このドキュメントでは、Apache Spark 向け Serverless のバッチ ワークロードのモニタリングとトラブルシューティングに使用できるツールとファイルについて説明します。
Google Cloud コンソールからワークロードのトラブルシューティングを行う
バッチジョブが失敗した場合やパフォーマンスが低い場合は、まず Google Cloud コンソールの [バッチ] ページから [バッチの詳細] ページを開くことをおすすめします。
[概要] タブを使用する: トラブルシューティング ハブ
[バッチの詳細] ページを開くとデフォルトで選択される [概要] タブには、バッチの健全性を迅速に初期評価するのに役立つ重要な指標とフィルタされたログが表示されます。この初期評価の後、[バッチの詳細] ページから利用できる Spark UI、ログ エクスプローラ、Gemini Cloud Assist などのより専門的なツールを使用して、より詳細な分析を行うことができます。
バッチ指標のハイライト
[バッチの詳細] ページの [概要] タブには、重要なバッチ ワークロード指標の値を表示するグラフが含まれています。指標グラフは完了後に表示され、リソース競合、データスキュー、メモリ負荷などの潜在的な問題が視覚的に示されます。
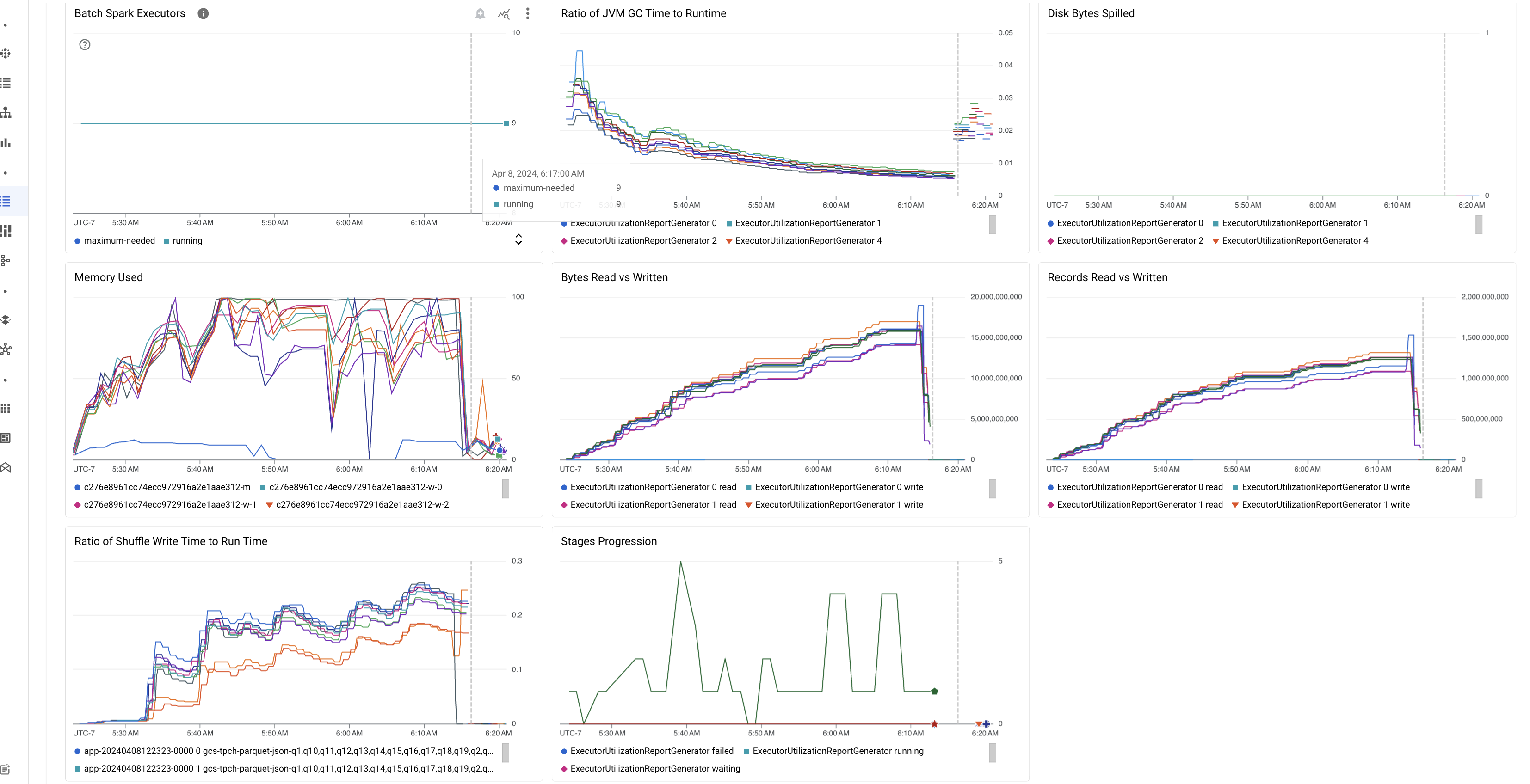
次の表は、 Google Cloud コンソールの [バッチの詳細] ページに表示される Spark ワークロードの指標の一覧と、指標の値からワークロードのステータスとパフォーマンスに関する分析情報を得る方法について説明します。
| 指標 | 確認できるポイント |
|---|---|
| エグゼキュータ レベルの指標 | |
| JVM GC 時間と実行時間の比率 | この指標は、エグゼキュータごとの JVM GC(ガベージ コレクション)時間と実行時間の比率を示します。比率が高い場合は、特定のエグゼキュータで実行されているタスク内のメモリリークや、非効率的なデータ構造が原因で、オブジェクトのチャーン率が高くなっている可能性があります。 |
| ディスクにオーバーフローしたバイト数 | この指標は、さまざまなエグゼキュータに流出したディスク バイトの合計数を示します。エグゼキュータのディスク バイト数が多すぎる場合は、データスキューが発生している可能性があります。指標が時間の経過とともに増加する場合は、メモリ不足またはメモリリークが発生しているステージがあることを示している可能性があります。 |
| 読み取りバイト数と書き込みバイト数 | この指標は、エグゼキュータごとの書き込みバイト数と読み取りバイト数を示します。読み取りまたは書き込みバイト数の大きな差異は、レプリケートされた結合によって特定のエグゼキュータでデータ増幅が発生するシナリオを示している可能性があります。 |
| 読み取りと書き込みのレコード数 | この指標は、エグゼキュータごとの読み取りと書き込みのレコードを示します。読み取られたレコードの数が多く、書き込まれたレコードの数が少ない場合は、特定のエグゼキュータの処理ロジックにボトルネックがあり、待機中にレコードが読み取られている可能性があります。読み取りと書き込みで一貫して遅延が発生するエグゼキュータは、それらのノードでのリソース競合や、エグゼキュータ固有のコードの非効率性を示している可能性があります。 |
| シャッフル書き込み時間と実行時間の比率 | この指標は、全体の実行時間に対して、エグゼキュータがシャッフル実行時間に費やした時間を示します。一部のエグゼキュータでこの値が高い場合は、データスキューまたはデータのシリアル化が非効率的であることを示している可能性があります。Spark UI で、シャッフル書き込み時間が長いステージを特定できます。これらのステージで、完了に平均時間よりも長い時間を要している外れ値タスクを探します。シャッフル書き込み時間の長いエグゼキュータで、ディスク I/O アクティビティも高いかどうかを確認します。シリアル化の効率を高めたり、パーティショニングの手順を追加したりすると、問題が解決する可能性があります。レコードの読み取りと比較してレコードの書き込みが非常に多い場合は、非効率的な結合や誤った変換による意図しないデータの重複が原因である可能性があります。 |
| アプリケーション レベルの指標 | |
| ステージの進行 | この指標は、失敗したステージ、待機中のステージ、実行中のステージの数を示します。失敗したステージや待機中のステージが多数ある場合は、データスキューが発生している可能性があります。データ パーティションを確認し、Spark UI の [ステージ] タブを使用してステージの失敗の原因をデバッグします。 |
| バッチ Spark エグゼキュータ | この指標は、必要なエグゼキュータの数と実行中のエグゼキュータの数を示します。必要なエグゼキュータと実行中のエグゼキュータの間に大きな差がある場合は、自動スケーリングの問題を示している可能性があります。 |
| VM レベルの指標 | |
| 使用されたメモリ | この指標は、使用中の VM メモリの割合を示します。マスターの割合が高い場合は、ドライバがメモリ不足になっている可能性があります。他の VM ノードでは、割合が高い場合、エグゼキュータがメモリ不足であることを示している可能性があります。これにより、ディスクの流出が高まり、ワークロード実行時間が遅くなる可能性があります。Spark UI を使用してエグゼキュータを分析し、GC 時間の増加とタスクの失敗の増加を確認します。また、大規模なデータセットのキャッシュ保存と不要な変数のブロードキャストに関する Spark コードをデバッグします。 |
ジョブのログ
[バッチの詳細] ページには、ジョブ(バッチ ワークロード)ログからフィルタされた警告とエラーが一覧表示される [ジョブログ] セクションがあります。この機能を使用すると、大規模なログファイルを手動で解析することなく、重大な問題をすばやく特定できます。プルダウン メニューからログの [重大度](Error など)を選択し、テキストの [フィルタ] を追加して結果を絞り込むことができます。詳細な分析を行うには、[ログ エクスプローラで表示] アイコンをクリックして、選択したバッチログをログ エクスプローラで開きます。
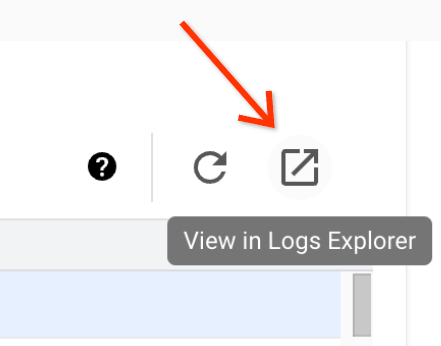
例: Google Cloud コンソールの [バッチの詳細] ページの重大度セレクタで Errors を選択すると、ログ エクスプローラが開きます。
Spark UI
Spark UI は、Apache Spark 向け Serverless バッチ ワークロードから Apache Spark の実行の詳細を収集します。Spark UI 機能はデフォルトで有効になっており、料金はかかりません。
Spark UI 機能によって収集されたデータは 90 日間保持されます。このウェブ インターフェースを使用すると、永続履歴サーバーを作成しなくても、Spark ワークロードをモニタリングしてデバッグできます。
必要な Identity and Access Management の権限とロール
バッチ ワークロードで Spark UI 機能を使用するには、次の権限が必要です。
データ収集権限:
dataproc.batches.sparkApplicationWrite。この権限は、バッチ ワークロードを実行するサービス アカウントに付与する必要があります。この権限はDataproc Workerロールに含まれています。このロールは、Apache Spark 向け Serverless がデフォルトで使用する Compute Engine のデフォルト サービス アカウントに自動的に付与されます(Apache Spark 向け Serverless サービス アカウントをご覧ください)。ただし、バッチ ワークロードにカスタム サービス アカウントを指定する場合は、そのサービス アカウントにdataproc.batches.sparkApplicationWrite権限を追加する必要があります(通常は、サービス アカウントに DataprocWorkerロールを付与します)。Spark UI アクセス権限:
dataproc.batches.sparkApplicationRead。Google Cloud コンソールの Spark UI にアクセスするには、この権限をユーザーに付与する必要があります。この権限は、Dataproc Viewerロール、Dataproc Editorロール、Dataproc Administratorロールに含まれています。 Google Cloud コンソールで Spark UI を開くには、次のいずれかのロールを付与されているか、この権限を含むカスタムロールが必要です。
Spark UI を開く
Spark UI ページは、 Google Cloud コンソール バッチ ワークロードで使用できます。
[Apache Spark 向け Serverless のインタラクティブ セッション] ページに移動します。
[バッチ ID] をクリックして、[バッチの詳細] ページを開きます。
上部のメニューで [View Spark UI] をクリックします。
[View Spark UI] ボタンは、次の場合に無効になります。
- 必要な権限が付与されていない場合
- [バッチの詳細] ページの [Spark UI を有効にする] チェックボックスをオフにした場合
- バッチ ワークロードを送信するときに
spark.dataproc.appContext.enabledプロパティをfalseに設定した場合
Apache Spark 向け Serverless のログ
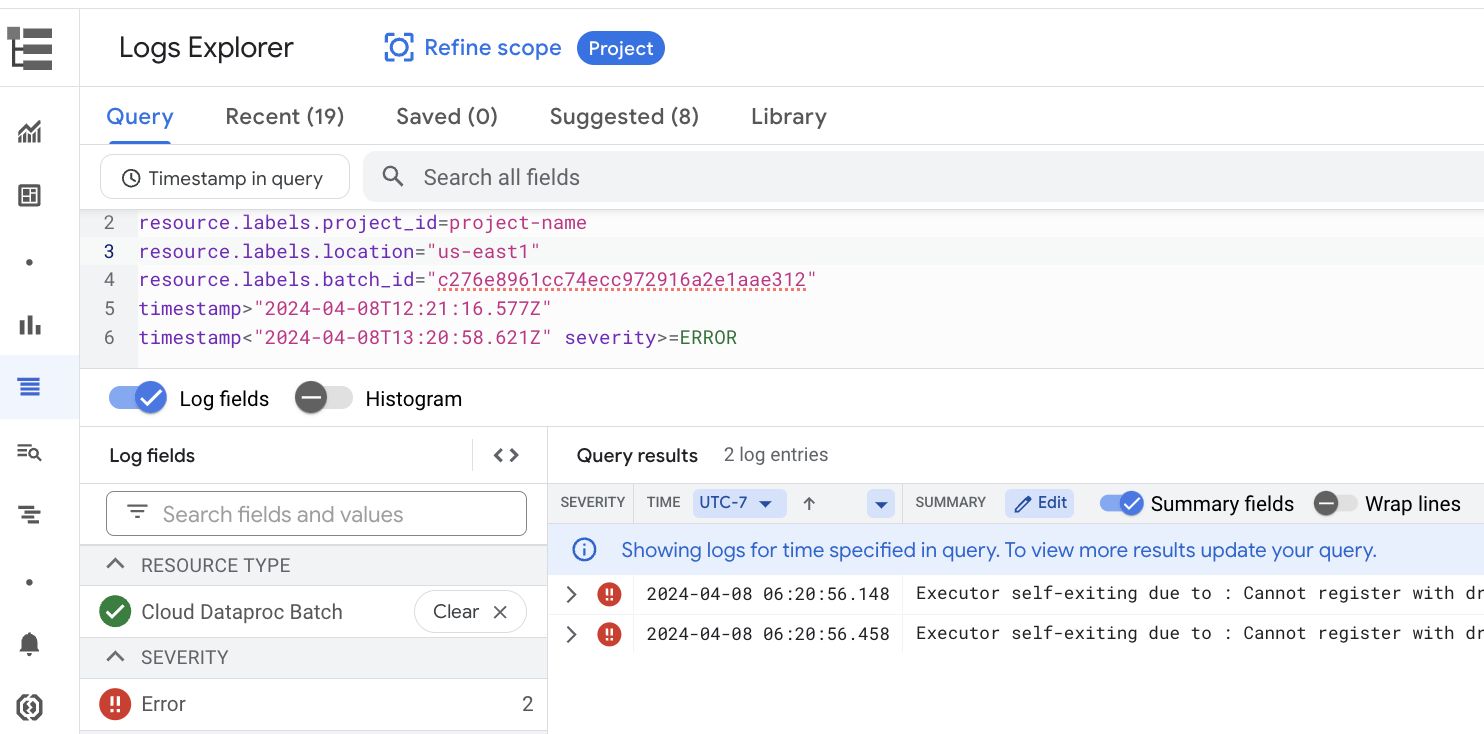
Apache Spark 向けサーバーレスでは、ロギングがデフォルトで有効になっており、ワークロードが完了した後にワークロード ログが保持されます。Apache Spark 向け Serverless は、Cloud Logging でワークロード ログを収集します。Apache Spark 用サーバーレスのログには、ログ エクスプローラの Cloud Dataproc Batch リソースでアクセスできます。
Apache Spark 向け Serverless のログをクエリする
Google Cloud コンソールのログ エクスプローラには、バッチ ワークロード ログを調べるクエリを作成するためのクエリペインがあります。バッチ ワークロード ログを調べるクエリを作成する手順は次のとおりです。
- 現在のプロジェクトが選択されています。[プロジェクトのスコープを絞り込む] をクリックして、別のプロジェクトを選択できます。
バッチログクエリを定義します。
フィルタ メニューを使用して、バッチ ワークロードをフィルタします。
[すべてのリソース] で、[Cloud Dataproc Batch] リソースを選択します。
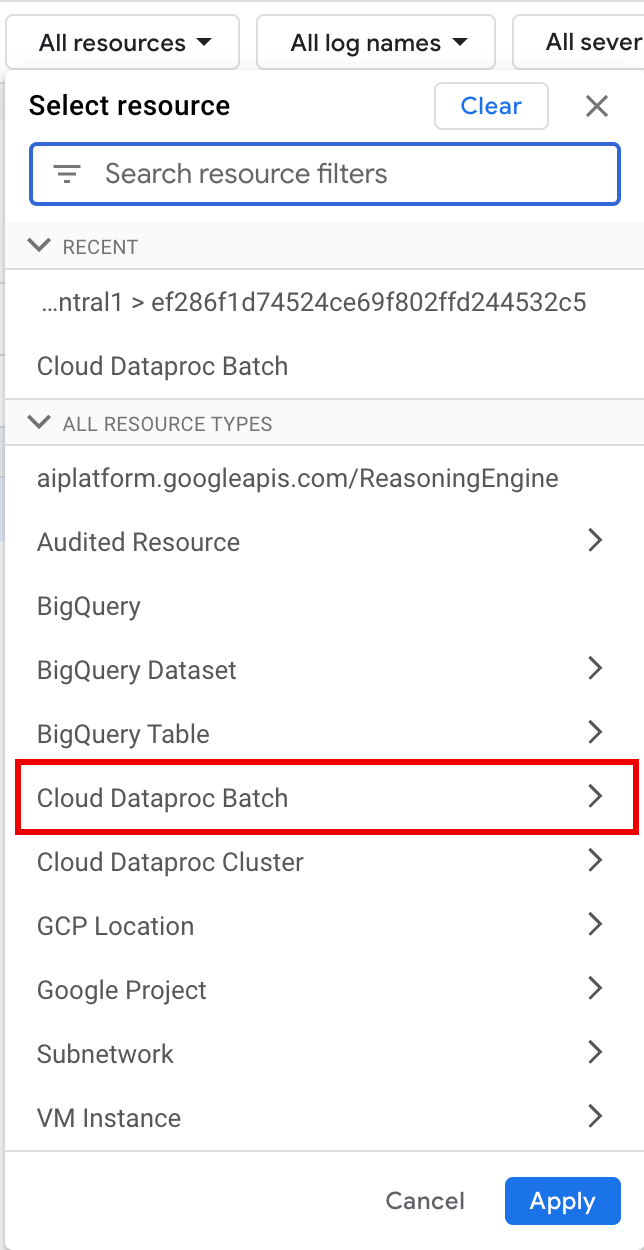
[リソースの選択] パネルで、バッチの [ロケーション]、[バッチ ID] の順に選択します。これらのバッチ パラメータは、 Google Cloud コンソールの Dataproc の [バッチ] ページに表示されます。
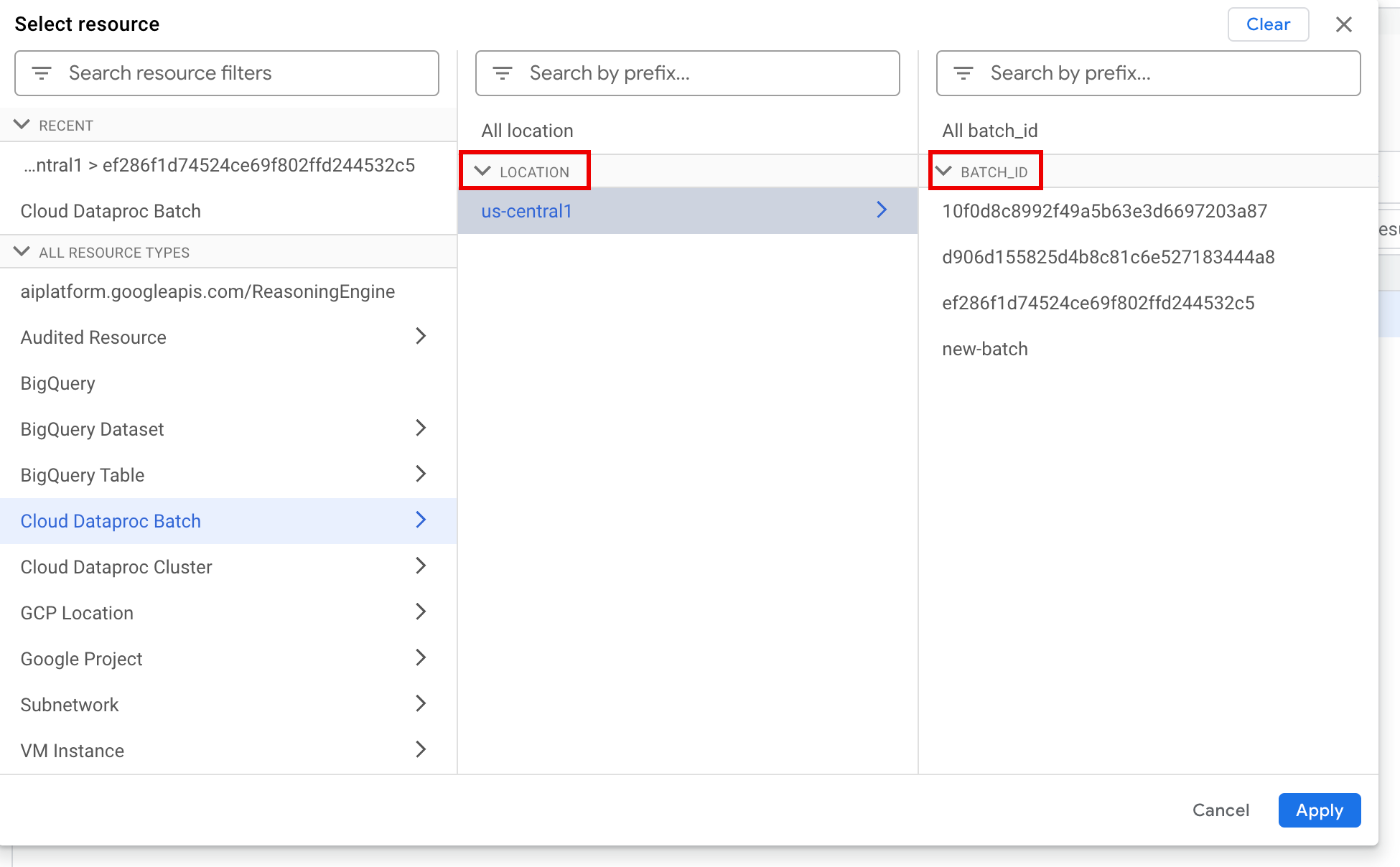
[適用] をクリックします。
[ログ名を選択] で、[ログ名を検索] ボックスに「
dataproc.googleapis.com」と入力して、クエリするログタイプを制限します。表示されたログファイル名を 1 つ以上選択します。
クエリエディタを使用して、VM 固有のログをフィルタします。
次の例に示すように、リソースタイプと VM リソース名を指定します。
resource.type="cloud_dataproc_batch" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
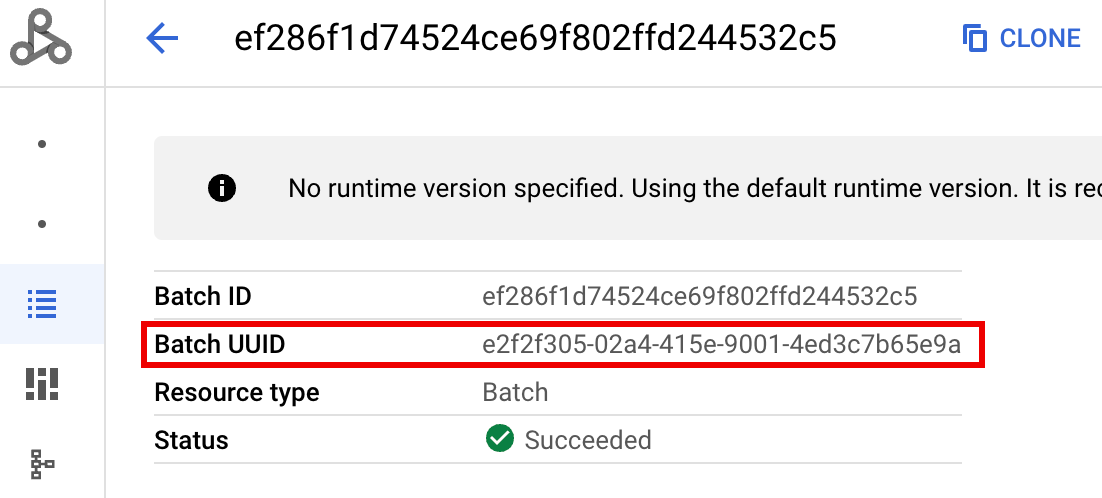
- BATCH_UUID: バッチ UUID は、 Google Cloud コンソールの [バッチ] ページでバッチ ID をクリックすると表示される [バッチの詳細] ページに表示されます。
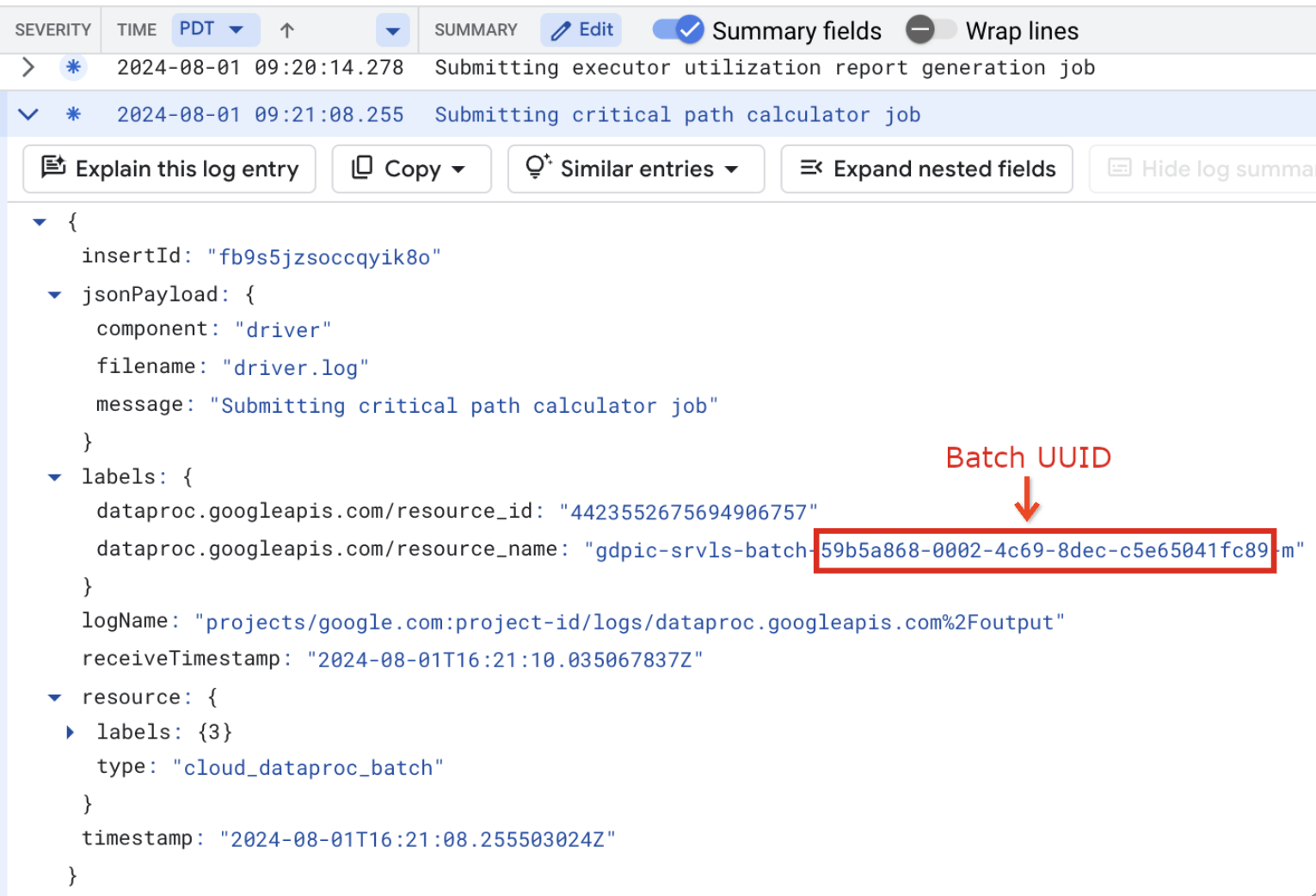
バッチログには、VM リソース名のバッチ UUID も一覧表示されます。バッチ driver.log の例を次に示します。
- BATCH_UUID: バッチ UUID は、 Google Cloud コンソールの [バッチ] ページでバッチ ID をクリックすると表示される [バッチの詳細] ページに表示されます。
[クエリを実行] をクリックします。
Apache Spark 向け Serverless のログタイプとサンプルクエリ
次のリストに、さまざまな Serverless for Apache Spark ログタイプと、各ログタイプのログ エクスプローラのクエリの例を示します。
dataproc.googleapis.com/output: このログファイルには、バッチ ワークロードの出力内容が含まれています。Apache Spark 向け Serverless は、バッチ出力をoutputNamespace にストリーミングし、ファイル名をJOB_ID.driver.logに設定します。出力ログのログ エクスプローラ クエリの例:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Foutput"
dataproc.googleapis.com/spark:sparkNamespace は、Dataproc クラスタのマスター VM とワーカー VM で実行されているデーモンとエグゼキュータの Spark ログを集約します。各ログエントリには、ログソースを識別するmaster、worker、またはexecutorコンポーネントラベルが含まれています。executor: ユーザーコード エグゼキュータからのログ。通常、これらは分散ログです。master: Spark スタンドアロン リソース マネージャー マスターのログ。Dataproc on Compute Engine YARNResourceManagerログに似ています。worker: Spark スタンドアロン リソース マネージャー ワーカーのログ。Dataproc on Compute Engine YARNNodeManagerログに似ています。
sparkNamespace 内のすべてのログに対するログ エクスプローラのクエリの例:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark"
sparkNamespace の Spark スタンドアロン コンポーネント ログのサンプル ログ エクスプローラ クエリ:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark" jsonPayload.component="COMPONENT"
dataproc.googleapis.com/startup:startupNamespace には、バッチ(クラスタ)の起動ログが含まれます。初期化スクリプトのログが含まれます。コンポーネントはラベルで識別されます。次に例を示します。startup-script[855]: ... activate-component-spark[3050]: ... enable spark-worker
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fstartup" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
dataproc.googleapis.com/agent:agentNamespace は、Dataproc エージェント ログを集約します。各ログエントリには、ログソースを識別するファイル名ラベルが含まれています。指定したワーカー VM によって生成されたエージェントログのログ エクスプローラ クエリの例:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fagent" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
dataproc.googleapis.com/autoscaler:autoscalerNamespace は、Apache Spark 用サーバーレスのオートスケーラー ログを集約します。指定したワーカー VM によって生成されたエージェントログのログ エクスプローラ クエリの例:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fautoscaler" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
詳細については、Dataproc ログをご覧ください。
Apache Spark 用サーバーレスの監査ログについては、Dataproc 監査ロギングをご覧ください。
ワークロード指標
Apache Spark 向け Serverless は、Metrics Explorer または Google Cloud コンソールの [バッチの詳細] ページで確認できるバッチ指標と Spark 指標を提供します。
バッチ指標
Dataproc batch リソース指標は、バッチ エグゼキュータの数などのバッチ リソースに関する分析情報を提供します。バッチ指標には dataproc.googleapis.com/batch という接頭辞が付いています。
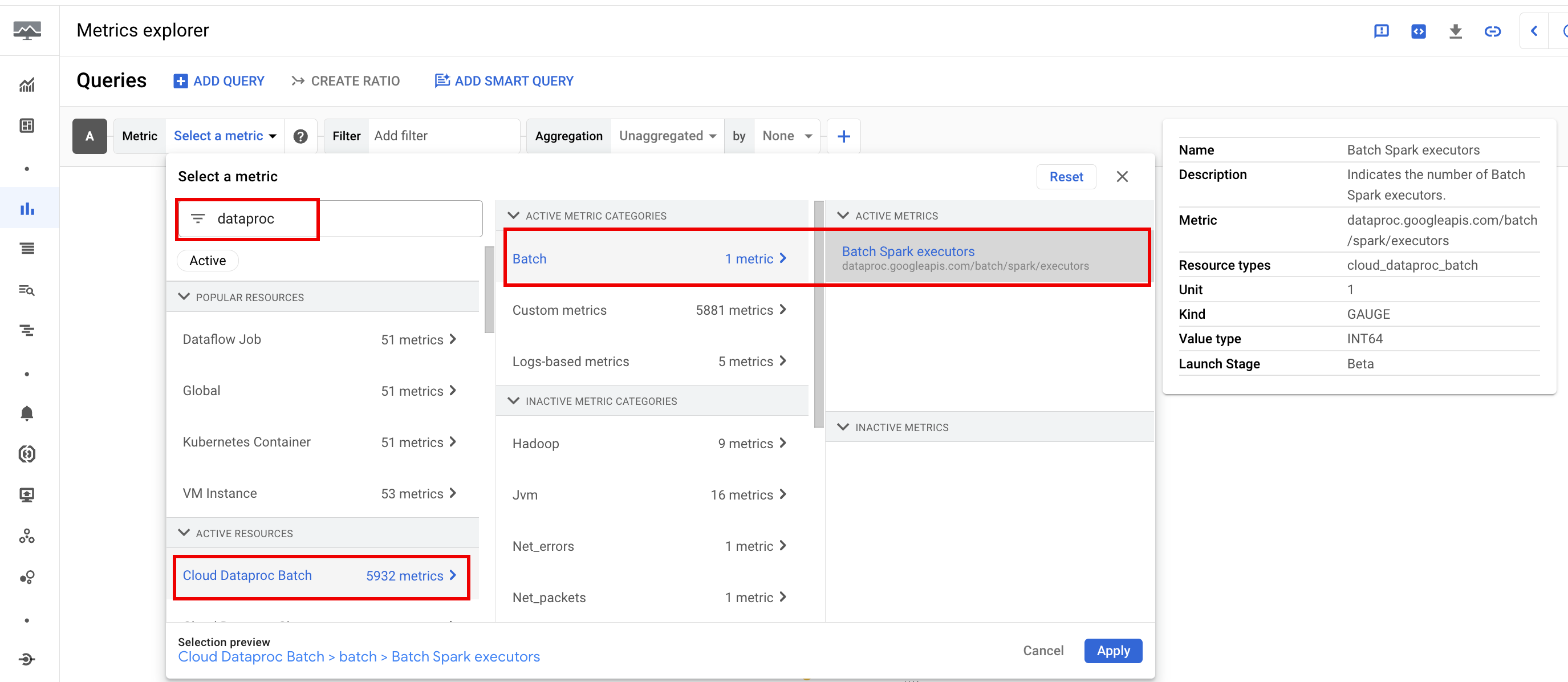
Spark 指標
デフォルトでは、Apache Spark 向けサーバーレスは、Spark 指標収集プロパティを使用して無効にしない限り、利用可能な Spark 指標の収集を有効にします。または、1 つ以上の Spark 指標のコレクションをオーバーライドできます。
利用可能な Spark 指標には、Spark ドライバとエグゼキュータの指標、システム指標が含まれます。利用可能な Spark 指標には custom.googleapis.com/ という接頭辞が付いています。
指標アラートを設定する
Dataproc 指標アラートを作成すると、ワークロードの問題の通知を受け取ることができます。
グラフを作成
Google Cloud コンソールの Metrics Explorer を使用して、ワークロード指標を可視化するグラフを作成できます。たとえば、disk:bytes_used を表示するグラフを作成し、batch_id でフィルタできます。
Cloud Monitoring
モニタリングでは、ワークロードのメタデータと指標を使用して、Apache Spark 向け Serverless ワークロードの健全性とパフォーマンスに関する分析情報を提供します。ワークロード指標には、Spark 指標、バッチ指標、オペレーション指標が含まれます。
Google Cloud コンソールの Cloud Monitoring を使用すると、指標の確認、グラフの追加、ダッシュボードの作成、アラートの作成を行えます。
ダッシュボードの作成
複数のプロジェクトとさまざまな Google Cloud プロダクトの指標を使用して、ワークロードをモニタリングするダッシュボードを作成できます。詳細については、カスタム ダッシュボードの作成と管理をご覧ください。
永続的履歴サーバー
Apache Spark 用サーバーレスは、ワークロードの実行に必要なコンピューティング リソースを作成し、それらのリソースでワークロードを実行し、ワークロードが終了するとリソースを削除します。ワークロードの指標とイベントは、ワークロードが完了すると保持されません。ただし、永続的履歴サーバー(PHS)を使用すると、ワークロード アプリケーションの履歴(イベントログ)を Cloud Storage に保持できます。
バッチ ワークロードで PHS を使用する手順は次のとおりです。
ワークロードを送信するときに、PHS を指定します。
コンポーネント ゲートウェイを使用して PHS に接続し、アプリケーションの詳細、スケジューラ ステージ、タスクレベルの詳細、環境とエグゼキュータの情報を表示します。
自動チューニング
- Apache Spark 用 Serverless の自動チューニングを有効にする: Google Cloud コンソール、gcloud CLI、Dataproc API を使用して、定期的な各 Spark バッチ ワークロードを送信する場合は、Apache Spark 用 Serverless の自動チューニングを有効にできます。
コンソール
次の手順を実行して、繰り返しの Spark バッチ ワークロードで自動チューニングを有効にします。
Google Cloud コンソールで、Dataproc の [バッチ] ページに移動します。
バッチ ワークロードを作成するには、[作成] をクリックします。
[コンテナ] セクションで、コホート名を入力します。バッチが一連の反復的なワークロードの 1 つとして識別されます。Gemini 支援の分析は、このコホート名で送信された 2 回目以降のワークロードに適用されます。たとえば、毎日 TPC-H クエリを実行するスケジュール設定されたワークロードのコホート名として
TPCH-Query1を指定します。必要に応じて [バッチを作成] ページの他のセクションに入力し、[送信] をクリックします。詳細については、バッチ ワークロードを送信するをご覧ください。
gcloud
次の gcloud CLI gcloud dataproc batches submit コマンドをターミナル ウィンドウでローカルに実行するか、Cloud Shell で実行して、繰り返しの Spark バッチ ワークロードで自動チューニングを有効にします。
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ other arguments ...
次のように置き換えます。
- COMMAND: Spark ワークロード タイプ(
Spark、PySpark、Spark-Sql、Spark-Rなど)。 - REGION: ワークロードが実行される リージョンを指定します。
- COHORT: コホート名。バッチが一連の繰り返しワークロードの 1 つとして識別されます。Gemini 支援の分析は、このコホート名で送信された 2 回目以降のワークロードに適用されます。たとえば、毎日 TPC-H クエリを実行するスケジュール設定されたワークロードのコホート名として
TPCH Query 1を指定します。
API
batches.create リクエストに RuntimeConfig.cohort 名を含めて、繰り返しの Spark バッチ ワークロードで自動チューニングを有効にします。自動チューニングは、このコホート名で送信された 2 回目以降のワークロードに適用されます。たとえば、毎日 TPC-H クエリを実行するスケジュール設定されたワークロードのコホート名として TPCH-Query1 を指定します。
例:
...
runtimeConfig:
cohort: TPCH-Query1
...