기능 목록
Vision API에서는 현재 다음 기능을 사용할 수 있습니다.
| 모든 기능 유형 |

|
- 이미지의 광학 문자 인식(OCR), 텍스트 인식 후 머신 코딩된 텍스트로 변환 이미지에서 UTF-8 텍스트를 찾아 추출합니다.
- 이미지: 큰 이미지 내의 희소 텍스트 영역에 최적화되어 있습니다.
- 응답: 텍스트, 경계 상자,
textAnnotations로 식별된 단어 목록과 OCR로 감지된 텍스트(fullTextAnnotation)의 계층 구조를 모두 반환합니다.
- 추출된 텍스트의 계층 구조
- TextAnnotation -> 페이지 -> 블록 -> 단락 -> 단어 -> 기호
- 페이지의 각 구조적 구성요소에는 인식된 언어, 줄바꿈 등 자체 속성이 추가로 있을 수 있습니다.
- 지원 언어: 현재 지원, 매핑, 실험용 언어로 작동합니다.
- 특징의 열거형 값:
TEXT_DETECTION
|

|
- 파일(PDF/TIFF)이나 밀집 텍스트 이미지의 광학 문자 인식(OCR), 밀집 텍스트 인식 및 머신 코딩된 텍스트로 변환
- 파일: 문서 파일(PDF/TIFF)에 최적화되었습니다.
- 이미지: 이미지(문서 형식의 이미지) 속 밀집 텍스트 영역 및 필기 입력이 포함된 이미지에 최적화되어 있습니다.
- 응답: OCR로 감지된 텍스트(
fullTextAnnotation)의 계층 구조를 반환합니다.
- 추출된 텍스트의 계층 구조
- TextAnnotation -> 페이지 -> 블록 -> 단락 -> 단어 -> 기호
- 페이지의 각 구조적 구성요소에는 인식된 언어, 줄바꿈 등 자체 속성이 추가로 있을 수 있습니다.
- 지원 언어: 현재 지원, 매핑, 실험용 언어로 작동합니다.
- 특징의 열거형 값:
DOCUMENT_TEXT_DETECTION
DOCUMENT_TEXT_DETECTION 및 TEXT_DETECTION이 요청되면 우선 적용됩니다.
|

|
- 랜드마크 이미지 속 랜드마크 이름, 신뢰도 점수, 경계 상자를 제공합니다.
- 인식된 항목의 좌표를 제공합니다.
|

|
- 파일 속 로고의 식별된 항목에 대한 텍스트 설명, 신뢰도 점수, 경계 다각형을 제공합니다.
|
|
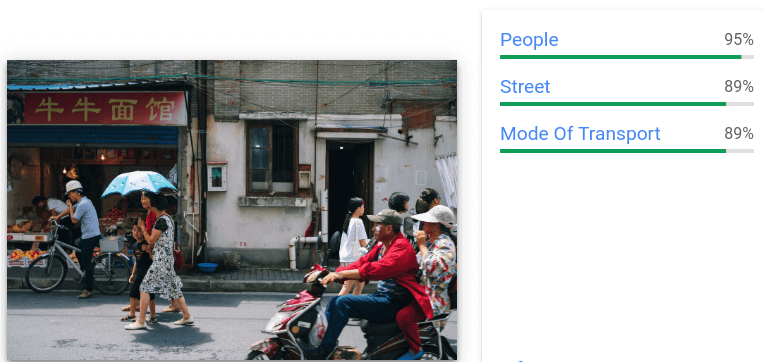
- 이미지에 대한 일반화된 라벨을 제공합니다.
- 각 라벨에 대해 텍스트 설명, 신뢰도 점수, 적합성 평점을 반환합니다.
|

|
- 이미지에서 가장 두드러진 색상을 반환합니다.
- 각 색상은 RGBA 색상 공간으로 표시되고, 신뢰도 점수가 있으며, [0, 1] 색상이 차지하는 픽셀의 비율을 표시합니다.
|

|
|
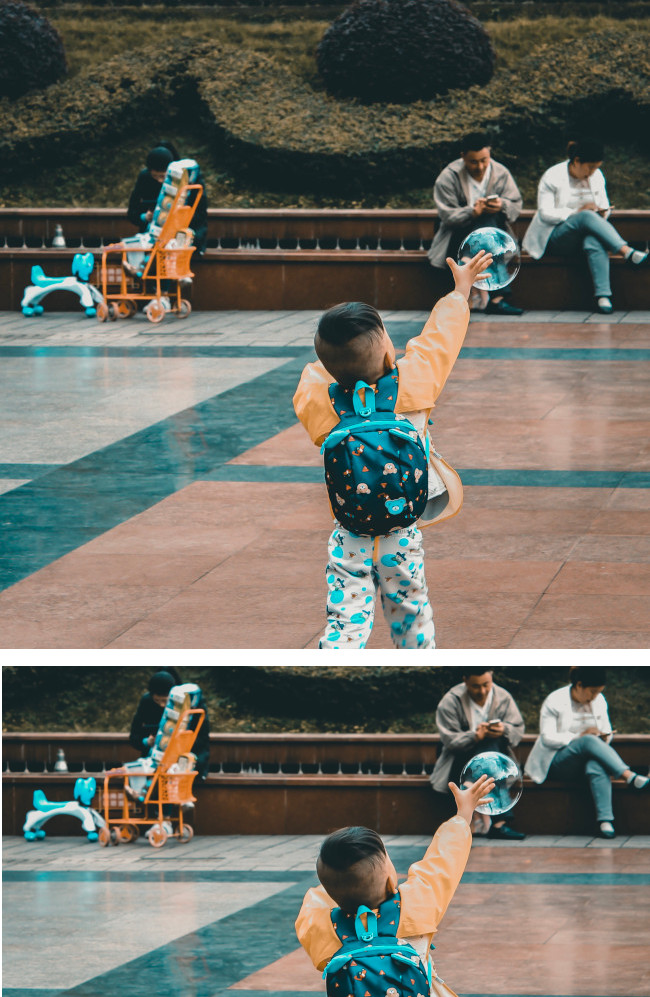
|
- 각 요청의 원본 이미지를 바탕으로 잘린 이미지, 신뢰도 점수, 이 두드러진 영역의 중요도 비율을 제공합니다.
- 단일 이미지에 최대 16개의 이미지 비율 값(너비:높이)을 제공할 수 있습니다.
|

|
- 이미지와 관련된 여러 웹 콘텐츠를 제공합니다.
- 다음 정보를 반환합니다.
- 웹 항목: 웹상의 유사한 이미지에서 추론한 항목(라벨/설명)입니다.
- 전체 일치 이미지: 크기에 제한 없이 인터넷상의 모든 이미지와 완전히 일치하는 URL의 목록입니다.
- 부분 일치 이미지: 원본 이미지의 잘린 버전 등 핵심 특징을 공유하는 이미지의 URL 목록입니다.
- 일치 이미지가 있는 페이지: 위에 설명된 조건을 충족하는 이미지가 있는 웹페이지(페이지 URL, 페이지 제목, 일치 이미지 URL로 식별)의 목록입니다.
- 시각적으로 유사한 이미지: 원본 이미지의 일부 특징을 공유하는 이미지의 URL 목록입니다.
- 최선의 추측 라벨: 인터넷상의 유사한 이미지에서 추론한 요청 이미지의 주제와 가장 가까운 라벨을 반환합니다.
|
|
adult, spoof, medical, violence, racy의 선정적인 콘텐츠 카테고리의 일치 가능성 평점을 제공합니다.- 일치 가능성 평점은
UNKNOWN, VERY_UNLIKELY, UNLIKELY, POSSIBLE, LIKELY, VERY_LIKELY의 6가지 값으로 표시됩니다.
|

|
- 경계 다각형이 있는 얼굴을 찾아 눈, 귀, 코, 입 등과 같은 얼굴의 '특징'과 해당 신뢰값을 식별합니다.
- 감정 상태(기쁨, 슬픔, 분노, 놀람 등)와 일반 이미지 속성(노출 부족, 흐리게 처리, 모자 착용)에 대한 일치 가능성 평점을 반환합니다.
- 일치 가능성 평점은
UNKNOWN, VERY_UNLIKELY, UNLIKELY, POSSIBLE, LIKELY, VERY_LIKELY의 6가지 값으로 표시됩니다.
- 특정 개인의 얼굴 인식은 지원되지 않습니다.
|
1.
이미지 크레딧:
니코레이 보로비에,
Unsplash(주석 추가됨)
↩
2.
이미지 크레딧:
로버트 스코블
(CC BY 2.0, 주석 추가됨)
↩
3.
이미지 크레딧:
알렉스 나이트, Unsplash
↩
4.
이미지 크레딧:
제레미 비숍, Unsplash
↩
5.
이미지 크레딧:
보그단 다다, Unsplash
(주석 추가됨)
↩
6.
이미지 크레딧:
야스민 당고, Unsplash(원본 및 잘린 이미지 표시)
↩
7.
이미지 크레딧:
퀸텐 데 그라프,
Unsplash
↩
달리 명시되지 않는 한 이 페이지의 콘텐츠에는 Creative Commons Attribution 4.0 라이선스에 따라 라이선스가 부여되며, 코드 샘플에는 Apache 2.0 라이선스에 따라 라이선스가 부여됩니다. 자세한 내용은 Google Developers 사이트 정책을 참조하세요. 자바는 Oracle 및/또는 Oracle 계열사의 등록 상표입니다.
최종 업데이트: 2025-10-19(UTC)
[[["이해하기 쉬움","easyToUnderstand","thumb-up"],["문제가 해결됨","solvedMyProblem","thumb-up"],["기타","otherUp","thumb-up"]],[["이해하기 어려움","hardToUnderstand","thumb-down"],["잘못된 정보 또는 샘플 코드","incorrectInformationOrSampleCode","thumb-down"],["필요한 정보/샘플이 없음","missingTheInformationSamplesINeed","thumb-down"],["번역 문제","translationIssue","thumb-down"],["기타","otherDown","thumb-down"]],["최종 업데이트: 2025-10-19(UTC)"],[],[]]