Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Halaman ini menjelaskan cara memantau kondisi dan performa lingkungan Cloud Composer secara keseluruhan dengan metrik utama di dasbor Monitoring.
Pengantar
Tutorial ini berfokus pada metrik pemantauan Cloud Composer utama yang dapat memberikan ringkasan yang baik tentang kondisi dan performa tingkat lingkungan.
Cloud Composer menawarkan beberapa metrik yang menjelaskan status lingkungan secara keseluruhan. Panduan pemantauan dalam tutorial ini didasarkan pada metrik yang ditampilkan di Dasbor pemantauan lingkungan Cloud Composer Anda.
Dalam tutorial ini, Anda akan mempelajari metrik utama yang berfungsi sebagai indikator utama masalah pada performa dan kesehatan lingkungan, serta panduan untuk menafsirkan setiap metrik menjadi tindakan korektif guna memastikan lingkungan tetap sehat. Anda juga akan menyiapkan aturan pemberitahuan untuk setiap metrik, menjalankan contoh DAG, dan menggunakan metrik dan pemberitahuan ini untuk mengoptimalkan performa lingkungan Anda.
Tujuan
Biaya
Tutorial ini menggunakan komponen Google Cloudyang dapat ditagih berikut:
Setelah menyelesaikan tutorial ini, Anda dapat menghindari penagihan berkelanjutan dengan menghapus resource yang Anda buat. Untuk detail selengkapnya, lihat Pembersihan.
Sebelum memulai
Bagian ini menjelaskan tindakan yang diperlukan sebelum Anda memulai tutorial.
Membuat dan mengonfigurasi project
Untuk tutorial ini, Anda memerlukan project Google Cloud. Konfigurasikan project dengan cara berikut:
Di Google Cloud konsol, pilih atau buat project:
Pastikan penagihan diaktifkan untuk project Anda. Pelajari cara memeriksa apakah penagihan diaktifkan pada project.
Pastikan Google Cloud pengguna project Anda memiliki peran berikut untuk membuat resource yang diperlukan:
- Environment and Storage Object Administrator
(
roles/composer.environmentAndStorageObjectAdmin) - Compute Admin (
roles/compute.admin) - Monitoring Editor (
roles/monitoring.editor)
- Environment and Storage Object Administrator
(
Mengaktifkan API untuk project Anda
Enable the Cloud Composer API.
Membuat lingkungan Cloud Composer
Buat lingkungan Cloud Composer 2.
Sebagai bagian dari prosedur ini,
Anda memberikan peran Ekstensi Agen Layanan Cloud Composer v2 API
(roles/composer.ServiceAgentV2Ext) ke akun Agen Layanan Composer. Cloud Composer menggunakan akun ini untuk melakukan operasi
di project Google Cloud Anda.
Mempelajari metrik utama untuk kesehatan dan performa tingkat lingkungan
Tutorial ini berfokus pada metrik utama yang dapat memberikan ringkasan yang baik tentang status dan performa lingkungan Anda secara keseluruhan.
Dasbor pemantauan di konsolGoogle Cloud berisi berbagai metrik dan diagram yang memungkinkan pemantauan tren di lingkungan Anda dan mengidentifikasi masalah pada komponen Airflow dan resource Cloud Composer.
Setiap lingkungan Cloud Composer memiliki dasbor Monitoring sendiri.
Pahami metrik utama di bawah dan temukan setiap metrik di dasbor Pemantauan:
Di Google Cloud console, buka halaman Environments.
Di daftar lingkungan, klik nama lingkungan Anda. Halaman Environment details akan terbuka.
Buka tab Monitoring.
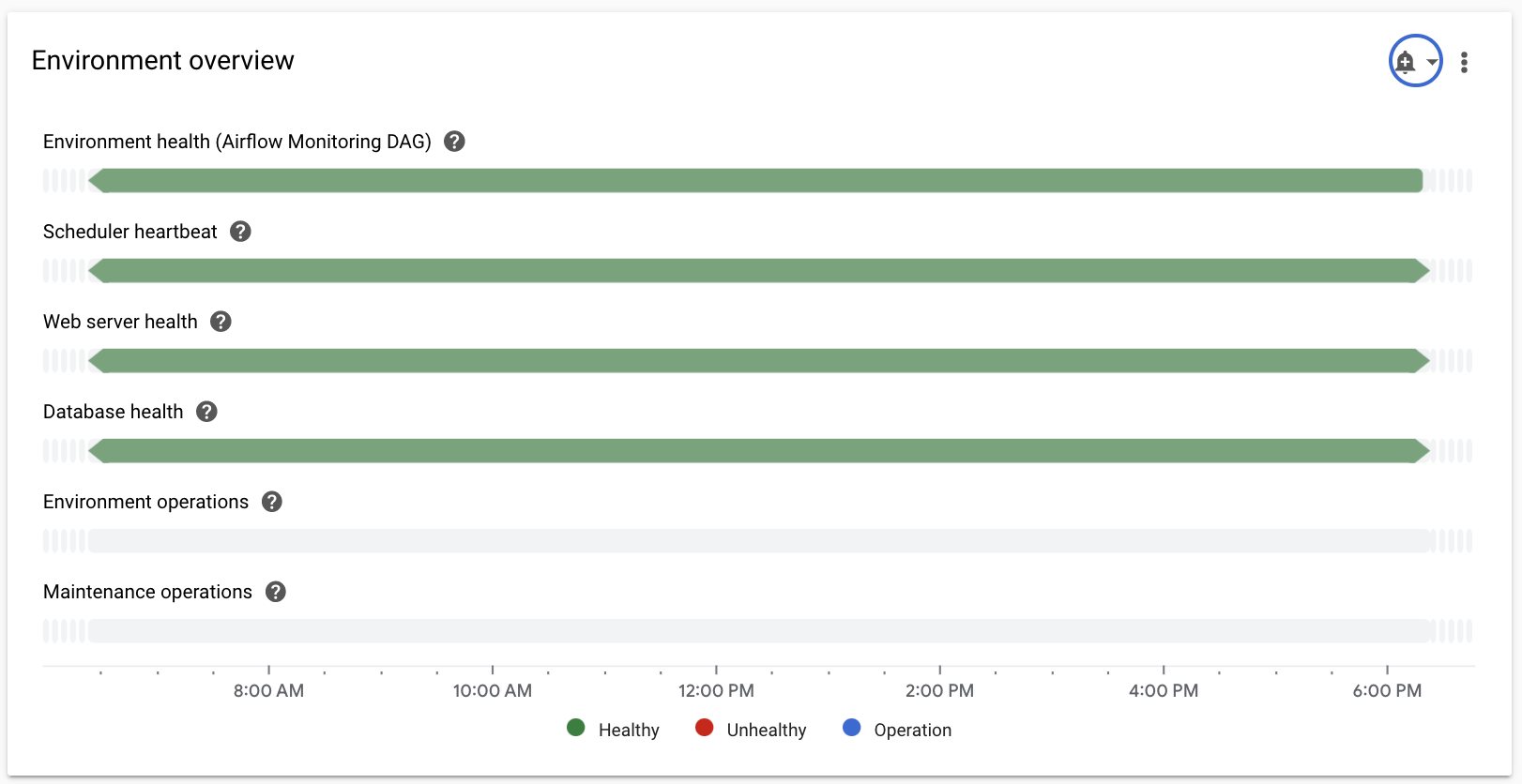
Pilih bagian Ringkasan, temukan item Ringkasan Lingkungan di dasbor, dan amati metrik Kondisi lingkungan (DAG pemantauan alur data).
Linimasa ini menunjukkan kondisi lingkungan Cloud Composer. Warna hijau pada status kesehatan lingkungan menunjukkan bahwa lingkungan sehat, sedangkan status lingkungan yang tidak sehat ditunjukkan dengan warna merah.
Setiap beberapa menit, Cloud Composer akan mengeksekusi DAG status aktif bernama
airflow_monitoring. Jika operasi DAG liveness berhasil diselesaikan, status kesehatannya adalahTrue. Jika DAG keaktifan gagal dijalankan (misalnya, karena pengosongan Pod, penghentian proses eksternal, atau pemeliharaan), status kesehatannya adalahFalse.
Pilih bagian SQL database, temukan item Database health di dasbor, dan amati metrik Database health.
Linimasa ini menunjukkan status koneksi ke instance Cloud SQL di lingkungan Anda. Status Database hijau menunjukkan konektivitas, sedangkan kegagalan untuk terhubung ditunjukkan dengan warna merah.
Pod pemantauan Airflow mengirim ping ke database secara berkala dan melaporkan status kesehatan sebagai
Truejika koneksi dapat dibuat atau sebagaiFalsejika tidak.
Di item Database health, amati metrik Database CPU usage dan Database memory usage.
Grafik penggunaan CPU Database menunjukkan penggunaan core CPU oleh instance database Cloud SQL di lingkungan Anda dibandingkan dengan total batas CPU database yang tersedia.
Grafik Penggunaan memori database menunjukkan penggunaan memori oleh instance database Cloud SQL di lingkungan Anda dibandingkan dengan total batas memori database yang tersedia.
Pilih bagian Penjadwal, temukan item Detak jantung penjadwal di dasbor, lalu amati metrik Detak jantung penjadwal.
Linimasa ini menunjukkan kondisi scheduler Airflow. Periksa area merah untuk mengidentifikasi masalah penjadwal Airflow. Jika lingkungan Anda memiliki lebih dari satu penjadwal, status heartbeat akan baik selama setidaknya salah satu penjadwal merespons.
Penjadwal dianggap tidak responsif jika heartbeat terakhir diterima lebih dari 30 detik (nilai default) sebelum waktu saat ini.
Pilih bagian DAG statistics, temukan item Zombie tasks killed di dasbor, dan amati metrik Zombie tasks killed.
Grafik ini menunjukkan jumlah tugas zombie yang dihentikan dalam jangka waktu kecil. Tugas zombie sering kali disebabkan oleh penghentian eksternal proses Airflow (seperti saat proses tugas dihentikan).
Penjadwal Airflow menghentikan tugas zombie secara berkala, yang tercermin dalam diagram ini.
Pilih bagian Workers, temukan item Worker container restarts di dasbor, dan amati metrik Worker container restarts.
- Grafik menunjukkan jumlah total mulai ulang untuk setiap penampung pekerja. Terlalu banyak memulai ulang penampung dapat memengaruhi ketersediaan layanan Anda atau layanan downstream lainnya yang menggunakannya sebagai dependensi.
Pelajari tolok ukur dan kemungkinan tindakan korektif untuk metrik utama
Daftar berikut menjelaskan nilai tolok ukur yang dapat menunjukkan masalah dan memberikan tindakan korektif yang dapat Anda lakukan untuk mengatasi masalah ini.
Kesehatan lingkungan (DAG pemantauan alur data)
Rasio keberhasilan kurang dari 90% selama periode 4 jam
Kegagalan dapat berarti pengusiran Pod atau penghentian pekerja karena lingkungan kelebihan beban atau tidak berfungsi. Area merah pada linimasa kesehatan lingkungan biasanya berkorelasi dengan area merah di status kesehatan lain dari setiap komponen lingkungan. Identifikasi akar masalah dengan meninjau metrik lain di dasbor Monitoring.
Kesehatan database
Rasio keberhasilan kurang dari 95% selama jangka waktu 4 jam
Kegagalan berarti ada masalah dengan konektivitas ke database Airflow, yang dapat disebabkan oleh error database atau periode nonaktif karena database kelebihan beban (misalnya, karena penggunaan CPU atau memori yang tinggi atau latensi yang lebih tinggi saat terhubung ke database). Gejala ini paling sering disebabkan oleh DAG yang kurang optimal, seperti saat DAG menggunakan banyak variabel lingkungan atau Airflow yang ditentukan secara global. Identifikasi akar masalah dengan meninjau metrik penggunaan resource database SQL. Anda juga dapat memeriksa log penjadwal untuk menemukan error yang terkait dengan konektivitas database.
Penggunaan CPU dan memori database
Penggunaan CPU atau memori rata-rata lebih dari 80% dalam periode 12 jam
Database mungkin kelebihan beban. Analisis korelasi antara operasi DAG dan lonjakan penggunaan CPU atau memori database.
Anda dapat mengurangi beban database melalui DAG yang lebih efisien dengan kueri dan koneksi yang berjalan dan dioptimalkan, atau dengan menyebarkan beban secara lebih merata dari waktu ke waktu.
Sebagai alternatif, Anda dapat mengalokasikan lebih banyak CPU atau memori ke database. Resource database dikontrol oleh properti ukuran lingkungan lingkungan Anda, dan lingkungan harus diskalakan ke ukuran yang lebih besar.
Heartbeat scheduler
Rasio keberhasilan kurang dari 90% selama periode 4 jam
Tetapkan lebih banyak resource ke penjadwal atau tingkatkan jumlah penjadwal dari 1 menjadi 2 (direkomendasikan).
Tugas zombie dihentikan
Lebih dari satu tugas zombie per 24 jam
Alasan paling umum untuk tugas zombie adalah kekurangan resource CPU atau memori di cluster lingkungan Anda. Tinjau grafik penggunaan resource pekerja dan tetapkan lebih banyak resource ke pekerja Anda, atau tingkatkan waktu tunggu tugas zombie sehingga penjadwal menunggu lebih lama sebelum menganggap tugas sebagai zombie.
Mulai ulang penampung pekerja
Lebih dari satu mulai ulang per 24 jam
Alasan paling umum adalah kurangnya memori atau penyimpanan pekerja. Periksa konsumsi resource pekerja dan alokasikan lebih banyak memori atau penyimpanan ke pekerja Anda. Jika kekurangan resource bukan alasannya, pelajari memecahkan masalah insiden mulai ulang pekerja dan gunakan Kueri logging untuk menemukan alasan mulai ulang pekerja.
Membuat saluran notifikasi
Ikuti petunjuk yang diuraikan dalam Membuat saluran notifikasi untuk membuat saluran notifikasi email.
Untuk mengetahui informasi selengkapnya tentang saluran notifikasi, lihat Mengelola saluran notifikasi.
Membuat kebijakan pemberitahuan
Buat kebijakan pemberitahuan berdasarkan tolok ukur yang diberikan di bagian sebelumnya dalam tutorial ini untuk terus memantau nilai metrik dan menerima notifikasi saat metrik tersebut melanggar kondisi.
Konsol
Anda dapat menyiapkan pemberitahuan untuk setiap metrik yang ditampilkan di dasbor Monitoring dengan mengklik ikon lonceng di sudut item yang sesuai:
Temukan setiap metrik yang ingin Anda pantau di dasbor Monitoring dan klik ikon lonceng di sudut item metrik. Halaman Buat kebijakan pemberitahuan akan terbuka.
Di bagian Transform data:
Konfigurasikan bagian Within each time series seperti yang dijelaskan dalam konfigurasi kebijakan pemberitahuan untuk metrik.
Klik Next, lalu konfigurasikan bagian Configure alert trigger seperti yang dijelaskan dalam konfigurasi kebijakan pemberitahuan untuk metrik.
Klik Berikutnya.
Konfigurasi notifikasi. Luaskan menu Notification channels dan pilih saluran notifikasi yang Anda buat di langkah sebelumnya.
Klik Oke.
Di bagian Name the alert policy, isi kolom Alert policy name. Gunakan nama deskriptif untuk setiap metrik. Gunakan nilai "Namakan kebijakan pemberitahuan" seperti yang dijelaskan dalam konfigurasi kebijakan pemberitahuan untuk metrik.
Klik Berikutnya.
Tinjau kebijakan pemberitahuan, lalu klik Create policy.
Metrik kondisi lingkungan (DAG pemantauan Airflow) - konfigurasi kebijakan pemberitahuan
- Nama metrik: Cloud Composer Environment - Healthy
- API: composer.googleapis.com/environment/healthy
Filter:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Mengubah data > Dalam setiap deret waktu:
- Periode bergulir: Kustom
- Nilai kustom: 4
- Unit kustom: jam
- Fungsi periode berkelanjutan: pecahan benar
Mengonfigurasi pemicu pemberitahuan:
- Jenis kondisi: Nilai minimum
- Pemicu pemberitahuan: Deret waktu mana saja melanggar
- Posisi nilai minimum: Di bawah nilai minimum
- Nilai minimum: 90
- Nama kondisi: Kondisi kesehatan lingkungan
Mengonfigurasi notifikasi dan menyelesaikan pemberitahuan:
- Beri nama kebijakan pemberitahuan: Airflow Environment Health
Metrik kesehatan database - konfigurasi kebijakan pemberitahuan
- Nama metrik: Cloud Composer Environment - Database Healthy
- API: composer.googleapis.com/environment/database_health
Filter:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Mengubah data > Dalam setiap deret waktu:
- Periode bergulir: Kustom
- Nilai kustom: 4
- Unit kustom: jam
- Fungsi periode berkelanjutan: pecahan benar
Mengonfigurasi pemicu pemberitahuan:
- Jenis kondisi: Nilai minimum
- Pemicu pemberitahuan: Deret waktu mana saja melanggar
- Posisi nilai minimum: Di bawah nilai minimum
- Nilai minimum: 95
- Nama kondisi: Kondisi kesehatan database
Mengonfigurasi notifikasi dan menyelesaikan pemberitahuan:
- Beri nama kebijakan pemberitahuan: Airflow Database Health
Metrik penggunaan CPU database - konfigurasi kebijakan pemberitahuan
- Nama metrik: Lingkungan Cloud Composer - Pemakaian CPU Database
- API: composer.googleapis.com/environment/database/cpu/utilization
Filter:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Mengubah data > Dalam setiap deret waktu:
- Periode bergulir: Kustom
- Nilai kustom: 12
- Unit kustom: jam
- Fungsi periode berkelanjutan: rata-rata
Mengonfigurasi pemicu pemberitahuan:
- Jenis kondisi: Nilai minimum
- Pemicu pemberitahuan: Deret waktu mana saja melanggar
- Posisi nilai minimum: Di atas nilai minimum
- Nilai minimum: 80
- Nama kondisi: Kondisi penggunaan CPU database
Mengonfigurasi notifikasi dan menyelesaikan pemberitahuan:
- Beri nama kebijakan pemberitahuan: Airflow Database CPU Usage
Metrik penggunaan memori database - konfigurasi kebijakan pemberitahuan
- Nama metrik: Lingkungan Cloud Composer - Penggunaan Memori Database
- API: composer.googleapis.com/environment/database/memory/utilization
Filter:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Mengubah data > Dalam setiap deret waktu:
- Periode bergulir: Kustom
- Nilai kustom: 12
- Unit kustom: jam
- Fungsi periode berkelanjutan: rata-rata
Mengonfigurasi pemicu pemberitahuan:
- Jenis kondisi: Nilai minimum
- Pemicu pemberitahuan: Deret waktu mana saja melanggar
- Posisi nilai minimum: Di atas nilai minimum
- Nilai minimum: 80
- Nama kondisi: Kondisi penggunaan memori database
Mengonfigurasi notifikasi dan menyelesaikan pemberitahuan:
- Beri nama kebijakan pemberitahuan: Penggunaan Memori Database Airflow
Metrik heartbeat penjadwal - konfigurasi kebijakan pemberitahuan
- Nama metrik: Cloud Composer Environment - Scheduler Heartbeats
- API: composer.googleapis.com/environment/scheduler_heartbeat_count
Filter:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Mengubah data > Dalam setiap deret waktu:
- Periode bergulir: Kustom
- Nilai kustom: 4
- Unit kustom: jam
- Fungsi periode berkelanjutan: jumlah
Mengonfigurasi pemicu pemberitahuan:
- Jenis kondisi: Nilai minimum
- Pemicu pemberitahuan: Deret waktu mana saja melanggar
- Posisi nilai minimum: Di bawah nilai minimum
Nilai minimum: 216
- Anda bisa mendapatkan angka ini dengan menjalankan kueri yang menggabungkan nilai
_scheduler_heartbeat_count_meandi Editor Kueri Metrics Explorer.
- Anda bisa mendapatkan angka ini dengan menjalankan kueri yang menggabungkan nilai
Nama kondisi: Kondisi heartbeat penjadwal
Mengonfigurasi notifikasi dan menyelesaikan pemberitahuan:
- Beri nama kebijakan pemberitahuan: Airflow Scheduler Heartbeat
Metrik tugas zombie dihentikan - konfigurasi kebijakan pemberitahuan
- Nama metrik: Lingkungan Cloud Composer - Tugas Zombie Dihentikan
- API: composer.googleapis.com/environment/zombie_task_killed_count
Filter:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Mengubah data > Dalam setiap deret waktu:
- Periode bergulir: 1 hari
- Fungsi periode berkelanjutan: jumlah
Mengonfigurasi pemicu pemberitahuan:
- Jenis kondisi: Nilai minimum
- Pemicu pemberitahuan: Deret waktu mana saja melanggar
- Posisi nilai minimum: Di atas nilai minimum
- Nilai minimum: 1
- Nama kondisi: Kondisi tugas zombie
Mengonfigurasi notifikasi dan menyelesaikan pemberitahuan:
- Beri nama kebijakan pemberitahuan: Airflow Zombie Tasks
Metrik mulai ulang penampung pekerja - konfigurasi kebijakan pemberitahuan
- Nama metrik: Kubernetes Container - Restart Count
- API: kubernetes.io/container/restart_count
Filter:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION] pod_name =~ airflow-worker-.*|airflow-k8s-worker-.* container_name =~ airflow-worker|base cluster_name = [CLUSTER_NAME]CLUSTER_NAMEadalah nama cluster lingkungan Anda yang dapat ditemukan di bagian Konfigurasi Lingkungan > Resource > cluster GKE di konsol Google Cloud .Mengubah data > Dalam setiap deret waktu:
- Periode bergulir: 1 hari
- Fungsi periode berkelanjutan: tarif
Mengonfigurasi pemicu pemberitahuan:
- Jenis kondisi: Nilai minimum
- Pemicu pemberitahuan: Deret waktu mana saja melanggar
- Posisi nilai minimum: Di atas nilai minimum
- Nilai minimum: 1
- Nama kondisi: Kondisi dimulai ulang penampung pekerja
Mengonfigurasi notifikasi dan menyelesaikan pemberitahuan:
- Beri nama kebijakan pemberitahuan: Airflow Worker Restarts
Terraform
Jalankan skrip Terraform yang membuat saluran notifikasi email dan mengupload kebijakan pemberitahuan untuk metrik utama yang diberikan dalam tutorial ini berdasarkan benchmark masing-masing:
- Simpan contoh file Terraform di komputer lokal Anda.
Ganti kode berikut:
PROJECT_ID: Project ID project Anda. Misalnya,example-project.EMAIL_ADDRESS: alamat email yang harus diberi tahu jika pemberitahuan dipicu.ENVIRONMENT_NAME: nama lingkungan Cloud Composer Anda. Contoh,example-composer-environment.CLUSTER_NAME: nama cluster lingkungan Anda yang dapat ditemukan di bagian Konfigurasi Lingkungan > Resource > cluster GKE di Google Cloud console.
resource "google_monitoring_notification_channel" "basic" {
project = "PROJECT_ID"
display_name = "Test Notification Channel"
type = "email"
labels = {
email_address = "EMAIL_ADDRESS"
}
# force_delete = false
}
resource "google_monitoring_alert_policy" "environment_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Environment Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Environment health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/healthy\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.9
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "database_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Database Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database_health\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.95
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_cpu_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database CPU Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database CPU usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/cpu/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_memory_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database Memory Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database memory usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/memory/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_scheduler_heartbeat" {
project = "PROJECT_ID"
display_name = "Airflow Scheduler Heartbeat"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Scheduler heartbeat condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/scheduler_heartbeat_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 216 // Threshold is 90% of the average for composer.googleapis.com/environment/scheduler_heartbeat_count metric in an idle environment
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_COUNT"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_zombie_task" {
project = "PROJECT_ID"
display_name = "Airflow Zombie Tasks"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Zombie tasks condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/zombie_task_killed_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_SUM"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_worker_restarts" {
project = "PROJECT_ID"
display_name = "Airflow Worker Restarts"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Worker container restarts condition"
condition_threshold {
filter = "resource.type = \"k8s_container\" AND (resource.labels.cluster_name = \"CLUSTER_NAME\" AND resource.labels.container_name = monitoring.regex.full_match(\"airflow-worker|base\") AND resource.labels.pod_name = monitoring.regex.full_match(\"airflow-worker-.*|airflow-k8s-worker-.*\")) AND metric.type = \"kubernetes.io/container/restart_count\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_RATE"
}
}
}
}
Menguji kebijakan pemberitahuan
Bagian ini menjelaskan cara menguji kebijakan pemberitahuan yang dibuat dan menafsirkan hasil.
Mengupload contoh DAG
Contoh DAG memory_consumption_dag.py yang diberikan dalam tutorial ini meniru penggunaan memori pekerja yang intensif. DAG berisi 4 tugas, setiap
tugas menulis data ke string contoh, yang menggunakan memori sebesar 380 MB. DAG contoh
dijadwalkan untuk berjalan setiap 2 menit dan akan mulai berjalan secara otomatis
setelah Anda menguploadnya ke lingkungan Composer.
Upload contoh DAG berikut ke lingkungan yang Anda buat di langkah sebelumnya:
from datetime import datetime
import sys
import time
from airflow import DAG
from airflow.operators.python import PythonOperator
def ram_function():
data = ""
start = time.time()
for i in range(38):
data += "a" * 10 * 1000**2
time.sleep(0.2)
print(f"{i}, {round(time.time() - start, 4)}, {sys.getsizeof(data) / (1000 ** 3)}")
print(f"Size={sys.getsizeof(data) / (1000 ** 3)}GB")
time.sleep(30 - (time.time() - start))
print(f"Complete in {round(time.time() - start, 2)} seconds!")
with DAG(
dag_id="memory_consumption_dag",
start_date=datetime(2023, 1, 1, 1, 1, 1),
schedule="1/2 * * * *",
catchup=False,
) as dag:
for i in range(4):
PythonOperator(
task_id=f"task_{i+1}",
python_callable=ram_function,
retries=0,
dag=dag,
)
Menafsirkan pemberitahuan dan metrik di Monitoring
Tunggu sekitar 10 menit setelah contoh DAG mulai berjalan dan evaluasi hasil pengujian:
Periksa kotak masuk email Anda untuk memverifikasi bahwa Anda telah menerima notifikasi dari Google Cloud Pemberitahuan dengan baris subjek yang dimulai dengan
[ALERT]. Konten pesan ini berisi detail insiden kebijakan pemberitahuan.Klik tombol Lihat Insiden di notifikasi email. Anda akan diarahkan ke Metrics Explorer. Tinjau detail insiden pemberitahuan:
Gambar 2. Detail insiden pemberitahuan (klik untuk memperbesar) Grafik metrik insiden menunjukkan bahwa metrik yang Anda buat melebihi ambang batas 1, yang berarti Airflow mendeteksi dan membunuh lebih dari 1 tugas zombie.
Di lingkungan Cloud Composer, buka tab Monitoring, buka bagian DAG statistics, dan temukan grafik Zombie tasks killed:
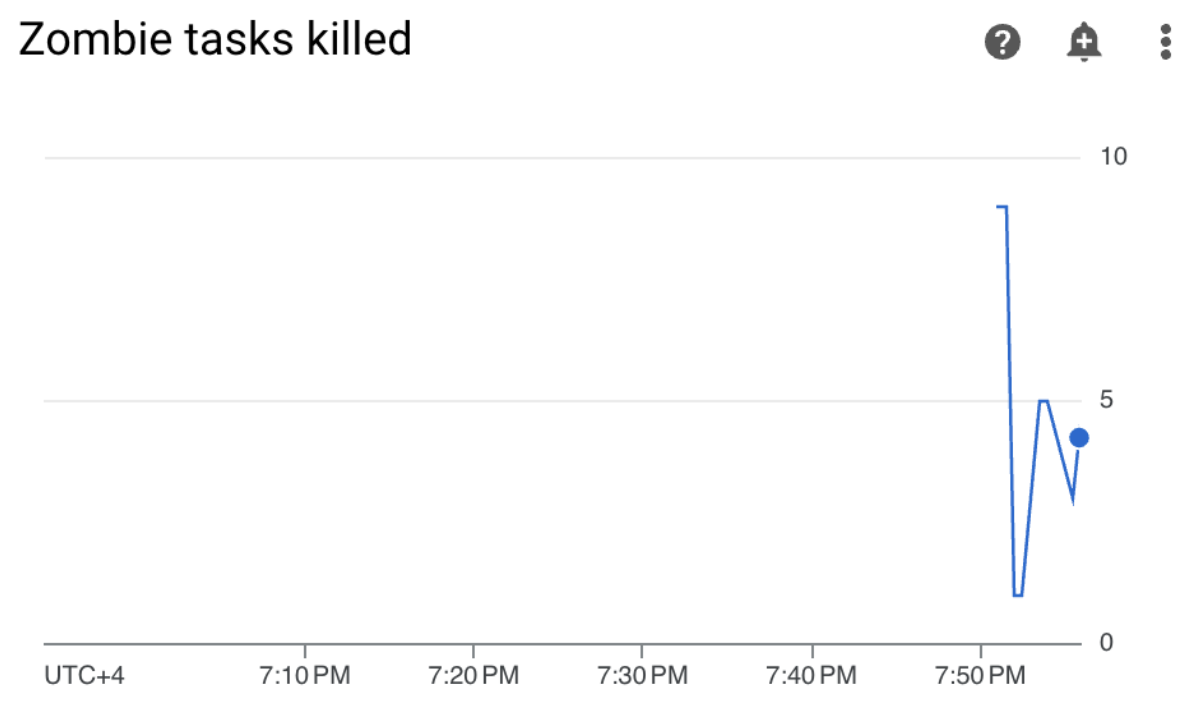
Gambar 3. Grafik tugas zombie (klik untuk memperbesar) Grafik menunjukkan bahwa Airflow menghentikan sekitar 20 tugas zombie hanya dalam 10 menit pertama setelah menjalankan contoh DAG.
Menurut tolok ukur dan tindakan korektif, alasan paling umum untuk tugas zombie adalah kurangnya memori atau CPU pekerja. Identifikasi akar penyebab tugas zombie dengan menganalisis penggunaan resource pekerja Anda.
Buka bagian Pekerja di dasbor Monitoring dan tinjau metrik penggunaan CPU dan memori pekerja:
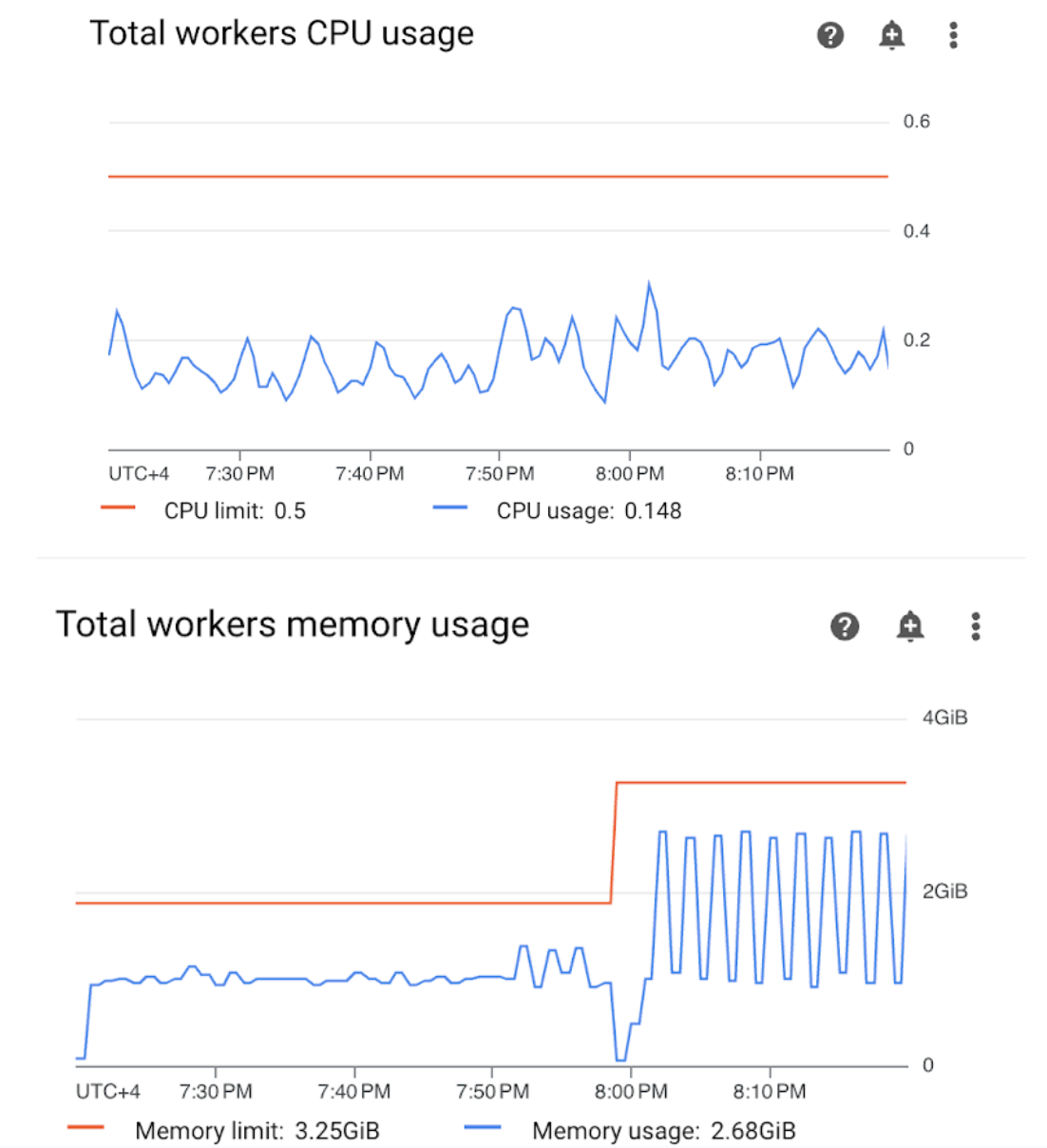
Gambar 4.Metrik penggunaan CPU dan memori pekerja (klik untuk memperbesar) Grafik Total penggunaan CPU pekerja menunjukkan bahwa penggunaan CPU pekerja berada di bawah 50% dari total batas yang tersedia setiap saat, sehingga CPU yang tersedia memadai. Grafik Total penggunaan memori pekerja menunjukkan bahwa menjalankan contoh DAG mengakibatkan batas memori yang dapat dialokasikan tercapai, yang setara dengan hampir 75% dari total batas memori yang ditampilkan pada grafik (GKE mencadangkan 25% dari 4 GiB memori pertama dan memori tambahan 100 MiB di setiap node untuk menangani penghapusan Pod).
Anda dapat menyimpulkan bahwa pekerja tidak memiliki resource memori untuk menjalankan contoh DAG dengan sukses.
Mengoptimalkan lingkungan dan mengevaluasi performanya
Berdasarkan analisis penggunaan resource pekerja, Anda perlu mengalokasikan lebih banyak memori ke pekerja agar semua tugas dalam DAG berhasil.
Di lingkungan Composer, buka tab DAG, klik nama contoh DAG (
memory_consumption_dag), lalu klik Jeda DAG.Alokasikan memori pekerja tambahan:
Di tab Environment configuration, temukan konfigurasi Resources > Workloads, lalu klik Edit.
Di item Worker, tingkatkan batas Memory. Dalam tutorial ini, gunakan 3,25 GB.
Simpan perubahan dan tunggu beberapa menit hingga pekerja dimulai ulang.
Buka tab DAG, klik nama DAG contoh (
memory_consumption_dag), lalu klik Hentikan Jeda DAG.
Buka Pemantauan dan pastikan tidak ada tugas zombie baru yang muncul setelah Anda memperbarui batas resource pekerja:
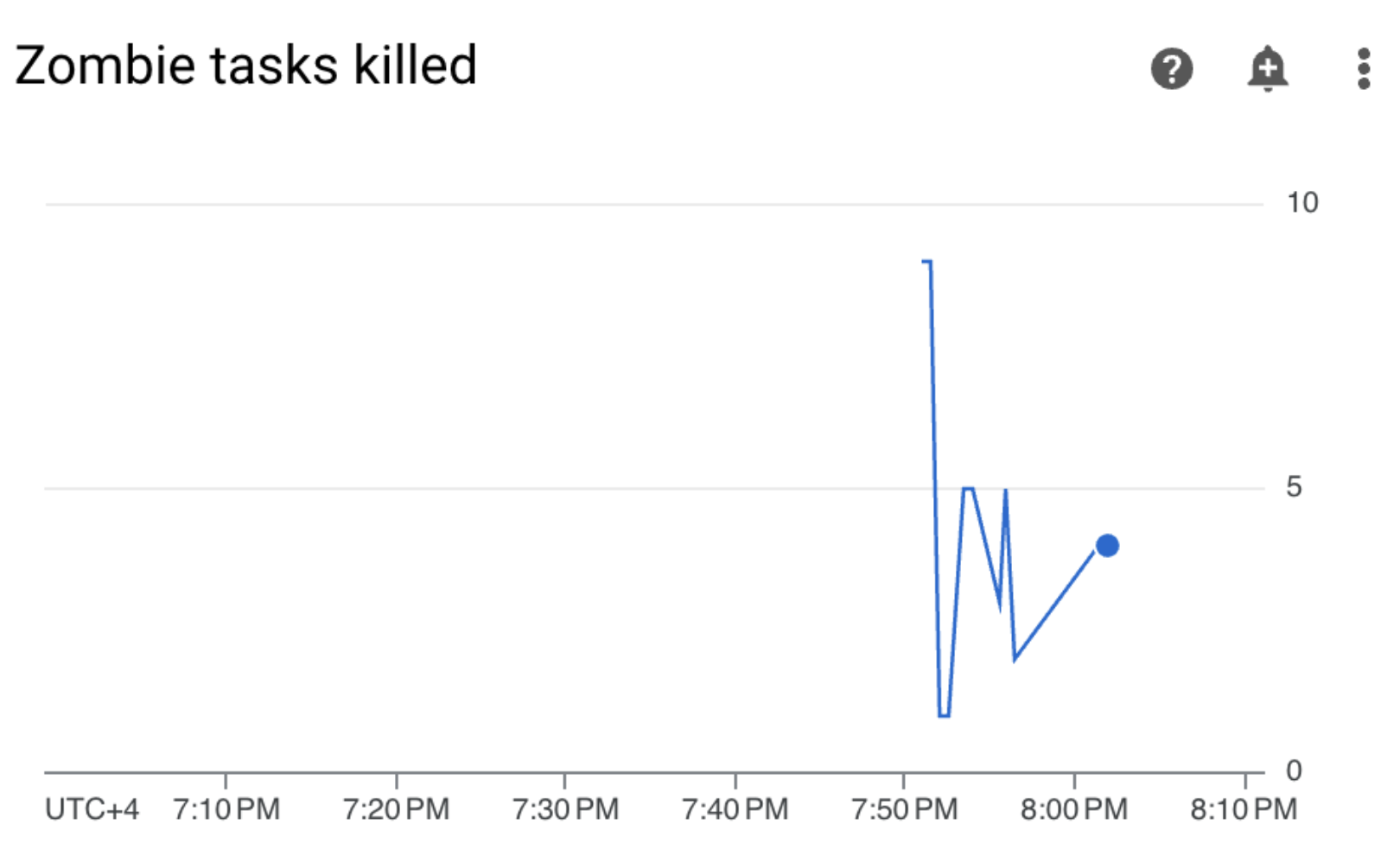
Ringkasan
Dalam tutorial ini, Anda telah mempelajari metrik performa dan kesehatan tingkat lingkungan utama, cara menyiapkan kebijakan pemberitahuan untuk setiap metrik, dan cara menafsirkan setiap metrik menjadi tindakan korektif. Kemudian, Anda menjalankan contoh DAG, mengidentifikasi akar masalah kesehatan lingkungan dengan bantuan pemberitahuan dan diagram Pemantauan, serta mengoptimalkan lingkungan dengan mengalokasikan lebih banyak memori ke pekerja. Namun, sebaiknya optimalkan DAG Anda untuk mengurangi konsumsi resource pekerja terlebih dahulu, karena tidak mungkin untuk meningkatkan resource di luar nilai minimum tertentu.
Pembersihan
Agar tidak dikenai biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam tutorial ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus setiap resource.
Menghapus project
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Menghapus resource satu per satu
Jika Anda berencana mempelajari beberapa tutorial dan panduan memulai, menggunakan kembali project dapat membantu Anda agar tidak melampaui batas kuota project.
Konsol
- Hapus lingkungan Cloud Composer. Anda juga akan menghapus bucket lingkungan selama prosedur ini.
- Hapus setiap kebijakan pemberitahuan yang Anda buat di Cloud Monitoring.
Terraform
- Pastikan skrip Terraform Anda tidak berisi entri untuk resource yang masih diperlukan oleh project Anda. Misalnya, Anda mungkin ingin tetap mengaktifkan beberapa API dan izin IAM masih ditetapkan (jika Anda menambahkan definisi tersebut ke skrip Terraform).
- Jalankan
terraform destroy. - Hapus bucket lingkungan secara manual. Cloud Composer tidak menghapusnya secara otomatis. Anda dapat melakukannya dari konsol Google Cloud atau Google Cloud CLI.
Langkah berikutnya
- Mengoptimalkan lingkungan
- Menskalakan lingkungan
- Mengelola label lingkungan dan mengelompokkan biaya lingkungan