Ce document explique comment installer et utiliser l'extension JupyterLab sur une machine ou une VM autogérée ayant accès aux services Google. Il explique également comment développer et déployer du code de notebook Spark sans serveur.
Installez l'extension en quelques minutes pour profiter des fonctionnalités suivantes :
- Lancez des notebooks Spark sans serveur et BigQuery pour développer du code rapidement.
- Parcourir et prévisualiser les ensembles de données BigQuery dans JupyterLab
- Modifier des fichiers Cloud Storage dans JupyterLab
- Planifier un notebook sur Composer
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
-
Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
-
Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init Téléchargez et installez Python version 3.11 ou ultérieure depuis
python.org/downloads.- Vérifiez l'installation de Python 3.11 ou version ultérieure.
python3 --version
- Vérifiez l'installation de Python 3.11 ou version ultérieure.
Virtualisez l'environnement Python.
pip3 install pipenv
- Créez un dossier d'installation.
mkdir jupyter
- Accédez au dossier d'installation.
cd jupyter
- Créez un environnement virtuel.
pipenv shell
- Créez un dossier d'installation.
Installez JupyterLab dans l'environnement virtuel.
pipenv install jupyterlab
Installez l'extension JupyterLab.
pipenv install bigquery-jupyter-plugin
jupyter lab
La page Lanceur d'applications de JupyterLab s'ouvre dans votre navigateur. Il contient une section Jobs et sessions Dataproc. Il peut également contenir des sections Notebooks Serverless pour Apache Spark et Notebooks de cluster Dataproc si vous avez accès à des notebooks Dataproc sans serveur ou à des clusters Dataproc avec le composant Jupyter facultatif en cours d'exécution dans votre projet.
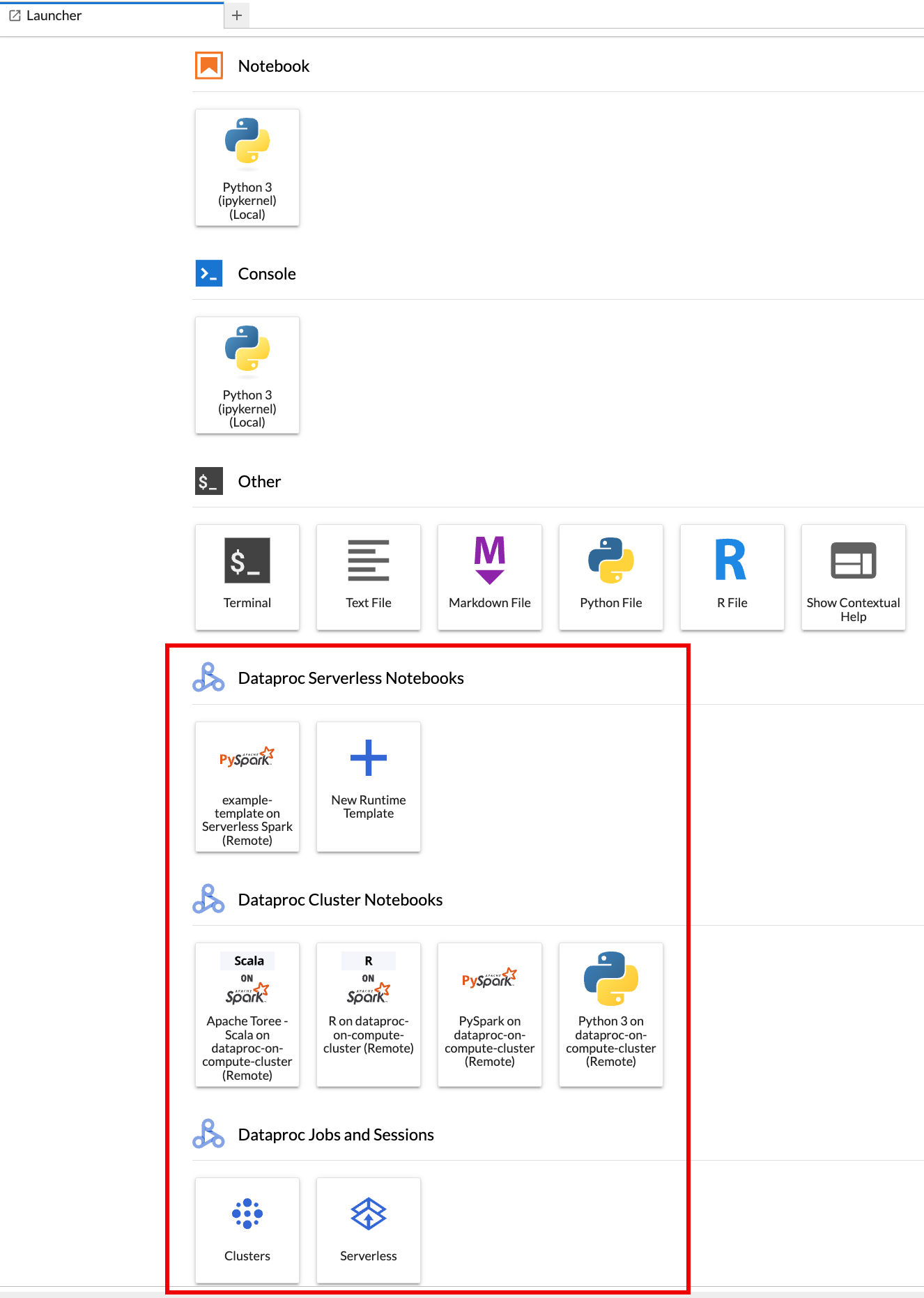
Par défaut, votre session interactive Serverless pour Apache Spark s'exécute dans le projet et la région que vous avez définis lorsque vous avez exécuté
gcloud initdans Avant de commencer. Vous pouvez modifier les paramètres de projet et de région de vos sessions depuis JupyterLab Settings > Google Cloud Settings > Google Cloud Project Settings (Paramètres > Google Cloud Paramètres > Google Cloud Paramètres du projet).Vous devez redémarrer l'extension pour que les modifications prennent effet.
Cliquez sur la fiche
New runtime templatedans la section Notebooks sans serveur pour Apache Spark de la page Launcher (Lanceur d'applications) de JupyterLab.
Remplissez le formulaire Modèle d'exécution.
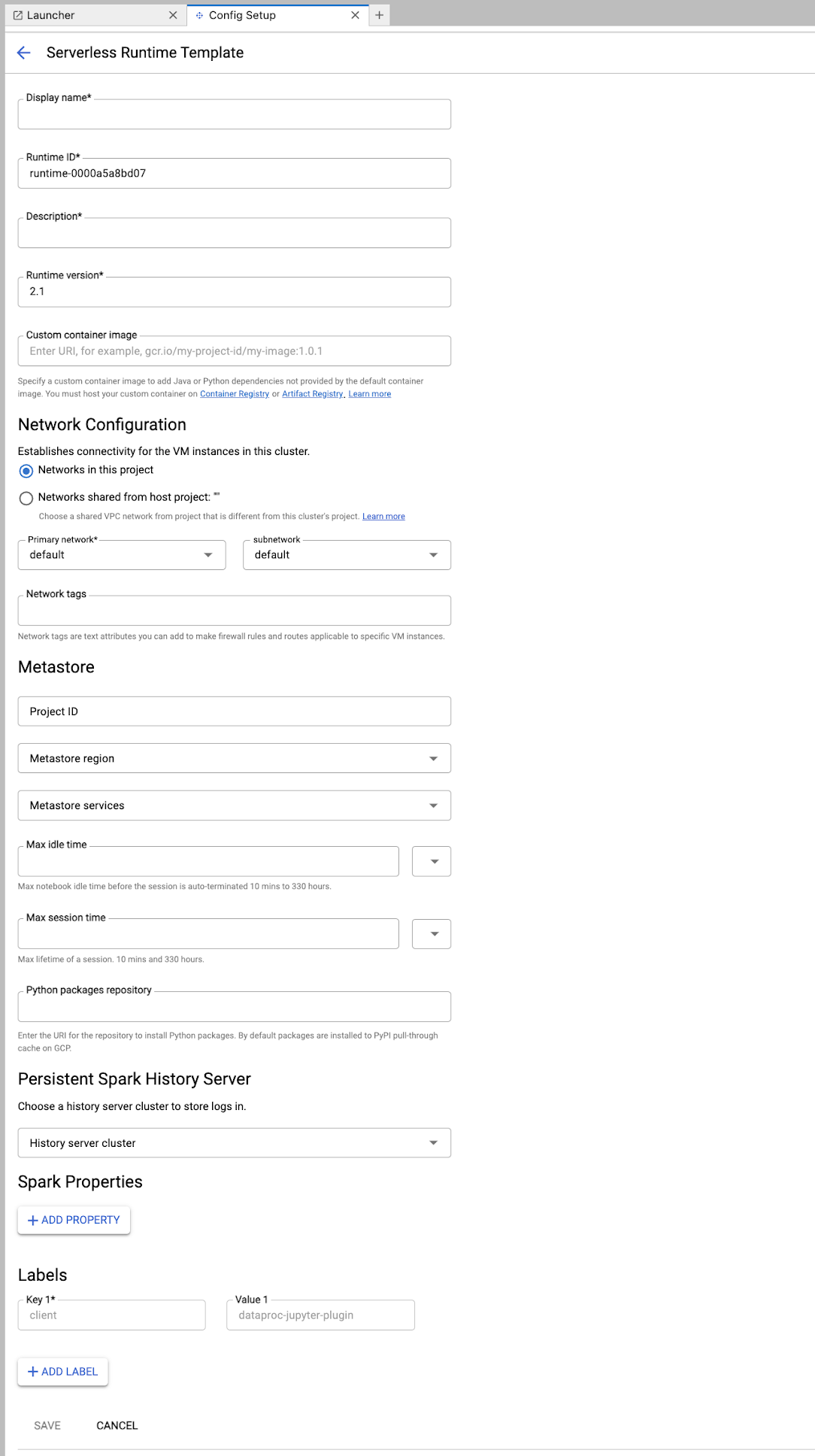
Informations sur le modèle :
- Nom à afficher, ID d'exécution et Description : acceptez ou renseignez le nom à afficher, l'ID d'exécution et la description du modèle.
Configuration de l'exécution : sélectionnez Compte utilisateur pour exécuter les notebooks avec l'identité de l'utilisateur au lieu de celle du compte de service Dataproc.
- Compte de service : si vous ne spécifiez pas de compte de service, le compte de service Compute Engine par défaut est utilisé.
- Version de l'environnement d'exécution : confirmez ou sélectionnez la version de l'environnement d'exécution.
- Image de conteneur personnalisée : vous pouvez spécifier l'URI d'une image de conteneur personnalisée.
- Bucket de préproduction : vous pouvez éventuellement spécifier le nom d'un bucket de préproduction Cloud Storage à utiliser par Serverless pour Apache Spark.
- Dépôt de packages Python : par défaut, les packages Python sont téléchargés et installés à partir du cache d'extraction PyPI lorsque les utilisateurs exécutent des commandes d'installation
pipdans leurs notebooks. Vous pouvez spécifier le dépôt d'artefacts privés de votre organisation pour les packages Python à utiliser comme dépôt de packages Python par défaut.
Chiffrement : acceptez la valeur par défaut Google-owned and Google-managed encryption key ou sélectionnez Clé de chiffrement gérée par le client (CMEK). Si vous utilisez CMEK, sélectionnez ou fournissez les informations sur la clé.
Configuration réseau : sélectionnez un sous-réseau dans le projet ou partagé à partir d'un projet hôte (vous pouvez modifier le projet dans JupyterLab : Paramètres > Google Cloud Paramètres > Google Cloud Paramètres du projet). Vous pouvez spécifier des tags réseau à appliquer au réseau spécifié. Notez que Serverless pour Apache Spark active l'accès privé à Google sur le sous-réseau spécifié. Pour connaître les exigences en matière de connectivité réseau, consultez Configuration du réseauGoogle Cloud Serverless pour Apache Spark.
Configuration de la session : vous pouvez éventuellement remplir ces champs pour limiter la durée des sessions créées avec le modèle.
- Durée d'inactivité maximale : durée d'inactivité maximale avant l'arrêt de la session. Plage autorisée : de 10 minutes à 336 heures (14 jours).
- Durée maximale de la session : durée de vie maximale d'une session avant son interruption. Plage autorisée : de 10 minutes à 336 heures (14 jours).
Metastore : pour utiliser un service Dataproc Metastore avec vos sessions, sélectionnez l'ID du projet et le service de métastore.
Serveur d'historique persistant : vous pouvez sélectionner un serveur d'historique Spark persistant disponible pour accéder aux journaux de session pendant et après les sessions.
Propriétés Spark : vous pouvez sélectionner et ajouter des propriétés Spark Resource Allocation (Allocation de ressources), Autoscaling (Autoscaling) ou GPU. Cliquez sur Ajouter une propriété pour ajouter d'autres propriétés Spark. Pour en savoir plus, consultez Propriétés Spark.
Libellés : cliquez sur Ajouter un libellé pour chaque libellé à définir sur les sessions créées avec le modèle.
Cliquez sur Enregistrer pour créer le modèle.
Pour afficher ou supprimer un modèle d'environnement d'exécution.
- Cliquez sur Paramètres > Google Cloud Paramètres.
La section Paramètres Dataproc > Modèles d'exécution sans serveur affiche la liste des modèles d'exécution.
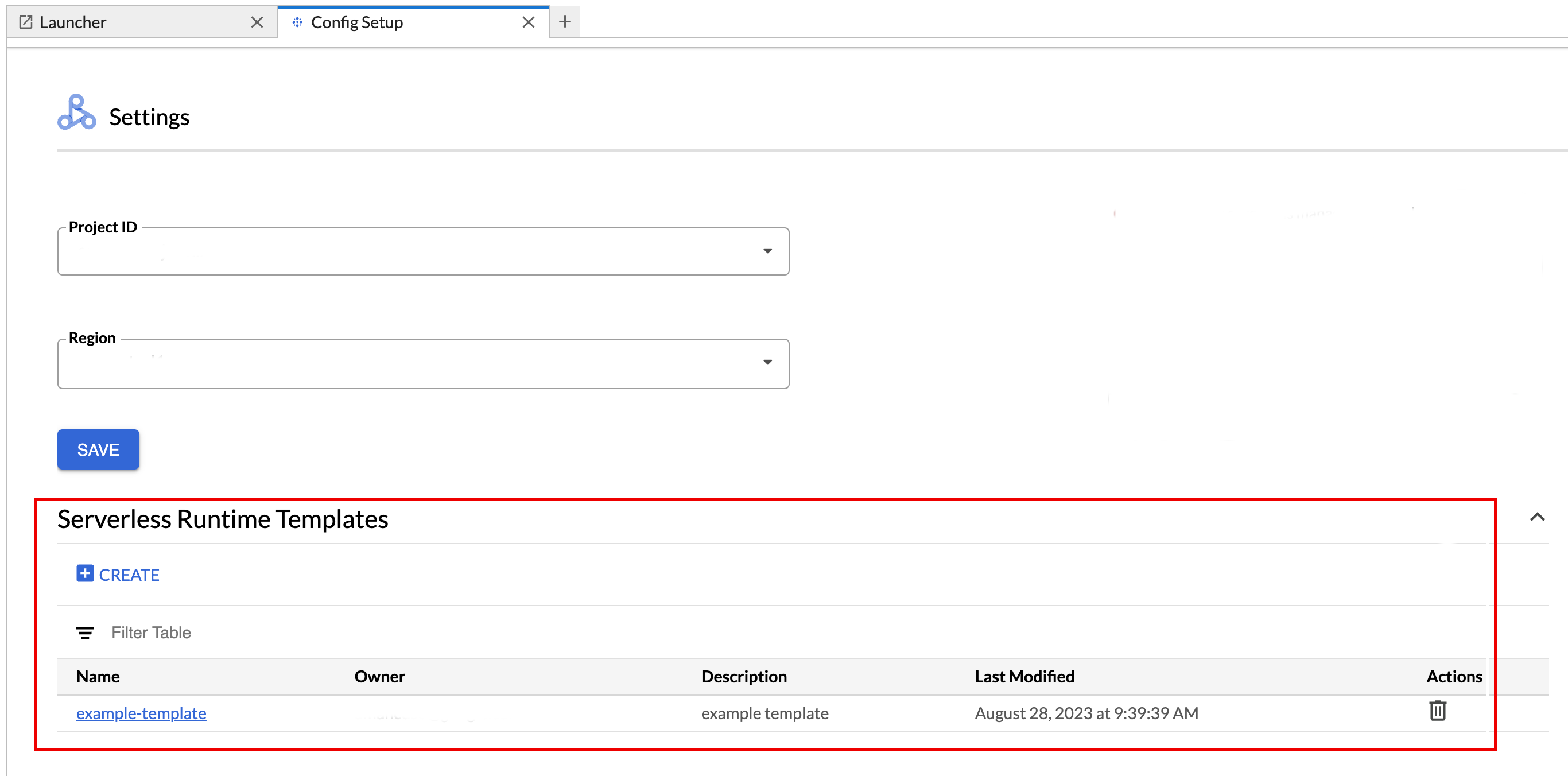
- Cliquez sur le nom d'un modèle pour afficher ses détails.
- Vous pouvez supprimer un modèle à partir du menu Action du modèle.
Ouvrez et rechargez la page Lanceur d'applications de JupyterLab pour afficher la fiche du modèle de notebook enregistré sur la page Lanceur d'applications de JupyterLab.

Créez un fichier YAML avec la configuration de votre modèle d'exécution.
YAML simple
environmentConfig: executionConfig: networkUri: default jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing description: Team A Development Environment
YAML complexe
description: Example session template environmentConfig: executionConfig: serviceAccount: sa1 # Choose either networkUri or subnetworkUri networkUri: subnetworkUri: default networkTags: - tag1 kmsKey: key1 idleTtl: 3600s ttl: 14400s stagingBucket: staging-bucket peripheralsConfig: metastoreService: projects/my-project-id/locations/us-central1/services/my-metastore-id sparkHistoryServerConfig: dataprocCluster: projects/my-project-id/regions/us-central1/clusters/my-cluster-id jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing runtimeConfig: version: "2.3" containerImage: gcr.io/my-project-id/my-image:1.0.1 properties: "p1": "v1" description: Team A Development Environment
Créez un modèle de session (d'exécution) à partir de votre fichier YAML en exécutant la commande gcloud beta dataproc session-templates import suivante en local ou dans Cloud Shell :
gcloud beta dataproc session-templates import TEMPLATE_ID \ --source=YAML_FILE \ --project=PROJECT_ID \ --location=REGION
- Consultez gcloud beta dataproc session-templates pour obtenir des commandes permettant de décrire, lister, exporter et supprimer des modèles de session.
Lancez un notebook Jupyter sur Serverless pour Apache Spark.
Lancez un notebook Jupyter sur un cluster Dataproc sur Compute Engine.
Cliquez sur une fiche pour créer une session Serverless pour Apache Spark et lancer un notebook. Lorsque la création de la session est terminée et que le kernel associé au notebook est prêt à être utilisé, l'état du kernel passe de
StartingàIdle (Ready).Écrivez et testez le code du notebook.
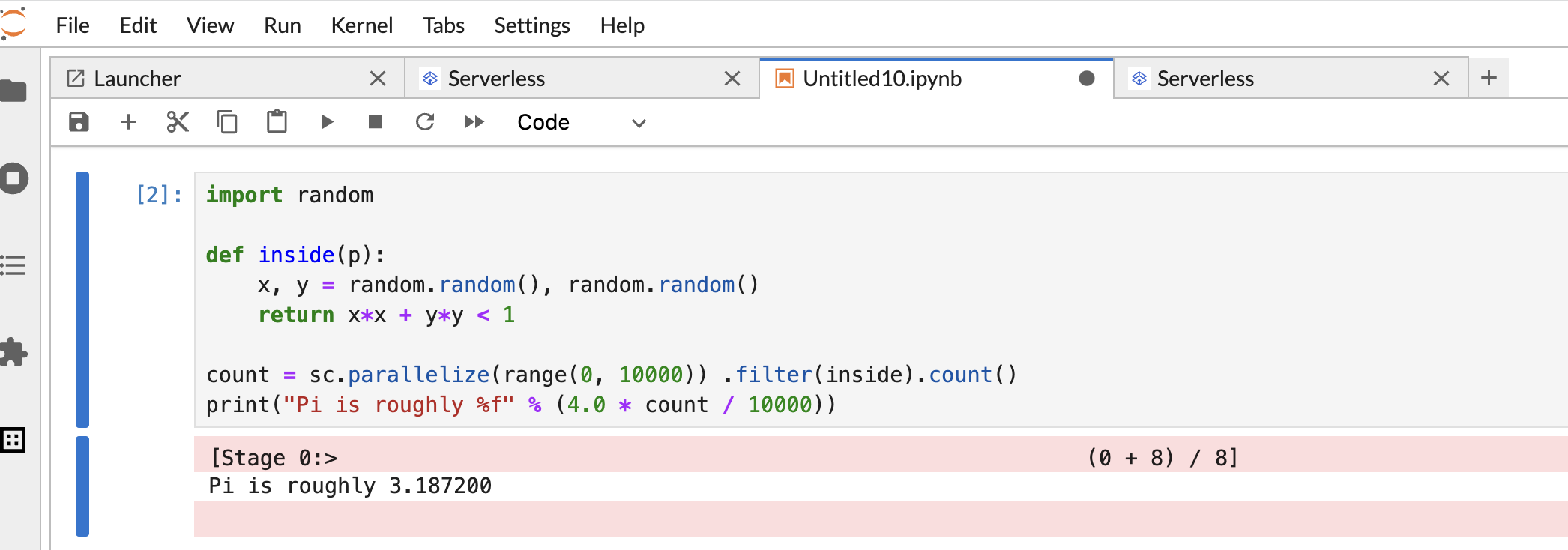
Copiez et collez le code
Pi estimationPySpark suivant dans la cellule du notebook PySpark, puis appuyez sur Maj+Entrée pour exécuter le code.import random def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 count = sc.parallelize(range(0, 10000)) .filter(inside).count() print("Pi is roughly %f" % (4.0 * count / 10000))
Résultat du notebook :
Après avoir créé et utilisé un notebook, vous pouvez mettre fin à la session associée en cliquant sur Shut Down Kernel (Arrêter le kernel) dans l'onglet Kernel (Kernel).
- Pour réutiliser la session, créez un notebook en sélectionnant Notebook dans le menu File >> New (Fichier >> Nouveau). Une fois le notebook créé, sélectionnez la session existante dans la boîte de dialogue de sélection du noyau. Le nouveau notebook réutilisera la session et conservera le contexte de session du notebook précédent.
Si vous ne mettez pas fin à la session, Dataproc s'en chargera une fois que le minuteur d'inactivité de la session sera arrivé à zéro. Vous pouvez définir le délai d'inactivité d'une session dans la configuration du modèle d'exécution. Par défaut, ce délai est d'une heure.
Cliquez sur une fiche dans la section Notebook du cluster Dataproc.
Lorsque l'état du noyau passe de
StartingàIdle (Ready), vous pouvez commencer à écrire et à exécuter du code de notebook.Après avoir créé et utilisé un notebook, vous pouvez mettre fin à la session associée en cliquant sur Shut Down Kernel (Arrêter le kernel) dans l'onglet Kernel (Kernel).
Pour accéder au navigateur Cloud Storage, cliquez sur l'icône du navigateur Cloud Storage dans la barre latérale de la page Lanceur de JupyterLab, puis double-cliquez sur un dossier pour afficher son contenu.
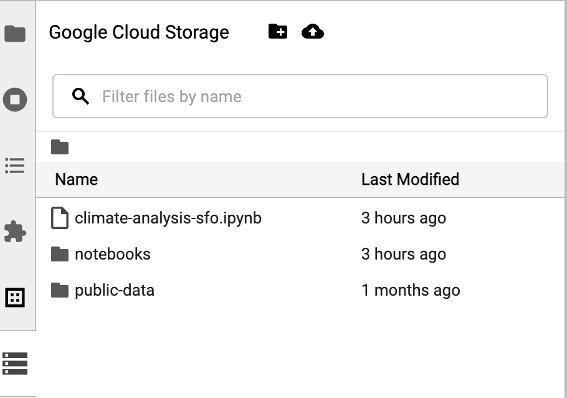
Vous pouvez cliquer sur les types de fichiers compatibles avec Jupyter pour les ouvrir et les modifier. Lorsque vous enregistrez les modifications apportées aux fichiers, elles sont écrites dans Cloud Storage.
Pour créer un dossier Cloud Storage, cliquez sur l'icône Nouveau dossier, puis saisissez le nom du dossier.
Pour importer des fichiers dans un bucket ou un dossier Cloud Storage, cliquez sur l'icône d'importation, puis sélectionnez les fichiers à importer.
Cliquez sur une fiche PySpark dans la section Notebooks Serverless pour Apache Spark ou Notebooks de cluster Dataproc de la page Lanceur de JupyterLab pour ouvrir un notebook PySpark.
Cliquez sur une fiche de noyau Python dans la section Notebook de cluster Dataproc de la page Lanceur de JupyterLab pour ouvrir un notebook Python.
Cliquez sur la fiche Apache Toree dans la section Notebooks de cluster Dataproc de la page Lanceur d'applications JupyterLab pour ouvrir un notebook permettant de développer du code Scala.

Figure 1 : Fiche du noyau Apache Toree sur la page du lanceur d'applications JupyterLab. - Développez et exécutez du code Spark dans des notebooks Serverless pour Apache Spark.
- Créez et gérez des modèles de temps d'exécution (session) Serverless pour Apache Spark, des sessions interactives et des charges de travail par lot.
- Développer et exécuter des notebooks BigQuery.
- Parcourir, inspecter et prévisualiser les ensembles de données BigQuery
- Téléchargez et installez VS Code.
- Ouvrez VS Code, puis cliquez sur Extensions dans la barre d'activité.
Dans la barre de recherche, recherchez l'extension Jupyter, puis cliquez sur Install (Installer). L'extension Jupyter de Microsoft est une dépendance requise.

- Ouvrez VS Code, puis cliquez sur Extensions dans la barre d'activité.
Dans la barre de recherche, recherchez l'extension Google Cloud Code, puis cliquez sur Installer.

Si vous y êtes invité, redémarrez VS Code.
- Ouvrez VS Code, puis dans la barre d'activité, cliquez sur Google Cloud Code.
- Ouvrez la section Dataproc.
- Cliquez sur Se connecter à Google Cloud. Vous êtes redirigé pour vous connecter avec vos identifiants.
- Utilisez la barre des tâches de niveau supérieur de l'application pour accéder à Code > Paramètres > Paramètres > Extensions.
- Recherchez Google Cloud Code, puis cliquez sur l'icône Gérer pour ouvrir le menu.
- Sélectionnez Paramètres.
- Dans les champs Projet et Région Dataproc, saisissez le nom du projet Google Cloud et de la région à utiliser pour développer des notebooks et gérer les ressources Serverless pour Apache Spark.
- Ouvrez VS Code, puis dans la barre d'activité, cliquez sur Google Cloud Code.
- Ouvrez la section Notebooks, puis cliquez sur New Serverless Spark Notebook (Nouveau notebook Spark sans serveur).
- Sélectionnez ou créez un modèle d'exécution (session) à utiliser pour la session de notebook.
Un fichier
.ipynbcontenant un exemple de code est créé et ouvert dans l'éditeur.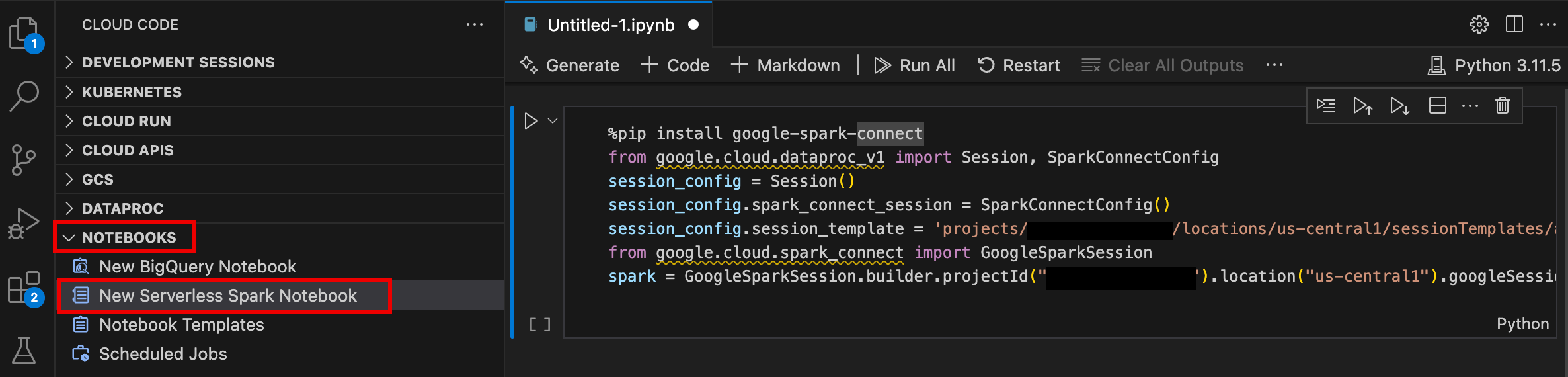
Vous pouvez désormais écrire et exécuter du code dans votre notebook Serverless pour Apache Spark.
- Ouvrez VS Code, puis dans la barre d'activité, cliquez sur Google Cloud Code.
Ouvrez la section Dataproc, puis cliquez sur les noms de ressources suivants :
- Clusters : créez et gérez des clusters et des jobs.
- Sans serveur : créez et gérez des charges de travail par lot et des sessions interactives.
- Modèles d'exécution Spark : créez et gérez des modèles de session.

Exécuter le code de votre notebook sur l'infrastructure Google Cloud Serverless pour Apache Spark
Planifier l'exécution d'un notebook sur Cloud Composer
Envoyez des jobs par lot à l'infrastructure Google Cloud Serverless pour Apache Spark ou à votre cluster Dataproc sur Compute Engine.
Cliquez sur le bouton Planificateur de tâches en haut à droite du notebook.

Remplissez le formulaire Create A Scheduled Job (Créer un job planifié) pour fournir les informations suivantes :
- Nom unique du job d'exécution du notebook
- Environnement Cloud Composer à utiliser pour déployer le notebook
- Paramètres d'entrée si le notebook est paramétré
- Le cluster Dataproc ou le modèle d'exécution sans serveur à utiliser pour exécuter le notebook
- Si un cluster est sélectionné, indique si le cluster doit être arrêté une fois l'exécution du notebook terminée sur le cluster.
- Nombre de nouvelles tentatives et délai entre les tentatives en minutes si l'exécution du notebook échoue lors de la première tentative
- Notifications d'exécution à envoyer et liste des destinataires. Les notifications sont envoyées à l'aide d'une configuration SMTP Airflow.
- Programmation de l'exécution du notebook
Cliquez sur Créer.
Une fois le notebook planifié, le nom du job apparaît dans la liste des jobs planifiés de l'environnement Cloud Composer.

Cliquez sur la fiche Sans serveur dans la section Jobs et sessions Dataproc de la page Lanceur d'applications JupyterLab.
Cliquez sur l'onglet Lot, puis sur Créer un lot et remplissez les champs Informations sur le lot.
Cliquez sur Envoyer pour envoyer le job.
Cliquez sur la fiche Clusters dans la section Tâches et sessions Dataproc de la page Lanceur d'applications JupyterLab.
Cliquez sur l'onglet Tâches, puis sur Envoyer une tâche.
Sélectionnez un cluster, puis renseignez les champs Job.
Cliquez sur Envoyer pour envoyer le job.
- Cliquez sur la fiche Sans serveur.
- Cliquez sur l'onglet Sessions, puis sur un ID de session pour ouvrir la page Détails de la session. Vous pourrez ainsi afficher les propriétés de la session, consulter les journaux Google Cloud dans l'explorateur de journaux et mettre fin à une session. Remarque : Une session Google Cloud Serverless pour Apache Spark unique est créée pour lancer chaque notebook Google Cloud Serverless pour Apache Spark.
- Cliquez sur l'onglet Lots pour afficher la liste des lots Google Cloud Serverless pour Apache Spark dans le projet et la région actuels. Cliquez sur un ID de lot pour afficher les détails du lot.
- Cliquez sur la carte Clusters. L'onglet Clusters est sélectionné pour lister les clusters Dataproc on Compute Engine actifs dans le projet et la région actuels. Vous pouvez cliquer sur les icônes de la colonne Actions pour démarrer, arrêter ou redémarrer un cluster. Cliquez sur le nom d'un cluster pour afficher ses détails. Vous pouvez cliquer sur les icônes de la colonne Actions pour cloner, arrêter ou supprimer un job.
- Cliquez sur la fiche Jobs pour afficher la liste des jobs dans le projet actuel. Cliquez sur l'ID d'une tâche pour afficher ses détails.
Installer l'extension JupyterLab
Vous pouvez installer et utiliser l'extension JupyterLab sur une machine ou une VM ayant accès aux services Google, comme votre machine locale ou une instance de VM Compute Engine.
Pour installer l'extension, procédez comme suit :
Créer un modèle d'exécution Serverless pour Apache Spark
Les modèles d'exécution Serverless pour Apache Spark (également appelés modèles de session) contiennent des paramètres de configuration pour l'exécution du code Spark dans une session. Vous pouvez créer et gérer des modèles d'exécution à l'aide de JupyterLab ou de la gcloud CLI.
JupyterLab
gcloud
Lancer et gérer des notebooks
Après avoir installé l'extension Dataproc JupyterLab, vous pouvez cliquer sur les cartes de modèles sur la page Lanceur d'applications de JupyterLab pour :
Lancer un notebook Jupyter sur Serverless pour Apache Spark
La section Notebooks Serverless pour Apache Spark de la page du lanceur d'applications JupyterLab affiche des fiches de modèles de notebooks qui correspondent aux modèles d'exécution Serverless pour Apache Spark (voir Créer un modèle d'exécution Serverless pour Apache Spark).

Lancer un notebook sur un cluster Dataproc sur Compute Engine
Si vous avez créé un cluster Jupyter Dataproc sur Compute Engine, la page Lanceur d'applications de JupyterLab contient une section Notebook de cluster Dataproc avec des fiches de kernels préinstallées.
Pour lancer un notebook Jupyter sur votre cluster Dataproc sur Compute Engine :
Gérer les fichiers d'entrée et de sortie dans Cloud Storage
L'analyse exploratoire des données et la création de modèles de ML impliquent souvent des entrées et des sorties basées sur des fichiers. Serverless pour Apache Spark accède à ces fichiers sur Cloud Storage.
Développer du code de notebook Spark
Après avoir installé l'extension Dataproc JupyterLab, vous pouvez lancer des notebooks Jupyter depuis la page Lanceur de JupyterLab pour développer le code de l'application.
Développement de code PySpark et Python
Serverless pour Apache Spark et les clusters Dataproc sur Compute Engine sont compatibles avec les kernels PySpark. Dataproc sur Compute Engine est également compatible avec les kernels Python.
Développement de code SQL
Pour ouvrir un notebook PySpark afin d'écrire et d'exécuter du code SQL, sur la page Lanceur de JupyterLab, dans la section Notebooks Serverless pour Apache Spark ou Notebooks de cluster Dataproc, cliquez sur la fiche du noyau PySpark.
Magic Spark SQL : comme le noyau PySpark qui lance les notebooks Serverless pour Apache Spark est préchargé avec le magic Spark SQL, vous pouvez taper %%sparksql magic en haut d'une cellule, puis taper votre instruction SQL dans la cellule, au lieu d'utiliser spark.sql('SQL STATEMENT').show() pour encapsuler votre instruction SQL.
SQL BigQuery : le connecteur BigQuery Spark permet au code de votre notebook de charger des données à partir de tables BigQuery, d'effectuer des analyses dans Spark, puis d'écrire les résultats dans une table BigQuery.
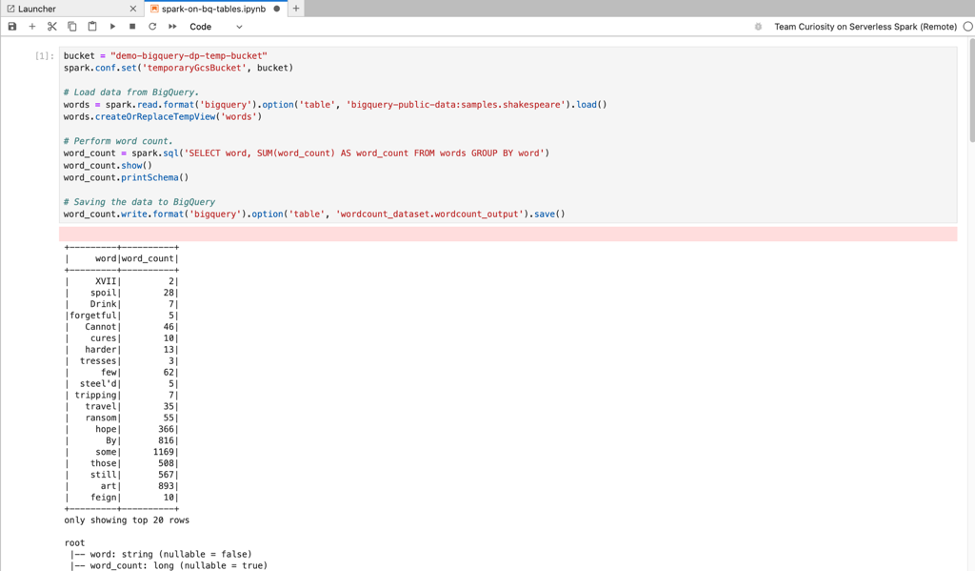
Les environnements d'exécution Serverless pour Apache Spark 2.2 et versions ultérieures incluent le connecteur BigQuery Spark.
Si vous utilisez une version d'exécution antérieure pour lancer des notebooks Serverless pour Apache Spark, vous pouvez installer le connecteur Spark BigQuery en ajoutant la propriété Spark suivante à votre modèle d'exécution Serverless pour Apache Spark :
spark.jars: gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.25.2.jar
Développement de code Scala
Les clusters Dataproc sur Compute Engine créés avec les versions d'image 2.0 et ultérieures incluent Apache Toree, un kernel Scala pour la plate-forme Jupyter Notebook qui fournit un accès interactif à Spark.
Développer du code avec l'extension Visual Studio Code
L'extension Google Cloud Visual Studio Code (VS Code) vous permet d'effectuer les opérations suivantes :
L'extension Visual Studio Code est gratuite, mais vous êtes facturé pour tous les servicesGoogle Cloud , y compris les ressources Dataproc, Serverless pour Apache Spark et Cloud Storage que vous utilisez.
Utiliser VS Code avec BigQuery : vous pouvez également utiliser VS Code avec BigQuery pour effectuer les opérations suivantes :
Avant de commencer
Installer l'extension Google Cloud
L'icône Google Cloud Code est désormais visible dans la barre d'activité de VS Code.
Configurer l'extension
Développer des notebooks Serverless pour Apache Spark
Créer et gérer des ressources Serverless pour Apache Spark
Explorateur d'ensembles de données
Utilisez l'explorateur d'ensembles de données JupyterLab pour afficher les ensembles de données BigLake Metastore.
Pour ouvrir l'explorateur d'ensembles de données JupyterLab, cliquez sur son icône dans la barre latérale.
Vous pouvez rechercher une base de données, une table ou une colonne dans l'explorateur d'ensembles de données. Cliquez sur le nom d'une base de données, d'une table ou d'une colonne pour afficher les métadonnées associées.
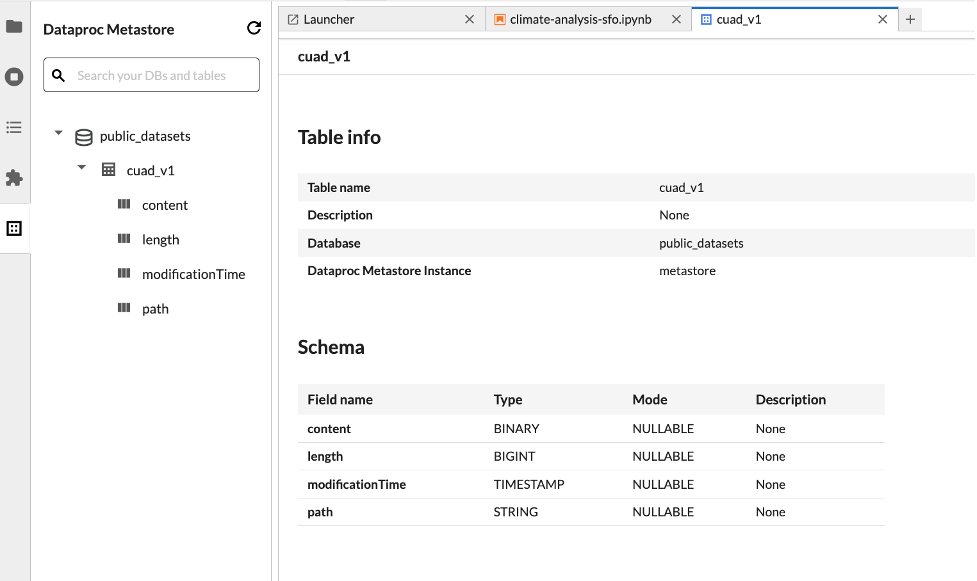
Déployer votre code
Après avoir installé l'extension Dataproc JupyterLab, vous pouvez utiliser JupyterLab pour :
Planifier l'exécution d'un notebook sur Cloud Composer
Procédez comme suit pour planifier l'exécution de votre code de notebook sur Cloud Composer en tant que job par lot sur Serverless pour Apache Spark ou sur un cluster Dataproc sur Compute Engine.
Envoyer un job par lot à Google Cloud Serverless pour Apache Spark
Envoyer un job par lot à un cluster Dataproc sur Compute Engine
Afficher et gérer les ressources
Après avoir installé l'extension Dataproc JupyterLab, vous pouvez afficher et gérer Google Cloud Serverless pour Apache Spark et Dataproc sur Compute Engine depuis la section Tâches et sessions Dataproc de la page Lanceur d'applications JupyterLab.
Cliquez sur la section Jobs et sessions Dataproc pour afficher les fiches Clusters et Sans serveur.
Pour afficher et gérer les sessions Google Cloud Serverless pour Apache Spark :
Pour afficher et gérer les lots Google Cloud Serverless pour Apache Spark :
Pour afficher et gérer les clusters Dataproc sur Compute Engine :
Pour afficher et gérer les jobs Dataproc sur Compute Engine :