Arsitektur
Diagram berikut menunjukkan arsitektur tingkat tinggi pipeline ekstraksi, pemuatan, dan transformasi (ELT) serverless menggunakan Workflows.

Dalam diagram sebelumnya, pertimbangkan platform retail yang secara berkala mengumpulkan peristiwa penjualan sebagai file dari berbagai toko, lalu menulis file tersebut ke bucket Cloud Storage. Peristiwa digunakan untuk memberikan metrik bisnis dengan mengimpor dan memproses di BigQuery. Arsitektur ini menyediakan sistem orkestrasi serverless yang andal untuk mengimpor file Anda ke BigQuery, dan dibagi menjadi dua modul berikut:
- Daftar file: Memelihara daftar file yang belum diproses yang ditambahkan ke bucket Cloud Storage dalam koleksi Firestore.
Modul ini berfungsi melalui Cloud Run Function yang dipicu oleh
peristiwa penyimpanan
Object Finalize, yang dihasilkan saat file baru ditambahkan ke bucket Cloud Storage. Nama file ditambahkan ke array
filesdari koleksi bernamanewdi Firestore. Alur kerja: Menjalankan alur kerja terjadwal. Cloud Scheduler memicu alur kerja yang menjalankan serangkaian langkah sesuai dengan sintaksis berbasis YAML untuk mengatur pemuatan, lalu mengubah data di BigQuery dengan memanggil fungsi Cloud Run. Langkah-langkah dalam alur kerja memanggil Cloud Run Function untuk menjalankan tugas berikut:
- Buat dan mulai tugas pemuatan BigQuery.
- Polling status tugas pemuatan.
- Buat dan mulai tugas kueri transformasi.
- Melakukan polling status tugas transformasi.
Menggunakan transaksi untuk mempertahankan daftar file baru di Firestore membantu memastikan tidak ada file yang terlewat saat alur kerja mengimpornya ke BigQuery. Eksekusi alur kerja yang terpisah dibuat idempoten dengan menyimpan metadata dan status tugas di Firestore.
Tujuan
- Buat database Firestore.
- Siapkan pemicu fungsi Cloud Run untuk melacak file yang ditambahkan ke bucket Cloud Storage di Firestore.
- Deploy fungsi Cloud Run untuk menjalankan dan memantau tugas BigQuery.
- Deploy dan jalankan alur kerja untuk mengotomatiskan proses.
Biaya
Dalam dokumen ini, Anda akan menggunakan komponen Google Cloudyang dapat ditagih berikut:
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Setelah menyelesaikan tugas yang dijelaskan dalam dokumen ini, Anda dapat menghindari penagihan berkelanjutan dengan menghapus resource yang Anda buat. Untuk mengetahui informasi selengkapnya, lihat Pembersihan.
Sebelum memulai
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Build, Cloud Run functions, Identity and Access Management, Resource Manager, and Workflows APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Buka halaman Welcome dan catat Project ID untuk digunakan di langkah berikutnya.
In the Google Cloud console, activate Cloud Shell.
Menyiapkan lingkungan Anda
Untuk menyiapkan lingkungan, buat database Firestore, clone contoh kode dari repositori GitHub, buat resource menggunakan Terraform, edit file YAML Workflows, dan instal persyaratan untuk generator file.
Untuk membuat database Firestore, lakukan langkah-langkah berikut:
Di konsol Google Cloud , buka halaman Firestore.
Klik Pilih mode native.
Di menu Pilih lokasi, pilih region tempat Anda ingin menghosting database Firestore. Sebaiknya pilih region yang dekat dengan lokasi fisik Anda.
Klik Buat database.
Pada Cloud Shell, clone repositori sumber:
cd $HOME && git clone https://github.com/GoogleCloudPlatform/workflows-demos cd workflows-demos/workflows-bigquery-loadDi Cloud Shell, buat resource berikut menggunakan Terraform:
terraform init terraform apply \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approveGanti kode berikut:
PROJECT_ID: Google Cloud project ID AndaREGION: lokasi geografis Google Cloud tertentu untuk menghosting resource Anda—misalnya,us-central1ZONE: lokasi dalam region untuk menghosting resource Anda—misalnya,us-central1-b
Anda akan melihat pesan yang mirip dengan berikut:
Apply complete! Resources: 7 added, 0 changed, 1 destroyed.Terraform dapat membantu Anda membuat, mengubah, dan mengupgrade infrastruktur dalam skala besar dengan aman dan terprediksi. Resource berikut dibuat di project Anda:
- Akun layanan dengan hak istimewa yang diperlukan untuk memastikan akses yang aman ke resource Anda.
- Set data BigQuery bernama
serverless_elt_datasetdan tabel bernamaword_countuntuk memuat file yang masuk. - Bucket Cloud Storage bernama
${project_id}-ordersbucketuntuk melakukan penyiapan file input. - Lima Cloud Run function berikut:
file_add_handlermenambahkan nama file yang ditambahkan ke bucket Cloud Storage ke koleksi Firestore.create_jobmembuat tugas pemuatan BigQuery baru dan mengaitkan file dalam koleksi Firebase dengan tugas tersebut.create_querymembuat tugas kueri BigQuery baru.poll_bigquery_jobmendapatkan status tugas BigQuery.run_bigquery_jobmemulai tugas BigQuery.
Dapatkan URL untuk fungsi Cloud Run
create_job,create_query,poll_job, danrun_bigquery_jobyang Anda deploy pada langkah sebelumnya.gcloud functions describe create_job | grep url gcloud functions describe poll_bigquery_job | grep url gcloud functions describe run_bigquery_job | grep url gcloud functions describe create_query | grep url
Outputnya mirip dengan hal berikut ini:
url: https://REGION-PROJECT_ID.cloudfunctions.net/create_job url: https://REGION-PROJECT_ID.cloudfunctions.net/poll_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/run_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/create_query
Catat URL ini karena diperlukan saat Anda men-deploy alur kerja.
Membuat dan men-deploy alur kerja
Di Cloud Shell, buka file sumber untuk alur kerja,
workflow.yaml:Ganti kode berikut:
CREATE_JOB_URL: URL fungsi untuk membuat tugas baruPOLL_BIGQUERY_JOB_URL: URL fungsi untuk melakukan polling status tugas yang sedang berjalanRUN_BIGQUERY_JOB_URL: URL fungsi untuk memulai tugas pemuatan BigQueryCREATE_QUERY_URL: URL fungsi untuk memulai tugas kueri BigQueryBQ_REGION: region BigQuery tempat data disimpan—misalnya,USBQ_DATASET_TABLE_NAME: nama tabel set data BigQuery dalam formatPROJECT_ID.serverless_elt_dataset.word_count
Deploy file
workflow:gcloud workflows deploy WORKFLOW_NAME \ --location=WORKFLOW_REGION \ --description='WORKFLOW_DESCRIPTION' \ --service-account=workflow-runner@PROJECT_ID. \ --source=workflow.yamlGanti kode berikut:
WORKFLOW_NAME: nama unik alur kerjaWORKFLOW_REGION: region tempat alur kerja di-deploy—misalnya,us-central1WORKFLOW_DESCRIPTION: deskripsi alur kerja
Buat lingkungan virtual Python 3 dan instal persyaratan untuk generator file:
sudo apt-get install -y python3-venv python3 -m venv env . env/bin/activate cd generator pip install -r requirements.txt
Membuat file untuk diimpor
Skrip Python
gen.pymenghasilkan konten acak dalam format Avro. Skemanya sama dengan tabelword_countBigQuery. File Avro ini disalin ke bucket Cloud Storage yang ditentukan.Di Cloud Shell, buat file:
python gen.py -p PROJECT_ID \ -o PROJECT_ID-ordersbucket \ -n RECORDS_PER_FILE \ -f NUM_FILES \ -x FILE_PREFIXGanti kode berikut:
RECORDS_PER_FILE: jumlah data dalam satu fileNUM_FILES: jumlah total file yang akan diuploadFILE_PREFIX: awalan untuk nama file yang dihasilkan
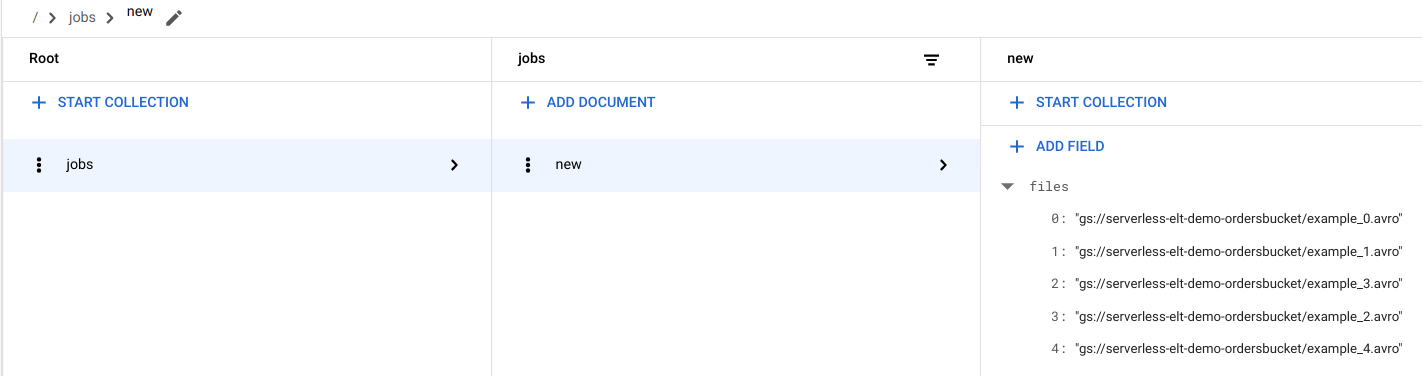
Melihat entri file di Firestore
Saat file disalin ke Cloud Storage, fungsi Cloud Run
handle_new_filedipicu. Fungsi ini menambahkan daftar file ke array daftar file dalam dokumennewdi koleksijobsFirestore.Untuk melihat daftar file, di konsol Google Cloud , buka halaman Data Firestore.
Memicu alur kerja
Workflows menghubungkan serangkaian tugas serverless dari Google Cloud dan layanan API. Setiap langkah dalam alur kerja ini berjalan sebagai fungsi Cloud Run dan statusnya disimpan di Firestore. Semua panggilan ke fungsi Cloud Run diautentikasi menggunakan akun layanan alur kerja.
Di Cloud Shell, jalankan alur kerja:
gcloud workflows execute WORKFLOW_NAME
Diagram berikut menunjukkan langkah-langkah yang digunakan dalam alur kerja:

Alur kerja dibagi menjadi dua bagian: alur kerja utama dan sub-alur kerja. Alur kerja utama menangani pembuatan tugas dan eksekusi bersyarat, sedangkan sub-alur kerja menjalankan tugas BigQuery. Alur kerja ini melakukan operasi berikut:
- Fungsi
create_jobCloud Run membuat objek tugas baru, mendapatkan daftar file yang ditambahkan ke Cloud Storage dari dokumen Firestore, dan mengaitkan file dengan tugas pemuatan. Jika tidak ada file yang akan dimuat, fungsi tidak akan membuat tugas baru. - Fungsi Cloud Run
create_querymengambil kueri yang perlu dieksekusi bersama dengan region BigQuery tempat kueri harus dieksekusi. Fungsi ini membuat tugas di Firestore dan menampilkan ID tugas. - Fungsi Cloud Run
run_bigquery_jobmendapatkan ID tugas yang perlu dijalankan, lalu memanggil BigQuery API untuk mengirimkan tugas. - Daripada menunggu hingga tugas selesai di fungsi Cloud Run, Anda dapat melakukan polling status tugas secara berkala.
Melihat status tugas
Anda dapat melihat daftar file dan status tugas.
Di konsolGoogle Cloud , buka halaman Data Firestore.
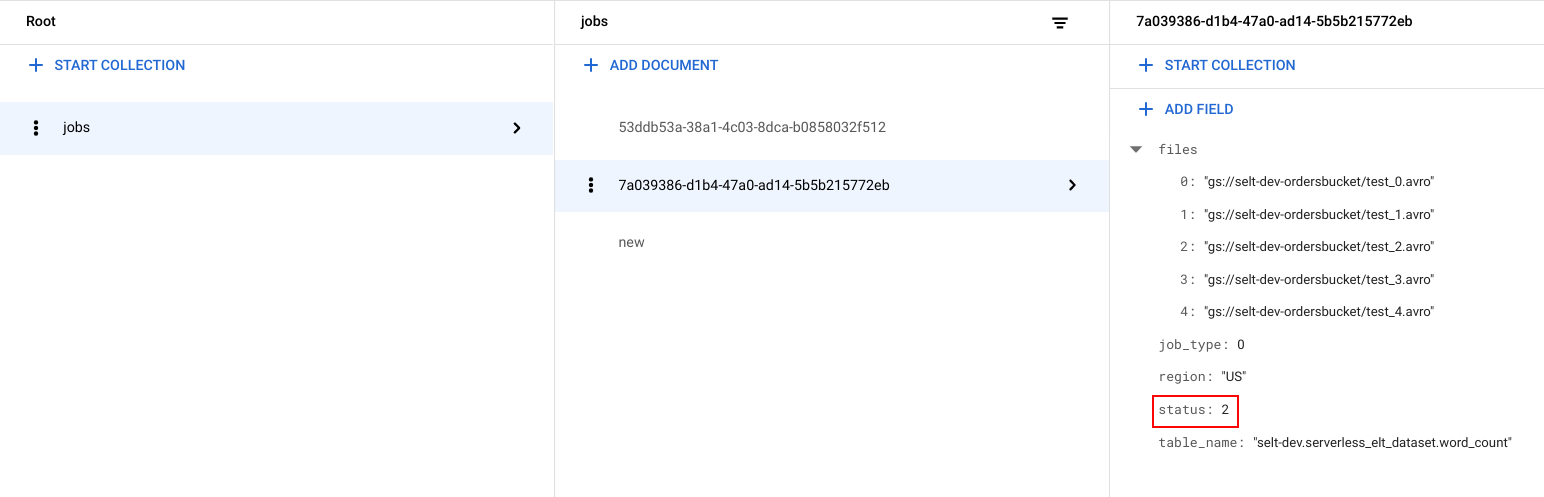
ID unik (UUID) dibuat untuk setiap tugas. Untuk melihat
job_typedanstatus, klik ID tugas. Setiap tugas dapat memiliki salah satu jenis dan status berikut:job_type: Jenis tugas yang dijalankan oleh alur kerja dengan salah satu nilai berikut:- 0: Muat data ke BigQuery.
- 1: Jalankan kueri di BigQuery.
status: Status tugas saat ini dengan salah satu nilai berikut:- 0: Tugas telah dibuat, tetapi belum dimulai.
- 1: Tugas sedang berjalan.
- 2: Tugas berhasil menyelesaikan eksekusinya.
- 3: Terjadi error dan tugas tidak berhasil diselesaikan.
Objek tugas juga berisi atribut metadata seperti region set data BigQuery, nama tabel BigQuery, dan jika merupakan tugas kueri, string kueri yang sedang dijalankan.
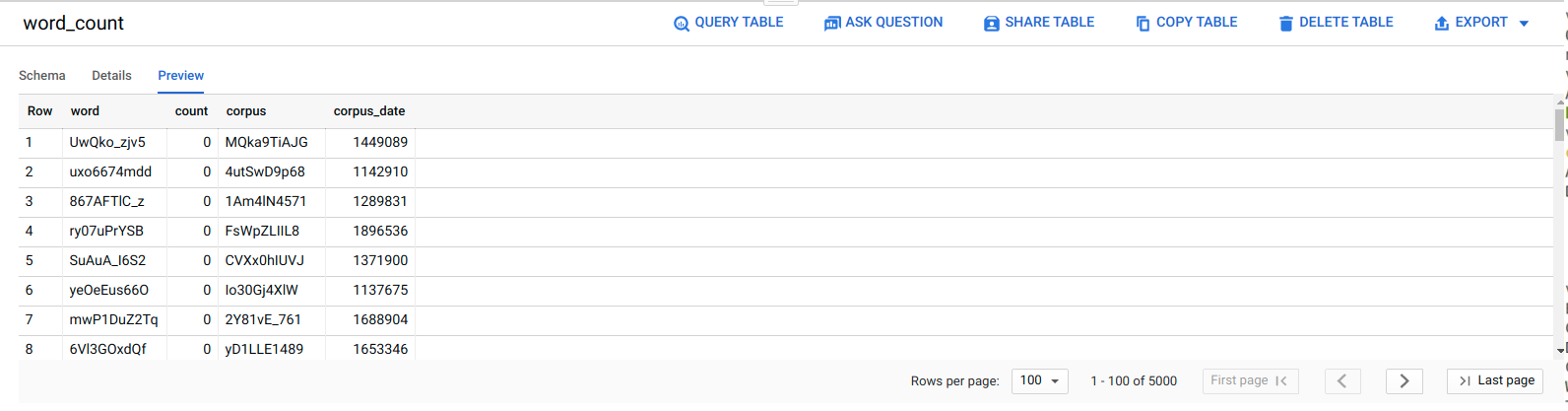
Melihat data di BigQuery
Untuk mengonfirmasi bahwa tugas ELT berhasil, pastikan data muncul di tabel.
Di konsol Google Cloud , buka halaman Editor BigQuery.
Klik tabel
serverless_elt_dataset.word_count.Klik tab Pratinjau.
Menjadwalkan alur kerja
Untuk menjalankan alur kerja secara berkala sesuai jadwal, Anda dapat menggunakan Cloud Scheduler.
Pembersihan
Cara termudah untuk menghilangkan penagihan adalah dengan menghapus Google Cloud project yang Anda buat untuk tutorial. Atau, Anda dapat menghapus resource satu per satu.Menghapus resource satu per satu
Di Cloud Shell, hapus semua resource yang dibuat menggunakan Terraform:
cd $HOME/bigquery-workflows-load terraform destroy \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approve
Di konsol Google Cloud , buka halaman Data Firestore.
Di samping Jobs, klik Menu, lalu pilih Delete.
Menghapus project
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Langkah berikutnya
- Untuk mempelajari lebih lanjut BigQuery, lihat dokumentasi BigQuery.
- Pelajari cara membangun pipeline machine learning kustom serverless.
- Untuk mengetahui lebih banyak tentang arsitektur referensi, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud.