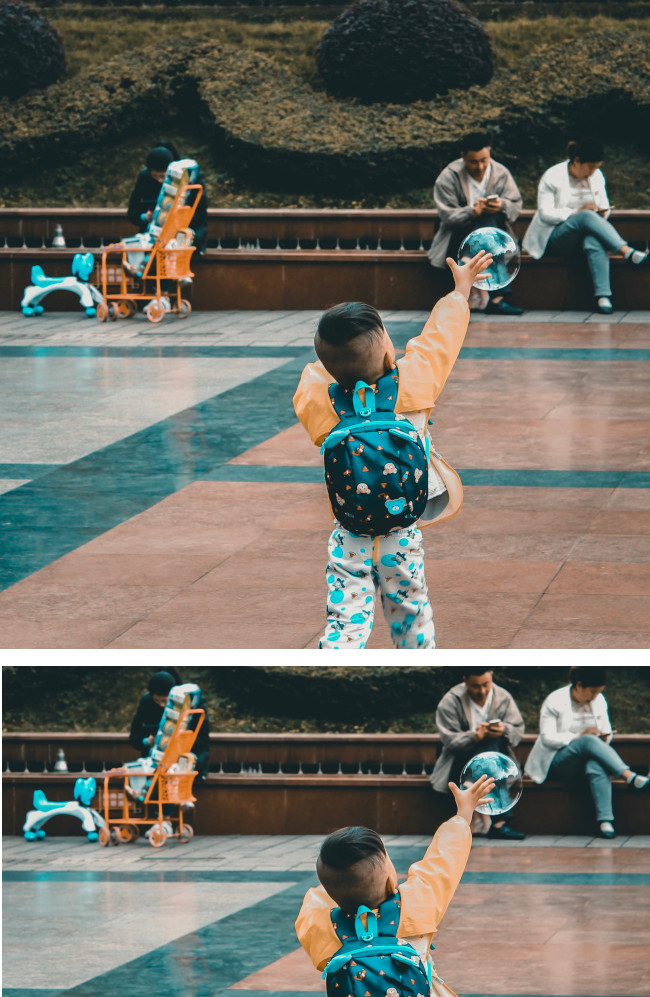Reconocimiento óptico de caracteres (OCR) para una imagen; reconocimiento de texto y conversión a texto codificado para máquina. Identifica y extrae texto UTF-8 en una imagen.
Imágenes: Optimizado para áreas de texto dispersas dentro de una imagen más grande.
Respuesta: Muestra una lista de palabras identificadas con texto, cuadros de límite y puntuaciones de confianza (textAnnotations), así como la jerarquía estructural del texto detectado de OCR (fullTextAnnotation).
Reconocimiento óptico de caracteres (OCR) para un archivo (PDF/TIFF) o imagen de texto denso; reconocimiento de texto denso y conversión a texto codificado para máquina.
Archivos: Optimizado para archivos de documentos (PDF/TIFF).
Imágenes: Optimizado para áreas de texto densas en una imagen (imágenes que son documentos) e imágenes que contienen escritura a mano.
Respuesta: Muestra la jerarquía estructural del texto detectado de OCR (fullTextAnnotation).
Cada color está representado en el espacio de color RGBA, tiene una puntuación de confianza y muestra la fracción de píxeles ocupados por el color [0, 1].
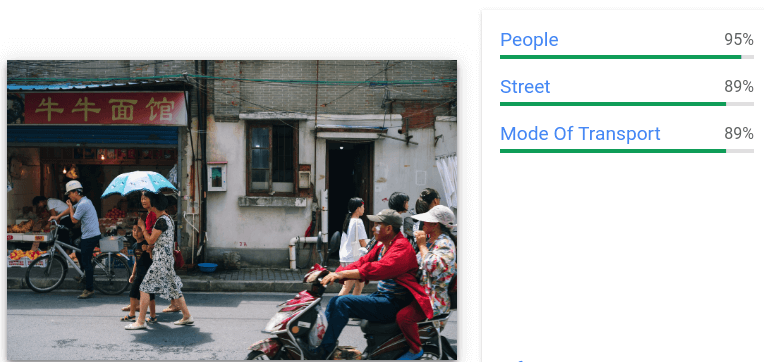
Proporciona etiquetas generales y anotaciones de cuadro de límite para varios objetos reconocidos en una sola imagen.
Para cada objeto detectado, se muestran los siguientes elementos: una descripción textual, una puntuación de confianza y vértices normalizados [0,1] para el polígono delimitador alrededor del objeto.
Proporciona un polígono de límite para la imagen recortada, una puntuación de confianza y una fracción de importancia de esta región destacada con respecto a la imagen original para cada solicitud.
Puedes proporcionar hasta 16 valores de proporción de imagen (ancho:alto) para una sola imagen.
Proporciona una serie de contenido web relacionado con una imagen.
Muestra la siguiente información:
Entidades web: Entidades inferidas (etiquetas/descripciones) a partir de imágenes similares en la Web.
Imágenes completas que coinciden: Una lista de URL de imágenes que coinciden por completo de cualquier tamaño en Internet.
Imágenes de coincidencia parcial: Una lista de URL de imágenes que comparten características de punto clave, como una versión recortada de la imagen original.
Páginas con imágenes coincidentes: Una lista de páginas web (que se identifican por la URL de la página, título de la página, URL de la imagen coincidente) con una imagen que cuenta con las condiciones que se describieron antes.
Imágenes visualmente similares: Una lista de URL de imágenes que comparten algunas características con la imagen original.
Etiqueta de mejor estimación: Una estimación aproximada del tema de la imagen solicitada inferida de imágenes similares de Internet.
Ubica los rostros con polígonos de límite y, también, identifica “puntos de referencia” faciales específicos, como ojos, oídos, nariz, boca, etc., junto con los valores de confianza correspondientes.
Muestra clasificaciones de probabilidad para la emoción (alegría, tristeza, enojo, sorpresa) y las propiedades generales de la imagen (subexpuesta, desenfocada, sombrero presente).
Las calificaciones de probabilidad se expresan en 6 valores diferentes: UNKNOWN, VERY_UNLIKELY, UNLIKELY, POSSIBLE, LIKELY o VERY_LIKELY.
[[["Fácil de comprender","easyToUnderstand","thumb-up"],["Resolvió mi problema","solvedMyProblem","thumb-up"],["Otro","otherUp","thumb-up"]],[["Difícil de entender","hardToUnderstand","thumb-down"],["Información o código de muestra incorrectos","incorrectInformationOrSampleCode","thumb-down"],["Faltan la información o los ejemplos que necesito","missingTheInformationSamplesINeed","thumb-down"],["Problema de traducción","translationIssue","thumb-down"],["Otro","otherDown","thumb-down"]],["Última actualización: 2025-10-19 (UTC)"],[],[]]