It is critical for many organizations to track trending and emerging topics. Conversational Insights lets you detect and identify top conversation drivers from calls or chats without prior labeling. Follow these best practices for using the Insights topic modeling V2.1 feature. Its unsupervised modeling makes setup simpler while automatically identifying top drivers surfaced in analyzed conversations.
Assessing training data quality
For voice data, the quality of Speech-to-Text outputs is critical to the performance of the topic model.
Ensure that the conversation's speaker roles are assigned properly when the conversation is ingested:
- Accurately label conversation turns as coming from customer or agent.
- Use
AGENTfor human roles,AUTOMATED_AGENTfor virtual ones, and, for customer roles,END_USERorCUSTOMER. - Make sure that most conversations have transcripts with customer and agent roles labeled. Conversations with only one role won't be used in training.
Ensure that the conversations are sufficiently long: About 10 total turns, with 5 from the agent and 5 from the customer.
Avoid using duplicate conversations in the dataset.
For better quality topics from the model, try using redacted conversations for topic modeling. However, if the redaction is overly aggressive and removes important information from the transcripts, it can affect the length of your training conversations. If applicable, check the Cloud Data Loss Prevention redaction quality.
Data requirements, including smaller datasets
A minimum of 1k conversations with 5 back-and-forth turns between an agent and customer are required. We also recommend using about 10k conversations for training.
Train the topic model
Start by training an unsupervised topic model without providing custom topics. Though optional, to identify the language used in the conversations, set a language filter.
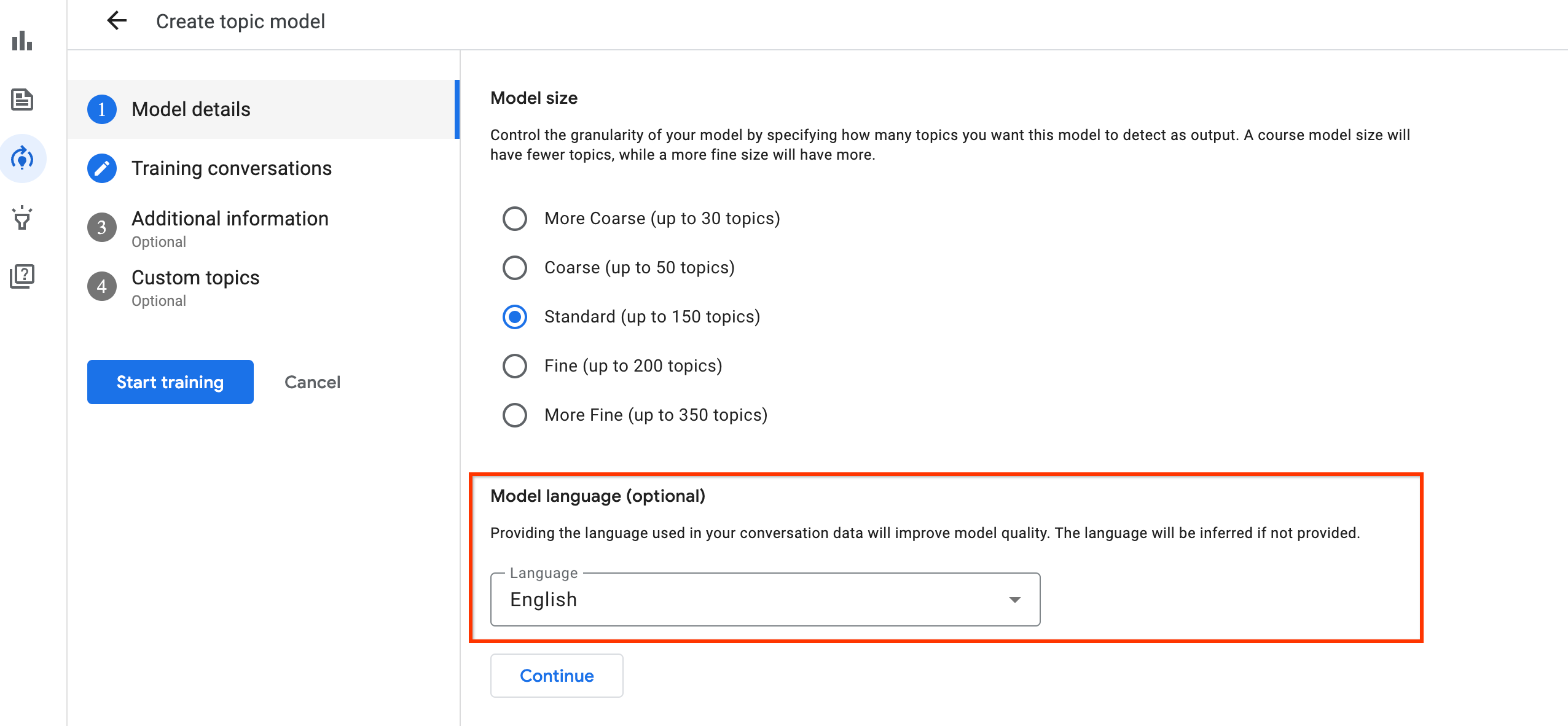
When training the topic model, understand your business use case, and decide on the granularity of the topics that you want. The use case might include what you're looking for in the topic model or the business values the model brings. Granularity determines model size in the training. Ask, What is the rough number of topic clusters in the existing solution, if any?
If quality from the unsupervised model is low, try training another topic model with a list of custom topics.
Customize the topic model
When using topic modeling, there are four main techniques for improving topic assignments:
- Remove existing topics.
- Add new topics.
- Change the name or description of topics.
- Merge topics.
When you perform any of these actions, a new analysis follows the updated topic list and the existing analysis is unchanged. To apply a new change to an existing analysis, follow these steps to re-analyze the conversation.
- In the Insights console, choose your project.
- Click news Conversation Hub.
- Choose one option:
- Select conversation from the list and click Re-analyze.
- Navigate to Conversation History and click Analyze.
Remove a Topic
Within the Insights console, follow these steps to remove a topic from the final topic list and the topic inference results.
- Select your Insights enabled project.
- Click model_training Topic Models and select a topic model.
- Go to the topic and click more_vert.
- Click do_not_disturb_on Remove topic.
Add or edit topics
You can also make the following changes to your topic list:
Add topics to cover areas the model doesn't already represent. Follow these steps to add a new topic.
- From the topic list, click New topic and enter a name, then click Add.
Update topic names or descriptions to better describe the subjects of conversations that should match, or to better suit the business use case. Follow these steps to edit a topic name or description.
- From the topic list, go to the topic and click more_vert, then edit Edit topic.
- Enter the name and description, then click Done.
Avoid adding duplicate or similar topics because they will negatively impact the quality of topic inferences. When creating or changing a topic, apply the following naming and description guidelines.
Name
Use short, descriptive topics of three to six words ("troubleshooting remote control" or "inquiring about billing policy").
Avoid generic or abstract names ("Sales").
Optional:
Use readily available custom topic names, such as "Billing"
Add a short description to the topic name, as in "Billing Errors & Refunds".
Choose a suitable model configuration based on the results you want.
Example
A credit card support center runs topic modeling on their archived support call logs. The modeling creates a topic from a cluster of conversations, and names it Credit card over the limit inquiries. The business shortens the name to Credit limit inquiries.
Description
Use a general description followed by a few examples.
Avoid including personal information like names, dates, or locations.
Too much detail (such as "don't include X topic") can negatively impact topic inference.
Examples
The customer is inquiring about their landline phone service. They may want to cancel it or consult about the current billing.
The customer is inquiring about their bill. They may want to know the amount or the due date.
Merge topics
You can combine several topics by merging them. Topic matching uses the names and descriptions of subtopics, but not the merged topic. In other words, changes to the name and description of a merged topic don't affect matching behavior.
Example
If you have the following list of topics and the first two are merged to create the third, then changing the name or description of the third topic won't affect the model's matching process.
- Subtopic: password reset issue
- Subtopic: two factor authentication issue
- Merged topic: account access issue
Imagine the topic list in this example also includes a fourth topic called login issue because of expired ID. If login issue because of expired ID is not merged with account access issue, then conversations matched to login issue because of expired ID won't be assigned to account access issue.
Instructions
Follow these steps to merge topics using the Insights console:
- Within the topic list, check the check_box_outline_blank box for each topic.
- Click Merge selected topics.
Combining topic merge with adding or editing a topic provides a powerful way to customize your topic model.
No topic match
A conversation might not match any of the existing or detected topics if:
- There are too few conversations to form a cluster.
- A conversation doesn't have a specific topic.
In such cases, the conversation is given a topic called no matching topic that can help alter the semantics of existing clusters.
The no matching topic provides a powerful use case for topic merging.
Example
If you have a topic called customer credit issue and want to exclude anything to do with credit cards, follow these steps:
- Create a topic that matches with conversations about credit card issues falsely assigned to the customer credit issue.
- Merge the new topic with no matching topic.
Topic modeling then learns not to cluster credit card conversations with customer credit issue conversations.
Evaluating the topic model
The evaluation of a trained topic model can be carried out in 2 phases: validation of generated topics & descriptions followed by evaluation of analyzed conversations for identified topics.
Step 1: Validation of generated topics and descriptions
We recommend that you remove topics that aren't relevant to your needs. For example, remove a "greetings" topic talking mostly about greeting utterances in the conversations. Details about removing a topic can be found at Delete a Topic.
Merging topics is useful if two or more topics have conversations with similar subject matter and you want them under a unified topic. For example, a custom topic that you provide and an identified topic might serve overlapping needs. If "billing" was one of the custom topics given and "troubleshooting billing issues" was one of the topics identified by the model, then you might merge them.
Add a new topic for any set of topics not identified by the topic model. You're most likely to see this scenario with a model trained without custom topics.
Step 2: Evaluate analyzed conversations
When step 1 is completed, the analyzed conversations should be evaluated for topics identified.
Why are fewer topics learned than selected for granularity?
If there are few topics to be discovered, the final number of topics might be significantly less than the numbers indicated in the selected granularity.
- More coarse: up to 30 topics
- Coarse: up to 50 topics
- Standard: up to 150 topics
- Fine: up to 200 topics
- More fine: up to 350 topics
The number of topics learned by the trained topic model can also be lower due to data quality issues. Ensure that the data requirements are met in terms of training conversation count, agent or customer turns in the conversations, and STT and redaction quality.
How to increase the topic count?
Verify that the training data quality requirements are met, as previously discussed. Also, ensure that they're met in terms of training conversation count, agent or customer turns in the conversations, and STT and redaction quality. If conversations continue for too many turns, you can experiment by removing their authentication portion.
Experimenting with a minimum turn-count filter (say 5, 10, 15, 20) while selecting training conversations in the training phase can help increase the number of topics learned. It can also help discard conversations which are too short to predict topics from.
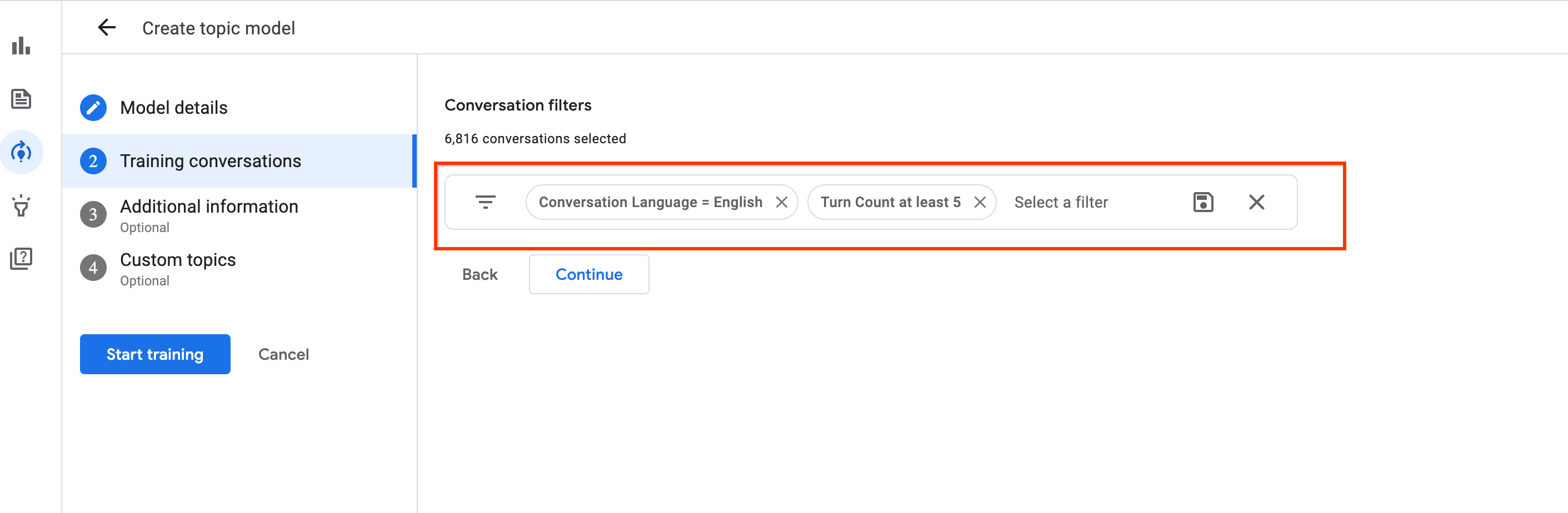
Why is training count smaller than conversation count?
The training volume count is the number of conversations used for training the topic model after downsampling the provided conversation data during the training phase.
During training, the conversations that don't have long enough utterances from the customer or are too short get filtered out. After the model is trained, the sum of the training volume in the Insights console represents the training/post-filtered conversation set.
Why does my model have more topics than the provided custom ones?
Depending on the model size, additional topics can be added to the model outputs. Model size impacts topic number in the output, but the actual number depends on the real topics learned in the model.
If you train a model with a "More fine" model size and expect it to learn up to 350 topics, but you bring only 30 custom topics into the training, you might see in the model outputs that only 32 topics are trained. This is because the model is trained on conversations with about 30 topics, not 350.