You can activate additional components like Flink when you create a Dataproc cluster using the Optional components feature. This page shows you how to create a Dataproc cluster with the Apache Flink optional component activated (a Flink cluster), and then run Flink jobs on the cluster.
You can use your Flink cluster to:
Run Flink jobs using the Dataproc
Jobsresource from the Google Cloud console, Google Cloud CLI, or the Dataproc API.Run Flink jobs using the
flinkCLI running on the Flink cluster master node.
Create a Dataproc Flink cluster
You can use the Google Cloud console, Google Cloud CLI, or the Dataproc API to create a Dataproc cluster that has the Flink component activated on the cluster.
Recommendation: Use a standard 1-master VM cluster with the Flink component. Dataproc High Availability mode clusters (with 3 master VMs) do not support Flink high-availability mode.
Console
To create a Dataproc Flink cluster using the Google Cloud console, perform the following steps:
Open the Dataproc Create a Dataproc cluster on Compute Engine page.
- The Set up cluster panel is selected.
- In the Versioning section, confirm or change the
Image Type and Version. The cluster image version determines the
version of the Flink component installed on the cluster.
- The image version must be 1.5 or higher to activate the Flink component on the cluster (See Supported Dataproc versions to view listings of the component versions included in each Dataproc image release).
- The image version must be [TBD] or higher to run Flink jobs through the Dataproc Jobs API (see Run Dataproc Flink jobs).
- In the Versioning section, confirm or change the
Image Type and Version. The cluster image version determines the
version of the Flink component installed on the cluster.
- In the Components section:
- Under Component Gateway, select Enable component gateway. You must enable the Component Gateway to activate the Component Gateway link to the Flink History Server UI. Enabling the Component Gateway also enables access to the Flink Job Manager web interface running on the Flink cluster.
- Under Optional components, select Flink and other optional components to activate on your cluster.
- The Set up cluster panel is selected.
Click the Customize cluster (optional) panel.
In the Cluster properties section, click Add Properties for each optional cluster property to add to your cluster. You can add
flinkprefixed properties to configure Flink properties in/etc/flink/conf/flink-conf.yamlthat will act as defaults for Flink applications that you run on the cluster.Examples:
- Set
flink:historyserver.archive.fs.dirto specify the Cloud Storage location to write Flink job history files (this location will be used by the Flink History Server running on the Flink cluster). - Set Flink task slots with
flink:taskmanager.numberOfTaskSlots=n.
- Set
In the Custom cluster metadata section, click Add Metadata to add optional metadata. For example, add
flink-start-yarn-sessiontrueto run the Flink YARN daemon (/usr/bin/flink-yarn-daemon) in the background on the cluster master node to start a Flink YARN session (see Flink session mode).
If you are using Dataproc image version 2.0 or earlier, click the Manage security (optional) panel, then, under Project access, select
Enables the cloud-platform scope for this cluster.cloud-platformscope is enabled by default when you create a cluster that uses Dataproc image version 2.1 or later.
Click Create to create the cluster.
gcloud
To create a Dataproc Flink cluster using the gcloud CLI, run the following gcloud dataproc clusters create command locally in a terminal window or in Cloud Shell:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=DATAPROC_IMAGE_VERSION \ --optional-components=FLINK \ --enable-component-gateway \ --properties=PROPERTIES ... other flags
Notes:
- CLUSTER_NAME: Specify the name of the cluster.
- REGION: Specify a Compute Engine region where the cluster will be located.
DATAPROC_IMAGE_VERSION: Optionally specify the image version to use on the cluster. The cluster image version determines the version of the Flink component installed on the cluster.
The image version must be 1.5 or higher to activate the Flink component on the cluster (See Supported Dataproc versions to view listings of the component versions included in each Dataproc image release).
The image version must be [TBD] or higher to run Flink jobs through the Dataproc Jobs API (see Run Dataproc Flink jobs).
--optional-components: You must specify theFLINKcomponent to run Flink jobs and the Flink HistoryServer Web Service on the cluster.--enable-component-gateway: You must enable the Component Gateway to activate the Component Gateway link to Flink History Server UI. Enabling the Component Gateway also enables access to the Flink Job Manager web interface running on the Flink cluster.PROPERTIES. Optionally specify one or more cluster properties.
When creating Dataproc clusters with image versions
2.0.67+ and2.1.15+, you can use the--propertiesflag to to configure Flink properties in/etc/flink/conf/flink-conf.yamlthat will act as defaults for Flink applications that you run on the cluster.You can set
flink:historyserver.archive.fs.dirto specify the Cloud Storage location to write Flink job history files (this location will be used by the Flink History Server running on the Flink cluster).Multiple properties example:
--properties=flink:historyserver.archive.fs.dir=gs://my-bucket/my-flink-cluster/completed-jobs,flink:taskmanager.numberOfTaskSlots=2Other flags:
- You can add the optional
--metadata flink-start-yarn-session=trueflag to run the Flink YARN daemon (/usr/bin/flink-yarn-daemon) in the background on the cluster master node to start a Flink YARN session (see Flink session mode).
- You can add the optional
When using 2.0 or earlier image versions, you can add the
--scopes=https://www.googleapis.com/auth/cloud-platformflag to enable access to Google Cloud APIs by your cluster (see Scopes best practice).cloud-platformscope is enabled by default when you create a cluster that uses Dataproc image version 2.1 or later.
API
To create a Dataproc Flink cluster using the Dataproc API, submit a clusters.create request, as follows:
Notes:
Set the SoftwareConfig.Component to
FLINK.You can optionally set
SoftwareConfig.imageVersionto specify the image version to use on the cluster. The cluster image version determines the version of the Flink component installed on the cluster.The image version must be 1.5 or higher to activate the Flink component on the cluster (See Supported Dataproc versions to view listings of the component versions included in each Dataproc image release).
The image version must be [TBD] or higher to run Flink jobs through the Dataproc Jobs API (see Run Dataproc Flink jobs).
Set EndpointConfig.enableHttpPortAccess to
trueto enable the Component Gateway link to Flink History Server UI. Enabling the Component Gateway also enables access to the Flink Job Manager web interface running on the Flink cluster.You can optionally set
SoftwareConfig.propertiesto specify one or more cluster properties.- You can specify Flink properties that will act as
defaults for Flink applications that you run on the cluster. For example,
you can set the
flink:historyserver.archive.fs.dirto specify the Cloud Storage location to write Flink job history files (this location will be used by the Flink History Server running on the Flink cluster).
- You can specify Flink properties that will act as
defaults for Flink applications that you run on the cluster. For example,
you can set the
You can optionally set:
GceClusterConfig.metadata. for example, to specifyflink-start-yarn-sessiontrueto run the Flink YARN daemon (/usr/bin/flink-yarn-daemon) in the background on the cluster master node to start a Flink YARN session (see Flink session mode).- GceClusterConfig.serviceAccountScopes
to
https://www.googleapis.com/auth/cloud-platform(cloud-platformscope) when using 2.0 or earlier image versions to enable access to Google Cloud APIs by your cluster (see Scopes best practice).cloud-platformscope is enabled by default when you create a cluster that uses Dataproc image version 2.1 or later.
After you create a Flink cluster
- Use the
Flink History Serverlink in the Component Gateway to view the Flink History Server running on the Flink cluster. - Use the
YARN ResourceManager linkin the Component Gateway to view the Flink Job Manager web interface running on the Flink cluster . - Create a Dataproc Persistent History Server to view Flink job history files written by existing and deleted Flink clusters.
Run Flink jobs using the Dataproc Jobs resource
You can run Flink jobs using the Dataproc Jobs resource from the
Google Cloud console, Google Cloud CLI, or Dataproc API.
Console
To submit a sample Flink wordcount job from the console:
Open the Dataproc Submit a job page in the Google Cloud console in your browser.
Fill in the fields on the Submit a job page:
- Select your Cluster name from the cluster list.
- Set Job type to
Flink. - Set Main class or jar to
org.apache.flink.examples.java.wordcount.WordCount. - Set Jar files to
file:///usr/lib/flink/examples/batch/WordCount.jar.file:///denotes a file located on the cluster. Dataproc installed theWordCount.jarwhen it created the Flink cluster.- This field also accepts a Cloud Storage path
(
gs://BUCKET/JARFILE) or a Hadoop Distributed File System (HDFS) path (hdfs://PATH_TO_JAR).
Click Submit.
- Job driver output is displayed on the Job details page.

- Flink jobs are listed on the Dataproc Jobs page in the Google Cloud console.
- Click Stop or Delete from the Jobs or Job details page to stop or delete a job.
gcloud
To submit a Flink job to a Dataproc Flink cluster, run the gcloud CLI gcloud dataproc jobs submit command locally in a terminal window or in Cloud Shell.
gcloud dataproc jobs submit flink \ --cluster=CLUSTER_NAME \ --region=REGION \ --class=MAIN_CLASS \ --jar=JAR_FILE \ -- JOB_ARGS
Notes:
- CLUSTER_NAME: Specify the name of the Dataproc Flink cluster to submit the job to.
- REGION: Specify a Compute Engine region where the cluster is located.
- MAIN_CLASS: Specify the
mainclass of your Flink application, such as:org.apache.flink.examples.java.wordcount.WordCount
- JAR_FILE: Specify the Flink application jar file. You can specify:
- A jar file installed on the cluster, using the
file:///` prefix:file:///usr/lib/flink/examples/streaming/TopSpeedWindowing.jarfile:///usr/lib/flink/examples/batch/WordCount.jar
- A jar file in Cloud Storage:
gs://BUCKET/JARFILE - A jar file in HDFS:
hdfs://PATH_TO_JAR
- A jar file installed on the cluster, using the
JOB_ARGS: Optionally, add job arguments after the double dash (
--).After submitting the job, job driver output is displayed in the local or Cloud Shell terminal.
Program execution finished Job with JobID 829d48df4ebef2817f4000dfba126e0f has finished. Job Runtime: 13610 ms ... (after,1) (and,12) (arrows,1) (ay,1) (be,4) (bourn,1) (cast,1) (coil,1) (come,1)
REST
This section shows how to submit a Flink job to a Dataproc Flink cluster using the Dataproc jobs.submit API.
Before using any of the request data, make the following replacements:
- PROJECT_ID: Google Cloud project ID
- REGION: cluster region
- CLUSTER_NAME: Specify the name of the Dataproc Flink cluster to submit the job to
HTTP method and URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Request JSON body:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
}
}
}
To send your request, expand one of these options:
You should receive a JSON response similar to the following:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "JOB_ID"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "CLUSTER_UUID"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "JOB_UUID"
}
- Flink jobs are listed on the Dataproc Jobs page in the Google Cloud console.
- You can click Stop or Delete from the Jobs or Job details page in the Google Cloud console to stop or delete a job.
Run Flink jobs using the flink CLI
Instead of
running Flink jobs using the Dataproc Jobs resource,
you can run Flink jobs on the master node of your Flink cluster using the flink CLI.
The following sections describe different ways you can run a flink CLI job on
your Dataproc Flink cluster.
SSH into the master node: Use the SSH utility to open a terminal window on the cluster master VM.
Set the classpath: Initialize the Hadoop classpath from the SSH terminal window on the Flink cluster master VM:
export HADOOP_CLASSPATH=$(hadoop classpath)Run Flink jobs: You can run Flink jobs in different deployment modes on YARN: application, per-job, and session mode.
Application mode: Flink Application mode is supported by Dataproc image version 2.0 and later. This mode executes the job's
main()method on the YARN Job Manager. The cluster shuts down after the job finishes.Job submission example:
flink run-application \ -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=2048m \ -Djobmanager.heap.mb=820 \ -Dtaskmanager.heap.mb=1640 \ -Dtaskmanager.numberOfTaskSlots=2 \ -Dparallelism.default=4 \ /usr/lib/flink/examples/batch/WordCount.jarList running jobs:
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YYCancel a running job:
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>Per-job mode: This Flink mode executes the job's
main()method on the client side.Job submission example:
flink run \ -m yarn-cluster \ -p 4 \ -ys 2 \ -yjm 1024m \ -ytm 2048m \ /usr/lib/flink/examples/batch/WordCount.jarSession mode: Start a long-running Flink YARN session, then submit one or more jobs to the session.
Start a session: You can start a Flink session in one of the following ways:
Create a Flink cluster, adding the
--metadata flink-start-yarn-session=trueflag to thegcloud dataproc clusters createcommand (See Create a Dataproc Flink cluster). With this flag enabled, after the cluster is created, Dataproc runs/usr/bin/flink-yarn-daemonto start a Flink session on the cluster.The session's YARN application ID is saved in
/tmp/.yarn-properties-${USER}. You can list the ID with theyarn application -listcommand.Run the Flink
yarn-session.shscript, which is pre-installed on the cluster master VM, with custom settings:Example with custom settings:
/usr/lib/flink/bin/yarn-session.sh \ -s 1 \ -jm 1024m \ -tm 2048m \ -nm flink-dataproc \ --detachedRun the Flink the
/usr/bin/flink-yarn-daemonwrapper script with default settings:. /usr/bin/flink-yarn-daemon
Submit a job to a session: Run the following command to submit a Flink job to the session.
flink run -m <var>FLINK_MASTER_URL</var>/usr/lib/flink/examples/batch/WordCount.jar- FLINK_MASTER_URL: the URL, including host
and port, of the Flink master VM where jobs are executed.
Remove the
http:// prefixfrom the URL. This URL is listed in the command output when you start a Flink session. You can run the following command to list this URL in theTracking-URLfield:
yarn application -list -appId=<yarn-app-id> | sed 's#http://##' ```- FLINK_MASTER_URL: the URL, including host
and port, of the Flink master VM where jobs are executed.
Remove the
List jobs in a session: To list Flink jobs in a session, do one of the following:
Run
flink listwithout arguments. The command looks for the the session's YARN application ID in/tmp/.yarn-properties-${USER}.Obtain the YARN application ID of the session from
/tmp/.yarn-properties-${USER}or the output ofyarn application -list, and then run<code>flink list -yid YARN_APPLICATION_ID.Run
flink list -m FLINK_MASTER_URL.
Stop a session: To stop the session, obtain the YARN application ID of the session from
/tmp/.yarn-properties-${USER}or the output ofyarn application -list, then run either of the following commands:echo "stop" | /usr/lib/flink/bin/yarn-session.sh -id YARN_APPLICATION_IDyarn application -kill YARN_APPLICATION_ID
Run Apache Beam jobs on Flink
You can run Apache Beam jobs on
Dataproc using the
FlinkRunner.
You can run Beam jobs on Flink in the following ways:
- Java Beam jobs
- Portable Beam jobs
Java Beam jobs
Package your Beam jobs into a JAR file. Supply the bundled JAR file with the dependencies needed to run the job.
The following example runs a Java Beam job from the Dataproc cluster's master node.
Create a Dataproc cluster with the Flink component enabled.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platform--optional-components: Flink.--image-version: the cluster's image version, which determines the Flink version installed on the cluster (for example, see the Apache Flink component versions listed for the latest and previous four 2.0.x image release versions).--region: a supported Dataproc region.--enable-component-gateway: enable access to the Flink Job Manager UI.--scopes: enable access to Google Cloud APIs by your cluster (see Scopes best practice).cloud-platformscope is enabled by default (you do not need to include this flag setting) when you create a cluster that uses Dataproc image version 2.1 or later.
Use the SSH utility to open a terminal window on the Flink cluster master node.
Start a Flink YARN session on the Dataproc cluster master node.
. /usr/bin/flink-yarn-daemonTake note of the Flink version on your Dataproc cluster.
flink --versionOn your local machine, generate the canonical Beam word count example in Java.
Choose a Beam version that is compatible with the Flink version on your Dataproc cluster. See the Flink Version Compatibility table that lists Beam-Flink version compatibility.
Open the generated POM file. Check the Beam Flink runner version specified by the tag
<flink.artifact.name>. If the Beam Flink runner version in the Flink artifact name does not match the Flink version on your cluster, update the version number to match.mvn archetype:generate \ -DarchetypeGroupId=org.apache.beam \ -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \ -DarchetypeVersion=BEAM_VERSION \ -DgroupId=org.example \ -DartifactId=word-count-beam \ -Dversion="0.1" \ -Dpackage=org.apache.beam.examples \ -DinteractiveMode=falsePackage the word count example.
mvn package -Pflink-runnerUpload the packaged uber JAR file,
word-count-beam-bundled-0.1.jar(~135 MB) to your Dataproc cluster's master node. You can usegcloud storage cpfor faster file transfers to your Dataproc cluster from Cloud Storage.On your local terminal, create a Cloud Storage bucket, and upload the uber JAR.
gcloud storage buckets create BUCKET_NAMEgcloud storage cp target/word-count-beam-bundled-0.1.jar gs://BUCKET_NAME/On your Dataproc's master node, download the uber JAR.
gcloud storage cp gs://BUCKET_NAME/word-count-beam-bundled-0.1.jar .
Run the Java Beam job on the Dataproc cluster's master node.
flink run -c org.apache.beam.examples.WordCount word-count-beam-bundled-0.1.jar \ --runner=FlinkRunner \ --output=gs://BUCKET_NAME/java-wordcount-outCheck that the results were written to your Cloud Storage bucket.
gcloud storage cat gs://BUCKET_NAME/java-wordcount-out-SHARD_IDStop the Flink YARN session.
yarn application -listyarn application -kill YARN_APPLICATION_ID
Portable Beam Jobs
To run Beam jobs written in Python, Go, and other supported languages, you can
use the FlinkRunner and PortableRunner as described on the Beam's
Flink Runner
page (also see Portability Framework Roadmap).
The following example runs a portable Beam job in Python from the Dataproc cluster's master node.
Create a Dataproc cluster with both the Flink and Docker components enabled.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK,DOCKER \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platformNotes:
--optional-components: Flink and Docker.--image-version: The cluster's image version, which determines the Flink version installed on the cluster (for example, see the Apache Flink component versions listed for the latest and previous four 2.0.x image release versions).--region: An available Dataproc region.--enable-component-gateway: Enable access to the Flink Job Manager UI.--scopes: Enable access to Google Cloud APIs by your cluster (see Scopes best practice).cloud-platformscope is enabled by default (you do not need to include this flag setting) when you create a cluster that uses Dataproc image version 2.1 or later.
Use the gcloud CLI locally or in Cloud Shell to create a Cloud Storage bucket. You will specify the BUCKET_NAME when you run a sample wordcount program.
gcloud storage buckets create BUCKET_NAMEIn a terminal window on the cluster VM, start a Flink YARN session. Note the Flink master URL, the address of the Flink master where jobs are executed.. You will specify the FLINK_MASTER_URL when you run a sample wordcount program.
. /usr/bin/flink-yarn-daemonDisplay and note the Flink version running the Dataproc cluster. You will specify the FLINK_VERSION when you run a sample wordcount program.
flink --versionInstall Python libraries needed for the job on the cluster master node.
Install a Beam version that is compatible with the Flink version on the cluster.
python -m pip install apache-beam[gcp]==BEAM_VERSIONRun the word count example on the cluster master node.
python -m apache_beam.examples.wordcount \ --runner=FlinkRunner \ --flink_version=FLINK_VERSION \ --flink_master=FLINK_MASTER_URL --flink_submit_uber_jar \ --output=gs://BUCKET_NAME/python-wordcount-outNotes:
--runner:FlinkRunner.--flink_version: FLINK_VERSION, noted earlier.--flink_master: FLINK_MASTER_URL, noted earlier.--flink_submit_uber_jar: Use the uber JAR to execute the Beam job.--output: BUCKET_NAME, created earlier.
Verify that results were written to your bucket.
gcloud storage cat gs://BUCKET_NAME/python-wordcount-out-SHARD_IDStop the Flink YARN session.
- Get the application ID.
yarn application -list1. Insert the <var>YARN_APPLICATION_ID</var>, then stop the session.yarn application -kill
Run Flink on a Kerberized cluster
The Dataproc Flink component supports Kerberized clusters. A valid Kerberos ticket is needed to submit and persist a Flink job or to start a Flink cluster. By default, a Kerberos ticket remains valid for seven days.
Access the Flink Job Manager UI
The Flink Job Manager web interface is available while a Flink job or Flink session cluster is running. To use the web interface:
- Create a Dataproc Flink cluster.
- After cluster creation, click the Component Gateway YARN ResourceManager link on the Web Interface tab on the Cluster details page in the Google Cloud console.
- On the YARN Resource Manager UI, identify the Flink cluster application
entry. Depending on a job's completion status, an ApplicationMaster
or History link will be listed.
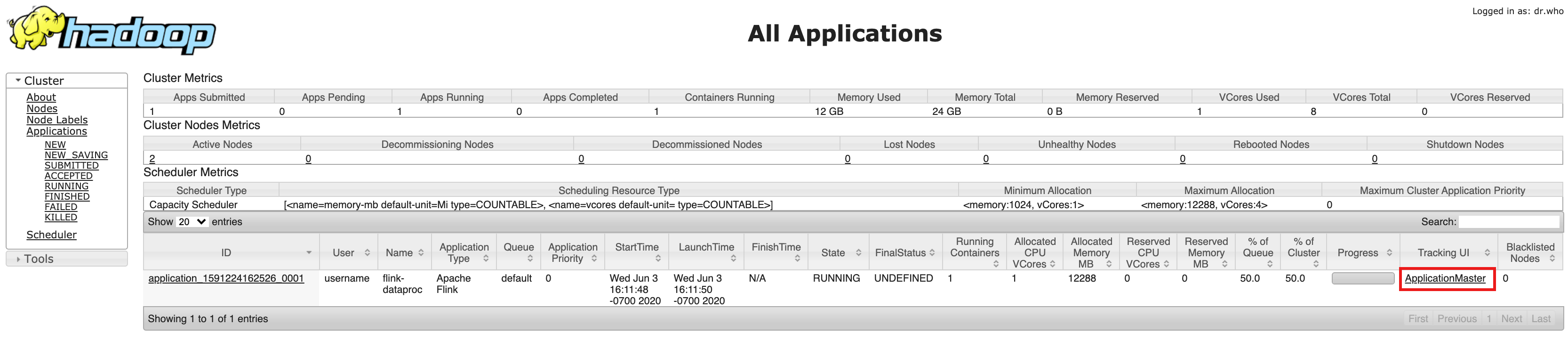
- For a long-running streaming job, click the ApplicationManager link to
open the Flink dashboard; for a completed job, click the History link
to view job details.
