Anda dapat menggunakan Vertex AI SDK untuk Python guna secara terprogram mengevaluasi model bahasa generatif Anda.
Menginstal Vertex AI SDK
Untuk menginstal evaluasi cepat dari Vertex AI SDK untuk Python, jalankan perintah berikut berikut:
pip install --upgrade google-cloud-aiplatform[rapid_evaluation]
Untuk mengetahui informasi selengkapnya, lihat Menginstal Vertex AI SDK untuk Python.
Mengautentikasi Vertex AI SDK
Setelah menginstal Vertex AI SDK untuk Python, Anda perlu melakukan autentikasi. Hal berikut menjelaskan cara melakukan autentikasi dengan Vertex AI SDK jika Anda secara lokal dan jika Anda bekerja di Colaboratory:
Jika Anda mengembangkan aplikasi secara lokal, siapkan Kredensial Default Aplikasi (ADC) di lingkungan lokal Anda:
Instal Google Cloud CLI, lalu lakukan inisialisasi dengan menjalankan perintah berikut:
gcloud initBuat kredensial autentikasi lokal untuk Akun Google Anda:
gcloud auth application-default loginLayar login akan ditampilkan. Setelah login, kredensial Anda akan disimpan dalam file kredensial lokal yang digunakan oleh ADC. Untuk informasi selengkapnya tentang cara bekerja dengan ADC di lingkungan lokal, lihat Lingkungan pengembangan lokal.
Jika Anda bekerja di Colaboratory, jalankan perintah berikut di Sel Colab untuk melakukan autentikasi:
from google.colab import auth auth.authenticate_user()Perintah ini akan membuka jendela tempat Anda dapat menyelesaikan autentikasi.
Lihat Referensi SDK evaluasi cepat untuk mempelajari lebih lanjut SDK evaluasi cepat.
Membuat tugas evaluasi
Karena evaluasi sebagian besar didasarkan pada tugas dengan model AI generatif,
evaluasi memperkenalkan abstraksi tugas evaluasi untuk memfasilitasi evaluasi
kasus penggunaan. Guna mendapatkan perbandingan yang adil untuk model generatif, Anda mungkin biasanya
menjalankan evaluasi untuk model dan template perintah terhadap set data evaluasi
dan metrik terkaitnya berulang kali. Class EvalTask dirancang untuk
mendukung paradigma evaluasi baru ini. Selain itu, EvalTask memungkinkan Anda
terintegrasi secara lancar dengan
Eksperimen Vertex AI,
yang dapat membantu melacak pengaturan
dan hasil untuk setiap evaluasi yang berjalan.
Eksperimen Vertex AI dapat membantu mengelola dan menafsirkan hasil evaluasi,
sehingga Anda dapat bertindak
dalam waktu yang lebih singkat. Contoh berikut menunjukkan cara
Buat instance class EvalTask dan jalankan evaluasi:
from vertexai.preview.evaluation import EvalTask
eval_task = EvalTask(
dataset=DATASET,
metrics=["bleu", "rouge_l_sum"],
experiment=EXPERIMENT_NAME
)
Parameter metrics menerima daftar metrik, sehingga memungkinkan
evaluasi simultan beberapa metrik dalam satu panggilan evaluasi.
Persiapan set data evaluasi
Set data diteruskan ke instance EvalTask sebagai DataFrame pandas, dengan setiap baris
mewakili contoh evaluasi terpisah (disebut {i>instance<i}), dan setiap kolom
mewakili parameter input metrik. Lihat metrik untuk input yang diharapkan oleh
setiap metrik. Kami menyediakan beberapa contoh untuk membangun set data evaluasi
untuk tugas evaluasi yang berbeda.
Evaluasi ringkasan
Buat {i>dataset<i} untuk perangkuman poin-poin dengan metrik berikut:
summarization_qualitygroundednessfulfillmentsummarization_helpfulnesssummarization_verbosity
Dengan mempertimbangkan parameter input metrik yang diperlukan, Anda harus menyertakan kolom berikut dalam set data evaluasi:
instructioncontextresponse
Dalam contoh ini, kita memiliki dua instance ringkasan. Buatlah
Kolom instruction dan context sebagai input, yang diperlukan oleh
evaluasi tugas ringkasan:
instructions = [
# example 1
"Summarize the text in one sentence.",
# example 2
"Summarize the text such that a five-year-old can understand.",
]
contexts = [
# example 1
"""As part of a comprehensive initiative to tackle urban congestion and foster
sustainable urban living, a major city has revealed ambitious plans for an
extensive overhaul of its public transportation system. The project aims not
only to improve the efficiency and reliability of public transit but also to
reduce the city\'s carbon footprint and promote eco-friendly commuting options.
City officials anticipate that this strategic investment will enhance
accessibility for residents and visitors alike, ushering in a new era of
efficient, environmentally conscious urban transportation.""",
# example 2
"""A team of archaeologists has unearthed ancient artifacts shedding light on a
previously unknown civilization. The findings challenge existing historical
narratives and provide valuable insights into human history.""",
]
Jika Anda sudah menyiapkan respons LLM (ringkasannya) dan ingin melakukannya evaluasi bawa prediksi Anda sendiri (BYOP), Anda dapat menyusun respons masukkan sebagai berikut:
responses = [
# example 1
"A major city is revamping its public transportation system to fight congestion, reduce emissions, and make getting around greener and easier.",
# example 2
"Some people who dig for old things found some very special tools and objects that tell us about people who lived a long, long time ago! What they found is like a new puzzle piece that helps us understand how people used to live.",
]
Dengan input ini, kita siap untuk membuat set data evaluasi dan
EvalTask.
eval_dataset = pd.DataFrame(
{
"instruction": instructions,
"context": contexts,
"response": responses,
}
)
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
'summarization_quality',
'groundedness',
'fulfillment',
'summarization_helpfulness',
'summarization_verbosity'
],
experiment=EXPERIMENT_NAME
)
Evaluasi pembuatan teks umum
Agak besar
berbasis model
metrik seperti coherence, fluency, dan safety, hanya memerlukan model
respons untuk menilai kualitas:
eval_dataset = pd.DataFrame({
"response": ["""The old lighthouse, perched precariously on the windswept cliff,
had borne witness to countless storms. Its once-bright beam, now dimmed by time
and the relentless sea spray, still flickered with stubborn defiance."""]
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["coherence", "fluency", "safety"],
experiment=EXPERIMENT_NAME
)
Evaluasi Berbasis Komputasi
Metrik berbasis komputasi, seperti pencocokan persis, bleu dan rouge, membandingkan respons terhadap referensi dan karenanya membutuhkan kolom referensi dalam set data evaluasi:
eval_dataset = pd.DataFrame({
"response": ["The Roman Senate was filled with exuberance due to Pompey's defeat in Asia."],
"reference": ["The Roman Senate was filled with exuberance due to successes against Catiline."],
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["exact_match", "bleu", "rouge"],
experiment=EXPERIMENT_NAME
)
Evaluasi penggunaan alat (panggilan fungsi)
Untuk evaluasi panggilan alat (fungsi), Anda hanya perlu menyertakan respons dan dalam set data evaluasi.
eval_dataset = pd.DataFrame({
"response": ["""{
"content": "",
"tool_calls":[{
"name":"get_movie_info",
"arguments": {"movie":"Mission Impossible", "time": "today 7:30PM"}
}]
}"""],
"reference": ["""{
"content": "",
"tool_calls":[{
"name":"book_tickets",
"arguments":{"movie":"Mission Impossible", "time": "today 7:30PM"}
}]
}"""],
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["tool_call_valid", "tool_name_match", "tool_parameter_key_match",
"tool_parameter_kv_match"],
experiment=EXPERIMENT_NAME
)
Paket metrik
Paket metrik menggabungkan metrik yang umumnya terkait untuk membantu menyederhanakan proses evaluasi. Metrik tersebut dikategorikan ke dalam empat paket berikut:
- Tugas evaluasi: perangkuman, menjawab pertanyaan, dan pembuatan teks
- Perspektif evaluasi: kesamaan, keamanan, dan kualitas
- Konsistensi input: semua metrik di paket yang sama menggunakan set data yang sama input
- Paradigma evaluasi: pointwise versus berpasangan
Anda dapat menggunakan paket metrik ini dalam layanan evaluasi online untuk membantu Anda mengoptimalkan alur kerja evaluasi yang disesuaikan.
Tabel ini mencantumkan detail tentang paket metrik yang tersedia:
| Nama paket metrik | Nama metrik | Input pengguna |
|---|---|---|
text_generation_similarity |
exact_matchbleurouge |
referensi prediksi |
tool_call_quality |
tool_call_validtool_name_matchtool_parameter_key_matchtool_parameter_kv_match |
referensi prediksi |
text_generation_quality |
coherencefluency |
prediction |
text_generation_instruction_following |
fulfillment |
prediksi petunjuk |
text_generation_safety |
safety |
prediction |
text_generation_factuality |
groundedness |
prediction context |
summarization_pointwise_reference_free |
summarization_qualitysummarization_helpfulnesssummarization_verbosity |
prediction context instruction |
summary_pairwise_reference_free |
pairwise_summarization_quality |
prediction context instruction |
qa_pointwise_reference_free |
question_answering_qualityquestion_answering_relevancequestion_answering_helpfulness |
prediction context instruction |
qa_pointwise_reference_based |
question_answering_correctness |
prediction context instruction reference |
qa_pairwise_reference_free |
pairwise_question_answering_quality |
prediction context instruction |
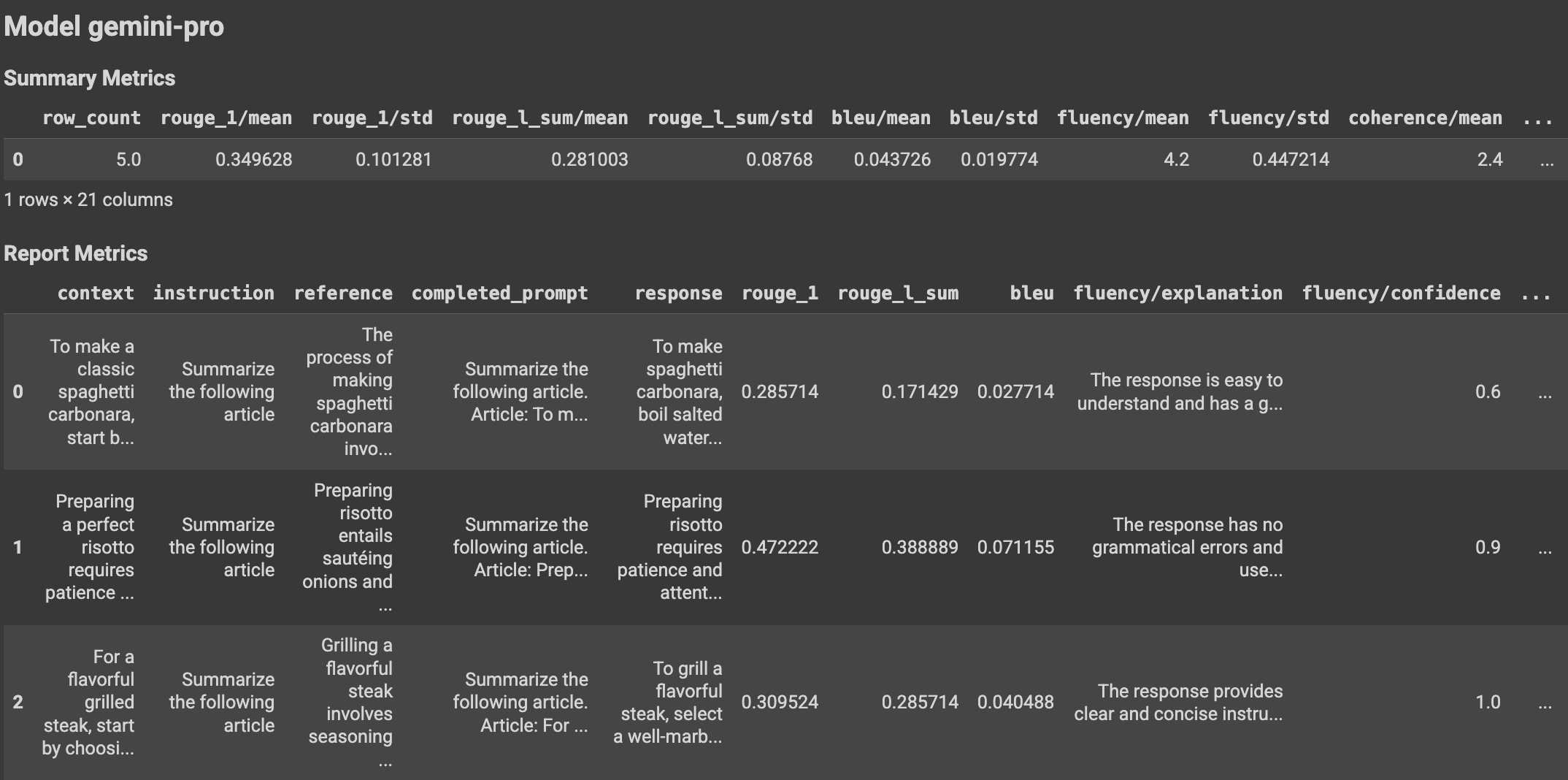
Lihat hasil evaluasi
Setelah Anda mendefinisikan tugas evaluasi, jalankan tugas untuk mendapatkan hasil evaluasi, sebagai berikut:
eval_result: EvalResult = eval_task.evaluate(
model=MODEL,
prompt_template=PROMPT_TEMPLATE
)
Class EvalResult merepresentasikan hasil evaluasi yang dijalankan, yang
mencakup metrik ringkasan dan tabel metrik dengan instance set data evaluasi
dan metrik per instance yang sesuai. Tentukan class sebagai berikut:
@dataclasses.dataclass
class EvalResult:
"""Evaluation result.
Attributes:
summary_metrics: the summary evaluation metrics for an evaluation run.
metrics_table: a table containing eval inputs, ground truth, and
metrics per row.
"""
summary_metrics: Dict[str, float]
metrics_table: Optional[pd.DataFrame] = None
Dengan menggunakan fungsi bantuan, hasil evaluasi dapat ditampilkan di Google Cloud.
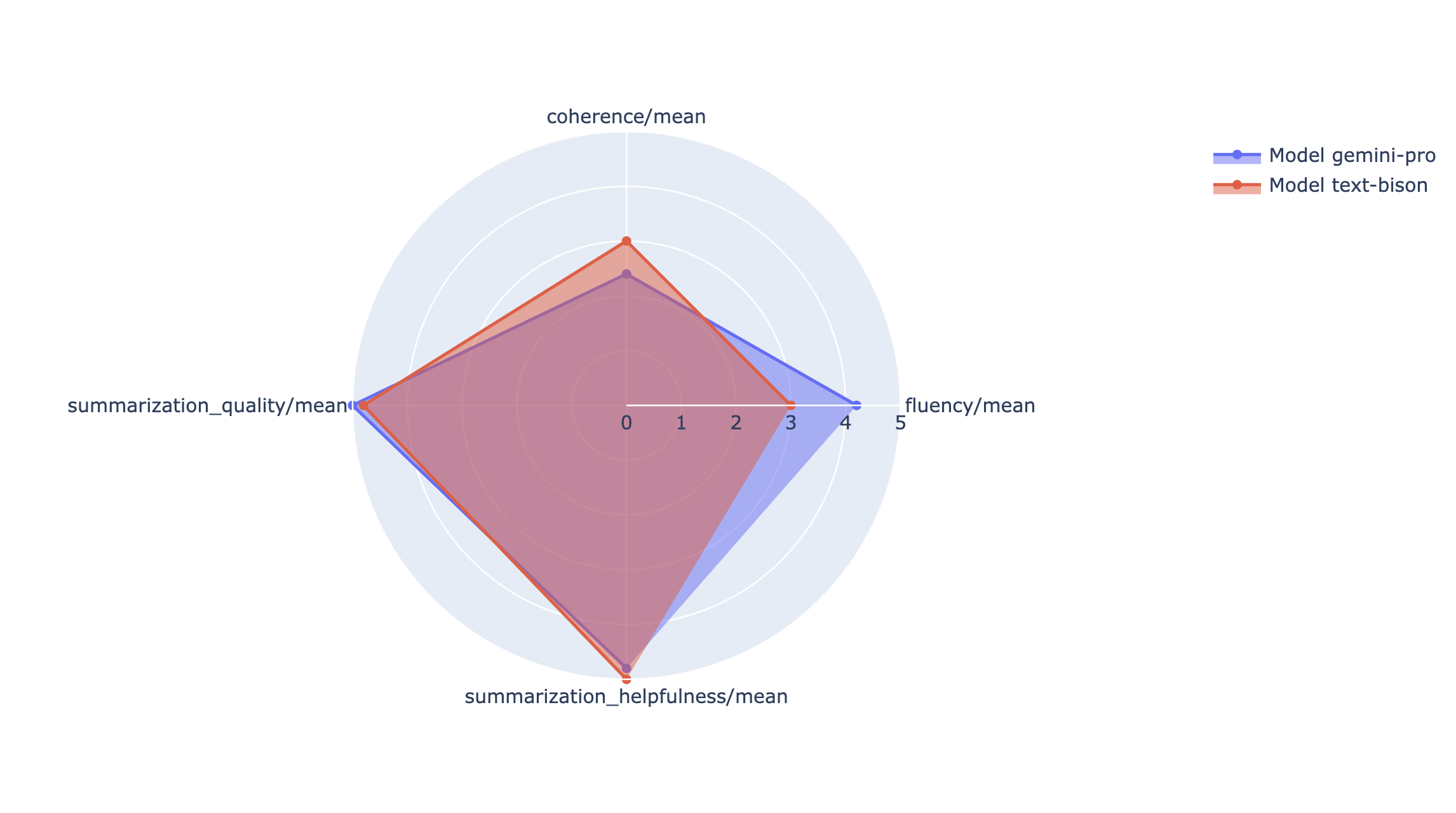
Visualisasi
Anda dapat memetakan metrik ringkasan dalam radar atau diagram batang untuk visualisasi dan perbandingan antara hasil dari berbagai evaluasi yang berjalan. Ini visualisasi data dapat membantu untuk mengevaluasi model yang berbeda dan template perintah.
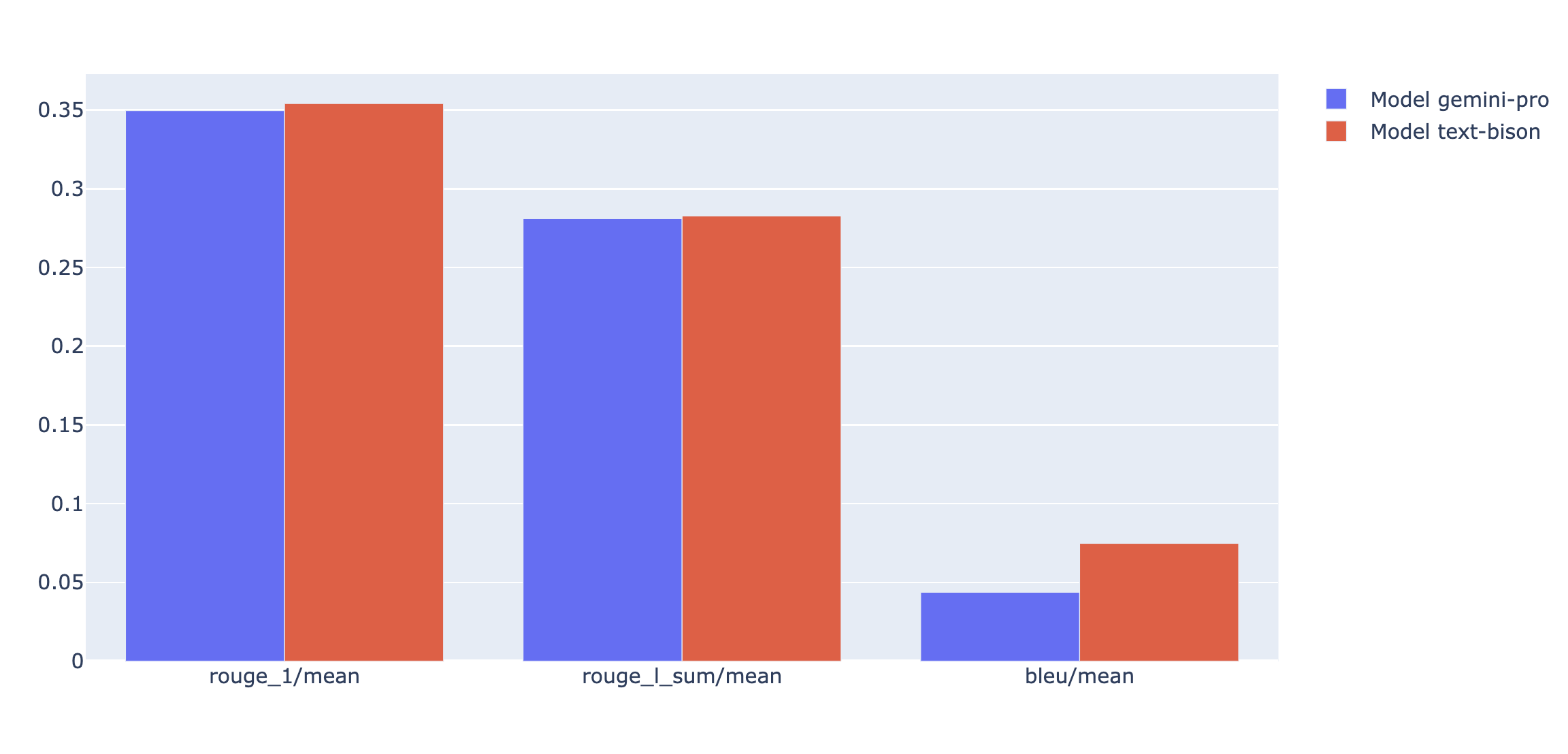
API evaluasi cepat
Untuk informasi tentang API evaluasi cepat, lihat API evaluasi cepat.
Memahami akun layanan
Akun layanan digunakan oleh layanan evaluasi {i>online<i} untuk mendapatkan prediksi dari layanan prediksi online untuk evaluasi berbasis model metrik. Akun layanan ini disediakan secara otomatis pada permintaan pertama ke layanan evaluasi online.
| Nama | Deskripsi | Alamat email | Peran |
|---|---|---|---|
| Agen Layanan Rapid Eval Vertex AI | Akun layanan yang digunakan untuk mendapatkan prediksi evaluasi berbasis model. | service-PROJECT_NUMBER@gcp-sa-ENV-vertex-eval.iam.gserviceaccount.com |
roles/aiplatform.rapidevalServiceAgent |
Izin yang terkait dengan agen layanan evaluasi cepat adalah:
| Peran | Izin |
|---|---|
| Agen Layanan Rapid Eval Vertex AI (roles/aiplatform.rapidevalServiceAgent) | aiplatform.endpoints.predict |
Langkah selanjutnya
- Coba notebook contoh evaluasi.
- Pelajari evaluasi AI generatif.
- Pelajari evaluasi berpasangan berbasis model dengan pipeline AutoSxS.
- Pelajari pipeline evaluasi berbasis komputasi.
- Pelajari cara menyesuaikan model dasar.