Tetap teratur dengan koleksi
Simpan dan kategorikan konten berdasarkan preferensi Anda.
Tugas kualitas data Dataplex Universal Catalog memungkinkan Anda menentukan dan menjalankan pemeriksaan kualitas data di seluruh tabel di BigQuery dan Cloud Storage. Tugas kualitas data Dataplex Universal Catalog juga memungkinkan Anda menerapkan kontrol data reguler di lingkungan BigQuery.
Kapan harus membuat tugas kualitas data Dataplex Universal Catalog
Tugas kualitas data Dataplex Universal Catalog dapat membantu Anda dalam hal berikut:
Memvalidasi data sebagai bagian dari pipeline produksi data.
Memantau secara rutin kualitas set data berdasarkan ekspektasi Anda.
Membuat laporan kualitas data untuk persyaratan peraturan.
Manfaat
Spesifikasi yang dapat disesuaikan. Anda dapat menggunakan sintaksis YAML yang sangat fleksibel
untuk mendeklarasikan aturan kualitas data.
Implementasi serverless. Dataplex Universal Catalog tidak memerlukan
penyiapan infrastruktur apa pun.
Zero-copy dan bentang bawah otomatis. Pemeriksaan YAML dikonversi ke SQL dan
didorong ke BigQuery, sehingga tidak ada data yang disalin.
Pemeriksaan kualitas data yang dapat dijadwalkan. Anda dapat menjadwalkan pemeriksaan kualitas data
melalui penjadwal serverless di Dataplex Universal Catalog, atau menggunakan
Dataplex API melalui penjadwal eksternal seperti Cloud Composer
untuk integrasi pipeline.
Pengalaman terkelola. Dataplex Universal Catalog menggunakan mesin kualitas data
open source, CloudDQ,
untuk menjalankan pemeriksaan kualitas data. Namun, Dataplex Universal Catalog memberikan
pengalaman terkelola yang lancar untuk menjalankan pemeriksaan kualitas data Anda.
Cara kerja tugas kualitas data
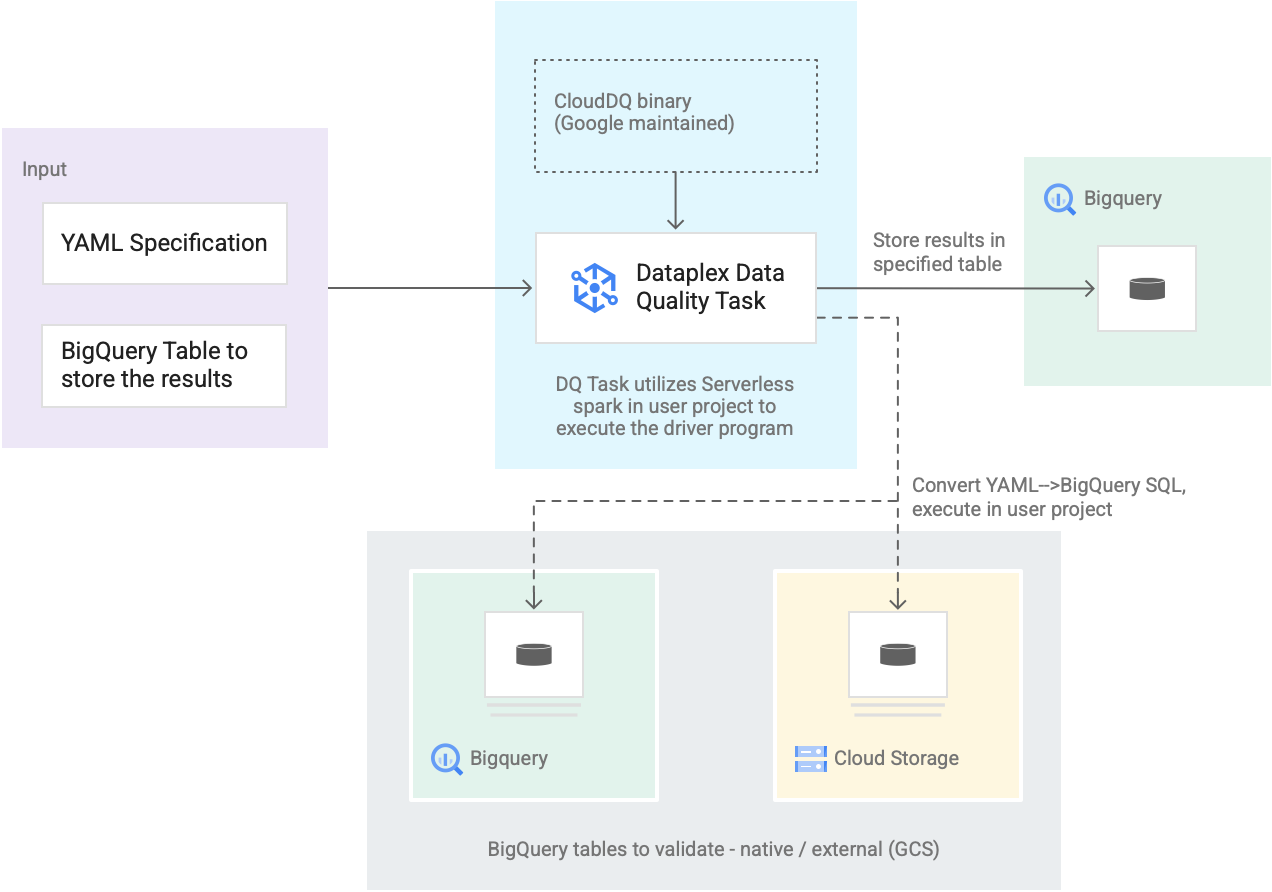
Diagram berikut menunjukkan cara kerja tugas kualitas data Dataplex Universal Catalog:
Input dari pengguna
Spesifikasi YAML: Sekumpulan yang berisi satu atau beberapa file YAML yang menentukan
aturan kualitas data berdasarkan sintaksis spesifikasi. Anda menyimpan file YAML di
bucket Cloud Storage di project Anda. Pengguna dapat menjalankan beberapa aturan
secara bersamaan, dan aturan tersebut dapat diterapkan ke berbagai tabel
BigQuery, termasuk tabel di berbagai set data atau project Google Cloud. Spesifikasi mendukung operasi inkremental hanya untuk memvalidasi data baru. Untuk
membuat spesifikasi YAML, lihat
Membuat file spesifikasi.
Tabel hasil BigQuery: Tabel yang ditentukan pengguna tempat penyimpanan hasil
validasi kualitas data. Google Cloud Project tempat
tabel ini berada dapat menjadi project yang berbeda dengan project yang
menggunakan tugas kualitas data Dataplex Universal Catalog.
Tabel untuk divalidasi
Dalam spesifikasi YAML, Anda harus menentukan tabel mana yang ingin
divalidasi untuk aturan tertentu, yang juga dikenal sebagai binding aturan. Tabel tersebut dapat berupa
tabel native BigQuery atau tabel eksternal BigQuery
di Cloud Storage. Spesifikasi YAML memungkinkan Anda menentukan tabel
di dalam atau di luar zona Dataplex Universal Catalog.
Tabel BigQuery dan Cloud Storage yang divalidasi
dalam satu operasi dapat menjadi bagian dari project yang berbeda.
Tugas kualitas data Dataplex Universal Catalog: Tugas kualitas data Dataplex Universal Catalog dikonfigurasi dengan biner
CloudDQ PySpark bawaan yang dikelola serta menggunakan spesifikasi YAML dan
tabel hasil BigQuery sebagai input. Serupa dengan
tugas Dataplex Universal Catalog lainnya,
tugas kualitas data Dataplex Universal Catalog berjalan di lingkungan Spark
serverless, mengonversi spesifikasi YAML menjadi kueri
BigQuery, lalu menjalankan kueri tersebut pada tabel yang ditentukan dalam
file spesifikasi.
Harga
Saat menjalankan tugas kualitas data Dataplex Universal Catalog, Anda akan dikenai biaya atas
penggunaan BigQuery dan Dataproc Serverless (Batch).
Tugas kualitas data Dataplex Universal Catalog mengonversi file spesifikasi
menjadi kueri BigQuery dan menjalankannya di project pengguna. Lihat bagian
Harga BigQuery.
Dataplex Universal Catalog menggunakan Spark untuk menjalankan program driver CloudDQ open source yang
dikelola Google guna mengonversi spesifikasi pengguna ke kueri
BigQuery. Lihat Harga Dataproc Serverless.
Penggunaan Dataplex Universal Catalog untuk mengatur data atau penggunaan penjadwal serverless di Dataplex Universal Catalog untuk menjadwalkan pemeriksaan kualitas data tidak akan dikenai biaya. Lihat
Harga Katalog Universal Dataplex.
[[["Mudah dipahami","easyToUnderstand","thumb-up"],["Memecahkan masalah saya","solvedMyProblem","thumb-up"],["Lainnya","otherUp","thumb-up"]],[["Sulit dipahami","hardToUnderstand","thumb-down"],["Informasi atau kode contoh salah","incorrectInformationOrSampleCode","thumb-down"],["Informasi/contoh yang saya butuhkan tidak ada","missingTheInformationSamplesINeed","thumb-down"],["Masalah terjemahan","translationIssue","thumb-down"],["Lainnya","otherDown","thumb-down"]],["Terakhir diperbarui pada 2025-09-05 UTC."],[[["\u003cp\u003eDataplex data quality tasks enable users to define and execute data quality checks on tables in BigQuery and Cloud Storage, also allowing for the implementation of regular data controls in BigQuery environments.\u003c/p\u003e\n"],["\u003cp\u003eThese tasks offer benefits such as customizable rule specifications using YAML syntax, a serverless implementation, zero-copy and automatic pushdown for efficiency, and the ability to schedule checks.\u003c/p\u003e\n"],["\u003cp\u003eThe tasks use a YAML specification to define data quality rules and can validate tables both inside and outside of Dataplex zones, as well as across different projects.\u003c/p\u003e\n"],["\u003cp\u003eUsers can store validation results in a specified BigQuery table, which can be in a different project than the one where the Dataplex task runs.\u003c/p\u003e\n"],["\u003cp\u003eDataplex uses the open source CloudDQ for data quality checks, though users are provided a managed experience, and cost is based on BigQuery and Dataproc Serverless (Batches) usage.\u003c/p\u003e\n"]]],[],null,["# Data quality tasks overview\n\n| **Caution:** Dataplex Universal Catalog data quality tasks is a legacy offering based on open source software. We recommend that you start using the latest built-in [Automatic data quality](/dataplex/docs/auto-data-quality-overview) offering.\n\nDataplex Universal Catalog data quality tasks let you define and run\ndata quality checks across tables in BigQuery and\nCloud Storage. Dataplex Universal Catalog data quality tasks also let you\napply regular data controls in BigQuery environments.\n\nWhen to create Dataplex Universal Catalog data quality tasks\n------------------------------------------------------------\n\nDataplex Universal Catalog data quality tasks can help you with the following:\n\n- Validate data as part of a data production pipeline.\n- Routinely monitor the quality of datasets against your expectations.\n- Build data quality reports for regulatory requirements.\n\nBenefits\n--------\n\n- **Customizable specifications.** You can use the highly flexible YAML syntax to declare your data quality rules.\n- **Serverless implementation.** Dataplex Universal Catalog does not need any infrastructure setup.\n- **Zero-copy and automatic pushdown.** YAML checks are converted to SQL and pushed down to BigQuery, resulting in no data copy.\n- **Schedulable data quality checks.** You can schedule data quality checks through the serverless scheduler in Dataplex Universal Catalog, or use the Dataplex API through external schedulers like Cloud Composer for pipeline integration.\n- **Managed experience.** Dataplex Universal Catalog uses an open source data quality engine, [CloudDQ](https://github.com/GoogleCloudPlatform/cloud-data-quality), to run data quality checks. However, Dataplex Universal Catalog provides a seamless managed experience for performing your data quality checks.\n\nHow data quality tasks work\n---------------------------\n\nThe following diagram shows how Dataplex Universal Catalog data quality tasks work:\n\n- **Input from users**\n - **YAML specification** : A set of one or more YAML files that define data quality rules based on the specification syntax. You store the YAML files in a Cloud Storage bucket in your project. Users can run multiple rules simultaneously, and those rules can be applied to different BigQuery tables, including tables across different datasets or Google Cloud projects. The specification supports incremental runs for only validating new data. To create a YAML specification, see [Create a specification file](/dataplex/docs/check-data-quality#create-a-specification-file).\n - **BigQuery result table**: A user-specified table where the data quality validation results are stored. The Google Cloud project in which this table resides can be a different project than the one in which the Dataplex Universal Catalog data quality task is used.\n- **Tables to validate**\n - Within the YAML specification, you need to specify which tables you want to validate for which rules, also known as a *rule binding*. The tables can be BigQuery native tables or BigQuery external tables in Cloud Storage. The YAML specification lets you specify tables inside or outside a Dataplex Universal Catalog zone.\n - BigQuery and Cloud Storage tables that are validated in a single run can belong to different projects.\n- **Dataplex Universal Catalog data quality task** : A Dataplex Universal Catalog data quality task is configured with a prebuilt, maintained CloudDQ PySpark binary and takes the YAML specification and BigQuery result table as the input. Similar to other [Dataplex Universal Catalog tasks](/dataplex/docs/schedule-custom-spark-tasks), the Dataplex Universal Catalog data quality task runs on a serverless Spark environment, converts the YAML specification to BigQuery queries, and then runs those queries on the tables that are defined in the specification file.\n\nPricing\n-------\n\nWhen you run Dataplex Universal Catalog data quality tasks, you are charged for\nBigQuery and Dataproc Serverless (Batches) usage.\n\n- The Dataplex Universal Catalog data quality task converts the specification file\n to BigQuery queries and runs them in the user project. See\n [BigQuery pricing](/bigquery/pricing).\n\n- Dataplex Universal Catalog uses Spark to run the prebuilt, Google-maintained [open source CloudDQ](https://github.com/GoogleCloudPlatform/cloud-data-quality)\n driver program to convert user specification to BigQuery\n queries. See [Dataproc Serverless pricing](/dataproc-serverless/pricing).\n\nThere are no charges for using Dataplex Universal Catalog to organize data or using the serverless\nscheduler in Dataplex Universal Catalog to schedule data quality checks. See\n[Dataplex Universal Catalog pricing](/dataplex/pricing).\n\nWhat's next\n-----------\n\n- [Create Dataplex Universal Catalog data quality checks](/dataplex/docs/check-data-quality)."]]