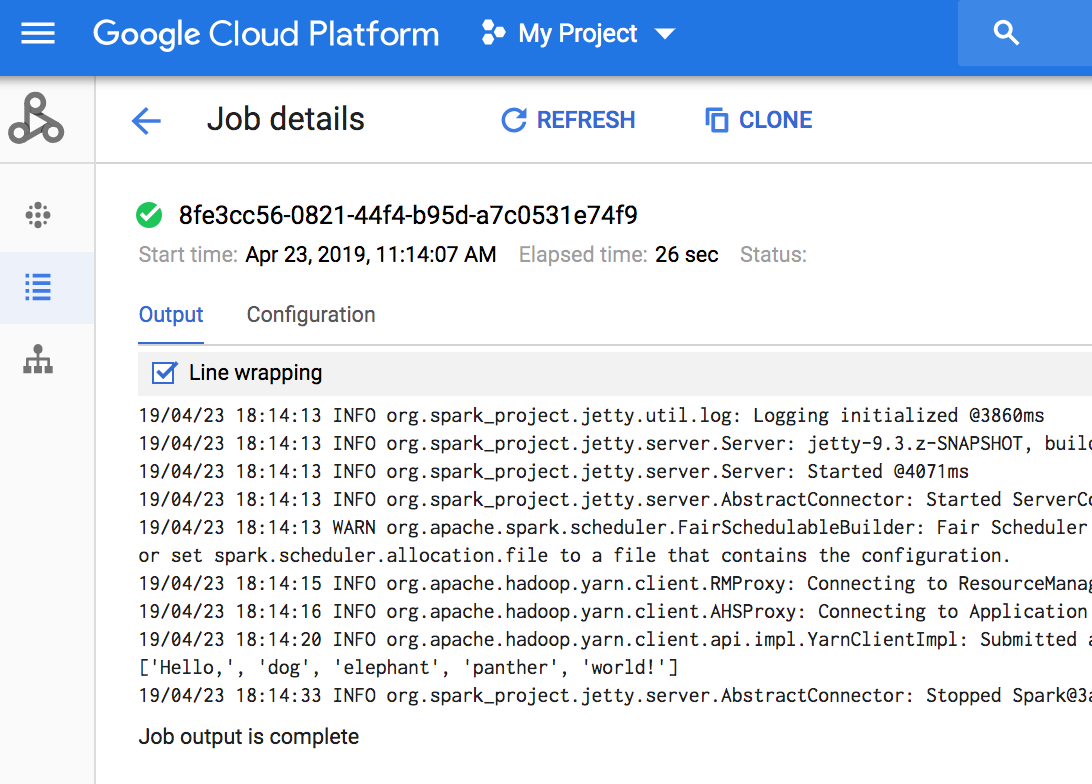
- Revisa el resultado. El código muestra el registro del controlador del trabajo en el bucket de staging predeterminado de Dataproc en Cloud Storage. Puedes ver el resultado del controlador del trabajo desde la consola de Google Cloud en la sección Trabajos de Dataproc de tu proyecto. Haz clic en el ID de tarea para ver el resultado del trabajo en la página Detalles del trabajo.
Java
- Instala la biblioteca cliente Para obtener más información, consulta la documentación sobre cómo configurar un entorno de desarrollo Java.
- Configura la autenticación
- Clona y ejecuta el código de muestra de GitHub.
- Revisa el resultado. El código muestra el registro del controlador del trabajo en el bucket de staging predeterminado de Dataproc en Cloud Storage. Puedes ver el resultado del controlador del trabajo desde la consola de Google Cloud en la sección Trabajos de Dataproc de tu proyecto. Haz clic en el ID de tarea para ver el resultado del trabajo en la página Detalles del trabajo.
Node.js
- Instala la biblioteca cliente Para obtener más información, consulta la documentación sobre cómo configurar un entorno de desarrollo de Node.js.
- Configura la autenticación
- Clona y ejecuta el código de muestra de GitHub.
- Revisa el resultado. El código muestra el registro del controlador del trabajo en el bucket de staging predeterminado de Dataproc en Cloud Storage. Puedes ver el resultado del controlador del trabajo desde la consola de Google Cloud en la sección Trabajos de Dataproc de tu proyecto. Haz clic en el ID de tarea para ver el resultado del trabajo en la página Detalles del trabajo.
Python
- Instala la biblioteca cliente Para obtener más información, consulta la documentación sobre cómo configurar un entorno de desarrollo de Python.
- Configura la autenticación
- Clona y ejecuta el código de muestra de GitHub.
- Revisa el resultado. El código muestra el registro del controlador del trabajo en el bucket de staging predeterminado de Dataproc en Cloud Storage. Puedes ver el resultado del controlador del trabajo desde la consola de Google Cloud en la sección Trabajos de Dataproc de tu proyecto. Haz clic en el ID de tarea para ver el resultado del trabajo en la página Detalles del trabajo.
¿Qué sigue?
- Consulta los Recursos adicionales de la biblioteca cliente de Cloud de Dataproc.